Napiszemy prosty program, który wczyta dane uczące z dołączonego pliku, następnie zostanie wyświetlone okno w którym myszką będzie można narysować cyfrę po czym program dokona jej klasyfikacji porównując z danymi uczącymi i odpowie nam jaką cyfrę narysowaliśmy.
Algorytm - K-Nearest Neighborhood
Jak każdy inny algorytm systemów uczących się KN składa się z dwóch faz. Pierwsza polega na dostarczeniu wektorów uczących wraz z odpowiednimi etykietami. Chodzi o to, że dostarczamy do naszego algorytmu obrazek prezentujący na przykład liczbę dwa:
Dodatkowo dostarczamy także odpowiadającą mu etykietę, która może być zapisana jako liczba float i dla naszej dwójki może wynosić 2.0, co jest najrozsądniejszym wyborem.
Mówi ona fazie uczącej, że ten obrazek należy w procesie uczenia sklasyfikować wraz z pozostałymi mu podobnymi pod etykietą 2.0.
W drugiej fazie algorytmu używa się wytrenowanego wcześniej klasyfikatora by rozpoznawać dostarczane wektory testowe. Czyli np. jeśli dostarczymy obrazek, na którym jest dwójka to nasz algorytm zwróci nam na wyjściu, że ten obrazek najbardziej przypomina te sklasyfikowane wcześniej w procesie uczenie z etykietą 2.0. Jako odpowiedź dostaniemy etykietę na podstawie, której będziemy mogli stwierdzić, że nasz obrazek reprezentuje ręcznie zapisaną liczbę 2.
Przypuśćmy więc, że chcemy użyć klasyfikatora KN tak by rozróżniał liczby 0 i 2. Dostarczamy więc w procesie uczenia tablicę obrazków oraz drugą tablicę zawierającą odpowiadające im etykiety, możemy zobaczyć to na poniższej grafice, gdzie pierwszą tablicę stanową obrazki wejściowe, a drugą odpowiadające im etykiety.
Choć powyższe grafiki prezentują dane uczące jako obrazki, w celu lepszego zobrazowania problemu, tak naprawdę do algorytmu w procesie uczenie przekazujemy dane w postaci wektorów uczących. Aby móc więc korzystać za algorytmu należy dokonać konwersji naszych obrazków na wektory. Robimy to w ten sposób, tworzymy macierz mającą 1 wiersz oraz liczbę kolumn odpowiadającą całkowitej ilości pikseli obrazka.
Mając więc obrazek o rozmiarach 16x16 powinniśmy utworzyć wektor o rozmiarach 1x256. Mając obrazek 3x3 powinniśmy utworzyć wektor o rozmiarach 1x9 co prezentuje poniższa grafika:
Na grafice pokazano obrazek binarny reprezentujący znak + o rozmiarach 3x3. Obok przedstawiono dwa sposoby na jego przechowywanie. Zmienna img nawiązuje do sposobu przechowywania obrazków w OpenCV, natomiast zmienna vector pokazuje jego reprezentację w postaci wektora.
Aby dokonać konwersji trzeba zapisać obrazek jednym ciągiem tak, aby dane były ułożone w kolejności następujących po sobie wierszy obrazu.
Po tym jak już nauczymy algorytm, możemy wykorzystać go by klasyfikował dla nas dostarczane wektory testowe jako cyfry. Aby to zrobić należy dostarczyć dwie wartości: obrazek do klasyfikacji oraz pewną liczbę K.
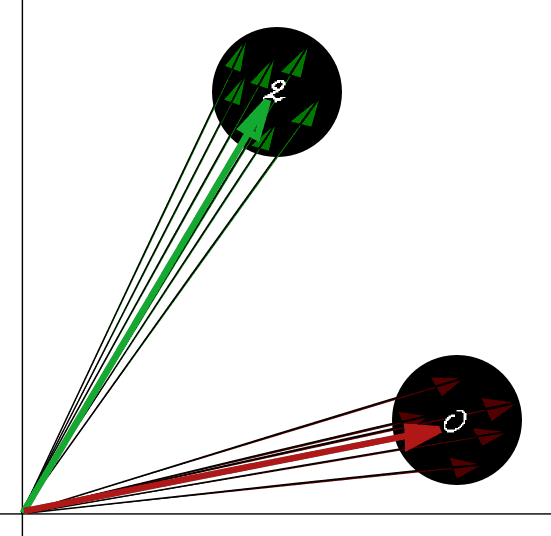
Aby zrozumieć czym jest liczba K spójrzmy na poniższą grafikę.
Cienkie zielone i czerwone strzałki z przeciętym grotem reprezentują nasze wektory uczące. Zielone są dla dwójek natomiast czerwone dla zer. Grube jednokolorowe strzałki: czerwona i zielona reprezentują obrazki uczące zamienione na wektory. Czarne kółka, są to kółka o średnicy równej naszej liczbie K.
Działanie algorytmu K-Nearest Neighborhood
Kiedy dostarczymy mu wektor testowy, reprezentowany powyżej poprzez grubą strzałkę, sprawdza całe jego sąsiedztwo w obrębie koła o średnicy "K" i znajduje wszystkie wektory uczące należące do tego sąsiedztwa.
Wynikiem będzie etykieta, która posiada najwięcej wektorów uczących we wspomnianym wyżej sąsiedztwie wektora testowego. Na podstawie zwróconej etykiety będziemy mogli stwierdzić jaka liczba została rozpoznana.
Dla zielonego grubego wektora na obrazku, w sąsiedztwie K reprezentowanym przez czarne kółko znajdują się tylko wektory uczące o etykiecie 2.0, a więc obrazek reprezentowany przez ten wektor zostanie sklasyfikowany jako dwójka.
Z powyższego wynika wniosek, iż bardzo ważnym elementem jest odpowiedni dobór wartości K. Czego amatorzy dokonują metodą prób i błędów.
Na koniec należy zaznaczyć, że algorytm KN jest najprostszą metodą klasyfikacji obiektów. Ma więc wiele wad. Aby działał poprawnie należy mu dostarczyć duża ilość danych trenujących, które trzeba trzymać w pamięci przez cały czas działania programu.
Następnie należy porównać każdy wektor testowy z wszystkimi wektorami trenującymi. Algorytm jest więc powolny i pamięciożerny. Jednakowoż niezrażeni tymi faktami zaimplementujemy go i zobaczymy jakie rezultaty możemy osiągnąć przy jego użyciu.
Aby móc uruchomić program należy jeszcze dysponować bazą danych uczących, należy ją pobrać z odpowiedniej strony. Konkretnie chodzi o plik semeion.data. W pliku tym zostały umieszczone 1593 obrazy ręcznie napisanych cyfr od 0 do 9 przez 80 różnych osób.
Zostały one zeskanowane, przeskalowane do rozmiarów 16x16 w odcieniach szarości, następnie wykonano progowanie i każdy piksel został zapisany w formie binarnej jako 0.0 lub 1.0 co odpowiada kolorom czarnemu lub białemu. Poniżej znajduje się kod programu.
#include <iostream>
#include <string>
#include <fstream>
#include <sstream>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include "opencv2/objdetect/objdetect.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/video/tracking.hpp"
#include "opencv2/ml/ml.hpp"
using namespace cv;
using namespace std;
int mouse_x = 0, mouse_y = 0; //Pozycja myszki
bool draw; //Zezwolenie na rysowanie ( gdy lewy klawisz myszy wcisnięty )
int img_x = 16, img_y = 16; //Rozmiary danych trenujacych
int img_size = img_x * img_y; //Rozmiary wektora trenujacego
void image_to_vector( Mat & vector, const Mat & img, int rows, int cols )
{
for ( int i = 0; i < rows; i++ )
{
for ( int j = 0; j < cols; j++ )
{
vector.at<float>(0, i * rows + j) = img.at<uchar>(i, j) / 255.0;
}
}
}
void my_mouse_callback( int event, int x, int y, int flags, void* param )
{
mouse_x = x;
mouse_y = y;
if ( flags == CV_EVENT_FLAG_LBUTTON ) draw = true;
else draw = false;
}
void vector_to_image( const Mat & vector, Mat & img, int rows, int cols, unsigned index )
{
for ( int i = 0; i < rows; i++ )
{
for ( int j = 0; j < cols; j++ )
{
img.at<uchar>(i, j) = 255 * uchar(vector.at<float>(index, i * rows + j));
}
}
}
int main()
{
const string window_name = "Wczytywanie bazy danych, czekaj...";
namedWindow(window_name, CV_WINDOW_AUTOSIZE);
Mat loading = Mat::zeros(Size(400, 100), CV_8UC3);
putText( loading, "Baza danych wczytana poprawnie", Point(50, 50), CV_FONT_HERSHEY_COMPLEX, 0.4, Scalar(120, 40, 80), 1, 8 );
imshow(window_name, loading);
/*Fragment odpowiadajacy ze wczytanie bazy danych z pliku*/
const string file_name = "semeion.data";
std::fstream file;
file.open( file_name.c_str(), ios::in);
if ( !file.good() )
{
cout << "Nie odnaleziono pliku " << file_name.c_str() << ".";
return -1;
}
Mat trainingvector(1, img_size, CV_32FC1);
Mat traininglabels(1, 1, CV_32FC1);
float buf;
unsigned char label_catch;
float label;
size_t index = -1;
while ( !file.eof() )
{
index++;
if ( index != 0 )
{
traininglabels.resize(index + 1);
trainingvector.resize(index + 1);
}
for ( int i = 0; i < img_size; i++ )
{
file >> buf;
trainingvector.at<float>(index, i) = buf;
}
for ( int i = 0; i < 10; i++ )
{
file >> label_catch;
if ( label_catch == '1' ) label = float(i);
}
traininglabels.at<float>(index, 0) = label;
}
traininglabels.resize(index); //Obcięcie pustego wiersza
trainingvector.resize(index); //który pojawia się ze względu na konstrukcję pętli
/*Koniec wczytywania danych*/
for ( int i = 40; i < 50; i++ )
{
Mat test( img_x, img_y, CV_8UC1 );
vector_to_image(trainingvector, test, img_x, img_y, i );
imshow(window_name, test);
string s;
stringstream out;
out << i;
s = out.str();
s += ".jpg";
vector<int> compression_params;
compression_params.push_back(CV_IMWRITE_JPEG_QUALITY);
compression_params.push_back(100);
imwrite(s.c_str(), test, compression_params);
waitKey();
}
/*Trenowanie klasyfikatora*/
KNearest KN(trainingvector, traininglabels);
cout << "Max. k = " << KN.get_max_k() << endl;
const string window_name2 = "Narysuj myszka liczbe ( 0-9 ) jednym pociagnieciem. ESC - koniec ";
namedWindow(window_name2, CV_WINDOW_AUTOSIZE);
setMouseCallback(window_name2, my_mouse_callback );
/*Pętla główna*/
while ( 1 )
{
Mat canvas = Mat::zeros( Size(600, 600), CV_8UC3 );
bool start = false;
/*Pętla rysująca liczbę*/
while ( waitKey(1) )
{
if ( draw )
{
circle(canvas, Point(mouse_x, mouse_y), 2, Scalar(255, 255, 255), 30, 8);
start = true;
}
else if ( start ) break;
imshow(window_name2, canvas);
}
/*Fragment odpowiadający z wykrycie konturu i obrysu narysowanej liczby*/
vector<vector<Point> > contours;
vector<Point> contours_poly;
Rect boundRect, newRect;
Mat cont, img_gary;
Mat digit;
cvtColor(canvas, cont, CV_BGR2GRAY);
cvtColor(canvas, img_gary, CV_BGR2GRAY);
findContours( cont, contours, CV_RETR_EXTERNAL, CV_CHAIN_APPROX_SIMPLE, Point(0, 0) );
for ( unsigned i = 0; i < contours.size(); i++ )
{
drawContours( canvas, contours, i, Scalar(125, 125, 250), 2 );
}
approxPolyDP( Mat(contours[0]), contours_poly, 3, true );
boundRect = boundingRect( Mat(contours_poly) );
rectangle( canvas, boundRect.tl(), boundRect.br(), Scalar(125, 250, 125), 2, 8, 0 );
/*Przeskalowanie liczby do rozmiarów danych uczących*/
digit = img_gary(boundRect);
resize(digit, digit, Size(img_x, img_y), 1.0, 1.0, INTER_CUBIC);
threshold(digit, digit, 1, 255, CV_THRESH_BINARY);
Mat testvector(1, img_size, CV_32FC1);
Mat predictedlabels(1, 1, CV_32FC1);
/*Przetworzenie obrazka na wektor*/
image_to_vector(testvector, digit, img_x, img_y);
/*Klasyfikacja wprowadzonej liczby*/
KN.find_nearest(testvector, KN.get_max_k(), &predictedlabels);
/*Wyswietlenie odpowiedzi*/
string s;
stringstream out;
out << predictedlabels.at<float>(0,0);
s = out.str();
putText( canvas, "Rozpoznana liczba : " + s, Point(20, 40), CV_FONT_HERSHEY_COMPLEX, 0.8, Scalar(125, 250, 80), 1, 8 );
putText( canvas, "ESC - Koniec, Spacja - Kolejna liczba", Point(20, canvas.cols - 40 ), CV_FONT_HERSHEY_COMPLEX, 0.5, Scalar(255, 40, 80), 1, 8 );
imshow(window_name2, canvas);
imshow(window_name, digit);
if ( waitKey() == 27 ) break;
}
file.close();
return 0;
}
Przystąpmy więc do analizy kodu. Na początek wczytujemy bazę danych zawierającą obrazki już w postaci wektorów trenujących oraz odpowiadających im etykiet z pliku semeion.data.
Po otwarciu pliku w edytorze tekstowym zobaczymy coś w rodzaju:
Zawartość pliku tekstowego.
Każda linia zawiera jeden wektor uczący, tzn. 256 następujących po sobie liczb. Obrazki są w formie binarnej dlatego też liczby to 0.0 oznaczają kolor czarny lub 1.0 dla koloru białego. Następnie po 256 liczbach opisujących wektor uczący następuje 10 cyfr 0 lub 1, które opisują etykietę obrazka. Przykładowo następujący ciąg:
1 0 0 0 0 0 0 0 0 0
daje nam etykietę równą 0 zasada jest następująca:
Z racji, że rozpoznajemy cyfry od 0 - 9 potrzebne nam 10 cyfr do opisu wszystkich etykiet przy czym pozycja 1 wśród tych dziesięciu ostatnich cyfr każdej linii determinuje wartość etykiety.
Zapamiętywanie etykiet
Pozostaje jeszcze kwestia zapamiętania naszych etykiet i wektorów uczących w programie. Użyjemy do tego macierzy. Macierze będą początkowo miały wymiary 1x256 dla wektorów uczących oraz 1x1 dla etykiet uczących. Wektory mają reprezentować obrazki 16x16, a etykiety są zapisywane jako pojedyncze liczby float. Tworzymy więc nasze macierze.
Mat trainingvector(1, img_size, CV_32FC1);
Mat traininglabels(1, 1, CV_32FC1);
Stała CV_32FC1 oznacza, że nasze macierze będą przechowywały informacje będące 32-bitow. liczbami float i będą miały 1 kanał. W naszej pętli wczytującej będziemy przy każdym nowym wczytywanym obrazku zwiększać liczbę wierszy macierzy z wektorami i etykietami o 1, aby pomieścić kolejne wektory uczące, gdyż będą one zapisane w następujących po sobie wierszach macierzy, ta sama sytuacje jest dla etykiet. Opisane operacje realizują metody.
Na koniec wczytywania należy jeszcze usunąć ostatni wiersz obu macierzy, gdyż ze względu na konstrukcję pętli dane w nim znajdujące się są niepoprawne.
traininglabels.resize(index); //Obcięcie pustego wiersza
trainingvector.resize(index); //który pojawia się ze względu na konstrukcję pętli
Trenowanie klasyfikatora
Trenowanie klasyfikatora sprowadza się do wywołania pojedynczej metody. Parametrami są wektory uczące zapisane wierszami w macierzy oraz odpowiadające i etykiety. Wypisujemy również największą znalezioną przez algorytm wartość K, którą potem wykorzystamy w drugiej fazie, odgadywania liczb.
Dalej mamy fragment wykrywający kontur narysowanej liczby. Na podstawie informacji o konturze tworzony jest prostokąt otaczający liczbę. Później następuje wycięcie obszaru z liczbą.
Następnie wykorzystujemy funkcję, która przetwarza obraz na wektor. Jej działanie jest bardzo proste i zostało już wcześniej wytłumaczone. Kolejne wiersze obrazu są zapisywane jeden po drugim w tworzonym wektorze.
Dzielenie przez liczbę 255.0 jest potrzebne po to by w wektorze dane były zapisane w postaci liczb 0.0 lub 1.0 czyli tak jak dla wektorów uczących wczytywanych z bazy danych. Zastosowanie indeksu i * rows + j pozwala zachować odpowiednie przesunięcie danych z obrazka w wektorze.
void image_to_vector( Mat & vector, const Mat & img, int rows, int cols )
{
for ( int i = 0; i < rows; i++ )
{
for ( int j = 0; j < cols; j++ )
{
vector.at<float>(0, i * rows + j) = img.at<uchar>(i, j) / 255.0;
}
}
}
W programie znajduje się też definicja funkcji, której działanie jest odwrotne do opisanej wyżej, a więc zamienia wektor na obraz. Parametrami są macierz z wektorami ułożonymi według wierszy, obraz wyjściowy, liczba wierszy i kolumn oraz numer wektora, który właściwie oznacza nr wiersza w macierzy z wektorami, który chcemy przetworzyć na obraz.
Funkcję można użyć np. do przetwarzania wektorów uczących na obrazy, aby wyświetlając je sprawdzić czy wszystko się poprawnie wczytuje i jak wyglądają dane uczące.
void vector_to_image( const Mat & vector, Mat & img, int rows, int cols, unsigned index )
{
for ( int i = 0; i < rows; i++ )
{
for ( int j = 0; j < cols; j++ )
{
img.at<uchar>(i, j) = 255 * uchar(vector.at<float>(index, i * rows + j));
}
}
}
Następnie mamy metodę, którą dokonujemy sklasyfikowania narysowanej liczby. Podajemy dla niej wektor z danymi do sklasyfikowania, wartość liczby K oraz adres macierzy, do której zostaną zwrócone etykiety.
Możemy naraz przekazać większą liczbę wektorów do sklasyfikowania, umieszczamy je wówczas wierszami w macierzy testvector.
Ilość wierszy macierzy testvector oraz predictedlabels musi być zgodna.
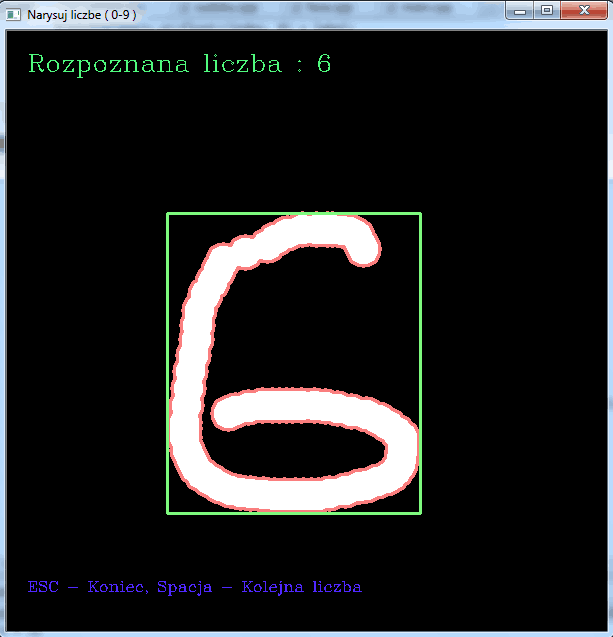
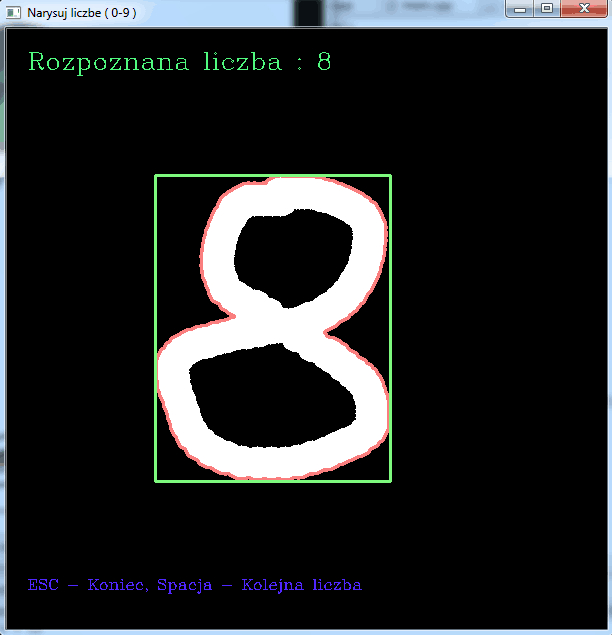
Efekt działania programu widoczny jest na poniższych zrzutach ekranu:
Podsumowanie
To by było na tyle. W załączniku zamieszczam jeszcze wykonalny program, aby Ci którzy nie mają zainstalowanego OpenCV mogli sprawdzić działanie omawianego algorytmu. Nie jest on idealny, ale działa całkiem dobrze. Aby móc uruchomić program należy mieć zainstalowany pakiet MinGW.
Dołącz do 30 tysięcy osób, które otrzymują powiadomienia o nowych artykułach! Zapisz się, a otrzymasz PDF-y ze ściągami (m.in. na temat mocy, tranzystorów, diod i schematów) oraz listę inspirujących DIY na bazie Arduino i Raspberry Pi.
To nie koniec, sprawdź również
Przeczytaj powiązane artykuły oraz aktualnie popularne wpisy lub losuj inny artykuł »
Dołącz do 30 tysięcy osób, które otrzymują powiadomienia o nowych artykułach! Zapisz się, a otrzymasz PDF-y ze ściągami (m.in. na temat mocy, tranzystorów, diod i schematów) oraz listę inspirujących DIY z Arduino i RPi.






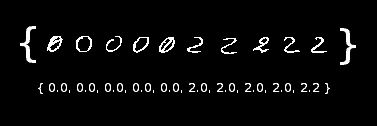
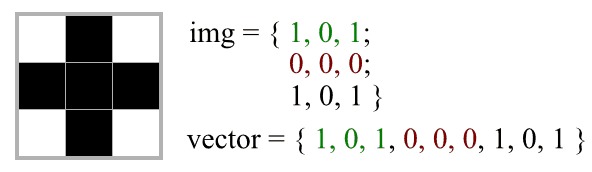



















Trwa ładowanie komentarzy...