Przeszukaj forum
Pokazywanie wyników dla tagów 'FAQ'.
Znaleziono 7 wyników
-
Choć tablice nie są tematem kursu Arduino ani poziomu 1 ani poziomu 2, to warto o nich wspomnieć. W pytaniach na forum kursanci często pytają jak udoskonalić swoje programy – w niektórych przykładach aż prosi się o użycie tablic. Temat jest omówiony co prawda w kursie STM32L4 w części 3 o GPIO, to jednak linkowanie trudnego artykułu dla zupełnie początkujących może budzić lęk. Postanowiłem więc napisać wstęp do tablic w Arduino, który przerodził się w nieco dłuższą serię (powiedzmy kurs). W pierwszej części ogólnikowo przedstawię tematykę oraz sposób poradzenia sobie z kilkoma typowymi problemami. W dalszych częściach zagłębimy się w bardziej wnikliwe zagadnienia, gdzie niezbędna będzie podstawowa wiedza o wskaźnikach. Spis treści #1 – wstęp i praktyka (czytasz ten artykuł) #2 – organizacja pamięci #3 – tablice w pamięci #4 – tablica jest wskaźnikiem #5 – znaki, cstring #6 – argumenty funkcji #7 – przykład #8 – tablice wielowymiarowe #9 – tablice dynamiczne #10 – zakończenie Zmienne i typy danych W kursie Arduino przyrównano zmienne do "szufladek" do których wkładamy jakieś dane. Przeznaczenie tych danych określa typ danych i na pewno kojarzysz już takie hasła jak: char, int, long czy float. Każda zmienna jest w stanie przechować jedną wartość, np. zmienna int może przechować liczbę całkowitą, a zmienna float liczbę zmiennoprzecinkową: int variable_int = 5; // zmienna całkowitoliczbowa float variable_float = 1.5; // zmienna zmiennoprzecinkowa Obiekt jest tu słusznym określeniem, ponieważ w C i C++ istnieją typy danych wbudowane (tzw. fundamentalne lub proste), np. char, int, ipt., a także typy dodane, które mogą reprezentować zbiór (np. strukturę) typów fundamentalnych. Więcej danych Co jednak zrobić, gdy liczba danych zaczyna rosnąć? Wyobraźmy sobie taki scenariusz: projektujemy sterownik skrytek na bagaż. W każdej skrytce ma być umieszczony czujnik zamknięcia drzwiczek, tak by sterownik miał kontrolę nad całą szafą: Gdybyśmy chcieli przyporządkować każdemu czujnikowi (skrytce) jedną zmienną to szybko dojdziemy do 2 słusznych wniosków: napisanie tego jest mozolne i małorozwojowe, trzeba jakoś usystematyzować nazewnictwo. Możliwe, że nasz kod zacznie wyglądać tak: // skrytki w górnym wierszu int locker_0 = 0; // skrytka w zerowej kolumnie int locker_1 = 0; // skrytka w pierwszej kolumnie int locker_2 = 0; // skrytka w drugiej kolumnie int locker_3 = 0; // skrytka w trzeciej kolumnie int locker_4 = 0; // skrytka w czwartej kolumnie // ... Jak się teraz do tego odwołać? Jak sprawdzić czy wybrana skrytka jest zamknięta? Lepiej nie zaprzątać sobie tym głowy. Użyjmy do tego tablicy! Tablice Tablica jest uporządkowanym ciągiem danych tego samego typu zajmujących ciągłe miejsce w pamięci. Wracając do przykładu podanego na wstępie, to tablica jest odpowiednikiem szafki z szufladami. Szuflady możemy ponumerować począwszy od zera, a następnie wkładać i wyciągać z nich obiekty posługując się tymi numerami, czyli indeksami. Dane są uporządkowane - każda skrytka ma swój niezmienny, unikatowy indeks. To że są tego samego typu oznacza, że w obrębie jednej tablicy możemy używać tylko jednego typu danych – to tak jakby uznać, że jedna szafka jest tylko na sztućce, a inna tylko na narzędzia. Do tego, że dane zajmują w pamięci określone miejsce jeszcze wrócimy. Tablice w praktyce Postaram się w skrócie napisać niezbędne minimum, aby móc używać tablic w programach (szczegóły zostaną omówione w dalszych częściach). Zadeklarujmy przykładową tablicę składającą się z 5 elementów: int lockers[5]; Deklaracja ta oznacza zarezerwowanie miejsca na 5 zmiennych typu int. Jak widać różnica polega tylko na dodaniu nawiasu kwadratowego po prawej stronie nazwy zmiennej z liczbą 5 oznaczającą liczbę komórek tablicy. Uwaga! Liczba komórek w takiej tablicy (statycznej) jest liczbą stałą i koniecznie musi być znana na etapie kompilacji, czyli w jakiś sposób jawnie zapisana w programie. Istnieje możliwość utworzenia tablicy (dynamicznej) w czasie działania programu. Jeżeli taką deklarację umieścisz "na górze kodu" poza jakąkolwiek funkcją (w tym setup), to domyślnie każdy element tablicy będzie miał wartość 0. Możliwe jest jednak zainicjowanie tablicy własnymi wartościami – należy je podać w nawiasach klamrowych zgodnie z przykładem: int lockers[5] = {1, 0, 1, 1, 1}; Odczyt wartości tablicy Aby upewnić się czy udało się zapisać w ten sposób dane do tablicy, odczytajmy kilka jej elementów: Serial.println(lockers[0]); Serial.println(lockers[1]); Serial.println(lockers[2]); Należy pamiętać, że indeksowanie w tablicach zaczynamy od 0. W wyniku powinniśmy otrzymać: 1 0 1 Jak można zauważyć, wpisywanie kolejnych indeksów jest niepraktyczne i można się przy tym pomylić, użyjmy więc pętli for do wypisania wszystkich elementów: for(int i = 0; i < 5; ++i) Serial.println(lockers[i]); Należy pamiętać, że ostatni indeks 5 elementowej tablicy to 4, a nie 5. Zapis elementów tablicy Podobnie jak w zwykłych zmiennych, w tablicach też można coś zapisać. Wystarczy przypisać wartość do konkretnego elementu: lockers[0] = digitalRead(3); Podobnie jak przy odczytywaniu wartości, również do zapisu można wykorzystać pętlę: for(int i = 0; i < 5; ++i) lockers[i] = 1; Do czego praktycznego można w Arduino użyć tablice? Sprawdźmy to na przykładzie odczytu wejść Arduino. Praktyczny przykład Załóżmy, że do pierwszych 8 pinów Arduino mamy podpięte przyciski. Przyciski te mogą być przełącznikami krańcowymi umieszczonymi w robocie służące do wykrywania kolizji. Chcemy mieć możliwość zapisania odczytów z czujników do osobnych zmiennych. Jak wiemy napisanie kilku prawie identycznych zmiennych mija się z celem, lepiej użyć tablicę: #define SENSORS_COUNT 8 int sensors[SENSORS_COUNT]; void read_all_sensors() { for(int i = 0; i < SENSORS_COUNT; ++i) sensors[i] = digitalRead(i); } Taki zapis wygląda dużo lepiej. Zwracam od razu uwagę na staranne pisanie kodu: dbanie o wcięcia i nawiasy, tworzenie sensownych nazw i unikanie magicznych liczb zastępując je stałymi lub "przezwiskami" (aliasami dyrektywy #define). Indeksy tablicy można potraktować jako kolejne czujniki na obwodzie robota. W razie zmian w sprzęcie (dołożeniu/usunięciu czujników) łatwo można zmienić program, tak aby pasował do nowego układu. Co jednak, gdyby nie dało się tak dobrać wyprowadzeń Arduino, tak by piny zgadzały się z indeksami tablicy? Przyda się tu koncepcja tablicowania stałych. LUT – Lookup Table Tablicowanie zwane po angielsku Lookup Table pozwana na zastąpienie funkcji tablicą. Argumenty funkcji zamieniane są w indeksy tablicy, zaś wyniki funkcji są w wartościach komórek przyporządkowanych do indeksów. Wygląda to podobnie do opisu funkcji nauczanego w szkole: Po lewej stronie są indeksy tablicy, po prawej wartości elementów kryjących się pod tymi indeksami. Jak to może wyglądać w praktyce? Wróćmy do problemu postawionego w poprzednim przykładzie. Załóżmy, że czujniki w robocie są trochę chaotycznie połączone. Zanotowaliśmy połączenia, ale co z tym zrobić? nr czujnika, pin Arduino 0 , 4 1 , 5 2 , 7 3 , 8 4 , 3 5 , 6 6 , 11 7 , 10 Zainicjujmy tablicę przechowującą numery wyprowadzeń Arduino, do których podpięte są czujniki zgodnie z powyższymi notatkami: int sensors_pins[SENSORS_COUNT] = {4, 5, 7, 8, 6, 3, 11, 10}; Czy liczba w nawiasach kwadratowych jest potrzebna? Nie, gdyż kompilator sam by się domyślił jaki jest rozmiar tablicy na podstawie liczby wartości ujętych w klamrach. Jawne wpisanie liczby elementów pomaga uniknąć problemów, bo kompilator sam może wykryć nieścisłość. Jak się później dowiesz może to być też wykorzystane do innych celów. Warto przypomnieć: liczba elementów tablicy statycznej (czyli takiej której rozmiar się nie zmienia) musi być w jakiś sposób znana na etapie kompilacji. Tak przygotowana tablica umożliwia nabudowanie pewnego poziomu abstrakcji, tak by nie posługiwać się fizycznymi wyprowadzeniami, a zacząć posługiwać się indeksami. Teraz aby odczytać dane z czujników wystarczy nieco poprawić poprzednią funkcję: #define SENSORS_COUNT 8 int sensors[SENSORS_COUNT]; int sensors_pins[SENSORS_COUNT] = {4, 5, 7, 8, 6, 3, 11, 10}; void read_all_sensors() { for(int i = 0; i < SENSORS_COUNT; ++i) sensors[i] = digitalRead(sensors_pins[i]); } I gotowe! W zmiennej sensors są odczyty czujników ułożonych zgodnie z fizycznym rozkładem w robocie (a nie narzucone niekoniecznie oczywistymi połączeniami). Zastosowanie tablicowania pomogło naprawić niedopatrzenie i sprawiło, że program jest bardziej elastyczny i szybszy. Zdarza się, że nie możemy użyć pewnych wyprowadzeń Arduino, bo niektóre pełnią specyficzną rolę (np. realizują komunikację UART) – wtedy tablicowanie może okazać się niezbędne. Kapitanie... do brzegu – zadania z kursu Pisałem na wstępie o zadaniach z kursu i obiecuję, że zaraz jedno zrobimy, na początek coś na rozgrzewkę – napiszmy funkcję, która włączy wszystkie diody w linijce LED. Później dojdziemy do tego jak poradzić sobie z dość trudnym przykładem z czujnikiem ultradźwiękowym. Załóżmy, że wyprowadzenia zapisaliśmy w postaci etykiet o nazwach LED_0 – LED_5. Gdyby nie używać tablic to kod wyglądałby jakoś tak: void turn_on_leds() { digitalWrite(LED_0, HIGH); digitalWrite(LED_1, HIGH); digitalWrite(LED_2, HIGH); digitalWrite(LED_3, HIGH); digitalWrite(LED_4, HIGH); digitalWrite(LED_5, HIGH); } Nie jest źle, ale da się lepiej! Używając pętli i tablicy będzie to wyglądać tak: int LED_pins[] = {LED_0, LED_1, LED_2, LED_3, LED_4, LED_5}; void turn_on_leds() { for(int i = 0; i < LEDS_COUNT; i++) digitalWrite(LED_pins[i], HIGH); } Brak mozolnego kopiowania na pewno uprzyjemni pisanie takich kodów Zadanie 2 – prosta animacja Teraz coś nieco trudniejszego – program ma wyświetlać animację, w której zapalane i gaszone są kolejne diody. Tu już bardzo ważne jest poprawne indeksowanie. Bez wykorzystania tablic kod byłby bardzo powtarzalny i nieprzyjemny w modyfikacji. Stosując tablicę i pętlę zajmie to tylko kilka linijek kodu! for(int i = 0; i < LEDS_COUNT; i++) { digitalWrite(LED_pins[i], HIGH); delay(250); digitalWrite(LED_pins[i], LOW); delay(250); } I tyle, kolejne diody są zapalane i gaszone. Kod ten można umieścić wewnątrz pętli loop() aby wykonywał się w nieskończoność zapętlając animację. Zadanie 3 – wyświetlacz słupkowy Wreszcie obiecane zadanie Na tapetę weźmy zadanie 9.3 z kursu Arduno 1 i części dotyczącej ultradźwiękowego czujnika przeszkód, którego teść brzmi: Załóżmy, że doszliśmy do momentu, gdzie mamy wyznaczoną odległość od przeszkody, np. w zmiennej: long dist; // wyrażone w cm i chcemy napisać funkcję wizualizującą wartość na linijce 6 diod. Zadanie rozpocznijmy od deklaracji funkcji: void show_dist_on_bargraph(long distance_cm); Znowu przypominam, aby tworzyć nazwy funkcji i zmiennych, które same z siebie coś mówią po polsku może to być wyzwaniem, bo nie użyjemy polskich znaków, ale po angielsku "feel free". Teraz czas na definicję (opisanie ciała funkcji). Mamy 6 diod więc trzeba jakoś zawęzić nasze wartości. Musimy poczynić pewne założenia: załóżmy, że interesuje nas zakres od 10 do 40 cm, jeżeli wartość jest poza zakresem to ma przyjąć wartości graniczne: 10 albo 40. Do dzieła! Od razu dodajmy kilka stałych, żeby nie używać w kodzie magicznych liczb: #define MIN_DIST 10 #define MAX_DIST 40 void show_dist_on_bargraph(long distance_cm) { if (distance_cm < MIN_DIST) distance_cm = MIN_DIST; if (distance_cm > MAX_DIST) distance_cm = MAX_DIST; int lit_leds = map(distance_cm, MIN_DIST, MAX_DIST, 0, LEDS_COUNT); } Wewnątrz funkcji przekazywana jest domyślnie kopia zmiennej distance_cm (przekazanie przez wartość), więc możemy śmiało ją modyfikować. Uzyskana zmienna lit_leds informuje o indeksie zapalonej diody. Bez znajomości tablic dalsza część kodu może wyglądać w ten sposób: switch(lit_leds) { case 0: digitalWrite(LED_0, HIGH); digitalWrite(LED_1, LOW); digitalWrite(LED_2, LOW); digitalWrite(LED_3, LOW); digitalWrite(LED_4, LOW); digitalWrite(LED_5, LOW); break; case 1: digitalWrite(LED_0, LOW); digitalWrite(LED_1, HIGH); digitalWrite(LED_2, LOW); digitalWrite(LED_3, LOW); digitalWrite(LED_4, LOW); digitalWrite(LED_5, LOW); break; // ... } Już samo dokończenie pisania tego stworka budzi zastrzeżenia... spróbujmy to poprawić! Dysponując tablicą LED_pins zapalenie wybranej diody jest banalnie proste! for(int i = 0; i < LEDS_COUNT; i++) digitalWrite(LED_pins[i], LOW); digitalWrite(LED_pins[lit_leds], HIGH); I zrobione! Odległość jest reprezentowana przez punkt na linijce LED. Takie podejście ma też inną, bardzo ważną zaletę – jest elastyczne. Łatwo można zmienić kod tak by wyświetlać wszystkie LEDy do wybranego punktu włącznie, tzw. bargraph: for(int i = 0; i < LEDS_COUNT; i++) if(i < lit_leds) digitalWrite(LED_pins[i], HIGH); else digitalWrite(LED_pins[i], LOW); // lub for(int i = 0; i < LEDS_COUNT; i++) digitalWrite(LED_pins[i], i < lit_ledds ? HIGH : LOW); Czy nie ładniej? Jeżeli wiemy, że tablica zawiera niezmienne elementy możemy dodać przed typem danych słowo kluczowe const, w ten sposób stworzymy tablicę 6 stałych zabezpieczoną przed modyfikacją: const int LED_pins[] = {LED_0, LED_1, LED_2, LED_3, LED_4, LED_5}; Podsumowanie W tej części przybliżyłem temat tablic. Temat został poruszony od strony praktycznej, więc tę część polecam tym, którzy chcą rozwiązać jakieś zadanie i od razu zobaczyć efekty. W kolejnych częściach przyjrzymy się bardziej wnikliwym tematom.









-

Arduino Tablice w Arduino – #2 – organizacja pamięci
Gieneq opublikował temat w Artykuły użytkowników
Udało Ci się napisać pierwsze programy z wykorzystaniem tablic. Ta część kursu jest bardziej teoretyczna, ale pozwoli Ci zapoznać się z organizacją pamięci w mikrokontrolerze ATmega328P. Dowiesz się o różnych typach zmiennych i gdzie są zapisywane. Przyda się to w nabraniu świadomości jak działa tablica. Spis treści #1 – wstęp i praktyka #2 – organizacja pamięci (czytasz ten artykuł) #3 – tablice w pamięci #4 – tablica jest wskaźnikiem #5 – znaki, cstring #6 – argumenty funkcji #7 – przykład #8 – tablice wielowymiarowe #9 – tablice dynamiczne #10 – zakończenie Język Arduino? Zanim przejdę do sedna sprawy zadam szybkie pytanie: W jakim języku programuje się Arduino? Nie jest to takie oczywiste, bo często spotyka się zapis C/C++ lub informację "dialekt C++". Są to poprawne informacje, ale aby być bardzie szczegółowym, wystarczy sprawdzić co znajduje się w pliku związanym z kompilacją. Zakładając, że używamy Arduino z mikrokontrolerem AVR ATmega328P przechodzimy do katalogu np. C:\Program Files (x86)\Arduino\hardware\arduino\avr i tam szukamy pliku związanego z biblioteką płytek pobranej w menadżerze płytek. Wewnątrz pliku platform.txt znajdziemy blok okomentowany jako domyślne ustawienia, gdzie jedna z linii informuje nas o użyciu C++11: compiler.cpp.flags=-c -g -Os {compiler.warning_flags} -std=gnu++11 -fpermissive -fno-exceptions -ffunction-sections -fdata-sections -fno-threadsafe-statics -Wno-error=narrowing -MMD -flto Podobną informację znajdziemy w logu kompilacji z Arduino IDE. Jeszcze jednym ciekawym sposobem jest wypisanie predefiniowanej nazwy preprocesora __cplusplus identyfikującej standerd C++. Wypisanie liczby 201103 będzie oznaczać C++11: Serial.println(__cplusplus); Wiedząc to możemy być bardzie świadomi co nam wolno, a czego nie Przykładowo, niektórzy zwolennicy czystego C będą na pewno wystrzegać się klas, wydedukowanego typu danych auto, wyrażeń lambda i innych zdobyczy "zinkrementowanego C", na których bazuje część bibliotek Arduino. Na szczęście tablice występują w C więc nie jest to temat dyskusyjny, ale w ramach kursu skorzystamy z innych dobrodziejstw C++11. Szczegóły dotyczące języka i procesu kompilacji dostępne są w osobnej serii artykułów. Optymalizacja Domyślnie w Arduino IDE włączona jest optymalizacja rozmiaru pliku wynikowego -Os. Jest to potrzebne dla mikrokontrolerów o ograniczonych zasobach (ATmega328P posiada tylko 2 kB RAM). Może to jednak powodować problemy zwłaszcza, gdy eksperymentujemy z pamięciĄ, więc tymczasowo polecam wyłączyć optymalizację podmieniając w pliku platform.txt -Os na -O0: Później warto jednak do niej wrócić, optymalizacja rozmiaru -Os może zmniejszyć kod programu nawet o ponad 80%! Organizacja pamięci operacyjnej Aby lepiej zrozumieć dalszą treść, niezbędna jest podstawowa wiedza na temat organizacji pamięci operacyjnej RAM. Jak wiemy mikrokontroler ATmega328P posiada 2 kB pamięci SRAM. Przeglądając 18 stronę dokumentacji znajdziemy diagram: wynika z niego, że pamięć operacyjna zaczyna się w adresie 0x0100, a kończy w adresie 0x08FF. Oznacza to, że mamy do dyspozycji 2048 bajtów pamięci, czyli tyle ile zadeklarował producent: 2 kB (albo bardziej jednoznacznie 2 KiB). Pamięć ta jest dalej dzielona na obszary przeznaczone do konkretnych zadań: Jak możemy zauważyć zaznaczone są tu 4 istotne obszary: sekcja .data, sekcja .bss, sterta (ang. heap), stos (ang. stack) . Dygresja o wskaźnikach Niestety bez tego nie przejdziemy dalej. Wskaźniki straszą początkujących, ale kiedyś trzeba je polubić, bo bez nich za daleko się nie zajedzie. Na szczęście dla potrzeb poznania adresów zmiennych nie będziemy potrzebować zbyt wiele. Wskaźnik na zmienną służy do wskazywania... czyli pokazywania, gdzie w pamięci znajduje się zmienna. Informacja gdzie jest dana zmienna zawarta jest w adresie (typie danych wskaźnika). To wszystko? W zasadzie tak Działa to na podobnej zasadzie co pocztowe dane adresowe. Przykładowo, zdefiniujmy zmienną typu int o nazwie velocity i przypiszmy jej wartość 12: int velocity = 12; // alternatywny zapis: int velocity {12}; To co się wydarzyło to zarezerwowanie w pamięci obszaru, gdzie zapisana została wartość 12. Jak duży to obszar? Z kursu Arduino dowiedziałeś się, że różne typy danych charakteryzują się różną wielkością (liczoną w bajtach) i przeznaczeniem. Zmienne typu int na tym mikrokontrolerze zajmują w pamięci 2 B i można to sprawdzić operatorem sizeof(). Serial.println(sizeof(velocity)); W tym przypadku użyliśmy operatora na zmiennej, ale można też użyć na samym typie danych: Serial.print("Size of char: "); Serial.println(sizeof(char)); Serial.print("Size of int: "); Serial.println(sizeof(int)); Serial.print("Size of long: "); Serial.println(sizeof(long)); Serial.print("Size of float: "); Serial.println(sizeof(float)); W wyniku otrzymamy: Size of char: 1 Size of int: 2 Size of long: 4 Size of float: 4 Dobrze wiemy jak sprawdzić ile pamięci zajmują zmienne, ale gdzie te wskaźniki? Śpieszę z wyjaśnieniem. Przypatrzmy się jeszcze raz zmiennej velocity. Wiemy, że zajmuje 2 B pamięci. Aby uzyskać adres tego obszaru pamięci użyjmy jednoargumentowego operatora & udostępniającego adres: int *address_velocity = &velocity; A co to za stwór po lewej stronie? Tak wygląda typ danych skojarzony ze wskaźnikiem na zmienną int. Choć gwiazdkę stawia się przy nazwie zmiennej to typ danych to int * – tak się przyjęło (choć możesz spotkać też inne zapisy – ze spacją lub bez niej). Przykładowo w środowisku Visual Studio Code dostępne są do wyboru wszystkie sposoby zapisu: Dla innych typów danych będą inne skojarzone z nimi wskaźniki – dla long będzie long *, dla char będzie char * itd. Skoro jest to tylko adres, to dlaczego istnieją osobne typy danych, a nie jeden dla adresów? Dzieje się tak, gdyż wskaźnik niesie też dodatkową informację, np. o tym jak wiele miejsca zajmuje zmienna, co przyda się, gdy wrócimy do tematu tablic. Istnieje uniwersalny wskaźnik, który wskazuje obszar pamięci, ale nie posiada informacji o rozmiarze danych: void *. Aby poznać adres wskaźnika możemy zrzutować go na int i wyświetlić w monitorze portu szeregowego: int velocity = 12; int *address_velocity = &velocity; void setup() { Serial.begin(9600); Serial.print(F("0x")); Serial.println((int)address_velocity, HEX); } Ważne jest aby wypisać liczbę w systemie heksadecymalnym (HEX). W wyniku otrzymamy adres zmiennej: 0x100 Dlaczego akurat taki adres, o tym za chwilę. Na razie zakończę temat wskaźników jeszcze jedną informacją – dysponując wskaźnikiem można uzyskać wartość, na którą wskazuje (obszar pamięci pod adresem wskaźnika). Służy do tego jednoargumentowy operator *, który używamy następująco: Serial.println(*address_velocity); W wyniku z powrotem otrzymamy wartość 12. Kapitanie... do brzegu – obszary pamięci Tak, tak... już już wracam do tematu Wiemy jak sprawdzić adres zmiennej w pamięci i wiemy, że są jakieś obszary pamięci: .data, .bss, heap i stack. Co dokładnie oznaczają? .data – ten obszar pamięci jest na samym początku SRAM i zaczyna się od adresu 0x100 (adres ten zdążyliśmy już zauważyć w zmiennej predkosc). Sekcja .data służy do przechowywania danych statycznych to znaczy takich, które istnieją przez cały czas działania programu. Do tych zmiennych należą: zmienne globalne (te które zainicjalizowaliśmy "na górze" kodu) ale mające wartość inną niż zero (zero jest domyślnie wartością zmiennych niezainicjowanych... tak wiem, pokręcone), zmienne lokalne z słowem kluczowym static, czyli lokalne zmienne statyczne (też w wywołaniach funkcji) z przypisaną niezerową wartością. .bss – kolejny obszar służący do przechowywania danych statycznych ale niezainicjowanych lub posiadających wartość 0. Do tych zmiennych należą: zmienne globalne niezainicjowane lub o wartości 0, statyczne zmienne lokalne niezainicjowane lub o wartości 0. Uwaga! Zmienne statyczne to nie zmienne stałe, ich wartość może się zmieniać. Przykłady zmiennych statycznych: int velocity = 5; // globalna zmienna, zainicjowana, niezerowa – .data int momentum; // globalna zmienna, niezainicjowana, domyślnie wartość 0 – .bss void setup() { // wewnątrz funkcji – zmienne lokalne static int acceleration = 2; // statyczna zmienna lokalna, zainicjowana, niezerowa – .data static int steps_numer; // statyczna zmienna lokalna, niezainicjowana, domyślna wartość 0 – .bss steps_numer = 5; // niezerowa wartość, ale dalej w .bss } Zmienne statyczne mogą się przydać w sytuacji, gdy projektujemy funkcję, która powinna mieć zapamiętany jakiś swój wewnętrzny stan. Zamiast tworzyć zmienną globalną, która byłaby widoczna w wielu miejscach w kodzie i mogłaby być myląca, to można utworzyć lokalną zmienną statyczną, której wartość nie zostanie utracona nawet po wyjściu z funkcji, ale będzie widoczna tylko wewnątrz tej funkcji. Takie zachowanie zmiennej może być zaskakujące, ale dzieje się tak, gdyż adres obszaru pamięci jest na stałe zarezerwowany. Jeżeli utworzymy zmienną jedynie przez definicję, to jej początkowa wartość będzie wynosić 0 lecz przy kolejnych wywołaniach wartość będzie aktualizowana. Przykładowo następujący kod zawiera statyczną zmienną lokalną i intuicja podpowiada, że pewnie jej wartość zostanie utracona po wyjściu z funkcji. void use_counter() { static int count; Serial.print(F("Function used: ")); Serial.print(count++); Serial.println(F(" times.")); } void loop() { use_counter(); delay(1000); } Efekt działania jednak wskazuje, że zmienna nie jest wymazana: Function used: 0 times. Function used: 1 times. Function used: 2 times. Function used: 3 times. Function used: 4 times. Zmienne i funkcje statyczne na pewno spotkasz nieraz w plikach bibliotecznych, gdyż użycie ich poprawia hermetyzację danych (widoczność tylko w ograniczonym zakresie) i wymusza pierwszeństwo przy kompilacji. Nie można tego mylić z metodami statycznymi klas, gdzie static oznacza przynależność do klasy, a nie poszczególnych instancji. stack – specjalnie zmieniłem kolejność, bo stos jest bardziej intuicyjny. Jest to obszar pamięci dynamicznej (czyli takiej która jest zapełniania i zwalniana w czasie działania programu) zaczynający się od końca RAM i rosnący w stronę początku pamięci. Zapełnianie stosu następuje automatycznie gdy: wywoływane są funkcje, tworzone są zmienne lokalne. Dane są dopisywane jedna po drugiej, stąd są one ciasno upchane (nie posiada luk). Posługując się przykładem z ilustracji jest to podobne do poukładanej ścianki narzędziowej, gdzie pobieramy i odkładamy narzędzia wiszące obok siebie. Zwalnianie stosu następuje automatycznie wraz z zakończeniem wywołania funkcji. Przykład zmiennej zapisanej na stosie: void setup() { int local_variable = 5; } Uwaga! Zmienne lokalne zapisane na stosie domyślnie mają wartość losową. Dzieje się dlatego, że przy większej liczbie danych (np. w pętli) ustawianie każdorazowo wartości na 0 pogarszałoby czas wykonania. Przykładowo: int local_variable; Serial.print(F("0x")); Serial.print((int)&local_variable, HEX); Serial.print(F(", value: ")); Serial.println(local_variable); Jak widać adres zmiennej jest bardzo blisko końca: 0x8FF i wskazywana wartość jest zupełnie przypadkowa: 0x8F6, value: -29696 heap – sterta to również obszar pamięci dynamicznej ale przeznaczony do przechowywania danych, gdy tworzone są nowe obiekty (alokowana pamięć) w czasie działania programu. Dokonuje się tego: używając operatora new, który przydziela pamięć do obiektu lub tablicy, alokując blok pamięci funkcją malloc(). Różnica polega na tym, że obiekty te tworzy programista – dodawanie i ściąganie obiektów ze starty nie jest zautomatyzowane. Sterta jest bardziej chaotyczna, może posiadać luki (można zwolnić dowolny blok pamięci pozostawiając dziurę). Choć możliwa jest większa swoboda (np. rozszerzenie obszaru pamięci w tablicy dynamicznej) to może to wiązać się, z przeniesieniem bloku pamięci. W ogólności dostęp jest wolniejszy od obiektów ze stosu. Posługując się przykładem stołu warsztatowego, jest to blat na którym sporo się dzieje – w różnych miejscach dokładane i przenoszone są materiały i narzędzia. Więcej na temat zagrożeń używania pamięci dynamicznej w części kurs o tablicach znaków. Dobrym podsumowaniem będzie analiza adresów zmiennych z przykładu: int zm_glob_niezer = 12; int zm_glob_zer = 0; int zm_glob_niezainc; static int zm_glob_niezer_static = 18; static int zm_glob_zer_static = 0; void setup() { int zm_lok_niezer = 33; int zm_lok_niezain; static int zm_lok_zer_stat = 6; static int zm_lok_niezain_stat; String *napis = new String("3333"); Serial.begin(9600); Serial.print(F("0x")); Serial.print((int)&zm_glob_niezer, HEX); Serial.print(F(" - zm_glob_niezer, ")); Serial.println(zm_glob_niezer); Serial.print(F("0x")); Serial.print((int)&zm_glob_zer, HEX); Serial.print(F(" - zm_glob_zer, ")); Serial.println(zm_glob_zer); Serial.print(F("0x")); Serial.print((int)&zm_glob_niezainc, HEX); Serial.print(F(" - zm_glob_niezainc, ")); Serial.println(zm_glob_niezainc); Serial.print(F("0x")); Serial.print((int)&zm_glob_niezer_static, HEX); Serial.print(F(" - zm_glob_niezer_static, ")); Serial.println(zm_glob_niezer_static); Serial.print(F("0x")); Serial.print((int)&zm_glob_zer_static, HEX); Serial.print(F(" - zm_glob_zer_static, ")); Serial.println(zm_glob_zer_static); Serial.print(F("0x")); Serial.print((int)&zm_lok_niezer, HEX); Serial.print(F(" - zm_lok_niezer, ")); Serial.println(zm_lok_niezer); Serial.print(F("0x")); Serial.print((int)&zm_lok_niezain, HEX); Serial.print(F(" - zm_lok_niezain, ")); Serial.println(zm_lok_niezain); Serial.print(F("0x")); Serial.print((int)&zm_lok_zer_stat, HEX); Serial.print(F(" - zm_lok_zer_stat, ")); Serial.println(zm_lok_zer_stat); Serial.print(F("0x")); Serial.print((int)&zm_lok_niezain_stat, HEX); Serial.print(F(" - zm_lok_niezain_stat, ")); Serial.println(zm_lok_niezain_stat); Serial.print(F("0x")); Serial.print((int)napis, HEX); Serial.print(F(" - napis, ")); Serial.println(*napis); } void loop() { } W wyniku otrzymamy coś takiego: 0x100 - zm_glob_niezer, 12 0x1A4 - zm_glob_zer, 0 0x1A6 - zm_glob_niezainc, 0 0x102 - zm_glob_niezer_static, 18 0x1A8 - zm_glob_zer_static, 0 0x8F2 - zm_lok_niezer, 33 0x8F4 - zm_lok_niezain, -26879 0x104 - zm_lok_zer_stat, 6 0x1AA - zm_lok_niezain_stat, 0 0x25B - napis, 3333 Widzimy wyraźnie adresy zainicjowanych danych statycznych (wartości bliskie 0x100). Nieco większe wartości przyjmują dane z obszaru niezainicjowanych danych statycznych (.bss). Następnie widoczny jest spory skok adresowania w przypadku zmiennych lokalnych umieszczonych na stosie (w tym tych niezainicjowanych), gdzie została odczytana losowa wartość. Na sam koniec została zaalokowana pamięć w obszarze sterty przy pomocy operatora new, które mają adresy większe od tych z .bss. Do tego czym jest operator new jeszcze kiedyś wrócimy. Ląd na horyzoncie – gdzie te tablice? Dygresja od dygresji ale bez tego nie da się omówić tematu Do czego to wszystko ma się przydać? W kolejnej części zostanie omówiony sposób tworzenia tablic (statycznych), ale tym razem ze świadomością co się dokładnie dzieje, a gdy dojdziemy do tematu alokacji dynamicznej, tworzenia obiektów to zrozumiemy dlaczego ta sterta jest trochę niebezpieczna. Oczywiście, bez tego da się żyć, dlatego też pierwsza część jest typowo praktyczna. Sam przeżyłem bez znajomości tego tematu kilka lat, napisałem w tym czasie wiele programów, brałem udział nawet w konkurach z algorytmiki i coś wygrałem! Ale apetyt rośnie w miarę jedzenia i warto kiedyś pochylić się nad tym tematem








-
Arduino Tablice w Arduino – #4 – tablica jest wskaźnikiem
Gieneq opublikował temat w Artykuły użytkowników
W ostatniej części omówiłem typowe sposoby tworzenia tablic i skończyliśmy na omówieniu koncepcji skakania pomiędzy zmiennymi posługując się operacjami na wskaźnikach. W tej części wykorzystamy tę koncepcję i potraktujemy tablicę jako wskaźnik, dzięki czemu możliwe będzie przyspieszenie niektórych operacji. Spis treści #1 – wstęp i praktyka #2 – organizacja pamięci #3 – tablice w pamięci #4 – tablica jest wskaźnikiem (czytasz ten artykuł) #5 – znaki, cstring #6 – argumenty funkcji #7 – przykład #8 – tablice wielowymiarowe #9 – tablice dynamiczne #10 – zakończenie Adres tablicy W jednym z ostatnio omawianych przykładów, wypisaliśmy adresy elementów tablicy: #define LOCKERS_COUNT 5 int lockers[LOCKERS_COUNT] = {1, 0, 1}; void setup() { Serial.begin(9600); for (int i = 0; i < LOCKERS_COUNT; i++) { Serial.print(F("0x")); Serial.println((int)&lockers[i], HEX); } } W wyniku możemy otrzymać takie dane: 0x100 0x102 0x104 0x106 0x108 Nigdzie jednak nie podaliśmy jaki jest adres samej tablicy, dlatego pora na najważniejszą informację dotycząca tablic: Nazwa tablicy jest zarazem adresem jej początkowego (zerowego) elementu. Tablica nie jest typem danych wiec nie ma adresu, jej adresem jest adres zerowego elementu, a nazwa jako adres obszaru pamięci może być stosowana wymiennie. W praktyce oznacza to że oba zapisy są poprawne: int *addr_1 = lockers; int *addr_2 = &lockers[0]; Można sprawdzić czy adresy są faktycznie takie same wypisując je: 0x100 0x100 To samo a jednak różne Czy skoro uzyskaliśmy ten sam adres w pamięci, czy można dojść do wniosku, że nazwa tablicy i wskaźnik są tym samym? Choć w obu przypadkach uzyskamy informację o adresie, to nazwa tablicy jest nieco bogatsza w informacje. Prześledźmy to na przykładzie, tylko tym razem użyjemy tablicy 1 B zmiennych char: char tab[5] = {'a', 'b', 'c', 'd', 'e'}; void setup() { Serial.begin(9600); char *addr = tab; Serial.print(F("Sizeof(tab): ")); Serial.println(sizeof(tab)); Serial.print(F("Sizeof(addr): ")); Serial.println(sizeof(addr)); Serial.print(F("Sizeof(&tab[0]): ")); Serial.println(sizeof(&tab[0])); Serial.print(F("Sizeof(tab[0]): ")); Serial.println(sizeof(tab[0])); } Użyty tu operator sizeof() zazwyczaj działa na zmiennej lub jej typie (jawnie wpisanej nazwie typu danych) i zwraca rozmiar zmiennej. Jednak w przypadku tablicy jest nieco inaczej, bo operator zwróci rozmiar obszaru zajmowanego przez tablicę: Sizeof(tab): 5 Sizeof(addr): 2 Sizeof(&tab[0]): 2 Sizeof(tab[0]): 1 Uzyskana wartość 5 oznacza, że tablica 1 B elementów int zajmuje 5 × 1 B pamięci. Zatem pierwsza różnica polega na tym jakie są dodatkowe informacje. Tablica niesie informację o całym obszarze pamięci, a wskaźnik niesie informację tylko o adresie, stąd używając operatora sizeof() uzyskaliśmy rozmiar ale nie wskazywanej wartości, tylko zmiennej typu danych wskaźnika – adres 2 B (16 bitowy) – w końcu adres musi być jakoś przechowany w pamięci. Dysponując tablicą jesteśmy w stanie uzyskać rozmiar bloku pamięci, rozmiar typu danych i nawet odtworzyć rozmiar tablicy wyrażony w liczbie elementów: int tab[] = {1, 2, 3, 4, 5}; int tab_len = sizeof(tab) / sizeof(tab[0]); // wynik 5 lub posługując się makrem: #define ARRLEN(x) (sizeof(x)/sizeof(x[0])) int tab_len = ARRLEN(tab); W prostych zadaniach najpewniej rozmiar tablicy (zwłaszcza statycznej) będzie znany więc takie obliczenia będą niepotrzebne. Jest to jednak dobre ćwiczenie na użycie operatora sizeof(), który może się przydać w zadaniach, gdzie trzeba wyznaczyć rozmiar bloku pamięci. Przykładem może być fragment funkcji z biblioteki Arduino: size_t Print::printNumber(unsigned long n, uint8_t base) { char buf[8 * sizeof(long) + 1]; // Assumes 8-bit chars plus zero byte. char *str = &buf[sizeof(buf) - 1]; ... Jak widać operator sizeof() pozwala wyznaczyć rozmiar bufora zwalniając programistę z wiedzy o rozmiarze typu danych long. Innym przykładem użycia może być złożony obiekt jakim jest klasa wektor (taka nieco lepsza tablica dynamiczna). Nie dość, że jako szablon (ang. template) może przyjąć dowolny typ danych (w tym obiekty klas) to może zmieniać swój rozmiar w czasie działania. Implementacja tak złożonego obiektu nie mogłaby obyć się bez tej wiedzy. Druga różnica tyczy się próby zmiany adresu. Jak przekonaliśmy się w poprzedniej części da się dodać coś do wskaźnika i w konsekwencji odwołać się do innego adresu. Mając wskaźnik uzyskany z tablicy jest to możliwe: int *addr = tab; addr++; //ok Ale próbując tego samego na tablicy już się nie uda: tab++; // błąd Dzieje się tak ponieważ spowodowałoby to utratę informacji o faktycznym adresie tablicy. Zatem wracając do regułki z początku można ją wzbogacić uzyskując trafniejszą definicję: Nazwa tablicy jest zarazem niezmiennym adresem jej początkowego (zerowego) elementu. Warto znać różne sposoby. Nawet jeżeli sami ich tak szybko nie użyjemy, to przeglądając kody programów bibliotek na pewno trafimy na takie przypadki. Dlatego teraz przećwiczymy alternatywny sposób poruszania się po tablicach – przy pomocy adresów. Indeksowanie bez nawiasów Skoro tablica jest dobrodziejstwem, w którym możemy śmiało skakać wskaźnikami bez obawy, że (w obrębie tablicy) coś naruszymy to warto z tego skorzystać. Zdefiniujmy więc tablicę, adres do niej i przy pomocy pętli prześledźmy jej wartości: int tab[5] = {1, 2, 3, 4, 5}; int *addr = tab; void setup() { Serial.begin(9600); for (int i = 0; i < 5; i++) Serial.println(*addr++); } W wyniku otrzymamy to co podaliśmy przy inicjalizacji tablicy: 1 2 3 4 5 Przy inicjalizacji tablicy co prawda posługujemy się nawiasami kwadratowymi (choć da się inaczej), ale reszta jest już inna. Co właściwie oznacza ten zapis? Mamy tu pewne uproszczenie – w jednej linii realizujemy pobranie wskazywanej wartości i operację postinkrementacji (zwiększenie zmiennej, ale dopiero po odczytaniu jej wartości). Używając notacji z nawiasami kwadratowymi można posłużyć się zmienną i, czy w tym zapisie jest to możliwe? Tak, jak najbardziej: for (int i = 0; i < 5; i++) Serial.println(*(tab + i)); Dodanie czegoś do tablicy nie narusza jej niezmiennego adresu, zwracany wynik jest nowym adresem, z którego odczytujemy wskazywaną wartość. Na razie wygląda to jakbyśmy uczyli się dokładnie tego samego zapisu ale w trochę przekombinowany sposób. Okazuje się, że nie jest on taki wcale zbędny. Są sytuacje w których będzie on łatwiejszy i szybszy od odpowiednika z typowymi tablicami, zwłaszcza gdy będziemy chcieli odwołać się do pewnych obszarów tablicy i wykonać na nich działania. Dygresja o dodawaniu (i odejmowaniu też) Jak można było zauważyć posłużyłem się pojęciem postinkrementacji. Sama inkrementacja, czyli zwiększenie zmiennej o 1 jest szerszym pojęciem pod którym kryją się 2 operacje o nieco innym sposobie dojścia do tego samego efektu: preinkrementacja i postinkrementacja: preinkrementacja (++v) dokonuje bezpośredniego zwiększenia zmiennej, w efekcie przyległe operacje działają na zwiększonej zmiennej, postinkrementacja (v++) dokonuje zwiększenia zmiennej, ale na tymczasowej kopii, w efekcie przyległe operacje działają na wartości oryginalnej (niezwiększonej), a po zakończeniu działań zmienna jest modyfikowana. Do czego to może służyć? Tak jak w poprzednim przykładzie, świadomie wypisaliśmy zmienną, aby w tej samej linii ją zwiększyć, ale dopiero po wykonaniu przyległej operacji dereferencji *. Poza kwestią funkcjonalną, operacje te różnią się szybkością wykonania, ta pierwsza z racji bezpośredniego działania na pamięci jest szybsza. Czy zatem pisanie ++i jest szybsze niż i++ w pętli for? Nie... jeżeli mamy włączoną optymalizację. W przypadku pętli for kolejność inkrementacji nie jest tak istotna, bo nie odwołujemy się podczas niej do wartości. Kompilator zoptymalizuje te działanie do szybszej wersji. Podobnie samodzielna operacja postinkrementacji zostanie zoptymalizowana do szybszego wariantu. Oczywiście na podobnej zasadzie działają operacje dekrementacji (zmniejszania). Porównanie wskaźników Skoro wiemy, że wskaźnik jest w 8 bitowych mikrokontrolerach AVR liczbą 16 bitową, to pewnie inne operacje na wskaźnikach też są możliwe. Bez problemu możemy użyć operatora porównania == a także różne warianty operatorów nierówności. Prześledźmy to na przykładzie: int tab[5] = {1, 2, 3, 4, 5}; int *addr = tab; void setup() { Serial.begin(9600); Serial.println(tab == &tab[0] ? F("Equal") : F("Different")); for (int *addr = tab; addr < &tab[4]; addr++) Serial.println(*addr); } W wyniku otrzymamy: Equal 1 2 3 4 W pierwszej linii wypisaliśmy wynik porównania dwóch wskaźników i jak już wiemy wskaźnik od nazwy tablicy i wskaźnik elementu zerowego są sobie równe. W pętli for przeprowadziliśmy iterację posługując się wskaźnikiem w miejscu typowej zmiennej int i. Jak widać przy każdym obiegu pętli następuje sprawdzenie, czy adres jest mniejszy od adresu ostatniego elementu w tablicy. Stąd wniosek – adresy można ze sobą porównywać. Posługując się przykładem to tak jakbyśmy szli wzdłuż ulicy i szukali konkretnego budynku. Widząc budynki o niższych adresach wiemy, że powinniśmy iść zgodnie z rosnącymi adresami i odwrotnie. Podsumowanie W tej części dotknęliśmy bardzo ciekawy temat, który często budzi strach u początkujących programistów. Przemieszanie gwiazdek, ampersandów, plusów i minusów już nie powinien stanowić problemu. W kolejnych częściach przejdziemy do bardzo popularnego zastosowania tablic – przechowywania ciągów znaków (napisów) czyli tzw. stringów.




-
W tej części kursu wracamy do tematu tablic, ale tym razem na dobre Wiemy już jak mniej więcej wygląda tablica (jednowymiarowa tablica statyczna) oraz jak wygląda pamięć operacyjna. Tym razem przypatrzymy się bliżej tworzeniu i inicjalizacji elementów tablicy oraz poruszaniu się w pamięci. Spis treści #1 – wstęp i praktyka #2 – organizacja pamięci #3 – tablice w pamięci (czytasz ten artykuł) #4 – tablica jest wskaźnikiem #5 – znaki, cstring #6 – argumenty funkcji #7 – przykład #8 – tablice wielowymiarowe #9 – tablice dynamiczne #10 – zakończenie Dlaczego statyczna? Jak już wiemy istnieją dane statyczne – takie które zostały "powołane do życia" na etapie kompilacji i mają stałe miejsce w pamięci. Można tu wyróżnić zmienne globalne i zmienne z dopiskiem (słowem kluczowym/specyfikatorem) static. Jest to tylko informacja dla kompilatora ile bajtów danych powinien (zarezerwować) zaalokować w pamięci. Statycznie nie znaczy stałe – zmienne można nadpisywać (nie jest to specyfikator const czy constexpr). Są to bardzo ważne informacje, ponieważ jak wiemy tablica służy do przechowywania danych tego samego typu, ale mogą mieć różną liczbie elementów. Skoro wiec kompilator życzy sobie mieć podany rozmiar obszaru pamięci jaki ma przydzielić określonym danym statycznym, to dlatego musimy w jakiś sposób podać informację ile ma być tych danych. Możemy tego dokonać na kilka sposobów. Tworzenie tablic statycznych W jednym z przykładów pokazałem zapis: int lockers[5]; Wiemy, że wpisywanie magicznych liczb nie jest dobrą praktyką, co więc powinno się tu znaleźć? Coś co znane jest na etapie kompilacji. Można tu więc podać wyrażenie, które utworzy dla nas preprocesor (działający przed kompilacją na kodzie źródłowy). Dyrektywą #define utworzy alias na ciąg znaków (tzw. tokenów) LOCKERS_COUNT. Wystąpienia aliasu zostaną przetłumaczone na token 5 i wstawione w kod źródłowy, który zostanie przekazany do kompilacji. #define LOCKERS_COUNT 5 int lockers[LOCKERS_COUNT]; Takie podejście przez kompilator jest widziane tak samo jak używanie magicznych liczb, ale na etapie pisania kodu poprawia czytelność i jest wspierane prze środowiska programistyczne (IDE). Użycie dyrektywy zamiast zmiennej pozwala uniknąć alokacji pamięci operacyjnej. Tak przygotowany alias możemy używać w różnych miejscach kodu, np. w pętli: for(int i = 0; i < LOCKERS_COUNT; i++) { Serial.print(F("Locker ")); Serial.print(i); if(lockers[i]) Serial.println(F(" is open.")); else Serial.println(F(" is closed.")); } Efekt działania preprocesora widoczny jest w pliku wynikowym w katalogu preproc, który znajdziemy w tymczasowym katalogu roboczym Ardunio IDE – jego ścieżkę znajdziemy przeglądając log kompilacji. Innym sposobem zadeklarowania tablicy jest użycie zmiennej wewnątrz nawiasów kwadratowych. Wymaga to tylko zapewnienia kompilatora, że to co tam wpisujemy jest stałe. Można tego dokonać dopisując przed typem danych zmiennej słowo kluczowe... const? Niekoniecznie... dlatego, że specyfikator const nie daje gwarancji, że w czasie kompilacji wartość będzie stała. Jak to? Prześledźmy przykład: void setup() { const int sensor_value = digitalRead(0); sensor_value = LOW; } Pierwsza linia jest w porządku – wartość raz ustalona, nie ulegnie zmianie, acz zmienna zapisana na stosie (adres 0x8F6). Druga linia spowoduje błąd kompilacji, bo zgodnie z prawdą raz ustalonej zmiennej const nie możemy zmienić. A czy da się użyć tej zmiennej do stworzenia tablicy statycznej? Da się: void setup() { const int sensor_value = digitalRead(0); int suspicious_tab[sensor_value]; } Nie jest to jednak poprawne, gdyż patrząc na ten kod nie da się stwierdzić jaki rozmiar ma tablica na etapie kompilacji. To dlaczego kompilacja przeszła? Bo aż do wersji C++11 był to dopuszczony sposób o ile był on używany z głową (podobnie jak nikt nie zabroni sięgnąć do pamięci poza ustalonym obszarem tablicy). W C++11 doszedł nowy specyfikator, który tworzy bardziej stałe... stałe, jest nim constexpr. Tego słowa kluczowego niestety nie znajdziemy wśród typowej składni Arduino IDE (znajdziemy np. w Visual Studio Code), ale działa i nie da się go oszukać, bo wartość constexpr musi być znana na etapie kompilacji: void setup() { constexpr int really_constant_lenght = 5; int tab[really_constant_lenght]; } Takie coś uda się na pewno. Pamiętajmy, że choć constexpr jest stałe to nie jest niezniszczalne - ten egzemplarz został zapisany na stosie więc po opuszczeniu funkcji setup() zostanie usunięty. Inicjalizacja tablic statycznych Podobnie jak zwykłe zmienne, tablice też podlegają inicjalizacji wartościami początkowymi co pobieżnie sprawdziliśmy w pierwszej części kursu. Jeżeli tablica jest widoczna globalnie lub jest statyczna (tak zgadza się statyczna tablica statyczna) to zostanie zapisana w bloku pamięci statycznej. To czy dane tablicy trafią do sekcji .data czy .bss zależy od tego czy zostanie przez nas zainicjowana. Zasada jest prosta: Jeżeli nie zainicjowaliśmy żadnego elementu globalnej/statycznej tablicy to zostanie zarezerwowany blok pamięci w .bss. Przykład: int lockers[LOCKERS_COUNT]; Jak wiemy do inicjalizacji możemy wykorzystać nawiasy klamrowe. Co ciekawe, nie musimy w takim przypadku inicjalizować wszystkich wartości, bo jeżeli mamy tablicę globalną/statyczną to pozostałe elementy (zgodnie z zadanym rozmiarem tablicy) otrzymają domyślne 0: int lockers[LOCKERS_COUNT] = {1, 0, 1}; // wartości tablicy: {1, 0, 1, 0, 0} Taka tablica trafi (zostanie zaalokowany obszar) w sekcji .data. W ramach ciekawostki – znak równości można pominąć (podobnie co z przypadku pojedynczej zmiennej): int lockers[LOCKERS_COUNT] {1, 0, 1}; // wartości tablicy: {1, 0, 1, 0, 0} A co z tablicami lokalnymi? Zasada jest ta sama co w przypadku zmiennych lokalnych. Tak naprawdę tablica to taka bardziej złożona zmienna obejmująca dużo więcej miejsca i posiadająca pewną specyficzną cechę - możliwość indeksowania. Tablica w pamięci Dobrze, a jak wygląda pamięć zajęta przez tablicę? Na wstępie do kursu wspomniałem, że wrócimy do podanej definicji tablicy, gdyż nie omówiłem na czym polega ciągłość bloku pamięci który zajmuje. Jako, że dane w tablicy są usystematyzowane i możliwe jest sprawne przechodzenie pomiędzy jej elementami, to też miejsce w pamięci jest zajęte w usystematyzowany sposób. Każda z wartości ma swój adres, który możemy uzyskać w taki sam sposób jak w przypadku zwykłej zmiennej: int *address_locker_3 = &lockers[3]; Zapis po lewej stronie już widzieliśmy. Wyrażenie po prawej stronie też jest znane, tylko że w miejsce nazwy zwykłej zmiennej podajemy wybrany element tablicy (tu 3). Wiedząc to spróbujmy wypisać wszystkie adresy i wartości tablicy z przykładu: int lockers[LOCKERS_COUNT] = {1, 0, 1}; void setup() { Serial.begin(9600); for (int i = 0; i < LOCKERS_COUNT; i++) { Serial.print(F("0x")); Serial.print((int)&lockers[i], HEX); Serial.print(F(" locker: ")); Serial.println(lockers[i]); } } Otrzymamy takie wyniki: 0x102 locker: 1 0x104 locker: 0 0x106 locker: 1 0x108 locker: 0 0x10A locker: 0 Jak widać elementy tablicy zaczynają się od adresu 0x102 i są zwiększane co 2 B (tyle ile zajmuje typ danych int). Dlatego możliwa jest bezpieczna iteracja. W bloku pamięci tablicy nie ma żadnych przerw. A jak wygląda sytuacja, w której wyjdziemy poza tablicę? Co się wtedy stanie? Dla przedstawienia efektu po tablicy utwórzmy zmienną w sekcji .data: int lockers[LOCKERS_COUNT] = {1, 0, 1}; int notimportant = (1<<15) - 1; // maksymalna wartość int (ze znakiem) void setup() { Serial.begin(9600); for (int i = 0; i < LOCKERS_COUNT + 1; i++) { Serial.print(F("0x")); Serial.print((int)&lockers[i], HEX); Serial.print(F(" locker: ")); Serial.println(lockers[i]); } } Zgodnie z oczekiwaniem kod się skompilował, bezbłędnie uruchomił i odczytaliśmy wartość sąsiedniego bloku pamięci (akurat udało się pobrać wartość zmiennej): 0x102 locker: 1 0x104 locker: 0 0x106 locker: 1 0x108 locker: 0 0x10A locker: 0 0x10C locker: 32767 Widzimy zatem jak niebezpieczne jest złe indeksowanie. Dobrze, że tylko odczytywaliśmy dane i udało się trafić na ten sam typ danych, gorzej gdybyśmy chcieli coś zapisać do takiej "tablicy". Dygresja o skakaniu Z powyższego przykładu, choć pokazującego błędne zachowanie można wyciągnąć wniosek – możliwe jest skakanie pomiędzy obszarami pamięci – udało się wyskoczyć z tablicy i przejść do innej zmiennej. Czy gdybyśmy zamiast tablicy mieli kilka zmiennych, czy możliwe byłoby przechodzenie pomiędzy nimi? Załóżmy że zmienne te są zaalokowane w kolejności. Bierzemy adres pierwszej z nich: int variable_1 = 6; int variable_2 = 123; int variable_3 = -555; int *var_1_address = &variable_1; Będzie to adres 0x100, kolejny będzie o 2 B większy więc będzie to 0x102, kolejny 0x104. Wydaje się, że wystarczy dodać do pierwszego adresu 2 i gotowe. Niekoniecznie... int variable_1 = 6; int variable_2 = 123; int variable_3 = -555; int *var_1_address = &variable_1; int *var_2_address = var_1_address + 2; void setup() { Serial.begin(9600); Serial.print(F("0x")); Serial.print((int)&variable_1, HEX); Serial.print(F(", variable_1: ")); Serial.println(variable_1); Serial.print(F("0x")); Serial.print((int)&variable_2, HEX); Serial.print(F(", variable_2: ")); Serial.println(variable_2); Serial.print(F("0x")); Serial.print((int)&variable_3, HEX); Serial.print(F(", variable_3: ")); Serial.println(variable_3); Serial.print(F("0x")); Serial.print((int)var_1_address, HEX); Serial.print(F(", var_1_address: ")); Serial.println(*var_1_address); Serial.print(F("0x")); Serial.print((int)var_2_address, HEX); Serial.print(F(", var_2_address: ")); Serial.println(*var_2_address); } void loop() { } Zwróćmy uwagę na ostatnią linię w wyniku ze zmienną var_2_address: 0x100, variable_1: 6 0x102, variable_2: 123 0x104, variable_3: -555 0x100, var_1_address: 6 0x104, var_2_address: -555 Nie tak miało być, ale widać że dodawanie działa! W poprzednim rozdziale wspomniałem, że wskaźnik niesie informację o wielkości obszaru pamięci, więc to że int zajmuje 2 B jest zachowane. Dodając coś do adresu zwiększamy go nie o liczbę bajtów tylko o liczbę związaną z obszarem zajmowanym przez ten typ danych. Dlatego wskaźnik zazwyczaj jest skojarzony z konkretnym typem danych. Przykładowo, utwórzmy zmienną int (2 B) i dalej 2 zmienne char (2 x 1 B) i odczytajmy wartość używając wskaźnika na int. Wartości wypiszmy w systemie szesnastkowym: int variable_1 = 6; char variable_2 = 33; // 0x21 char variable_3 = 76; // 0x4C int *var_1_address = &variable_1; int *var_2_address = var_1_address + 1; void setup() { Serial.begin(9600); Serial.print(F("0x")); Serial.print((int)&variable_1, HEX); Serial.print(F(", variable_1: ")); Serial.println(variable_1, HEX); Serial.print(F("0x")); Serial.print((int)&variable_2, HEX); Serial.print(F(", variable_2: ")); Serial.println(variable_2, HEX); Serial.print(F("0x")); Serial.print((int)&variable_3, HEX); Serial.print(F(", variable_3: ")); Serial.println(variable_3, HEX); Serial.print(F("0x")); Serial.print((int)var_1_address, HEX); Serial.print(F(", var_1_address: ")); Serial.println(*var_1_address, HEX); Serial.print(F("0x")); Serial.print((int)var_2_address, HEX); Serial.print(F(", var_2_address: ")); Serial.println(*var_2_address, HEX); } Co prawda odczytaliśmy kolejny adres 0x102 (ostatnia linia) ale nie taka wartość miała być: 0x100, variable_1: 6 0x102, variable_2: 21 0x103, variable_3: 4C 0x100, var_1_address: 6 0x102, var_2_address: 4C21 Jak widać sąsiednie bajty zostały złączone tak by obszar pamięci pasował do typu danych int. Sytuację można poprawić zmieniając typ danych wskaźnika na ten skojarzony z typem char, oraz rzutując wynik operacji dodawania: int *var_1_address = &variable_1; char *var_2_address = (char*)(var_1_address + 1); Jak można zauważyć przesunięcie adresu jest zgodne z typem danych int, a odczytanie wartości odbywa się zgodnie z char: 0x100, variable_1: 6 0x102, variable_2: 21 0x103, variable_3: 4C 0x100, var_1_address: 6 0x102, var_2_address: 21 "Ciekawe... a do czego mi to potrzebne, skoro tak nie powinno się poruszać pomiędzy zmiennymi?" – taka myśl może się zrodzić, bo wielokrotnie wspominałem, że takie skanie jest dozwolone tylko w obrębie tablic i właśnie tam wykorzystamy podobny mechanizm. Znajdując się w ostatniej scenie typowego cliffhangera zapowiem, że w kolejnej części przybliżę temat tablic, w których nie będziemy posługiwać się nawiasami kwadratowymi do poruszania siępo elementach. W tej części przybliżyłem różne sposoby tworzenia tablic statycznych oraz alokacji w pamięci. Oczywiście tablice statyczne to nie jedyny rodzaj tablic wiec w przyszłości wrócimy do tego tematu.






-
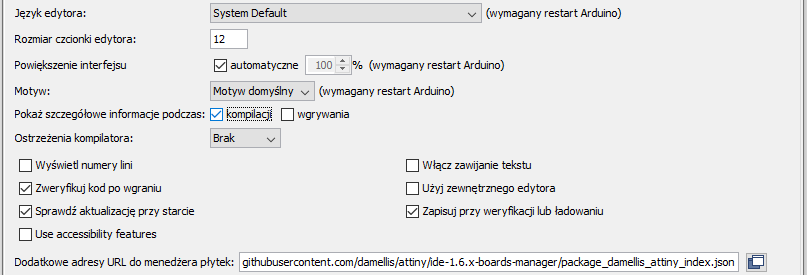
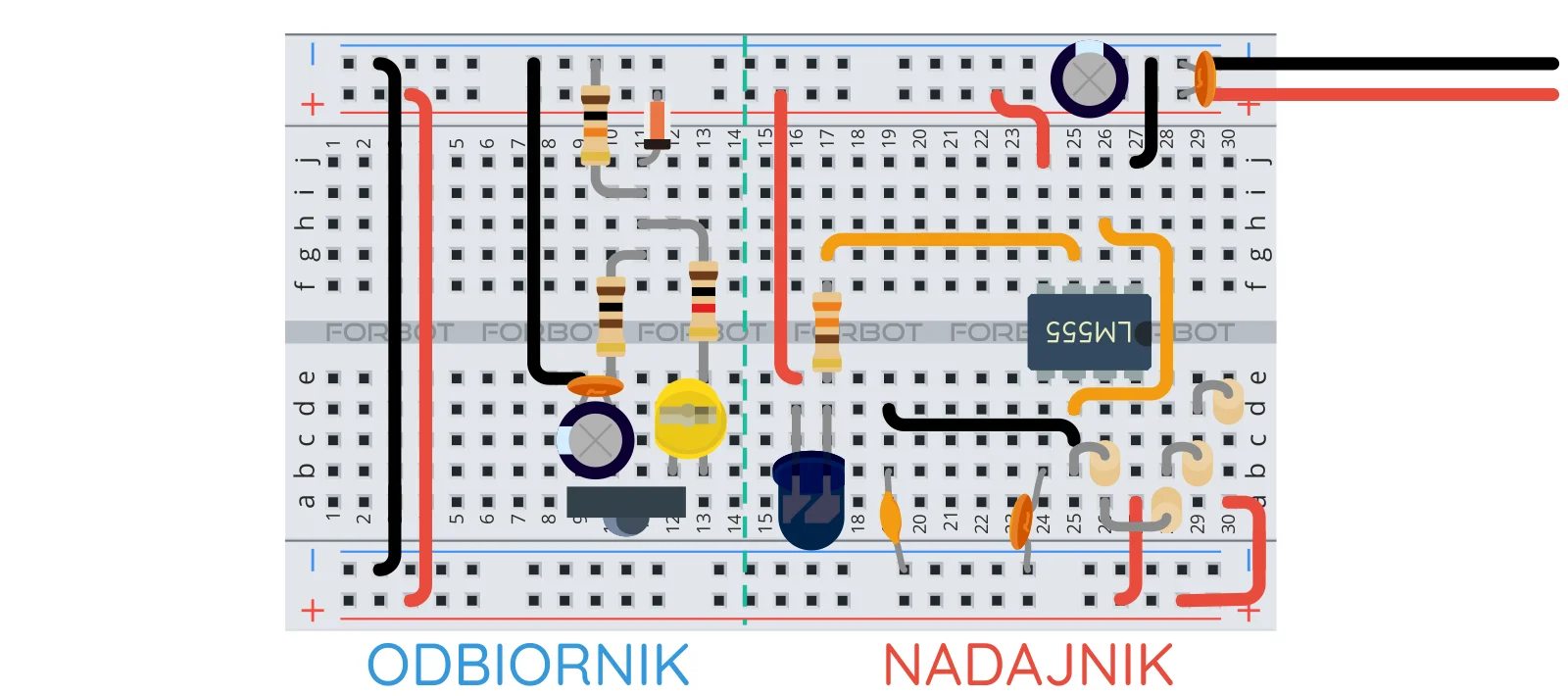
Zarys treści rozwiązanie problemów z bibliotekami rozwiązanie częstych problemów niepoprawnej kompilacji sposób szukania przyczyny braku kompilacji lub niepoprawnego działania sprzętu "debugowanie" z użyciem portu szeregowego i flag LED przykład bezpiecznej metody testowania i nabudowywania układu podstawowe narzędzia do testowania układu sposób zadawania pytań na forum (umieszczanie ilustracji i kodu źródłowego) Wstęp Z Arduino można wykonać wiele ciekawych projektów i bywa, że początkujący po zakupie Arduino dla testu wgrywa przykłady z Arduino IDE i gdy wszystko działa jak należy, idzie krok dalej i pyta wujka Googla jak zrealizować swój wymarzony projekt. Dość szybko trafia na poradnik, pobiera zipa z kodem, wgrywa i... właśnie. Albo kod się nie kompiluje, albo kod po wgraniu nie działa. I co teraz? Przyjrzyjmy się temu bliżej. Jakie mogą być przyczyny niewłaściwego działania? Kod programu z internetów niekoniecznie musi być niepoprawny, bo w końcu ktoś to kiedyś uruchomił. Jest jednak kilka typowych sytuacji i sposobów poradzenia sobie. Niekompatybilne biblioteki Jeżeli program się nie kompiluje, a w logu mamy sporo błędów dotyczących brakujących lub powtarzających się bibliotek, to trzeba doprowadzić do stanu, gdzie nie będzie tego problemu. Otwieramy menadżer bibliotek i instalujemy brakujące, jeżeli ich nie ma to szukamy na githubie (najpewniej tam będą). Jeżeli problem polega na wykryciu wielu bibliotek o tej samej nazwie to zaglądamy do katalogu libraries i sprawdzamy czy nie ma tam tego samego co w katalogu projektu. Znaleziono wiele bibliotek w "Servo.h" Wykorzystane: C:\Users\Piotr Adamczyk\Documents\Arduino\libraries\Servo Niewykorzystane: C:\Program Files\WindowsApps\ArduinoLLC.ArduinoIDE_1.8.42.0_x86__mdqgnx93n4wtt\libraries\Servo Znaleziono wiele bibliotek w "LiquidCrystal.h" Najlepiej usunąć to co jest w katalogu libraries, bo może tam być starsza wersja, choć niektórzy kombinatorzy mogą umieścić zmodyfikowane biblioteki, które mają identyczną nazwę ale specyficzne działanie. Tu trzeba wykazać się rozeznaniem. Nie kompiluje się Tu już może być wiele opcji, najlepiej zajrzeć do loga na dole ekranu, jeżeli nie ma tam nic ciekawego to warto, a nawet powinno się ustawić więcej szczegółów podczas kompilacji (w tym przypadku nadmiar na pewno nie zaszkodzi, a może oszczędzić czasu i zmartwień): Często może chodzić o drobiazgi: brakujący nawias, nawiązanie do biblioteki lokalnej (przy include zamiast <> mamy ""). Możliwe też że mamy wybraną płytkę niekompatybilną (np. ESP32) lub o innej liczbie wyprowadzeń przez co niektóre piny zwyczajnie nie istnieją i w wyniku mamy błąd. Jeżeli mamy podaną linię, w której jest błąd trzeba rozejrzeć się w jej pobliżu w poszukiwaniu czegoś kancerogennego. Jeżeli mimo to nie wiemy co jest nie tak trzeba przejść do innej metody. Divide et impera Z łac. "Dziel i zwyciężaj", metoda stosowana przez programistów podkradnięta starożytnym Rzymianom. Jeżeli nie wiesz jak ugryźć cały temat to podziel go na mniejsze, rozwiąż pomniejsze problemy i scal ich wyniki. Jeżeli jednak nie da się rozwiązać pomniejszego problemu, to podziel go i tak rekurencyjnie aż do uzyskania wyniku. Ważne jest zrozumienie działania programu, pośpiech nie jest korzystny. Jeżeli nie umiesz programować, zatrzymaj się i skorzystaj, np. z kursów Arduino. W przypadku Arduino można spróbować przetestować funkcje pojedynczej biblioteki zamiast wszystkich jednocześnie. Załóżmy, że w kodzie używam biblioteki do obsługi kart SD i wyświetlacza LCD, obie stosują SPI i celem jest wyświetlenie obrazka z karty SD na LCD. Coś nie działa, więc: zaznajamiam się z każdą z bibliotek z osobna, w tym celu otwieram przykłady Arduino IDE, które zazwyczaj się dołączone do bibliotek, wgrywam i testuję (może zajść potrzeba zmiany numerów wyprowadzeń tak by pasowały do naszego układu). Uwaga: w tym procesie należy też wymontować część elektroniki tak by w danej iteracji (czyli danej próbie) testowany był tylko kod biblioteki danego elementu i ten element. jeżeli wszystko działa jak powinno robię kopię programu, który nie działa i staram się wyizolować funkcje. Można wybrać jedną bibliotekę i jej obiekty i zakomentować wszystko co tyczy się pozostałych, a jako informację zwrotną wypisać wyniki na port szeregowy. jeżeli jedna z bibliotek działa, np. da się coś odczytać z karty SD, to odkomentuję etap dotyczący wyświetlania, kompiluję, wgrywam i patrzę na wyniki. I tak krok po kroku aż do odkrycia całego kody. Ważne jest aby poruszać się nie zgodnie z numeracją wierszy w kodzie, lecz zgodnie z logiką kodu - wywołaniami funkcji. W ten sposób w końcu trafię na moment, w którym coś jest nie tak. Przykładowo, niech w tym kodzie elektronicznej konewki (zaczerpniętym z internetu) nie działa coś z LCD. Zakomentowałem wszystko dotyczące LCD i sprawdzam czy działa serwo. Zamiast wypisywania tekstu na LCD wypisuję go na monitorze portu szeregowego: //#include<LiquidCrystal.h> //LiquidCrystal lcd(12,11,5,4,3,2); #include<Servo.h> Servo watervalve; void setup() { // lcd.begin(16,2); pinMode(8, OUTPUT); //red pinMode(9, OUTPUT); //green watervalve.attach(10); } void loop() { int mlevel; mlevel = analogRead(A0); mlevel = map(mlevel, 0, 1023, 100, 0); // lcd.clear(); // lcd.print("mois level="); // lcd.print(mlevel); // lcd.print("%"); //red green indicator if (mlevel < 60) { digitalWrite(8, HIGH); digitalWrite(9, LOW); } else { digitalWrite(9, HIGH); digitalWrite(8, LOW); } if (mlevel < 60) { int valpos; valpos = map(mlevel, 0, 60, 180, 0); watervalve.write(valpos); delay(100); } else { watervalve.write(0); } // lcd.setCursor(0,1); if (mlevel < 60) { // lcd.print("watering"); Serial.println("watering"); } else { // lcd.print("not watering"); Serial.println("not watering"); } delay(500); } Jeżeli na monitorze portu szeregowego wszystko będzie OK, to najpierw wypiszę przykładowy tekst gdzieś w bloku setup(), a gdy ten zadziała to przejdę dalej. Jeżeli jednak w powyższym kodzie serwo niezabardzo działa, to może okazać się, że serwomechanizm jest OK, a problem leży w czujniku. Warto zatem zamiast przetworzonych danych wypisać czysty pomiar ADC i wyciągnąć wnioski. Może okazać się że czujnik jest wadliwy, albo cos nie styka. W ten sposób może wyjść na jaw, który moment powoduje problemy, ale także może wyjść na to, że jakiś element nie działa lub coś było źle podłączone. Debugowanie DIY Niestety Arduino na 8 bitowych AVR nie posiada debugera, lecz można zrobić własne – najłatwiej wypisać coś na port szeregowy. Dajmy na to, że mam funkcję którą podejrzewam, że działa niepoprawnie, bo coś się zawiesza, ale nie wiem w którym momencie coś się dzieje. Mogę posłużyć się taką metodą: void funkcjacosrobiaca() { instrukcjaA(); Serial.print("A jest ok"); instrukcjaB(); Serial.print("B jest ok"); instrukcjaC(); Serial.print("C jest ok"); } Po każdej z instrukcji wstawiam tzw. flagę informującą że kod został wykonany do tego mementu i opuścił instrukcję. Jeżeli w wyniku otrzymam: A jest ok B jest ok No to wiem, że program zawisł na instrukcjiC i tam trzeba sprawdzić co jest nie tak. Jeżeli jednak nie mam z jakiegoś powodu dostępu do portu szeregowego (np. programuję Attiny13) to mogę posłużyć się LED w roli wskaźnika, informującego do jakiego momentu kod programu został wykonany. Program wygrywa się ale nie działa Trzeba sprecyzować co nie działa. Niestety ale hasło "Kod Arduino nie działa" jest dość częstym tematem wpisów, a problem może leżeć gdzieś indziej. Znowu najlepiej podzielić problem na pomniejsze, przetestować każdy funkcjonalny blok i powoli scalać. Jeżeli nie znam układów, nie testowałem ich to złym pomysłem jest montowanie całego układu i odpalanie wszystkiego jednocześnie. W przypadku podzespołów których nie znam, najlepiej jest najpierw zaznajomić się z nimi – podłączyć każdy z osobna, wgrać program testowy. Następnie stopniowo dokładać funkcjonalność. W ten sposób uniknie się wielu problemów: nie spalimy wszystkiego jednocześnie, poruszając się bezpiecznym szlakiem będziemy mieć kontrolę nad błędami i szybko je zniwelujemy (gdyby podłączyć jednoczenie 10 nowych elementów, a jeden z nich będzie miał odwrotnie połączone zasilanie i zacznie się grzać, to zanim do niego dojdziemy będzie już zniszczony). Dokładając stopniowo elementy może okazać się, że trafimy na bardzo prozaiczny problem - wadliwe połączenie (uszkodzony kabelek/sfatygowane złącze płytki stykowej), znalezienie tego przy rozruchu kompletnego układu może być problemem, a tak od razu na to trafimy. Dobrym tego przykładem jest dość skomplikowany układ czujnika odległości z kursu elektroniki 2. Składa się z 2 funkcjonalnych bloków: nadajnika podczerwieni, odbiornika z układu TSOP. Jego budowa została przedstawiona tak, że najpierw montowany jest jeden blok, a następnie kolejny, tak że można je rozróżnić na płytce: Multimetr Ważnym narzędziem jest multimetr. W przypadku próby dojścia co jest nie tak można sprawdzić: napięcie w różnych miejscach układu – czarną sondę stawiam na masie, a czerwoną sprawdzam napięcia zaczynając od zasilania, a kończąc na sygnałach wolnozmiennych (sprawdzenie miernikiem magistrali I2C nic nam nie powie). prąd płynący w gałęziach układu – rozwieram dane bloki i sprawdzam pobór prądu, jak gdzieś będzie zbyt wysoki niż domniemany to coś jest nie tak. Może okazać się, że jakiś regulator jest zepsuty, zamiast 3,3 V mam 5V i coś zaczyna się przypalać. ciągłość – sprawdzam czy to co ma być połączone jest połączone (może jakiś kabelek nie styka), a to co rozłączone takie pozostaje (nie ma zwarć na liniach zasilania). Do listy narzędzi można dodać inne, bardziej wyrafinowane, ale takimi nie posługują się początkujący elektronicy. Dalej nie działa Podzespoły sprawdzone, napięcia pomierzone, kabelki zwierają, nic nie płonie ale nic nie działa. Co jest nie tak? W tym momencie forum spełnia swoje zadanie, nietypowy problem, brak pomysłu, pomożemy! Ale trzeba mieć do tego podstawowe informacje. Odkładając na bok szklaną kulę (do której niektórzy szydercy zwykli powracać ), załóż temat o nazwie opisującej rodzaj problemu, hasło "Nie działa" nie jest wystarczające i informuje o tym notka na górze okna nowego tematu: umieść w swojej wiadomości kod programu ładnie zwarty znacznikami kodu programu: poniżej umieść schemat i zdjęcie swojego dzieła (schemat w pliku png/jpg, pdfa ani zipa nikt nie ruszy mając otwartą wersję mobilną forum. Możesz też dodać wynik kompilacji z loga jeżeli ta nie przechodzi: W ten sposób każdy będzie miał komplet informacji, z których będzie w stanie pomóc Ci dojść do tego co jest nie tak. Podsumowanie Aby dojść do przyczyny problemu należy: przeanalizować treść logu, przetestować każdy z modułów/funkcyjnych bloków/ bibliotek osobno, zdebugować kod możliwymi sposobami, sprawdzić napięcia, prądy, ciągłość w układzie, zapytać na forum w sposób dający możliwość pomocy Mam nadzieję, że artykuł ten pomoże początkującym. Jest to jeden z często powtarzających się tematów, więc zachęcam też innych doświadczonych użytkowników forum do zaproponowania swoich metod rozwiązywania problemów z niesforną płytką Arduino.
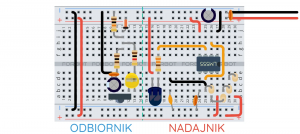

-
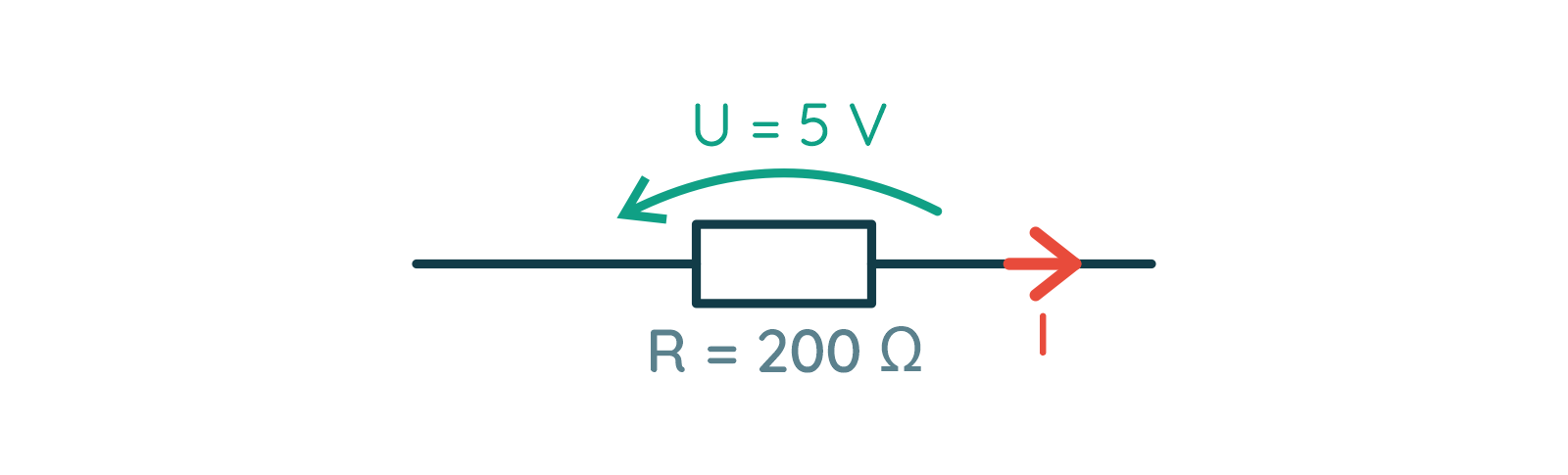
FAQ Napięcie, prąd, rezystancja – inżynierskie podejście
Gieneq opublikował temat w Artykuły użytkowników
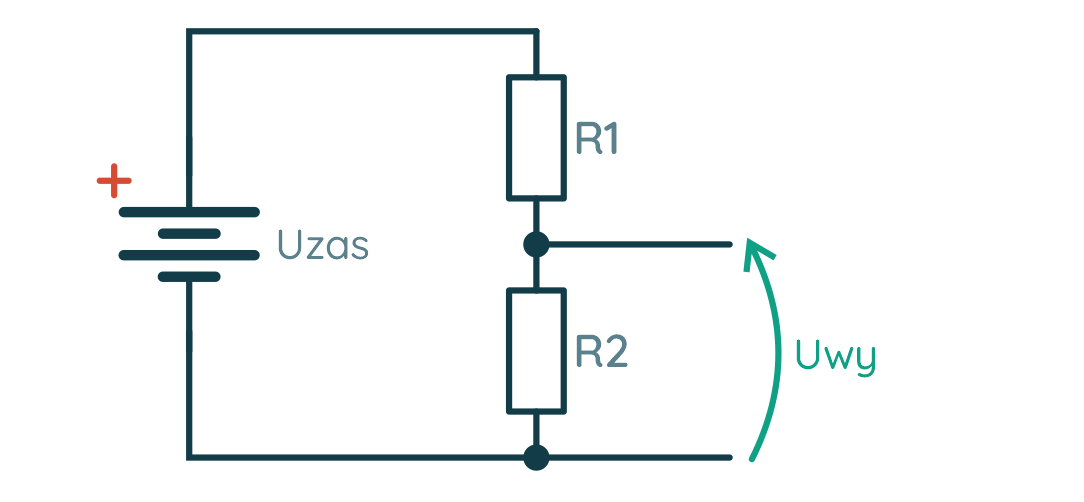
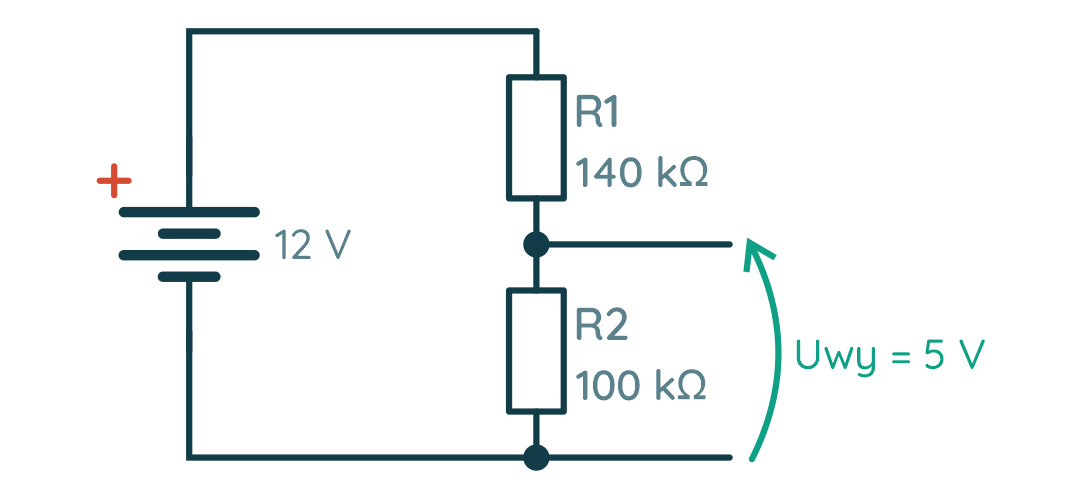
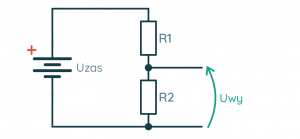
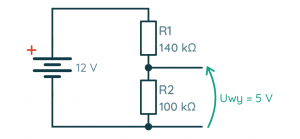
Wstęp Pierwszy wzór jaki poznają kursanci to nieśmiertelne prawo Ohma – prosta formułka, a ile potrafi nastręczyć problemów. Przeglądając wpisy zauważyłem, że wiele osób co prawda rozumie jak coś obliczyć, ale nie ma takiej intuicji, że coś jest duże, coś małe, tu płynie taki prąd, a tu taki, albo jak dołożę równolegle rezystor to na pewno opór zastępczy spadnie, a ile? No i szukamy kartki i ołówka. W tym artykule postaram się podzielić swoimi metodami na poradzenie sobie z kilkoma typowymi przypadkami, dzięki którym można oszacować pewne wartości. Wynikają one z obserwacji i analogii. Z pewnością każdy ma swoje metody, więc zachęcam do podzielenia się nimi w komentarzach Wybrane zagadnienia Przykładowe przypadki, w których można posłużyć się pewną intuicją: Mam rezystor w kiloomach, przykładam napięcie w woltach, wynikowy prąd jest w ... Do rezystora dodałem równolegle kolejny, jaki będzie miał wpływ na rezystancję zastępczą? Zbudowałem dzielnik napięcia, zmienię jedną z rezystancji i co wyjdzie? Elementy które mam nie są takie jak na schemacie, czy mogę je użyć? Dotknięcie prądu Po zapoznaniu się z prawem Ohma opisanym w kursie elektroniki 1, każdy powinien być w stanie wyznaczyć opór rezystora dysponując: wartością napięcia jakie odkłada się na zaciskach (nóżkach) rezystora, wartością prądu jaki przepływa przez rezystor. Problem pojawia się jednak z wyobrażeniem sobie co tam się właściwie dzieje, nabraniem intuicji, określeniem co jest duże a co jest małe, "dotknięciem prądu" tak by stał się bardziej rzeczywisty. Dlatego w tym śródtytule postaram się nakreślić jak można spróbować wyobrazić sobie wielkości elektryczne i nabrać intuicji w wyznaczaniu (szacowaniu) wartości. Prąd a rezystancja Efektem działania rezystora jest ograniczenie płynącego prądu (no i grzanie się), zatem dla naszego źródła napięcia i dobranego rezystora możemy wyznaczyć jaki będzie płynął prąd. I o ile same obliczenia nie są trudne, to łatwo się zamotać w rzędach wielkości. Podstawowym sposobem poradzenia sobie z różnymi rzędami wielkości (przedrostkami) jest sprowadzenie jednostki wartości do jednostki podstawowej, np. mam kiloomy to sprowadzam do tysięcy omów, a w zamiast miliamperów piszę tysięczne części ampera. Jak ktoś lubi zapis z potęgami 10 to ładnie to zawrze i wyjdzie poprawny wynik, który można znowu zamienić na jakiś rząd wielkości dodając odpowiedni przedrostek. Da się tu jednak zastosować pewien skrót myślowy. Zacznijmy od tego z czym mamy do czynienia. Początkujący jest najczęściej zaopatrzony w: źródło napięcia stałego (np. bateria 5 V), czyli w obliczeniach operujemy podstawową jednostką [V], rezystory od pojedynczych omów do megaomów, czyli w obliczeniach pojawiają się 2 kolejne rzędy wielkości 1000 = 103 [kΩ] i 106 [MΩ] . Wziąłem baterię 5 V, rezystor 1 Ω i jaki popłynie prąd? Nic nie zamieniamy, tu wolt, tu om i wychodzi: R = U/I = 5 V / 1 Ω = 5 A W elektronice z jaką zmaga się kursant taki prąd to jest już coś! Tylko 2 uwagi: choć z teorią nie podyskutujemy to praktyka może zaskoczyć – 5 A może nie popłynąć, bo wydajność prądowa źródła może być za mała (np. ładowarka do telefonu może dostarczyć maksymalnie 5 V i 3 A), podobnie pakiet kilku baterii raczej nie da rady dać 5 A, rezystor ma swoje ograniczenia związane z wydzielaną mocą – 5 V i 1 A ta aż 5 W, która wydzieli się w formie ciepła, a mały rezystor z kursu poradzi sobie tylko z 1/4 W mocy. A gdyby chcieć namacać prąd 5A, to duże to? Wspomniana ładowarka 5V 3A może rozgrzać się, gdy podłączymy do niej prawie rozładowany tablet – w końcu 5V i 3A to aż 15W mocy, tyle ile porządna lampa LED, słaba lampa energooszczędna, lub bardzo słaba żarówka. Niejeden laptop zużywa 15–20 W mocy. 5 A to naprawdę spory prąd. Początkujący może spotkać się z takim prądem przy sterowaniu większym silnikiem, żarówką, lub długą taśmą LED. Można zauważyć, że jeżeli mam napięcie rzędu pojedynczych woltów i rezystor rzędy pojedynczych omów, to wynik też będzie rzędu kilku amperów, czyli prąd będzie duży! Kolejny przypadek – źródło napięcia to samo (5 V), ale rezystor już 1 kΩ, jaki będzie prąd? R = U/I = 5 V / 1 kΩ = 5 V / 1000 Ω = 0,005 A = 5 mA Ajj... dziwnie wygląda, łatwo się pomylić. To może taki zapis będzie lepszy, nie ma tylu zer: R = U/I = 5 V / 1 kΩ = 5 V / 103 Ω = 5 * 10-3 A = 5 mA Można zapamiętać, że gdy wyznaczamy prąd dysponując napięciem w podstawowej jednostce i oporem rzędu kiloomów to wynik będzie w miliamperach. Opornik kiloomowy jest już dość duży, stosuje się taki np. przy ograniczaniu prądu płynącego przed LED. Choć może wydawać się, że taki prąd jest znikomy, to w elektronice jest to prąd użytkowy. Z takim prądem będziemy pracować w elektronice cyfrowej lub przy sterowaniu tranzystorami BJT małej mocy. Z drugiej strony prąd ten można uznać za dość duży, gdy myślimy o układach zasilanych z baterii. Gdyby mieć akumulator 2500 mAh, który ma całkiem sporą pojemność, to przy stałym poborze 5 mA rozładuje się po 500 godzinach czyli po niecałych 3 tygodniach. Znowu pytanie czy to dużo? Zależy! Jeżeli zbudujemy bezprzewodową klawiaturę zasilaną z baterii, to ładowanie co 3 tygodnie może być uciążliwe. To ile powinna pobierać prądu taka klawiatura? Klawiatura przy pomocy której pisze ten tekst wymaga wymiany baterii co około 6 miesięcy (załóżmy że w czasie pracy i uśpienia pobór prądu jest ten sam): 2500 mAh / 4320 h ≈ 0,579 mA = 579 µA Mikroampery [µA] to już naprawdę mało. Mikroampery osiągniemy dysponując napięciem w podstawowej jednostce i oporem rzędu megaomów. Właśnie weszliśmy w rząd wielkości prądu przeznaczonego dla urządzeń zasilanych z baterii. Zaś rezystory przez które płyną mikroampery możemy spotkać w dzielniku napięcia służącego do przeskalowania napięcia na akumulatorze, tak by możliwy był pomiar przy pomocy układu dostosowanego do niższych napięć (np. pomiar 12 V na akumulatorze samochodowym przy użyciu 5 V ADC Arduino). W takiej sytuacji istotny jest możliwie mały pobór prądu. Podsumowanie Myśląc o wielkościach występujących w elektronice takich jak prąd, napięcie i opór oraz o ich wartościach dobrze jest wyobrażać sobie konkretne przypadki z życia. Dobrze jest też wiedzieć, np. jaki rząd wielkości prądu uzyskamy dla danego rezystora, dzięki temu unikniemy błędów w obliczeniach. Połączenie 2 rezystorów Na początek oczywista prawda: im większa rezystancja tym mniejsza "przepustowość" – mniejszy prąd (duży opór mały prąd, mały opór duży prąd). Połączenie szeregowe W połączeniu szeregowym dokładając dodatkowy rezystor, nieważne jaki ma opór (duży czy mały), opór zastępczy będzie większy (stąd prąd płynący w szeregu będzie mniejszy). Jak można to sobie wyobrazić? Posługując się analogią wodną można wyobrazić sobie 2 kryzy (zwężki), jedna stawia opór, ale dokładając kolejną jeszcze bardziej zwiększamy opór. A jak to się ma w połączeniu równoległym? Najpierw krótka dygresja. 13 to nieskończoność Jak byłem na studiach podczas wykładów z tak zwanego M&Ms pan profesor opowiadał o modelach matematycznych. Gdy doszedł do tematu inercji i stałej czasowej powiedział, że gdy widzi, że obiekt ma stałą czasową 13 to jest to nieskończoność. Skąd taki pomysł? Gdy wartość jest duża, daleko odchodzi od pozostałych, dla ułatwienia analizy (nie wyznaczenia wyniku, tylko samej analizy), można przyjąć pewne wartości graniczne. Do wartości granicznych możemy zaliczyć 0 i nieskończoność. A w elektronice kiedy można posłużyć się takimi uproszczeniami? Na pewno spotkamy się z tym podczas dokonywania pomiarów multimetrem. Gdy przyrząd pracuje w roli: amperomierza to zależy nam aby w połączeniu szeregowym nie wprowadzał zaburzeń swoim oporem prądu, zatem jego opór jest pomijany i wynosi 0 Ω, woltomierza to zależy nam aby w połączeniu równoległym nie zaburzał swoim oporem napięcia, zatem jego opór jest nieskończony. Podobnie można uznać, że rozwarcie jest rezystorem o nieskończonym oporze, bo przez powietrze nie płynie prąd i nie wpływa na różnicę potencjałów pomiędzy dwoma punktami. Bogatsi o te uwagi ruszamy dalej! Połączenie równoległe To jak wyobrazić sobie połączenie równoległe rezystorów? Znowu posłużmy się analogią wodną ale tym razem tą opisaną w kursie dotyczącym prawa Kirchhoffa i rozkładu prądów w węzłach – rzeka z rozwidleniem. Z jakiegoś ogromnego zbiornika (o nieograniczonym wydatku wody) wypływa rzeka. Płynie nią tyle wody ile jest w stanie pomieścić koryto rzeki. Przy rzece wykopano wąski kanał. Jak zmieni się przepływ? Woda zignoruje kanał? No nie... Co prawda główny nurt się nie zmieni, ale do wąskiego kanału trafi tyle wody ile jest w stanie on pomieścić. Zatem wody wypływającej do rozwidlenia będzie więcej, dokładnie tyle ile suma obu nurtów. Zaś łączny opór stawiany przez oba koryta rzek (albo przepustowość) zmaleje, bo w końcu przepływa łącznie więcej wody. Dokładnie to samo można zaobserwować w elektronice – suma prądów w węźle opisana jest prawem Kirchoffa. Pytanie tylko jak zmienia się rezystancja? Do baterii 5 V podłączamy rezystor 220 Ω czyli o dość małym oporze. Równolegle dodajmy rezystor o względnie dużym oporze np. 10 kΩ. Jak się zachowa prąd? 10 kΩ jest tak duże że można potraktować je jak nieskończoność czyli rozwarcie, zaś 220 Ω jest tak małe jak zwarcie - wtedy w przepływie prądu dominujący wpływ ma rezystor 220 Ω. Lecz ten o dużym oporze też coś wnosi. Pewna część prądu przepływa przez niego, zwiększając całkowity prąd płynący w układzie rezystorów. Stąd rezystancja połączenia równoległego jest widziana w całości jako mniejsza od najmniejszego z rezystorów (220R) bo została pomniejszona przez wpływ rezystora o większym oporze. Stosunek ten opisany jest wzorem w postaci ogólnej: 1/Rz = 1/R1 + 1/R2 + 1/R3 + ... Który często ograniczamy tylko dla układu 2 rezystorów i dla wygodny przekształcamy do postaci: Rz = 1/(1/R1 + 1/R2) i ostatecznie takiej: Rz = (R1 * R2)/(R1 + R2) Jak łatwo go zapamiętać? Ja zawsze przypominam sobie jeden typowy przypadek – co wyjdzie, gdy połączę równolegle 2 rezystory 1 kΩ? Wynikowa rezystancja wyniesie połowę jednego z nich! We wzorze musi wyjść 1/2 czyli (1*1) / (1+1). Przypadek ten jest przypadkiem granicznym i warto o nim pamiętać, bo z założenia rezystancja zastępcza połączenia równoległego jest zawsze mniejsza od najmniejszej rezystancji. Zaś granice można ustalić w ten sposób: jeżeli zwiększać większą rezystancję to dążymy do nieskończoności (rozwarcia) i wypadkowa rezystancja równa jest tej mniejszej, jeżeli zmniejszać rezystancję, to dojdziemy do przypadku, gdzie oba rezystory są tej samej wartości i wynik to połowa jednej z nich. W połączeniu równoległym wartość wypadkowej rezystancji zawrze się w przedziale wartości od połowy rezystancji mniejszej do rezystancji mniejszej. Wnioski W połączeniu szeregowym rezystancja wypadkowa to suma rezystancji, gdzie prąd płynie ten sam przez oba rezystory. W połączeniu równoległym rezystancja wypadkowa będzie mniejsza od mniejszej z rezystancji i na pewno nie mniejsza niż jej połowa, zaś prąd wpływający na układ rezystorów zależy od sumy prądów każdego z nich. Dzielnik napięcia W przypadku budowy dzielnika dobrze jest wyprowadzić wzór. Zacznijmy od wyznaczenia prądu płynącego w obwodzie składającego się z baterii o napięciu Uzas oraz 2 rezystorów R1 przy plusie i R2 przy masie: Uzas = I*R1 + I*R2 I = Uzas / (R1 + R2) Tu dobrze jest zapamiętać, że przez oba rezystory płynie ten sam prąd (pomijamy pobór prądu przez odbiornik napięcia wyjściowego). Dobrze, teraz jak wyznaczamy wzór na napięcie na wyjściu dzielnika (na rezystorze R2 Uwy = R2 * I = R2 * Uzas / (R1 + R2) = Uzas * R2 / (R1 + R2) I teraz jak dobrać rezystory w dzielniku? Załóżmy że na wejściu jest 12 V a chcemy uzyskać 5 V. Możemy przekształcić wzór: Uwy / Uzas = R2 / (R1 + R2) 5/12 = R2 / (R1 + R2) Czyli musimy dobrać rezystory tak by uzyskać stosunek 5/12. Nasz dzielnik będzie działać przy akumulatorze więc weźmy za R2 rezystor 100 kΩ aby ograniczyć pobór prądu i sprawdźmy jaki wyjdzie drugi: 5/12 = 100 kΩ / (R1 + 100 kΩ) → R1 = 140 kΩ Zgadza się, zatem tak wygląda nasz układ: Tylko akurat rezystorów 140 kΩ nie ma, mam same 100 kΩ. Mogę np. z 2x 100 kΩ zbudować 1x 50 kΩ, dodać w szereg kolejny 100 kΩ i jest 150 kΩ. Tylko jak to wpłynie na układ? Sprawdźmy skrajny przypadek – jeżeli R1 mocno zmniejszymy tak, że będzie dążyć do 0 Ω, to wtedy w mianowniku pojawi się samo R2. Tu dla wtajemniczonych granica do policzenia Uwy = Uzas * R2 / (R1→0 Ω + R2) = Uzas Czyli im mniejszy opór R1 tym większy wpływ ma napięcie zasilania. Im opór rezystora przy plusie jest mniejszy tym większe napięcie na wyjściu (aż do równości podczas zwarcia z zasilaniem). Zatem w tym przypadku zwiększając rezystancję R1 bardziej odcinamy się od napięcia wejściowego czyli napięcie na wyjściu będzie niższe. To dobrze! Bo jeżeli ma to trafić na układ ze ścisłą tolerancją to lepiej żeby napięcie było za niskie. Sprawdźmy jeszcze czy się zgadza: Uwy = 12 V * 100 kΩ / (150 kΩ + 100 kΩ) = 4,8 V Faktycznie napięcie jest niższe. A co się stanie jakby zmniejszyć rezystancję R2? Znowu sprawdźmy skrajny przypadek: Uwy = Uzas * R2→0 Ω / (R1 + R2→0 Ω) W praktyce oznacza to że zwarliśmy wyjście do masy i tak też wyjdzie z obliczeń. W mianowniku jest coś większego od zera wiec można dzielić, a w liczniku coś dąży do zera, to wynik też dąży do 0. Uwy = 0 V Czyli im mniejszy R2 tym większy ma wpływ masa układu. Jest to tylko takie porównanie. W praktyce na rezystorze R2 o małym oporze odkłada się mniejsze napięcie. Należy też wziąć pod uwagę, że sumaryczny opór również się zmniejsza przez co przez rezystory popłynie większy prąd. Zgodnie z prawem Kirchhoffa dotyczącym napięć w oczku, napięcie na rezystorze R1: UR1 = Uwe - UR2 Jako że po teoretycznym zmniejszeniu oporu R2, UR2 spadło o jakieś ΔR to o te samo ΔUR wzrośnie UR1 tak by: Uwe = UR2 - ΔUR + UR2 - ΔUR Margines bezpieczeństwa Zaprojektowaliśmy układ ale zapomnieliśmy, że w akumulatorze 12 V jest w teorii, a tak naprawdę może być tam nawet 15 V. Jak poprawić układ? Po pierwsze trzeba przyjąć, że może być gorzej niż myślimy, w elektronice pesymizm jest mile widziany. Załóżmy że teraz napięcie wejściowe może wynieść aż 16 V, a na wyjściu ma być 5 V, ale najlepiej nieco mniej na wszelki wypadek. Nie można jednak przesadzać! W tym przypadku wyjście dzielnika podpięte jest do ADC Arduino i im większa będzie rozbieżność od wartości maksymalnej tym mniejszy zakres ADC wykorzystujemy. W konsekwencji pomiary będą mieć gorszą rozdzielczość. Dysponujemy dalej rezystorami 100 kΩ i tym razem dajmy 100 kΩ jako R1. Przekształćmy wzór, pomińmy upraszczanie i wyznaczmy wartość: R2 = (Uwy/Uwe) / (1 - Uwy/Uwe) * R1 = 45,5 kΩ Złożymy taki rezystor? Wiemy, że: z 2 identycznych rezystorów połączonych równolegle zrobimy nowy o wartości o połowę mniejszej, czyli 50 kΩ, w połączeniu równoległym większy rezystor wpływa na mniejszy, tak że można manipulować rezystancją. Rezystancja zastępcza zawrze się w przedziale od połowy rezystancji mniejszego do rezystancji mniejszego czyli tu od 50 kΩ do 100kΩ, czyli nie pasuje. Weźmy zatem układ z 2 rezystorów połączonych równolegle, rezystancja zastępcza to 50 kΩ. Opór jest większy, ale czy to źle? Jest to rezystor R2 czyli ten przy masie. Ma większy opór, zatem masa bardziej mniej wpływała na wynik czyli napięcie na wyjściu będzie większe niż 5V Dużo? Uwy = 16 V * 50 kΩ / (100 kΩ + 50 kΩ) = 5,33 V To już trochę jest, ale z drugiej strony wzięliśmy już bezpieczny margines. Jeżeli dla 16 V na wyjściu jest 5,33 V to z proporcji widać że dla 5 V jest nieco ponad 15 V na wejściu, czyli trochę groźnie. Czy da się coś z tym zrobić? Zamiana R1 z R2 nie ma sensu. Patrząc jednak na powyższy wzór widać, że wystarczy nieco podciągnąć R1 (100 kΩ) aby było dobrze. Tylko żeby uzyskać coś małego trzeb dać 4 rezystory 100 kΩ żeby uzyskać 25 kΩ. W wyniku uzyskamy napięcie maksymalne 4,57 V przy użyciu 7 rezystorów. A gdyby tak przeskalować R1 i R2 dwukrotnie i do R1 dodać jeszcze 100 kΩ? uzyskamy wtedy stosunek: 100 kΩ / (300 kΩ + 100 kΩ) = 1/4 Napięcie wyjściowe wyniesie 4 V i użyjemy 5 rezystorów, ale czy warto? Wnioski Na pewno warto zapamiętać, że w dzielniku im mniejsza rezystancja opornika przy masie tym niższe napięcie na wyjściu, zaś im niższa rezystancja przy zasilaniu tym wyższe napięcie na wyjściu. Warto przy tym pamiętać żeby nie przesadzić ze zmniejszaniem i brać pod uwagę bezpieczny margines napięcia uwzględniając projektowany układ. Końcowe próby są bardziej teoretyczne. Napisałem to dlatego, żeby początkujący nauczyli się kombinować. Jeżeli coś nie działa, nie zgadza się ze wzorem to spróbować przekształcić, dodać poprawkę, podmienić coś i za każdym razem skonfrontować z rzeczywistością. Nie należy od razu rozkładać rąk i wołać o pomoc na forum tylko najpierw spróbować własnych sił jest szansa, że się uda, a nawet jeżeli stracimy cenną godzinę to uczymy się czegoś na całe życie!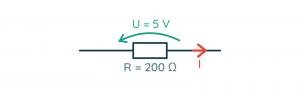


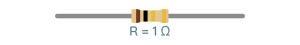









-
FAQ Obsługa przycisku w Arduino - wyzwalanie zmianą stanu
Gieneq opublikował temat w Artykuły użytkowników
Ten krótki artykuł dedykowany jest kursantom i często pojawiającym się pytaniom o wykonanie pojedynczego zadania po kliknięciu przycisku. Obsługa przycisku w Arduino jest prostym zadaniem pojawiającym się m.in. w kursie Arduino. Choć z odczytem stanu pinu nikt nie ma problemu, to problem może sprawić wykonanie jakiegoś bloku kodu tylko jeden raz po wciśnięciu przycisku. Załóżmy, że treść zadania brzmi: (...) po wciśnięciu przycisku wypisz przy pomocy portu szeregowego napis Hello world!. Często spotkałem się z sytuacjami, gdzie adepci programowania przesyłają rozwiązania tego typu: if (digitalRead(4) == LOW) { Serial.println("Hello world!"); delay(500); } Jeżeli uzna się, że użytkownik takiego rozwiązania wie, że trzeba kliknąć i możliwie szybko puścić przycisk to rozwiązanie to zadziała. Ale co jeżeli nikt nie wie o konwencji klikania i zamiast energicznego kliknięcia, użytkownik przytrzyma przycisk? Właśnie... kod wykona się cyklicznie z odstępem 500 ms. A nie o to chodzi. Celem zadania jest zatem nie tyle wykrycie stanu przycisku lecz zarejestrowanie zmiany stanu. Zmiana ta jest jednoznaczna z wykonaniem wciśnięcia przycisku (podczas gdy samo wykrycie stanu może trwać bardzo długo). Są 2 sposoby realizacji tego zadania: przesłuchiwanie (polling) z zatrzaskiem (proste od strony implementacji), przy pomocy przerwania (trudniejsze). Przesłuchiwanie i zatrzask Choć nazwa tego 1 może odstraszać, to niewiele różni się od tego co jest w powyższym kodzie, potrzeba tylko dodać dodatkową zmienną pamiętającą stan przycisku. Warunek zaś będzie poległ na tym, że sprawdzane będą 2 zmienne, w których odczyt obecnego stanu pinu różni się od tego co było ostatnio. Jeżeli przy obiegu pętli nastąpiła różnica, to wiadomo że przycisk był wciśnięty. #define PRZYCISK 4 int ostatniStan = HIGH; //BO PULLUP void setup() { Serial.begin(9600); pinMode(PRZYCISK, INPUT_PULLUP); } void loop() { int stan = digitalRead(PRZYCISK); if(ostatniStan == HIGH && stan == LOW) { Serial.println("Hello world!"); } ostatniStan = stan; delay(50); } W kodzie widać nową, globalną zmienną pamietającą ostatni stan: int ostatniStan = HIGH; //BO PULLUP Następnie w pętli loop najpierw odczytujemy stan przycisku ale nie wewnątrz warunku. Od razu zapisujemy stan do tymczasowej zmiennej tak by odczytywać stan tylko raz (uchroni to kod od wstrzelenia się z kliknięciem przycisku pomiędzy 2 odczyty). Teraz patrzymy co jest na końcu pętli: ostatniStan = stan; delay(50); Istota zapamiętania stanu - to co było teraz (obecny stan) trafia do przeszłości i w kolejnym obiegu pętli będzie już poprzednim stanem. Do tego drobne opóźnienie. Realizacja zatrzasku Dysponując 2 zmiennymi: obecnym stanem (zmienna stan) oraz stanem z poprzedniego obiegu pętli (zmienna ostatniStan) można bez problemu wykryć zmiany jakie nastąpiły przy ostatnim obiegu pętli. W powyższym kodzie w warunku następuje wykrycie tak zwanego zbocza opadającego - zmienna zmienia się ze stanu wysokiego w niski. Odwrotną sytuacją jest wykrycie stanu narastającego polegającego na wykryciu przejścia ze sanu niskiego w wysoki. Oba przypadki mają sens stosowania i zależnie od potrzeb wybiera się jeden lub drugi. Przykładowo reakcja na puszczenie przycisku występuje często w komputerowym GUI - naciskają przycisk myszy zazwyczaj nic się nie dzieje, można nim jeździć po przyciskach, a w razie pomyłki nawet zmienić przycisk na poprawny. Dopiero puszczenie przycisku aktywuje to na co się nim najechało. Przerwania Istnieje jednak inny sposób detekcji zdarzeń, są to przerwania zewnętrzne i tu polecam przeczytać kurs Arduino 2. W skrócie, w Arduino UNO przerwania zewnętrzne dostępne są tylko na pinach 2 i 3. Utworzenie przerwania polega na przypięciu funkcji obsługi przerwania: #define PRZYCISK 2 void setup() { attachInterrupt(digitalPinToInterrupt(PRZYCISK), funckjaObslugiPrzerwania, RISING); } Zdarzenie zostanie wykonane przy zboczu narastającym (parametr RISING), zaś kod zostanie zawarty w funkcji o nazwie funckjaObslugiPrzerwania (w argumencie attachInterrupt nazwa funkcji jest referencją). Funkcja obsługi przerwania Funkcja obsługi przerwania nie przyjmuje argumentów, zwraca typ void, nie może zawierać innych przerwań ani opóźnień (stąd nie są dozwolone żadne wywołania delay, Serial.print itp). To skoro nie można użyć Serial.print wewnątrz przerwania to jak go użyć? Przyda się tu zmienna pomocnicza: #define PRZYCISK 2 volatile int stan = HIGH; void funckjaObslugiPrzerwania() { stan = LOW; } void setup() { attachInterrupt(digitalPinToInterrupt(PRZYCISK), funckjaObslugiPrzerwania, RISING); } void loop() { if(stan == LOW) { stan = HIGH; Serial.println("Hello world!"); } } Pierwsze co widać to dopisek przed typem zmiennej stan: volatile oznacza że kompilator nie zoptymalizuje tej zmiennej (szczegóły w kursie). Funkcja obsługi przerwania ustawia zmienną, a w głównej pętli jest sprawdzany jej stan. Ta prosta komunikacja pomiędzy 2 funkcjami poprzez zmienną globalną umożliwia wykonanie bardziej złożonych operacji poza ciałem funkcji obsługi przerwania. Też drobna uwaga, deklaracje funkcji dobrze jest umieszczać przed ich wystąpieniem. W starszych wersjach wiązało się to z błędem, obecnie nie ma znaczenia. Podsumowanie W tym krótkim artykule postarałem się przedstawić bardzo prosty sposób obsługi przycisku. Skupiłem się na istocie realizacji zatrzasku lecz niedługo dopiszę fragment dotyczący problemu drgania styków i związanych z tym bibliotek.