Zasadniczo istnieją dwa przypadki, kiedy użycie wątków może przynieść wymierne korzyści:
przyspieszenie przetwarzania dzięki wykorzystaniu procesorów wielordzeniowych,
utrzymanie aktywnego wątku GUI lub innych czasowo krytycznych wątków przez przeniesienie długotrwałych lub blokujących operacji do innych wątków.
Stworzenie nowego wątku jest proste, ale bardzo trudno jest zapewnić integralność współdzielonych zasobów. Dlatego w celu rozwiązania konkretnego problemu warto przed stworzeniem nowego wątku rozważyć wszystkie dostępne możliwości.
Technologie wielowątkowe w Qt
Qt zapewnia nam szereg mechanizmów, które pozwalają na zrealizowanie wielowątkowości w naszej aplikacji. Mamy możliwość skorzystania zarówno z niskopoziomowych, jak i wysokopoziomowych API.
W dalszej części wpisu będziemy korzystać z niskopoziomowego API, które dostarcza klasa QThread. Klasa ta umożliwia utworzenie wątku, który istnieje od momentu jego uruchomienia aż do momentu kiedy metoda QThread::run() zwróci sterowanie. W domyślnej implementacji metoda run() wywołuje metodę QThread::exec(), która uruchamia lokalną dla wątku pętlę zdarzeń. Może być to przydatne, gdy przez cały czas działania programu komunikujemy się z czymś np. przez port szeregowy oraz zbieramy i przetwarzamy duże ilości danych.
W innych przypadkach, np. konieczności niezależnego przetworzenia dużej ilości plików lub budowy własnego serwera, lepsze mogą okazać się wysokopoziomowe klasy, np. QRunnable i QThreadPool, czy przestrzeń o nazwie QtConcurrent. W QML możemy wykorzystać też rozwiązanie WorkerScript.
Porównanie wszystkich technologii wraz z rekomendacjami ich zastosowania w konkretnych przypadkach znajdziemy w tej dokumentacji.
Czym jest thread-safety i reentrancy?
Przedzierając się przez dokumentację Qt, będziemy spotykać się z dwoma bardzo ważnymi terminami: reentrancyoraz thread-safety. Oznaczają one to, jak klasy lub funkcje mogą być używane w wielowątkowych aplikacjach.
Funkcję oznaczoną jako thread-safe można wywoływać jednocześnie z wielu wątków, nawet gdy wywołania korzystają ze współdzielonych danych, ponieważ wszystkie odwołania do współdzielonych danych są odpowiednio zabezpieczone. Funkcję oznaczoną jako reentrantmożna wywoływać jednocześnie z wielu wątków pod warunkiem, że każde wywołanie używa własnych danych.
Funkcja thread-safe jest zawsze reentrant, ale funkcja reentrant nie zawsze jest thread-safe.
Rozszerzając to na klasy: mówimy, że klasa jest reentrant, jeśli jej metody można bezpiecznie wywołać z wielu wątków, o ile każdy wątek używa innej instancji klasy. O klasie powiemy, że jest thread-safe, jeśli jej metody można bezpiecznie wywoływać z wielu wątków, nawet jeśli wszystkie wątki używają tego samego wystąpienia klasy.
W przypadkach, w których zwykle nie ma równoczesnego dostępu do metod, wywoływanie niezabezpieczonych metod (non-thread-safe) w innych wątkach może zadziałać tysiące razy, zanim nastąpi równoczesny dostęp, powodując nieoczekiwane zachowanie programu.
Jak zapewnić thread-safety i reentrancy?
Klasy C++ są często określane jako reentrant dlatego, że wykorzystują tylko swoje zmienne (członków klasy). Dowolny wątek może wywoływać metodę klasy reentrant, o ile żaden inny wątek nie może wywoływać tej samej metody w tym samym czasie na tej samej instancji klasy.
C++
1
2
3
4
5
6
7
8
9
10
11
12
classCounter
{
public:
Counter(){n=0;}
voidincrement(){++n;}
voiddecrement(){--n;}
intvalue()const{returnn;}
private:
intn;
};
Powyższa klasa jest reentrant dlatego, że wykorzystuje tylko swoje zmienne. Natomiast ta klasa nie jest thread-safe, bo jeśli wiele wątków spróbuje zmodyfikować element n, to wynik będzie niezdefiniowany. Wynika to z faktu, że operatory „++” i „−−” nie zawsze są atomowe. Zwykle rozwijają się do trzech instrukcji maszynowych nazywanych RMW (ang. read–modify–write):
Załaduj wartość zmiennej do rejestru.
Zwiększ lub zmniejsz wartość rejestru.
Zapisz wartość rejestru z powrotem w pamięci głównej.
Jeśli wątek A i wątek B jednocześnie załadują starą wartość zmiennej, następnie zwiększą swój rejestr i zapiszą go z powrotem, to ostatecznie wzajemnie się nadpiszą, a w konsekwencji zmienna będzie zwiększona tylko raz!
Widzimy tutaj konieczność synchronizacji wątków: wątek A musi wykonać kroki 1, 2, 3 bez przerwania (czyli atomowo), zanim wątek B będzie mógł wykonać te same kroki lub odwrotnie. Prostym sposobem zapewnienia klasie thread-safety jest ochrona dostępu do współdzielonych danych (w tym wypadku zmiennej n) za pomocą muteksów:
C++
1
2
3
4
5
6
7
8
9
10
11
12
13
classCounter
{
public:
Counter(){n=0;}
voidincrement(){QMutexLocker locker(&mutex);++n;}
voiddecrement(){QMutexLocker locker(&mutex);--n;}
intvalue(){QMutexLocker locker(&mutex);returnn;}
private:
QMutex mutex;
intn;
};
Zablokowanie muteksu zapewnia nam, że dostęp z różnych wątków zostanie zsynchronizowany. Klasa QMutexLocker automatycznie blokuje muteks w swoim konstruktorze i odblokowuje go w momencie, gdy wywoływany jest destruktor (na końcu funkcji).
Należy pamiętać, aby ponownie odblokować zablokowany muteks. Jeśli tego nie zrobimy, możemy napotkać wiele problemów (np. deadlocków) − więcej na ten temat znaleźć można w artykule The Risks of Mutexes.
Synchronizacja wątków
Chociaż celem wątków jest umożliwienie równoległego działania kodu i największe wykorzystanie CPU, to są chwile, w których wątki muszą się zatrzymać i czekać na inne − np. jeśli dwa wątki próbują jednocześnie zmienić zawartość tej samej zmiennej. Zasada zmuszania wątków do wzajemnego oczekiwania nazywa się wzajemnym wykluczeniem (ang. mutual exclusion).
Wzajemne wykluczenie jest powszechną techniką ochrony współdzielonych zasobów.
Qt zapewnia szereg klas przeznaczonych do synchronizacji wątków, mowa m.in. o QMutex, QReadWriteLock i QWaitCondition, a także wysokopoziomowe Event Queues. Porównanie możliwości synchronizacji wątków opisano w tej dokumentacji. Trzeba pamiętać, że zastosowanie mechanizmów synchronizacji wpływa na obniżenie wydajności − wątki rywalizują o dostęp do danych.
Bezpieczeństwo mechanizmu sygnałów i slotów
Podczas budowy aplikacji wielowątkowych, które wymieniają dane między wątkami, musimy zapewnić odpowiednią synchronizację wątków w dostępie do współdzielonych danych i spełnić następującą zasadę: wiele wątków może jednocześnie odczytywać współdzielone dane, ale tylko jeden z nich może dokonywać modyfikacji − wszystkie pozostałe wątki muszą czekać, nawet jeśli dokonują tylko odczytu.
Jeśli nie spełnimy tej zasady, możemy utracić integralność naszych danych, co standard definiuje jako nieokreślone zachowanie (ang. undefined behaviour).
Bezpieczeństwo mechanizmu
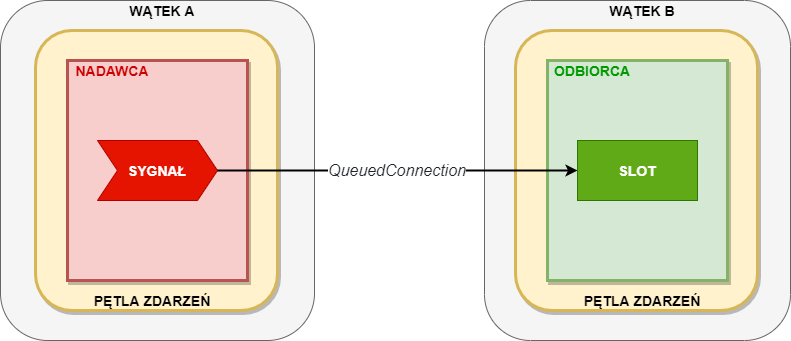
Jeśli przyjrzymy się metodzie QObject::connect(), to zauważymy, że posiada ona jeden domyślny argument: Qt::ConnectionType type = Qt::AutoConnection. Z tej dokumentacji dowiemy się, że przy wywołaniu metody QObject::connect() z argumentem Qt::ConnectionType typu Qt::QueuedConnection:
The slot is invoked when control returns to the event loop of the receiver's thread. The slot is executed in the receiver's thread.
Wówczas kod w slocie odbiorcy sygnału będzie wykonywany w jego wątku, a nie w wątku nadawcy sygnału. W tym miejscu dokumentacji czytamy, że:
It is safe to connect signals and slots across different threads, thanks to a mechanism called queued connections.
Dla nas to oznacza, że możemy wykorzystywać mechanizm sygnałów i slotów do wywoływania akcji, zlecając dyspozycję jej wywołania sygnałem wyemitowanym w dowolnym wątku za pomocą slotu obsługiwanego przez dowolny inny wątek.
Mechanizm sygnałów i slotów jest bezpieczny, dopóki nie są wymieniane za jego pomocą dane, które można modyfikować z dowolnego wątku. Innymi słowy, możemy wymieniać dane za pomocą mechanizmu sygnałów i slotów pod warunkiem, że wymieniane dane są stałe lub przekazujemy je za pomocą kopii, w szczególności „głębokiej kopii” (ang. deep copy). Jeżeli dane, które przekazujemy między wątkami, są stałe i żaden wątek nie ma możliwości ich modyfikacji, nie musimy zapewniać synchronizacji wątków w dostępie do tych danych.
Qt's event system is very useful for inter-thread communication. (…) To call a slot (or any invokable method) in another thread, place that call in the target thread's event loop.
To place an invocation in an event loop, make a queued signal-slot connection. Whenever the signal is emitted, its arguments will be recorded by the event system. The thread that the signal receiver lives in will then run the slot. (…) In both cases, a queued connection must be used because a direct connection bypasses the event system and runs the method immediately in the current thread.
There is no risk of deadlocks when using the event system for thread synchronization, unlike using low-level primitives. However, the event system does not enforce mutual exclusion. If invokable methods access shared data, they must still be protected with low-level primitives.
Having said that, Qt's event system, along with implicitly shared data structures, offers an alternative to traditional thread locking. If signals and slots are used exclusively and no variables are shared between threads, a multithreaded program can do without low-level primitives altogether.
Trzeba więc zapamiętać, że jeśli za pomocą sygnałów i slotów przekazujemy dane, które mogą zostać zmodyfikowane w dowolnym wątku, to musimy zapewnić odpowiednią synchronizację wątków w dostępie do tych danych.
Czym jest implicit sharing?
Wiele klas Qt, np. QString i QByteArray, implementuje mechanizm zwany implicit sharing. Dokumentacja Qt mówi, że:
(...) Qt use implicit data sharing to maximize resource usage and minimize copying. Implicitly shared classes are both safe and efficient when passed as arguments, because only a pointer to the data is passed around, and the data is copied only if and when a function writes to it, i.e., copy-on-write.
Wzrost wydajności przez ograniczenie kopiowania ma swoje konsekwencje w przekazywaniu obiektów tych klas do innych wątków. Przekazanie obiektu takiej klasy przez wartość nie oznacza wykonania głębokiej kopii, lecz tylko skopiowanie wskaźnika. Jeśli obiekt zostanie jednocześnie zmodyfikowany w jednym wątku i odczytany w innym, to mamy do czynienia z undefined behaviour.
Note that atomic reference counting does not guarantee thread-safety. Proper locking should be used when sharing an instance of an implicitly shared class between threads. This is the same requirement placed on all reentrant classes, shared or not. Atomic reference counting does, however, guarantee that a thread working on its own, local instance of an implicitly shared class is safe. We recommend using signals and slots to pass data between threads, as this can be done without the need for any explicit locking.
Trzeba więc zapamiętać, że dostęp z różnych wątków do obiektów klas, które implementują mechanizm implicit sharing, należy zabezpieczyć za pomocą dostępnych mechanizmów synchronizacji. Listę klas Qt, które stosują mechanizm, znaleźć można w dokumentacji Qt na temat implicit sharing.
Czym jest QThread?
Klasa QThread jest fundamentem dla wszelkiej kontroli wątków w Qt. Każda instancja klasy QThread reprezentuje i kontroluje jeden wątek. Klasa QThread nie jest wątkiem sama w sobie, tylko interfejsem kontrolującym go.
Klasa QThread może być wykorzystana na dwa sposoby:
stworzona jako obiekt – stworzenie instancji QThread zapewnia równoległą pętlę zdarzeń, umożliwiając wywoływanie slotów obiektów pochodnych klasy QObject w wątku obsługiwanym przez instancję QThread,
odziedziczona – co pozwala aplikacji na zainicjowanie nowego wątku przed uruchomieniem pętli zdarzeń lub uruchomienie kodu bez pętli zdarzeń.
My wykorzystamy pierwszą z opcji. Sprowadza się to do wykonania następujących czynności:
Zaimplementowania klasy Worker, dziedziczącej po QObject, której zadaniem jest wykonywanie czynności wewnątrz wątku.
Zaimplementowania klasy Controller, dziedziczącej po QObject, której zadaniem jest kontrolowanie i przekazywanie informacji między głównym wątkiem a wątkiem, gdzie pracuje obiekt klasy Worker.
Utworzenia instancji wątku – workerThread – i instancji klasy Worker w klasie Controller.
Zmienienia powinowactwa (ang. thread affinity) obiektu worker do wątku workerThread za pomocą metody QObject::moveToThread(QThread*).
Zdefiniowania odpowiednich połączeń.
Uruchomienia wątku.
Nazwy klas i obiektów mogą być dowolne. Tutaj używamy nazw zgodnie z dokumentacją.
Przykład praktyczny
Po długim wprowadzeniu możemy w końcu zająć się programowaniem. Rozwiążemy teraz problem, który przedstawiliśmy w poprzedniej części. Przypomnijmy zamierzone działanie programu: klikając w przycisk, rozpoczynamy wykonywanie obliczeń. Chcemy obserwować ich postęp za pomocą ProgressBar oraz zablokować przycisk na czas ich trwania. Na koniec chcemy poznać ich wynik (drukując go w konsoli).
W poprzedniej części wprowadziliśmy już klasę Worker. Pierwszy punkt z powyższej listy został zatem wykonany. Przypomnijmy jej kod:
Klasa kontrolera jest nieco bardziej skomplikowana. Jej zdefiniowanie to właściwie wykonanie punktów 2–5. Kod tej klasy (bez zawartości metod, które omówimy za chwilę) wygląda następująco:
C++
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
#ifndef CONTROLLER_H
#define CONTROLLER_H
#include <QObject>
#include <QThread>
#include <worker.h>
classController:publicQObject// punkt z listy: (2)
{
Q_OBJECT
public:
explicitController(QObject*parent=nullptr):QObject(parent)// punkt z listy: (3), (4), (5), (6)
{// ... }
~Controller()overridefinal
{// ... }
signals:
voidprogress(doublevalue);
voidresult(intresult);
voidfinished();
voidheavyCalculations();
private:
QThread workerThread;// punkt z listy: (3)
voidmakeConnections(constWorker*const_worker)const// punkt z listy: (5)
{// ... }
};
#endif // CONTROLLER_H
Punkt 2 za nami, przejdźmy więc do punktów 3–5. Wykonujemy je w konstruktorze, którego zawartość jest następująca:
worker->moveToThread(&workerThread);// punkt z listy (4)
makeConnections(worker);// punkt z listy (5)
workerThread.start();// punkt z listy (6)
}
Ostatni punkt – 6 – to uruchomienie nowego wątku. Od tego momentu poprzez obiekt Controller możemy zlecić wykonanie obliczeń w osobnym wątku, nie blokując interfejsu.
Instancję klasy QThread stworzyliśmy jako członka klasy Controller. W konstruktorze tworzymy na stercie obiekt klasy Worker, a następnie wykonujemy punkt 4, czyli dokonujemy zmiany powinowactwa obiektu worker do wątku workerThread za pomocą: worker->moveToThread(&workerThread).
Zauważmy jedną bardzo ważną rzecz: konstruktor klasy Worker zostanie wywołany w wątku, w którym istnieje obiekt klasy Controller. Po wywołaniu moveToThread() i uruchomieniu wątku nasz obiekt worker będzie wykonywał operacje w nowo utworzonym wątku workerThread.
Punkt 5 zdefiniowany jest w wywołaniu makeConnections(worker). Zapewniamy tam odpowiednie zwolnienie pamięci i definiujemy przepływ sterowania – naszą logikę. Zawartość metody makeConnections() jest następująca:
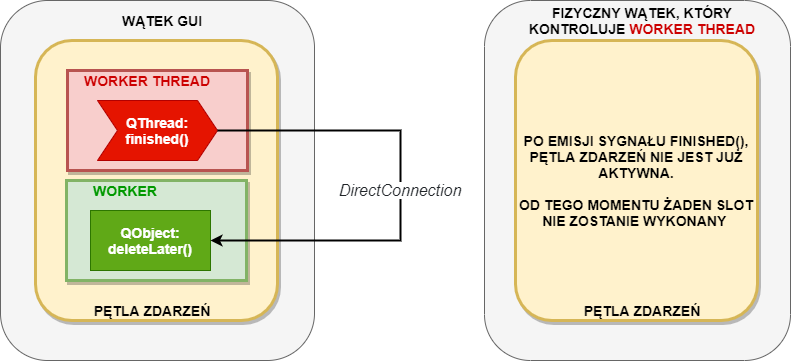
Pierwsze wywołanie connect() zapewnia nam odpowiednie zwolnienie pamięci po obiekcie klasy Worker, który został utworzony na stercie. Zwróćcie uwagę na typ połączenia: DirectConnection. Wątek po emisji sygnału finished() kończy działanie pętli zdarzeń, dlatego obowiązek zwolnienia pamięci po obiekcie worker kieruje do pętli głównej aplikacji (tej z main.cpp), która jednocześnie obsługuje obiekt klasy Controller.
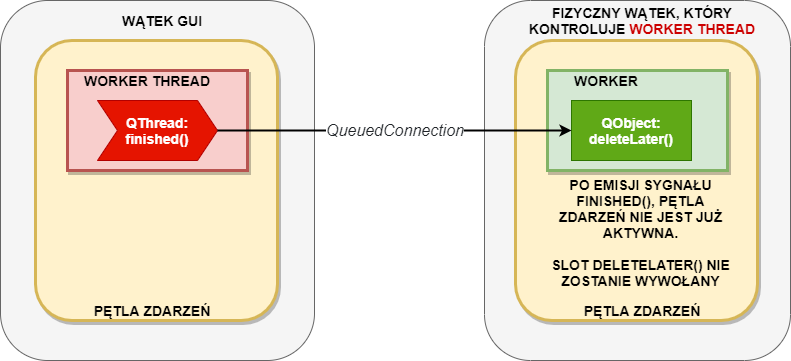
Gdybyśmy wykorzystali połączenie typu QueuedConnection, to doprowadzilibyśmy do memory leak – pamięć po obiekcie worker nie zostałaby zwolniona, ponieważ jej zwolnienie zostałoby przekierowanie do pętli zdarzeń wątku workerThread, która została właśnie zakończona przez kończący pracę wątek. Wrócimy do tego później.
Pozostałe wywołania connect() to zdefiniowanie przepływu naszego sterowania, czyli uruchomienie obliczeń, zwrócenie wyniku, zwracanie postępu i zwrócenie informacji o zakończeniu obliczeń. Zauważcie, że wykorzystaliśmy tutaj mały skrót – podłączyliśmy sygnały z innymi sygnałami. Dzięki temu uniknęliśmy tworzenia dodatkowych slotów, których zadaniem byłaby tylko emisja odpowiedniego sygnału. W tych wywołaniach definiujemy typ połączenia na QueuedConnection, aby wywołanie slotu zostało wykonane w wątku workerThread. W przypadku użycia DirectConnection:
Wywołanie slotu nastąpiłoby w głównym wątku, czyli GUI. Nasz dodatkowy wątek byłby wtedy absolutnie bezużyteczny.
Pominęliśmy jednak ostatnią ważną rzecz, czyli zakończenie działania wątku – wykonujemy je w destruktorze:
C++
1
2
3
4
5
~Controller()overridefinal
{
workerThread.quit();
workerThread.wait();
}
Pierwsze wywołanie – workerThread.quit() – to polecenie zakończenia pętli zdarzeń wątku. Drugie wywołanie – workerThread.wait() – to zablokowanie wątku do czasu jego zakończenia, czyli wyjścia z metody run(), co dzieje się w momencie zakończenia pętli zdarzeń w przypadku standardowej implementacji metody run(). Nasze podejście wykorzystuje opcję ze stworzeniem instancji klasy QThread, gdzie metoda run() implementuje opisane wyżej zachowane.
Warto zwrócić uwagę na oznaczenie funkcji: override final. Są to słowa kluczowe w C++11. Słowo override sygnalizuje kompilatorowi, że nadpisujemy metodę wirtualną – w tym wypadku konstruktor (który jest wirtualny w klasie QObject) – tutaj destruktor (który jest wirtualny w klasie QObject). Dodanie override pozwala na sprawdzanie w czasie kompilacji, czy faktycznie dokonujemy nadpisania jakiejś metody wirtualnej, a nie tworzymy nowej.
Z kolei słowo final informuje kompilator, że jest to ostatnia implementacja konstruktora. Innymi słowy, oznacza to, że nie można nadpisać tej metody wirtualnej w klasie pochodnej lub odziedziczyć tej klasy. Może to pozwolić kompilatorowi na dokonanie kolejnych optymalizacji.
Jedyną zmianą w porównaniu z wersją z poprzedniej części jest zamienienie klasy Worker na klasę Controller. Tym razem to obiekt klasy Controller będzie używany w QML w miejscu obiektu klasy Worker. Zawartość main.qml pozostaje bez zmian.
Zauważcie, że wszystkie dane, które wymieniamy między wątkami, przekazujemy poprzez kopię, dlatego nie wykorzystujemy tutaj żadnego mechanizmu synchronizacji dostępu do zasobów.
Możemy sprawdzić powyższą uwagę: wymieniamy dwie informacje: _progress i _result. Aby się upewnić, że nie współdzielimy danych między wątkami, możemy porównać adresy zmiennych w pamięci.
W klasie Worker:
C++
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
classWorker:publicQObject
{
// ...
publicslots:
voidheavyCalculations()
{
// ...
int_result;
double_progress;
for(inti=0;i<ITERATIONS;i++)
{
// ...
if(0==i%100000)
{
qDebug()<<"Iteration"<<i;
_progress=static_cast<double>(i+1)/(ITERATIONS);
// ...
}
}
// ...
qDebug()<<"Worker: Address of _result:"<<&_result << "Address of _progress:" << &_progress;
// ...
}
// …
private:
staticconstexprintITERATIONS=1;
};
W klasie Controller:
C++
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
classController:publicQObject
{
//...
publicslots:
voidonProgress(double_progress)
{
qDebug()<<"Controller: Address of _progress:"<<&_progress;
emit progress(_progress);
}
voidonResult(double_result)
{
qDebug()<<"Controller: Address of _result:"<<&_result;
Uruchamiając obliczenia dla jednej iteracji, dostajemy:
1
2
3
Worker:Address of _result:0x7f42f37fd998Address of _progress:0x7f42f37fd9a0
Controller:Address of _progress:0x7fffeab05ed0
Controller:Address of _result:0x7fffeab05ee0
Gdybyśmy przekazywali tutaj dane za pomocą wskaźników lub referencji albo przekazywali typy, które implementują mechanizm implicit sharing, musielibyśmy zapewnić odpowiednią synchronizację wątków.
Wcześniej wyjaśniliśmy konieczność użycia odpowiedniego typu połączenia, aby zwolnić pamięć:
Najpierw zapewnijmy jawną implementację dla destruktora klasy Worker:
C++
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// ...
#include <QThread>
classWorker:publicQObject
{
//...
public:
//...
~Worker()overridefinal
{
qDebug()<<"Worker dtor";
}
//...
};
Następnie uruchommy program z typem połączenia DirectConnection. Czy destruktor został wywołany? W konsoli po zamknięciu programu powinniśmy zobaczyć komunikat: Worker dtor.
Aplikacje możemy przeanalizować za pomocą programu Valgrind, który można zainstalować np. na Ubuntu. Program ten nie jest dostępny dla Windowsa, ale możemy posłużyć się zamiennikiem.
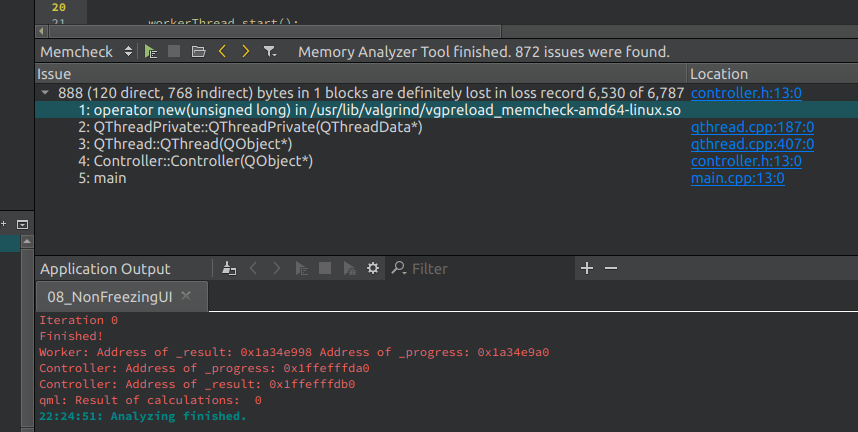
Analizując program za pomocą Valgrinda, klikamy Analyze > Valgrind Memory Analyzer, a po włączeniu i wyłączeniu naszej aplikacji otrzymamy raport, w którym znajdziemy wystąpienie wycieku pamięci:
Memory Analyzer Tool
Rzeczywiście, w konstruktorze klasy Controller alokujemy obiekt Worker, który nigdzie nie został zwolniony – jest to wspomniany problem związany z zakończeniem pętli zdarzeń w wątku workerThread i zleceniu zwolnienia pamięci po obiekcie Worker do tej pętli zdarzeń, co staje się niemożliwe po jej zakończeniu.
Przykład z zastosowaniem synchronizacji
W poprzednim przykładzie przesyłaliśmy informacje, przekazując podstawowe typy danych przez wartość. Tym samym zapewniliśmy, że żadne dane nie były współdzielone między wątkami. Załóżmy, że zamiast typu double chcemy przesyłać postęp obliczeń za pomocą wskaźnika na typ QString:
C++
1
2
signals:
voidprogress(QString*stringProgress);
Przekazując wskaźnik, skazujemy się na współdzielenie zasobów między wątkami. Skoro współdzielimy zasoby, musimy zapewnić odpowiednią synchronizację wątków w dostępie do tych zasobów. Zastosujemy klasy: QReadWriteLock, QReadLocker, QWriteLocker, QReadLocker i QWriteLocker – zagwarantują nam one odpowiednie zwolnienie blokady, natomiast QReadWriteLock będzie współdzieloną między wątkami blokadą.
Jeśli chcemy chronić zasoby za pomocą elementów synchronizacyjnych, np. QMutex, to musimy obiekt tej klasy współdzielić między wątkami, które mają mieć dostęp do tych zasobów. Użycie różnych instancji tej klasy w różnych wątkach nie zapewnia żadnej ochrony!
Zmieńmy nieco nasz poprzedni przykład i dodajmy następujące fragmenty. Plik Controller.h:
Nasz współdzielony zasób modyfikujemy tylko w klasie Worker, więc tam używamy blokady na zapis za pomocą QWriteLocker – wszystkie wątki, poza tym, który dokonuje modyfikacji, muszą czekać. W klasie Controller jedynie odczytujemy nasz współdzielony zasób, więc używamy blokady na odczyt za pomocą QReadLocker – wszystkie wątki, które dokonują odczytu, mogą to robić równolegle.
Naszą blokadę – QReadWriteLock (lock); – definiujemy w pliku main.cpp, a następnie przekazujemy za pomocą wskaźników do klasy Controller i Worker. Wszystkie metody klasy QReadWriteLock są thread-safe, dlatego możemy je współdzielić między wątkami. Natomiast w klasie Controller dodaliśmy nowy slot, w którym przejmujemy zasób i konwertujemy go z typu QString do double. Uruchamiając program, powinniśmy uzyskać taki sam efekt jak wcześniej.
Bez synchronizacji
Gdy zakomentujemy w klasie Worker linie, które włączają blokady, czyli QWriteLocker _locker(lock); a w klasie Controller –QReadLocker _locker(lock); i uruchomimy program, prawdopodobnie po chwili proces naszej aplikacji zostanie przerwany przez system z powodu naruszenia pamięci:
1
2
3
4
5
6
7
8
9
...
Iteration40050000
Iteration40060000
Iteration40070000
Iteration40080000
Iteration40090000
doublefree orcorruption(fasttop)
Iteration40100000
Aborted(core dumped)
Wystąpienie takiego błędu w aplikacji wielowątkowej znajdziemy np. w tym wątku na StackOverflow. Warto przeczytać o wytkniętych tam autorowi błędach.
Przedstawiony w przykładzie sposób współdzielenia zasobów pewnie nie znalazłby miejsca w normalnym kodzie produkcyjnym.
Zdecydowanie lepiej byłoby stworzyć klasę, która reprezentuje nasz współdzielony zasób, jest odpowiednio zabezpieczona i tylko jej instancja jest współdzielona między wątkami. Natomiast wątki jedynie wywołują odpowiednie metody (które są wewnętrznie odpowiednio zabezpieczone) tej klasy – zapewnienie odpowiedniej synchronizacji spada na twórcę takiej klasy, a nie na jej użytkownika. Przykład takiej klasy przedstawiliśmy we wstępie o thread-safety i reentrancy – klasa Counter.
Lockery a kontenery asocjacyjne
Użycie wygodnych klas, czyli wspomnianych QMutexLocker, QReadLocker czy QWriteLocker, nie zwalnia nas z zachowania czujności. Musimy być szczególnie uważni m.in. podczas pracy z kontenerami asocjacyjnymi, np. mapą.
W przypadku gdy dany klucz nie istnieje, wykorzystywanie na obiektach klas QMap czy std::map operatora [] w celu zwrócenia referencji do wartości zmapowanej przez podany klucz spowoduje wykonanie operacji wstawienia klucza z domyślną wartością. Przeanalizujmy poniższy pseudokod, w którym mamy do czynienia z undefined behaviour, wynikającym z opisanej wyżej sytuacji.
C++
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
#include <QCoreApplication>
#include <QMap>
#include <QReadWriteLock>
#include <QWriteLocker>
#include <QReadLocker>
#include <QDebug>
intmain(intargc,char*argv[])
{
QCoreApplicationa(argc,argv);
QReadWriteLock lock;
QMap<QString,int>map;
map.insert("Jeden",1);
map.insert("Dwa",2);
// wątek 1 wykonuje ten blok kodu równocześnie z wątkiem 2
{
lock.lockForRead();
qDebug()<<map["Jeden"];
qDebug()<<map["Dwa"];
qDebug()<<map["Trzy"];
lock.unlock();
}
// wątek 2 wykonuje ten blok kodu równocześnie z wątkiem 1
{
lock.lockForRead();
qDebug()<<map["Cztery"];// undefined behaviour
qDebug()<<map["Jeden"];
qDebug()<<map["Dwa"];
qDebug()<<map["Trzy"];
lock.unlock();
}
returna.exec();
}
W powyższym kodzie wątek 1 odczytuje zawartość mapy, w tym samym czasie wątek 2 również odczytuje zawartość mapy, ale oczekuje zwrócenia referencji do wartości zmapowanej przez klucz, który nie istnieje, co spowoduje wstawienie do mapy nowej wartości. W konsekwencji dochodzimy do naruszenia przytoczonej we wstępie reguły – doprowadziliśmy do sytuacji, gdzie jeden wątek modyfikuje dane, a inny wątek dokonuje ich odczytu w tym samym czasie.
Wątki a wielordzeniowe procesory
Ktoś mógłby zapytać: „Jaka jest optymalna liczba wątków, aby najwydajniej wykorzystać posiadany procesor?”. Możemy stworzyć dowolną liczbę wątków (o ile nie braknie nam pamięci RAM), jednak należy pamiętać, że wątki konkurują między sobą o zasób, jakim jest czas procesora. Dlatego stworzenie 100 wątków do przetworzenia np. 100 obrazów osobno niekoniecznie może być najlepszym pomysłem. Zdecydowanie lepsze będzie stworzenie puli wątków i umieszczenie listy obrazów w kolejce do przetworzenia – możemy np. wykorzystać klasę QThreadPool.
Jednak jaką liczbę wątków ma mieć do dyspozycji obiekt klasy QThreadPool? Standardowo klasa QThreadPool wykorzystuje liczbę wątków, której wartość jest równa wartości zwracanej przez metodę QThread::idealThreadCount(). Odpowiada ona liczbie fizycznych wątków naszego procesora, np. procesor AMD Ryzen 5 3600 posiada 6 rdzeni, a każdy z nich 2 wątki fizyczne, co daje w konsekwencji 12 wątków fizycznych. Stąd nasza aplikacja powinna stworzyć maksymalnie 12 wątków, aby najlepiej wykorzystać możliwości takiego procesora. Wykorzystując QThread::idealThreadCount(), możemy zapewnić skalowalność naszej aplikacji między różnymi platformami.
Należy pamiętać, że powyższa sugestia może sprawdzić się w rozwiązaniu pewnej części problemów, ale w tej pozostałej części już niekoniecznie. Wtedy należy przeprowadzić testy – najlepiej w warunkach zbliżonych do docelowych – i wybrać optymalną liczbę wątków.
Zadanie dodatkowe
Osoby, które chciałyby poznać lepiej ten temat, powinny zainteresować się poniższymi materiałami:
podrozdział QThread and QtConcurrent z książki An Introduction to Design Patterns in C++ with Qt, 2nd Edition,
podrozdział Synchronizing Threads z książki C++ GUI Programming with Qt 4, 1st Edition,
masa rzetelnych informacji dotyczących wzajemnych relacji mechanizmu eventów, wątków i klasy QObject w Qt znajdziemy również na Wiki Qt.
Podsumowanie
W tej części przedstawiliśmy kolejną partię teorii dotyczącej wielowątkowości w ogólnym rozumieniu i wielowątkowości przy użyciu Qt. Wyjaśniliśmy takie pojęcia jak thread-safety oraz reentrancy. Powiedzieliśmy o bezpieczeństwie mechanizmu sygnałów i slotów oraz zwróciliśmy uwagę na wiele istotnych elementów, którym należy się przyjrzeć podczas rozwoju aplikacji wielowątkowych, czyli np. na synchronizację wątków.
Czy wpis był pomocny? Oceń go:
Średnia ocena 4.8 / 5. Głosów łącznie: 22
Nikt jeszcze nie głosował, bądź pierwszy!
Artykuł nie był pomocny? Jak możemy go poprawić? Wpisz swoje sugestie poniżej. Jeśli masz pytanie to zadaj je w komentarzu - ten formularz jest anonimowy, nie będziemy mogli Ci odpowiedzieć!
Z tej części kursu powinniście zapamiętać to, że wielowątkowość to trudny temat, w którym wiele czynników ma ostateczny wpływ na efekt końcowy. Zanim postanowicie wykorzystać wielowątkowość, zastanówcie się, czy nie ma innych możliwości rozwiązania problemu. W następnej części zajmiemy się uruchamianiem procesów oraz komunikacją między procesami (ang. inter-process communication).
Autorem tej serii wpisów jest Mateusz Patyk, który zawodowo zajmuje się programowaniem systemów wbudowanych oraz rozwijaniem aplikacji na desktopy i urządzenia mobilne. Jego głównymi obszarami zainteresowań są systemy sterowania, egzoszkielety i urządzenia do wspomagania chodu człowieka. Prywatnie miłośnik dobrego kina i gier strategicznych.
Dołącz do 20 tysięcy osób, które otrzymują powiadomienia o nowych artykułach! Zapisz się, a otrzymasz PDF-y ze ściągami (m.in. na temat mocy, tranzystorów, diod i schematów) oraz listę inspirujących DIY na bazie Arduino i Raspberry Pi.
Dołącz do 20 tysięcy osób, które otrzymują powiadomienia o nowych artykułach! Zapisz się, a otrzymasz PDF-y ze ściągami (m.in. na temat mocy, tranzystorów, diod i schematów) oraz listę inspirujących DIY z Arduino i RPi.


















Trwa ładowanie komentarzy...