Artykuł ten jest krótkim wprowadzeniem do Test Driven Development, dzięki któremu każdy może poznać podstawy i prześledzić przykłady pisania kodu zgodnie z tą techniką.
TDD docenią szczególnie osoby, które mają już dosyć mozolnego szukania błędów w programie i chciałyby przejść na trochę wyższy poziom.
W tym wpisie przedstawię Wam technikę, która zupełnie zmieniła sposób w jaki piszę oprogramowanie. Pozawala mi ona ograniczyć do niezbędnego minimum testowanie i debugowanie na sprzęcie. Poza tym, technika ta, zmienia nasz sposób myślenia każąc najpierw zastanowić się nad wymaganiami, przez co zwiększa się nasza świadomość na temat rzeczy, które mogą pójść źle.
Chodzi o Test Driven Development (TDD), czyli technikę wykorzystującą testy automatyczne. Zanim zaczniesz się jej uczyć, musisz zdobyć trochę biegłości w programowaniu w klasyczny sposób, jednak na pewno warto poświęcić później czas na naukę tej techniki - wspominałem już o tym w poprzednim artykule: 3 różnice w programowaniu: hobbystycznie vs. komercyjnie.
Jeśli jesteś bardzo początkującym programistą to nie musisz od razu zaczynać od poznawania TDD, bo może to być dla Ciebie zbyt trudne. W takim wypadku lepiej skupić się na nauce kodowania bez popełniania podstawowych błędów. Pomoże Ci w tym poniższy artykuł:
Dobry programista powinien wiedzieć jakie aspekty języka są niebezpieczne i umiejętnie sobie z nimi radzić. W artykule przybliżę kilka... Czytaj dalej »
Naturalne podejście do programowania
Zwykle nasze projekty rozwijamy z wyraźnym rozdzieleniem fazy pisania kodu i debugowania. Metoda ta jest czasem nazywana Code & Fix, albo Debug Later Programming. Polega ona na tym, że najpierw przez pewien czas piszemy, a potem próbujemy to uruchomić i sprawdzamy czy działa tak jak powinno. Czas mijający do uruchomienia programu bywa bardzo długi. Jeżeli więc popełnimy jakiś błąd, zdąży on dojrzeć i odpowiednio się ukryć, przez co potem musimy stracić sporo czasu, aby go znaleźć.
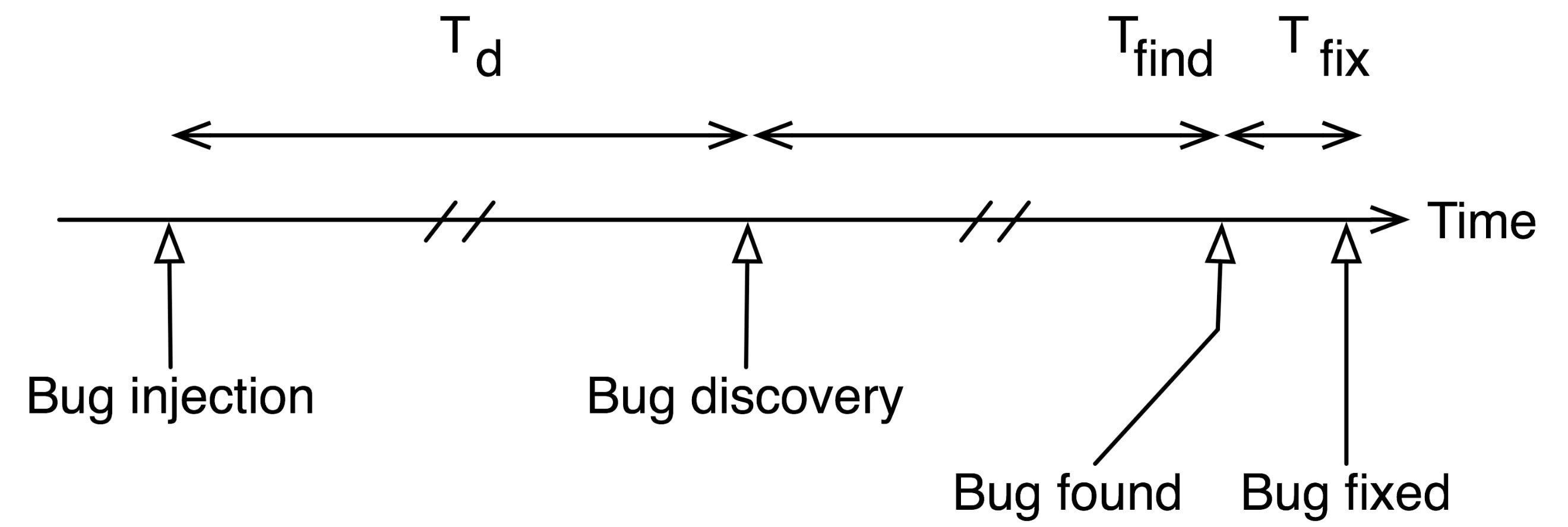
Dobrze obrazuje to wykres czasu życia buga przedstawiony przez Jamesa Grenninga w książce Test Driven Development for Embedded C:
Czas życia błędu
Im dłuższy czas Td od wprowadzenia buga do jego wykrycia, tym dłuższy czas Tfind potrzebny na odkrycie przyczyny problemu. Kiedy już znamy tę przyczynę, Tfix czyli czas naprawy jest zwykle krótki. Jednak jeżeli błąd znajdziemy bardzo późno, możemy już mieć dużo zależności nabudowanych na tym błędzie. Jeżeli rozwijamy projekt komercyjny, czas życia buga jest proporcjonalny do kosztów. Tym bardziej, że im więcej czasu mija, tym większa szansa, że zaangażujemy w problem więcej osób: innych developerów, testerów, a nawet użytkowników końcowych.
Code & Fix to naturalny sposób tworzenia kodu, którego każdy uczy się od samego początku i którym musimy się biegle posługiwać. Jednak wcale nie jest on najbardziej efektywny.
Problemy typowe dla systemów embedded
Problemem, o którym zawsze trzeba pamiętać w systemach embedded jest sprzęt. Zwykle debugujemy bezpośrednio używając sprzętowego debugera. Wgrywanie kodu na docelowy procesor trwa długo i czasem kończy się błędem. Nie wszystkie błędy łatwo jest odtworzyć przechodząc ręcznie przez kolejne linijki kodu w debugerze, dlatego testowanie w ten sposób jest nieefektywne.
Nikomu nie chce się też powtarzać wszystkich sprawdzeń po każdej zmianie. Możliwości sprzętowych debugerów są również mniejsze niż w przypadku tych na PC (rozbudowane sondy do debugowania są drogie). Poza tym system może być wielozadaniowy co dodatkowo utrudnia debugowanie.
Na szczęście nie musimy wszystkiego debugować na docelowym sprzęcie. Jest część, przy której od tego nie uciekniemy np. sterowniki peryferiów. Jednak cała logika mogłaby być z powodzeniem uruchamiana i testowania na komputerze. Nie od dziś wiadomo, że najbardziej efektywnym sposobem testowania jest automatyzacja. Dzięki temu mamy powtarzalne testy, które wykonują się szybko i bez angażowania uwagi programistów.
Czym jest Test Driven Development?
Test Driven Development to technika programowania odwracająca naturalną kolejność. Najpierw piszemy test definiujący wymagania stawiane naszemu programowi, a dopiero potem dopisujemy implementację przechodzącą ten test. Cały cykl dzielimy na krótkie iteracje, gdzie najpierw piszemy jeden test, potem dodajemy kod przechodzący wszystkie testy, a następnie poprawiamy strukturę kodu tak, aby testy dalej przechodziły.
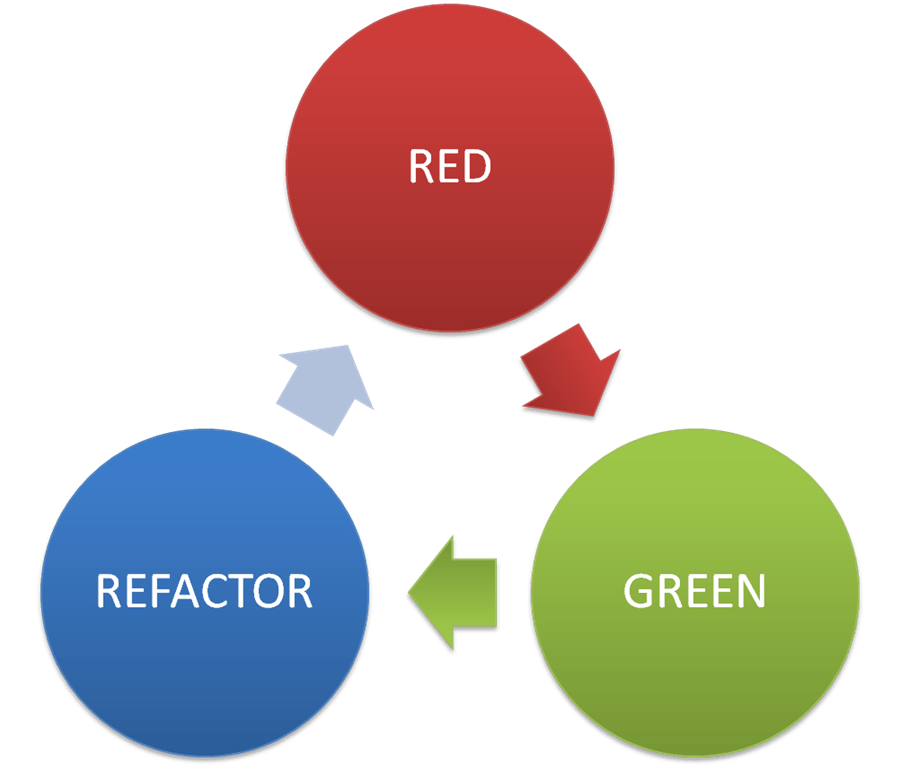
Te trzy operacje tworzą tak zwany Mikrocykl TDD, czyli Red-Green-Refactor.
Mikrocykl TDD, czyli Red-Green-Refactor
TDD - czym jest faza Red?
W fazie Red dodajemy tylko jeden test, który nie przechodzi i w ten sposób pokazuje jakiś brakujący element naszej implementacji. Szczególnie na początku może to być nieintuicyjne, ponieważ możemy łatwo wskazać wiele niespełnionych wymagań.
Najlepiej takie wymagania zapisać wtedy w formie komentarza w kodzie i wybierać po kolei przy następnych obiegach Mikrocyklu TDD.
Faza Red zmusza nas do przemyślenia wymagań zanim rzucimy się w wir kodowania. Dzięki temu nasz system będzie lepiej przemyślany. Czasem od razu wychwycimy jakieś niespójności i będziemy mogli doprecyzować działanie systemu zanim jeszcze napiszemy pierwszą linijkę kodu produkcyjnego.
TDD - czym jest faza Green?
W fazie Green dodajemy minimalną ilość kodu produkcyjnego potrzebną do przejścia testów. Tutaj również ręce będą nas świerzbić, aby od razu napisać ostateczną implementację. Jednak musimy się od tego powstrzymać i napisać tylko tyle ile wymagają od nas istniejące testy.
Czasem prowadzi to początkowo do absurdalnej implementacji, ale to nic. Ostatecznie testy wymuszą na nas dobrą implementację. Dzięki zachowaniu takiego reżimu mamy potem cały kod pokryty testami i w przypadku jakiejś zmiany wiemy, że nic nie zepsuliśmy.
TDD - czym jest faza Refactor?
W fazie Refactorpoprawiamy napisany kod nie zmieniając jego funkcjonalności. Gwarantują nam to istniejące testy, które zawsze możemy uruchomić i sprawdzić, że nic nie zepsuliśmy. Zwykle nie mając testów unikamy refaktoru lub robimy tylko kosmetyczne zmiany typu poprawienie nazw zmiennych.
Dzięki TDD możemy dokonywać głębszych zmian w strukturze kodu – dodawać lub usuwać funkcje, zmieniać wewnętrzną implementację. W końcu mamy testy, które wyłapią błędy!
To tyle teorii, pora na przykład praktyczny!
Przykładowy kod – bufor cykliczny
Jako przykład napiszemy sobie w TDD bufor cykliczny. Jest to struktura danych często wykorzystywana w embedded na przykład do komunikacji lub do składowania próbek pomiarowych. Pewnie większość czytelników wie jak on działa, jednak dla pewności zacznę od krótkiego opisu.
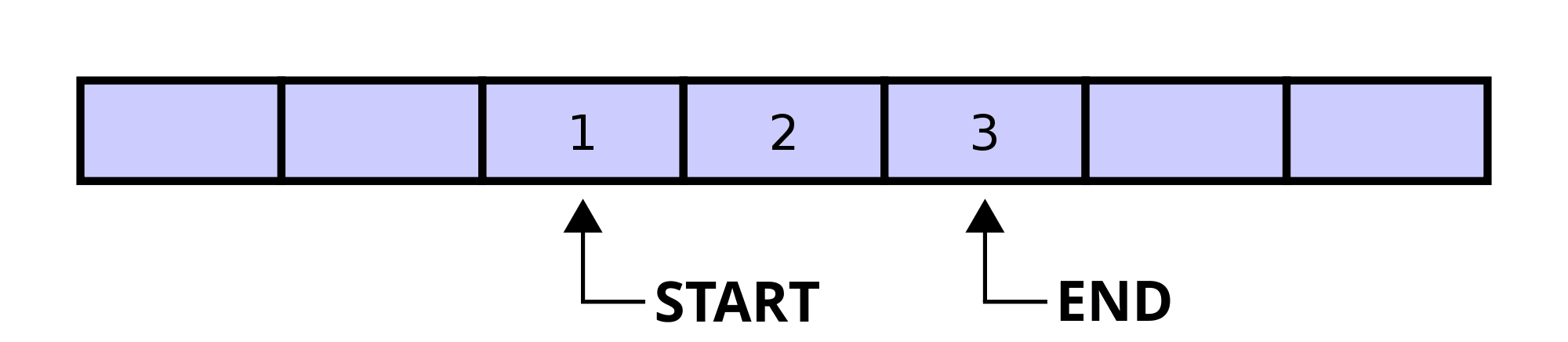
Bufor cykliczny składa się z tablicy o pewnym z góry ustalonym, maksymalnym rozmiarze oraz ze zmiennych przechowujących dwa indeksy – startowy, często nazywany głową (head), oraz końcowy, często nazywany ogonem (tail).
Głowa wskazuje pierwszy element, jaki zostanie odczytany z bufora. Odczyt spowoduje też przesunięcie indeksu na kolejny element. Ogon natomiast wskazuje ostatni element jaki został zapisany. Kolejny zapis spowoduje przesunięcie indeksu na następny element. Dzięki zastosowaniu tych wskaźników pierwszy element do odczytu nie musi się koniecznie znajdować na początku bufora.
Przy implementacji buforów cyklicznych ważne są dwa zagadnienia – obsługa dojścia do końca tablicy, oraz przepełnienie, czyli sytuacja kiedy zapisanie kolejnego elementu nadpisze pierwszy do odczytu. W takim wypadku mamy do wyboru nie przyjmować kolejnych danych lub nadpisać najstarsze.
Wymagane biblioteki i narzędzia
Kod będzie powstawał w czystym C, a jako frameworka testowego użyty zostanie Unity. Do budowania użyty będzie Cmake dzięki czemu projekt powinien budować się na każdym systemie operacyjnym. Przykład będzie kompilowany i uruchamiany na PC. Nie potrzebujemy więc żadnej płytki embedded. Nie będę na razie wchodził w konfigurowanie builda na PC i HW, ani inne szczegóły. Skupię się na podstawach TDD.
Opiszę zmiany w pliku testowym i produkcyjnych. Aby projekt działał należy jeszcze dostarczyć funkcję main uruchamiającą testy i każdy z nich dodać do runnera grupy testowej.
Zaczynamy od fazy Red, czyli utworzenia pierwszego testu. Nie mamy jeszcze nic, a z opisu powyżej wynika cały zestaw wymagań. Na początku warto więc wypisać je w komentarzach.
Zawartość pliku cyclic_buffer_test.c:
//after init buffer is empty
//after pushing single item, the same item is returned
//after adding 2 items, they are returned in the same order
//when max capacity is reached, first item is overriden
//number of items in the buffer is returned by function
//pass nullptr to functions
W pierwszej linijce używamy makra TEST z Unity, a jako argumenty dajemy nazwę grupy testowej (cyclic_buffer) i testu (BufferEmptyAfterInit). Następnie definiujemy i inicjalizujemy bufor, żeby w końcu sprawdzić, czy jest pusty za pomocą asercji.
Co to są grupy testowe, asercje, jak nazywać testy, co powinien zawierać pojedynczy test to wszystko zagadnienia trochę bardziej zaawansowane i nie będę się na nich tutaj skupiał. Zainteresowanych odsyłam na mojego bloga, gdzie można znaleźć dużo materiałów o unit testach i TDD.
Kompilujemy nasz projekt i otrzymujemy błędy:
../test/cyclic_buffer_test.c: In function 'TEST_cyclic_buffer_BufferEmptyAfterInit_':
../test/cyclic_buffer_test.c:19:17: error: storage size of 'buffer' isn't known
Nic dziwnego – mamy sam plik testu, a struktury cbuf jeszcze nawet nigdzie nie zdefiniowaliśmy. Błąd kompilacji również jest uznawany za błąd testu. Skutecznie zakończyliśmy więc fazę Red i możemy przejść do fazy Green, czyli implementacji kodu produkcyjnego. Zacznijmy od zdefiniowania typu cbuf.
Zawartość pliku cyclic_buffer.h:
struct cbuf
{
};
Tym razem po kompilacji czeka nas błąd linkera – brakuje funkcji cbuf_init i cbuf_is_empty:
c:/tools/mingw/bin/../lib/gcc/x86_64-w64-mingw32/8.2.0/../../../../x86_64-w64-mingw32/bin/ld.exe: CMakeFiles/unit_tests.dir/test/cyclic_buffer_test.c.obj:cyclic_buffer_test.c:(.text+0x76): undefined reference to `cbuf_init'
c:/tools/mingw/bin/../lib/gcc/x86_64-w64-mingw32/8.2.0/../../../../x86_64-w64-mingw32/bin/ld.exe: CMakeFiles/unit_tests.dir/test/cyclic_buffer_test.c.obj:cyclic_buffer_test.c:(.text+0x7e): undefined reference to `cbuf_is_empty'
Definiujemy więc brakujące funkcje. Idziemy tu po linii najmniejszego oporu – w fazie Green naszym celem jest przejście testów najprościej jak tylko będziemy mogli.
Unity test run 1 of 1
.
-----------------------
1 Tests 0 Failures 0 Ignored
OK
Jednak było w tym trochę przypadku – funkcja cbuf_is_empty zwraca losową wartość. Poza tym kod kompiluje się z ostrzeżeniami o nieużywanych argumentach i braku zwracanych wartości.
Mając przechodzące testy możemy więc zająć się usuwaniem ostrzeżeń. Zawartość pliku cyclic_buffer.c:
Zwracamy na sztywno wartość true, bo to najprostsza implementacja przechodząca testy. Na razie nas nie obchodzi, że jest niepoprawna. Jak napiszemy test udowadniający błąd – wtedy ją poprawimy. Takie podejście skłania nas do wybierania najprostszych rozwiązań. Czasem może się okazać, że taka uproszczona implementacja będzie wystarczająca.
Implementacja przy użyciu TDD - kolejne cykle
Ostrzeżenia mamy poprawione, nie ma nic więcej do refactorowania, możemy rozpocząć drugi cykl. Bierzemy więc kolejny test z listy. Po dodaniu elementu do bufora, odczytujemy ten sam element.
Mamy tu nowe funkcje, więc pierwsze co musimy poprawić to błąd linkera. Przy okazji komuś może wydawać się bez sensu stosowanie nieistniejących funkcji w teście, a dopisywanie ich dopiero potem. Jednak w ten sposób od razu używamy naszych funkcji i możemy lepiej wiedzieć jakiego interfejsu potrzebujemy, żeby było prosto i intuicyjnie. Tutaj odwrócenie kolejności również służy uproszczeniom.
W każdym razie przy błędzie linkera musimy dodać brakujące funkcje. Przyspieszę trochę opis i od razu zamieszczę też ich implementację.
Test wcale od nas nie wymaga jeszcze tablicy elementów ani wskaźników head i tail. Dlatego idziemy na skróty i na razie trzymamy tylko jeden element. Na potrzeby aktualnych testów to wystarczy.
Unity test run 1 of 1
..
-----------------------
2 Tests 0 Failures 0 Ignored
OK
Kolejny test sprawdza poprawność zapisu i odczytu dwóch elementów oraz obnaża naiwność naszej dotychczasowej implementacji.
Unity test run 1 of 1
...../test/cyclic_buffer_test.c:49:TEST(cyclic_buffer, AfterPushingTwoItemsTheyAreReturnedInTheSameOrder):FAIL: Expected 0x55AA00FF Was 0xFF00AA55
-----------------------
3 Tests 1 Failures 0 Ignored
FAIL
Teraz już implementacja musi być pełniejsza. Zawartość pliku cyclic_buffer.h:
Mamy już bufor działający w prostym przypadku, pora na obsługę wyjścia poza rozmiar tablicy.
Zawartość pliku cyclic_buffer_test.c:
TEST(cyclic_buffer, Overflow)
{
int i;
struct cbuf buffer;
cbuf_item_t item1 = 0x55AA00FF;
cbuf_item_t item2 = 0xFF00AA55;
cbuf_init(&buffer);
for (i = 0; i < CBUF_ITEM_CNT; i++)
{
cbuf_push(&buffer, item1);
cbuf_pop(&buffer);
}
cbuf_push(&buffer, item2);
TEST_ASSERT_EQUAL_HEX32(item2, cbuf_pop(&buffer));
}
Tym razem uruchomienie testu skutkuje błędem runtime – przekraczamy rozmiar wewnętrznej tablicy i nadpisujemy cudze dane (przy okazji: takie rzeczy dużo łatwiej debuguje się na PC). Mikrokontrolery nie mają ochrony pamięci i zwykle po prostu nadpiszemy jakieś dane i możemy długo nie wiedzieć, że program "poszedł w krzaki".
Pora na poprawienie implementacji. Zawartość pliku cyclic_buffer.c:
Unity test run 1 of 1
....
-----------------------
4 Tests 0 Failures 0 Ignored
OK
Pozostało jeszcze trochę testów z listy – ich wykonanie pozostawiam jako ćwiczenie dla czytelników. Przypominam również, że wszystkie potrzebne pliki dostępne są w repozytorium.
Zalety Test Driven Development
Spójrzmy na wyniki naszej pracy. Implementacja bufora cyklicznego jest prosta i dosyć dobrze znana. Bez TDD prawdopodobnie napisalibyśmy taki kod szybciej. Jednak czas potrzebny na stworzenie programu to nie tylko mechaniczne pisanie. Musielibyśmy przecież wykonać jakieś testy, musielibyśmy to robić ręcznie. Poza tym jeśli wrócimy do tego kodu po jakimś czasie to nie będziemy już pamiętać całego kontekstu i testowanie od nowa będzie trwało jeszcze dłużej. W przypadku TDD mamy testy automatyczne, które zawsze wykonują się tak samo szybko i sprawdzają te same asercje.
Dobrze nazwane i skupione na pojedynczym zadaniu przypadki testowe mogą służyć jako dokumentacja zachowania modułu.
Poza tym do sprawdzenia poprawności naszego kodu nie musieliśmy ani razu uruchomić debugera. Zupełnie wystarczy nam tekst zwracany przez konsolę.
Rozbudowany przykład TDD
Przedstawiony przykład jest dosyć prosty. Specjalnie na początek nie wybierałem niczego co zależy bezpośrednio od rejestrów sprzętowych. Takie moduły oddzielone warstwą abstrakcji od sprzętu mogą najszybciej skorzystać na TDD. Przy okazji są dobrym przykładem na początek. Polecam również inny przykład TDD na moim GitHubie, gdzie implementuję protokół komunikacyjny.
Podsumowanie
Musimy pamiętać, że TDD nie rozwiąże wszystkich naszych problemów. Istnieją typy błędów, które muszą być rozwiązywane na docelowym systemie np. współbieżność, wydajność, integracja między modułami. Warto więc wspomagać się również innymi dobrymi praktykami. Część z nich opisałem jakiś czas temu w poniższym artykule:
W pewnym momencie każdy programista musi przestawić się z hobbystycznego kodowania na bardziej profesjonalne podejście do tematu. Czym różni... Czytaj dalej »
Po więcej informacji na temat Test Driven Developmentodsyłam na mojego bloga, gdzie jest cały dział poświęcony tej tematyce. Jeżeli interesujesz się TDD i chcesz poznać odpowiedzi na jakieś konkretne zagadnienia – wystarczy, że zostawisz mi je używając tego formularza. Planuję stworzyć jeszcze więcej materiałów o TDD, nie tylko w formie artykułów, dlatego wszystkie propozycje są dla mnie ważne.
Co o tym sądzisz? Oceń ten wpis:
Średnia ocena 4.4 / 5. Głosów łącznie: 50
Nikt jeszcze nie głosował, bądź pierwszy!
Artykuł nie był pomocny? Jak możemy go poprawić? Wpisz swoje sugestie poniżej. Jeśli masz pytanie to zadaj je w komentarzu - ten formularz jest anonimowy, nie będziemy mogli Ci odpowiedzieć!
O autorze
Autorem wpisu jest Maciek Gajdzica zawodowo zajmujący się programowaniem systemów ebedded, w tym systemów safety-critical. Maciek prowadzi swojego bloga ucgosu.pl, na którym publikuje teksty o programowaniu systemów wbudowanych i robotyce. Jego artykuły kierowanie są głównie do bardziej zaawansowanych czytelników, którzy mają już opanowane podstawy (np. z kursów Forbota). Jeśli taka tematyka jest dla Was ciekawa to zapiszcie się na newsletter ucgosu.pl, a w ramach bonusu otrzymacie wtedy poradnik „Jak zwiększyć jakość kodu w projektach embedded? – darmowe narzędzia”.
Autor tekstu: Maciek (GAndaLF) Gajdzica Redakcja: Damian Szymański
Dołącz do 30 tysięcy osób, które otrzymują powiadomienia o nowych artykułach! Zapisz się, a otrzymasz PDF-y ze ściągami (m.in. na temat mocy, tranzystorów, diod i schematów) oraz listę inspirujących DIY na bazie Arduino i Raspberry Pi.
To nie koniec, sprawdź również
Przeczytaj powiązane artykuły oraz aktualnie popularne wpisy lub losuj inny artykuł »
Dołącz do 30 tysięcy osób, które otrzymują powiadomienia o nowych artykułach! Zapisz się, a otrzymasz PDF-y ze ściągami (m.in. na temat mocy, tranzystorów, diod i schematów) oraz listę inspirujących DIY z Arduino i RPi.

























Trwa ładowanie komentarzy...