Zealota
-
Zawartość
197 -
Rejestracja
-
Ostatnio
-
Wygrane dni
5
Osiągnięcia użytkownika Zealota
")





-
Budowa urządzenia do pomiaru siły chwytu
Zealota odpisał w temacie użytkownika mikolajaha • Arduino i ESP
Można by wykorzystać belkę tensometryczną i mierzyć wagę, siłę uścisku. Tutaj właściwie są wszystkie komponenty do takiego projektu. https://sklep.msalamon.pl/blog/zbuduj-wlasna-wage-na-esp32-z-wyswietlaczem-oled/ -
STM32F469 oraz podobne, kilka pytań o MIPI/DSI
Zealota odpisał w temacie użytkownika _LM_ • Mikrokontrolery
A może od razu gotowy produkt: Drukarka 3D Elegoo Mars 2 Mono -
STM32 F411 Timer interrupt nie działa
Zealota odpisał w temacie użytkownika DeadGeneratio • Mikrokontrolery
To nie do końca prawda w przypadku STM32. HAL_Delay to zwykły polling na rejestrze SysTicku, może być przerwany prze każde inne, o lepszym priorytecie przerwanie. Tam jest wielopoziomowy system priorytetów i wywłaszczeń dzięki, któremu zasada taka znana choćby z AVR nie jest tak ścisła. W AVR _delay wyłącza przerwania, w STM32 tak nie jest. Przy poprawnie zaprojektowanym urządzeniu w przerwaniach mogą być dowolnie długo trwające procedury. Oczywiście w szczególnych przypadkach należy trzymać się zasady krótkiego "kodu" w przerwaniach i pewnie w tym przypadku, dla mniej wprawionego programisty, będzie to dobra i skuteczna zasada. -
FFTSlice - moduł do wyznaczania FFT w czasie rzeczywistym
Zealota odpisał w temacie użytkownika Gieneq • Projekty - DIY w budowie (worklogi)
Założyłem, ze konfigurujesz DAC i posyłasz sygnał wyjściowy z niego z powrotem na wejść ADC i w ten sposób robisz "samotestowanie" :). W takim kontekście wydawało mi się, że łatwiej sobie zrobić tablice próbek np w Excelu i przygotować kilka tablic z "wartościami" ADC i w ten sposób "karmić" transformatę Fouriera. Można też na szybko tworzyć sygnały jako sumę sinusoid podczas pracy programu. To oczywiście mocno obciąża mikrokontroler, ale do testów wystarczy. https://sound.eti.pg.gda.pl/~greg/dsp/06-GenerowanieSygnalow.html#Podsumowanie -
FFTSlice - moduł do wyznaczania FFT w czasie rzeczywistym
Zealota odpisał w temacie użytkownika Gieneq • Projekty - DIY w budowie (worklogi)
A czemu akurat generujesz przez DAC, a nie np. przez tablice próbek trzymanych w flash? -
Biblioteka CMSIS (DSP) dla rodziny H7xx
Zealota odpisał w temacie użytkownika DeadGeneratio • Mikrokontrolery
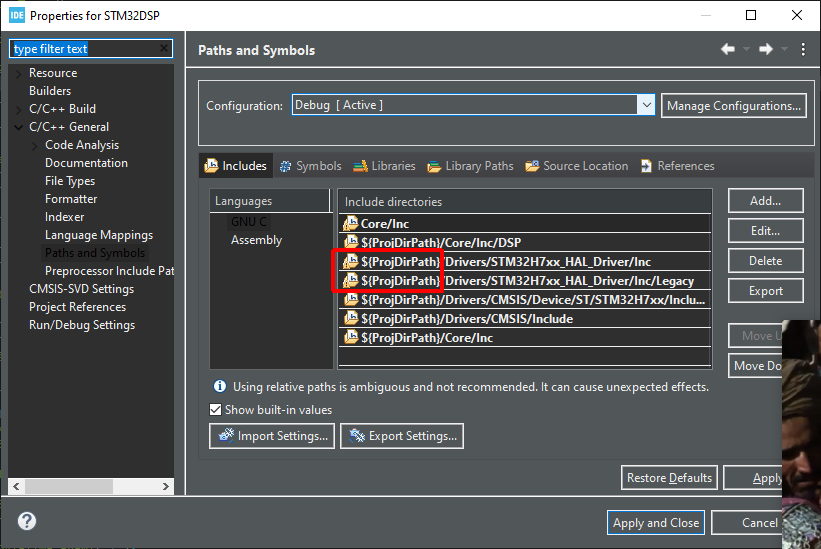
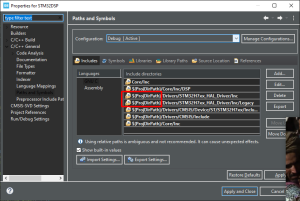
Coś kiepsko ten projekt utworzyłeś. Brakuje plików od HALa, są tylko w "w widoku projektu" Po skopiowaniu brakujących plików projekt się kompiluje. CubeIDE_STM32H723.zip
-
Biblioteka CMSIS (DSP) dla rodziny H7xx
Zealota odpisał w temacie użytkownika DeadGeneratio • Mikrokontrolery
Coś kiepsko ten projekt utworzyłeś. Brakuje plików od HALa -
Biblioteka CMSIS (DSP) dla rodziny H7xx
Zealota odpisał w temacie użytkownika DeadGeneratio • Mikrokontrolery
Spróbowałem dodać CMSIS DSP w najnowszej wersji i chyba jednak wymaga ona cmake do poprawnej konfiguracji Przynajmniej tak mi się wydaje, bo nie potrafiłem zintegrować tego z CubeIDE 1.9.0 bez "multiple definitions". Wydaje się, że nieźle tam nadźgali wielopoziomowych deklaracji. Na szczęście miałem starsze wersje, która działa. W załączniku wersja na H750, którą wygenerowałem w CubeIDE i dodałem pliki CMSIS. Łatwo zauważysz co tam dodane. Przejrzyj ustawienia projektu, sprawdź flagi i ścieżki, powinieneś bez problemu to zmodyfikować do swojego mikrokontrolera. Gdyby były kłopoty to wygeneruję to dla właściwego procka. CubeIDE_STM32H750.zip -
Tu nie chodzi o przeczytanie tylko studiowanie dokumentacji. Czytasz raz, nie rozumiesz, czytasz drugi raz i tak dalej, jak Forrest Gump z demontażem karabinu, aż do perfekcji
-
-
Na etapie "prostych projektów", o których pisałeś nawet nie ma potrzeby o tym myśleć. Zrobiłem już kilka takich i nawet nie wiem o czym pisałeś
-
Co do H7 się nie wypowiem, jeszcze leży w "do zrobienia" natomiast co do F7 to się nie zgodzę. Taki STM32F722 w obudowie 64 pin to taka bardziej rozbudowana F4. Wiele modułów "kopiuje" się w wprost. Choćby część interfejsów z DMA
-
Przydałoby się jeszcze z parę zdjęć "gotowego produktu". Na chwile obecną nie wiele widać, żeby ocenić ostatecznie.
-
Arduino: jak rysować rozbudowane wykresy na żywo?
Zealota odpisał w temacie użytkownika Komentator • Artykuły redakcji (blog)
Można też skorzystać z Octave, który ma dostępne odpowiednie moduły https://wiki.octave.org/Instrument_control_package https://octave.sourceforge.io/instrument-control/package_doc/Serial-Port.html Warto się też z innych powodów zapoznać z tym matematycznym programem, darmowym odpowiednikiem Matlaba -
[STM32] Optymalizacja sterowania wyświetlaczem TFT
Zealota odpisał w temacie użytkownika Wloczykij555 • Mikrokontrolery
Nie jest konieczne. Również konfiguracja kanału DMA z odp. liczbą transakcji. Kanał sam się "wyłączy" gdy wewn. licznik kanału się wyzeruje. Tak właśnie działa DMA wyłączonym trybem circular