System kontroli wersji to niezbędnik dla każdego programisty. Kopia plików, wracanie do stanu sprzed kilku dni i łatwe porównywanie różnych wersji kodu to tylko część zalet pracy z Gitem.
Jednak czy ma to sens, jeśli projekt prowadzimy samodzielnie? Odpowiedź wraz z praktycznymi przykładami znajduje się w tym poradniku.
Jeżeli słyszałeś już o Gicie, prawdopodobnie wiesz, że sprawdza się on doskonale w projektach, nad którymi pracuje wiele osób. A co, jeśli pracujesz sam? Czy w takim wypadku Git ma coś do zaoferowania? Tak. Pomyśl o następujących scenariuszach:
Chcesz wrócić do wersji kodu sprzed 2 tygodni, czwartek o 17:12. Albo do wczorajszej, bo wczoraj jeszcze działało, a jesteś absolutnie pewien, że nic nie zepsułeś.
Nie pamiętasz, po co modyfikowałeś dany plik albo nawet konkretną linię.
Fragment programu nie działa, nie wiesz od kiedy.
Chcesz wykonać mały eksperyment „na boku”, bez obaw, że zepsujesz „właściwą” wersję kodu.
Chcesz móc sprawdzić, jak wyglądały Twoje postępy w projekcie.
Chcesz łatwo opublikować swój kod w serwisie GitHub, aby się nim pochwalić lub pozwolić skorzystać komuś innemu.
We wszystkich tych przypadkach Git oferuje swoje wsparcie! Dlatego właśnie powstał ten artykuł – ma on pomóc osobom, które piszą programy hobbystycznie i do tej pory nie korzystały z dobrodziejstw Gita, czyli popularnego systemu do tzw. kontroli wersji. Jeśli jesteś zaawansowanym użytkownikiem Gita, to nic ciekawego tutaj nie znajdziesz – to miniporadnik dla zupełnie początkujących.
Praca z Gitem opiera się na używaniu repozytorium. Można powiedzieć, że jest to taka „baza danych” przechowująca informacje o aktualnym oraz historycznym stanie projektu. Na potrzeby początkujących można założyć, że jeden projekt to jedno repozytorium.
Logotyp projektu Git
Repozytorium może być lokalne lub zdalne. Lokalne to takie, które posiadasz na swoim komputerze. Natomiast zdalne znajduje się w innej lokalizacji (np. na popularnym GitHubie), do której istnieje odwołanie w lokalnym repozytorium. Korzystanie z takiego modelu pozwala na to, by nad projektem jednocześnie pracowało wiele osób.
Czym jest commit?
Podstawową jednostką pracy jest commit, czyli zapisany stan repozytorium w danym momencie – trochę jak spakowany katalog projektu, tyle że dużo bardziej inteligentny. Zdecydowana większość codziennej pracy z Gitem opiera się na tworzeniu, przeglądaniu i modyfikowaniu commitów.
Każdy commit składa się z kilku elementów, m.in.:
zmian, które wprowadza,
autora,
daty utworzenia,
komentarza,
wartości hash (SHA-1),
listy rodziców.
Commity są unikalne i rozróżnialne na podstawie hasha SHA-1. Jest on dosyć długi – w praktyce używa się jego skróconej wersji (pierwsze 6–8 znaków). Commity mogą też dostać dodatkowe identyfikatory poza hashem – dla porządku nazwijmy je etykietami.
Czym są tagi?
Jest kilka rodzajów takich etykiet. Jeden z nich to tzw. tagi. Wyobraź sobie, że Twój projekt osiągnął wersję 1.0 i chcesz łatwo dotrzeć do konkretnego commita zawierającego tę wersję – możesz stworzyć tag v1.0, v1.0.1 itd., aby łatwo to śledzić za pomocą odpowiedniej adnotacji w systemie.
Stosowanie tagów
Innym rodzajem etykiet są tzw. gałęzie, którymi nie będziemy się zajmować w tym poradniku. To szeroki temat – jego opanowanie nie jest potrzebne na początku samodzielnej pracy z Gitem.
Czym jest drzewo?
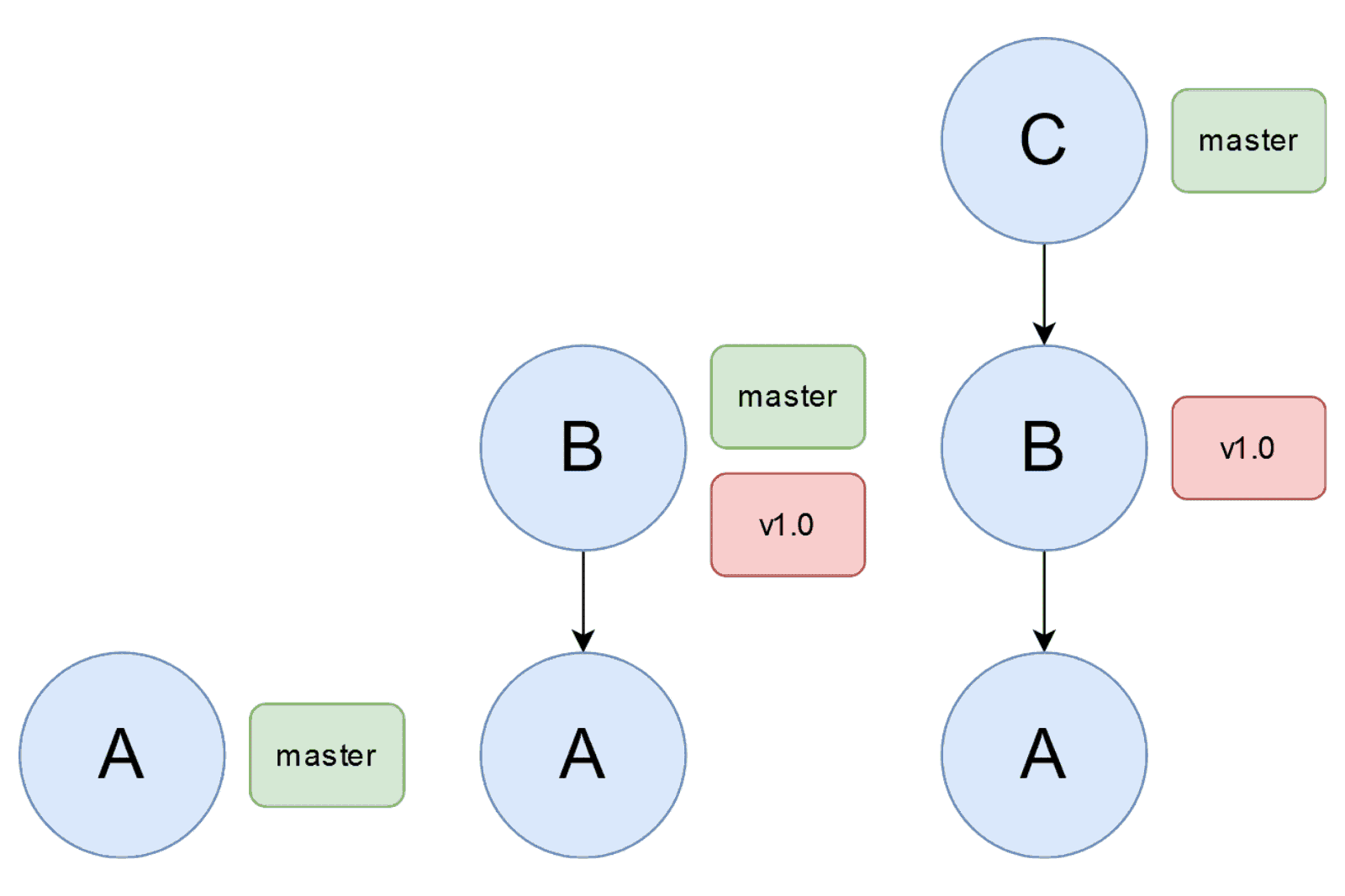
Każdy commit (poza pierwszym) ma przynajmniej jednego rodzica, czyli commita, na bazie którego powstał. Tworzy to strukturę podobną do drzewa. Poniższy rysunek przedstawia dwa przykładowe drzewa. Górne jest liniowe, dolne posiada rozgałęzienie. W obu przypadkach commit A jest pierwszy (jako jedyny nie posiada rodzica). Strzałka od X do Y oznacza „X jest potomkiem Y”.
Przykładowe drzewa commitów: górne liniowe, dolne z rozgałęzieniem
Skupmy się na przypadku z liniową historią – nie wszystko naraz. To, co warto zapamiętać o gałęziach, to to, że w każdym repozytorium zawsze istnieje domyślna gałąź o nazwie master. W przypadku liniowego projektu będzie to jedyna istniejąca gałąź. Co to dla nas oznacza? Ostatnio utworzony commit zawsze będzie miał dodatkową etykietę „master”, co ilustruje poniższy schemat.
W przypadku niektórych repozytoriów (od 2020 roku) nazwa „master” została zastąpiona przez „main” - sytuacja taka ma miejsce np. na GitHubie.
Nowo utworzony commit przejmuje etykietę z gałęzią rodzica (ale tylko gałęzią)
Praktyczny wstęp do Gita
Pora przejść do praktyki. Na początku będziemy potrzebowali dwóch rzeczy:
programu Git dla Twojego systemu operacyjnego – na potrzeby tego poradnika skupimy się na Windowsie. Odpowiedni program można pobrać z tej strony: https://git-scm.com/downloads.
Instalacja tego narzędzia na PC (standardowo) polega na klikaniu przycisku Next. Większość opcji wystarczy pozostawić domyślnych, warto zmienić tylko domyślny edytor tekstowy (Git czasami będzie go otwierał, najlepiej wybrać np. Notepad++).
Po instalacji Git będzie dostępny z każdego okna konsoli. Osobiście korzystam z Git bash, który instaluje się automatycznie. Aby to zrobić, klikamy prawym przyciskiem myszy (PPM) w dowolnym folderze i wybieramy opcję Git Bash here. Nie musimy robić żadnych dodatkowych konfiguracji.
Rozmiar tekstów można zmienić, klikając PPM na pasku tytułu i wybierając Options > Text.
Wszystkie komendy będziemy wykonywać w oknie Git bash
Na początku musimy ustawić dosłownie dwie opcje konfiguracyjne – nazwę użytkownika oraz e-mail. Aby to zrobić, wywołujemy dwa polecenia (bez znaków „>”; w cytowanych niżej fragmentach oznaczają one te linijki, które powinieneś wpisać; linie bez tego znaku są wyjściem zwracanym przez Gita).
Nazwa użytkownika pojawi się przy każdym commicie razem z adresem e-mail. Adres e-mail musi być taki sam jak ten, który użyty został na GitHubie.
Polecenie Git config służy do ustawiania i podglądania opcji konfiguracyjnych. Parametr --global oznacza, że chcemy ustawić opcję dla wszystkich repozytoriów – możliwe są różne ustawienia dla każdego repozytorium z osobna. Na końcu linii znajduje się opcja do ustawienia oraz jej nowa wartość.
Pierwszy projekt na GitHubie
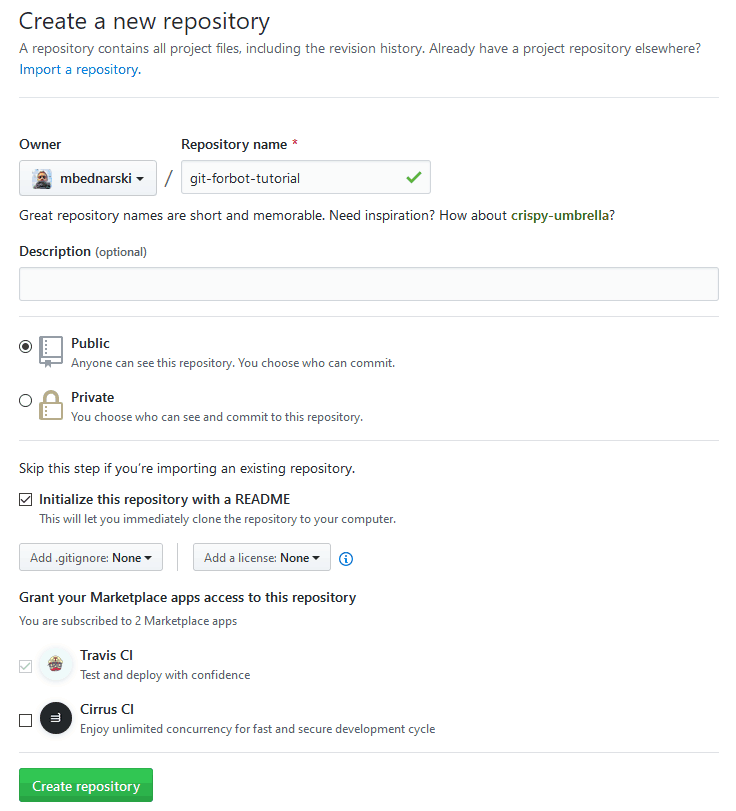
Aby uprościć sprawę repozytorium, załóżmy je od razu na GitHubie. Logujemy się na stronie, klikamy ikonę plusa w prawym górnym rogu ekranu i wybieramy New repository. Wpisujemy jego nazwę i zaznaczamy Initialize this repository with a README – GitHub utworzy automatycznie pierwszy commit z plikiem readme, co nieco ułatwi nam start.
Stworzenie nowego repozytorium
Po kliknięciu Create repository repozytorium zostanie utworzone. To jest nasze zdalne repozytorium. Teraz na jego bazie utworzymy repozytorium lokalne. W tym celu klikamy przycisk Code i z menu Clone wybieramy HTTPS, a następnie kopiujemy URL, który będzie tam widoczny.
Klonowanie repozytorium
Wracamy do pracy na naszym komputerze. W oknie Git bash przechodzimy do folderu, w którym trzymamy projekty (na potrzeby tego artykułu był to D:/code), i wpisujemy:
Jeśli nasze repozytorium na GitHubie oznaczyliśmy jako prywatne, to chwilę po wydaniu tego polecenia wyświetli nam się okno do logowania. Jeśli repozytorium jest dostępne publicznie, to nie będzie takiej konieczności.
Niezależnie od typu repozytorium (publiczne/prywatne) Git powinien utworzyć na naszym komputerze nowy katalog z projektem (sklonował go ze zdalnego repozytorium). Teraz wchodzimy do niego z poziomu Git bash (wydając polecenie cd nazwakatalogu) i wywołujemy git status.
> git status
On branch master
Your branch is up to date with 'origin/master'.
nothing to commit, working tree clean
Czytając po kolei:
jesteśmy w gałęzi master (domyślnej),
nasza lokalna gałąź jest aktualna względem zdalnej (origin/master),
nie mamy żadnych zmian widocznych dla gita.
Teraz warto wyjaśnić, czym jest origin. Tak nazywane jest zdalne repozytorium. W naszych przykładach origin będzie odnosić się do naszego zdalnego repozytorium na GitHubie. Odniesienia do zdalnych repozytoriów mogą się nazywać dowolnie (i może być ich więcej), jednak origin jest standardową praktyką.
Wyświetla ono listę commitów. Widzimy wymienione wcześniej elementy (adres e-mail został ukryty na potrzeby artykułu). Warto jeszcze wspomnieć, czym jest HEAD – to etykieta oznaczająca „aktualny” commit, czyli ten, który będzie rodzicem dla nowo utworzonego (po jego utworzeniu HEAD przesunie się automatycznie). Jest jeszcze origin/HEAD, ale tym nie musisz się na razie przejmować.
Wysyłamy pierwszy commit
Najwyższa pora utworzyć pierwszy commit. Przykład będzie w zwykłym C – dla Gita nie ma to żadnego znaczenia. W katalogu naszego lokalnego repozytorium zapisujemy plik main.c o poniższej treści (ale równie dobrze moglibyśmy zapisać tam zwykły plik tekstowy):
#include <stdio.h>
int main(){
puts("Hello world");
return 0;
}
Zapytajmy teraz Gita o status repozytorium:
> git status
On branch master
Your branch is up to date with 'origin/master'.
Untracked files:
(use "git add <file>..." to include in what will be committed)
main.c
nothing added to commit but untracked files present (use "git add" to track)
Pojawiły się nowe informacje. Git rozpoznał, że w naszym working copy (czyli de facto tym, co jest aktualnie w katalogu) pojawił się nowy plik – w stanie untracked. Stan ten oznacza, że Git nie będzie się tym plikiem interesował. Aby wskazać, że nowy plik jest częścią projektu, wydajemy polecenie:
> git add main.c
I jeszcze raz wydajemy polecenie git status (na początku warto wydawać tę komendę po każdej akcji – w ten sposób szybciej nauczysz się, co „widzi” Git).
> git status
On branch master
Your branch is up to date with 'origin/master'.
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
new file: main.c
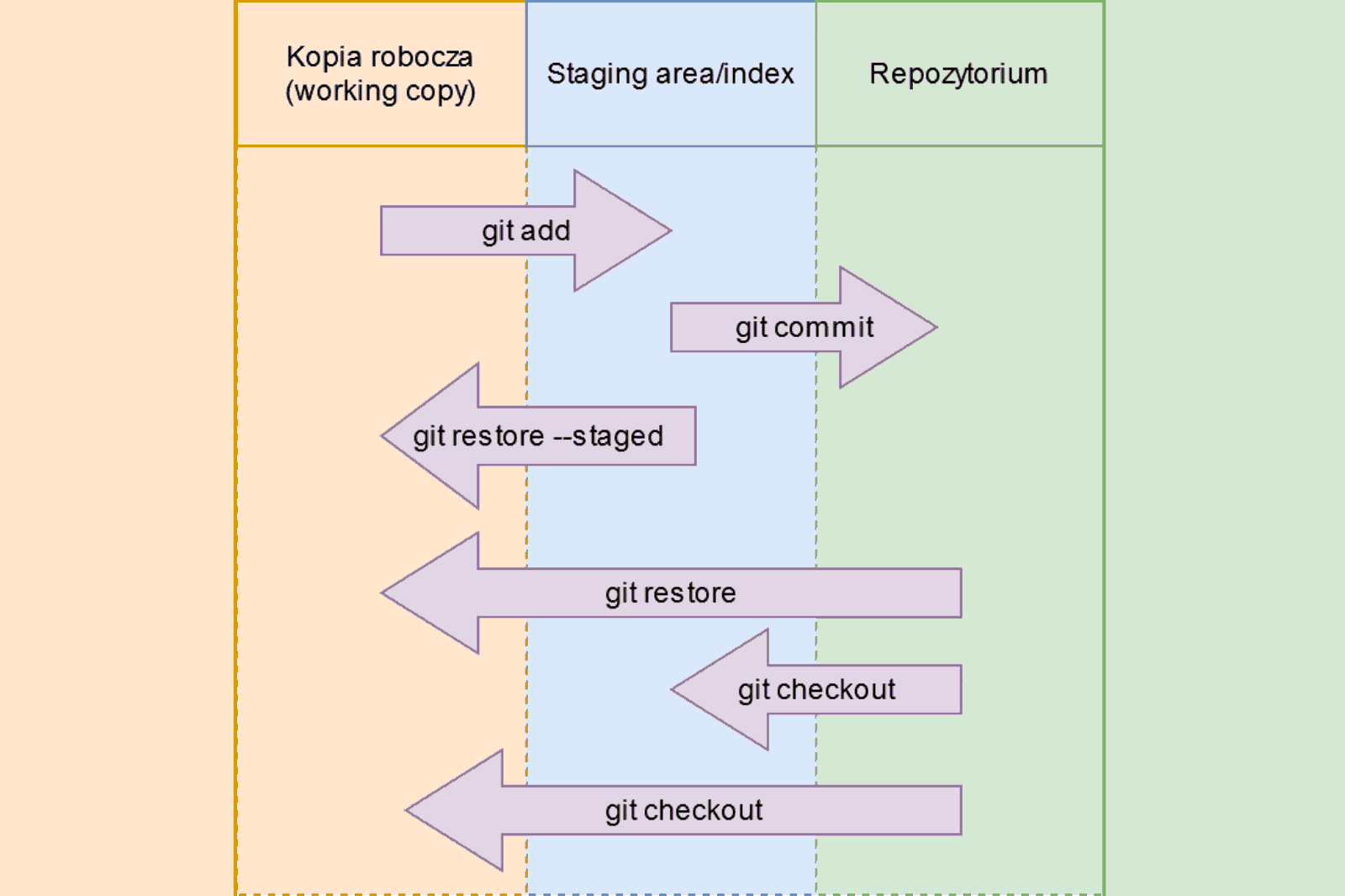
Status zmienił się na staged. Co to oznacza? Plik został dodany do tzw. staging area albo index – to miejsce, gdzie przygotowywany jest następny commit. W Gicie tworzenie commita jest dwuetapowe. Najpierw dodajemy zmiany do indeksu, usuwamy je z niego, modyfikujemy – dowolnie długo, do czasu, kiedy nasz commit jest już gotowy. Wtedy za jednym razem zapisujemy wszystkie zmiany z indeksu jako nowy commit, a indeks jest czyszczony i gotowy do przygotowania następnego.
Chcemy, aby nasz pierwszy commit zawierał tylko tę jedną zmianę, więc jesteśmy gotowi na:
Utworzyliśmy pierwszego commita! Jak widać, służy do tego polecenie git commit. Parametr -m ustawia komentarz, który powinien opisywać zmiany w projekcie. Jeżeli go pominiesz, to Git uruchomi edytor tekstowy, gdzie będziesz mógł go wpisać. Możemy to sprawdzić, wydając polecenie git log:
> git log
Kolejne commity
Od razu idziemy za ciosem i dodajemy kolejnego commita. Edytujemy plik README, wpisując do jego treści jakąś zawartość (normalnie – przez notatnik lub inny edytor tekstu). Przykładowa zawartość:
# git-forbot-tutorial
A small repository for git tutorial.
Oraz main.c:
#include <stdio.h>
int main(){
puts("Hello from git-managed world!");
return 0;
}
Dodatkowo, jeśli działamy faktycznie w programie napisanym w C i mamy zainstalowany kompilator, możemy skompilować nasz program (co sprawi, że w katalogu zostaną utworzone nowe pliki):
gcc main.c
Następnie, jak zwykle, najpierw git status:
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: README.md
modified: main.c
Untracked files:
(use "git add <file>..." to include in what will be committed)
a.exe
Widzimy, że Git rozpoznał zmiany w śledzonych plikach, jak również pojawienie się nowego. Dodajmy pliki źródłowe do indeksu:
git add README.md main.c
Następnie robimy commit:
git commit -m "Updated readme and hello world message"
Przetestowaliśmy właśnie najprostszy sposób tworzenia commitów!
Ignorowanie plików?
Plików a.exe oraz a.out, które zostały utworzone przez kompilator, nie chcemy dodawać, ponieważ są one plikami wynikowymi, a w naszym repozytorium powinny znajdować się tylko pliki źródłowe.
Tak samo nie chcemy, aby znalazły się tam logi czy pliki tymczasowe. Niestety, polecenie status będzie je pokazywać za każdym razem, burząc nam obraz sytuacji. Oczywiście istnieje na to sposób – możemy stworzyć plik .gitignore, w którym zawrzemy listę wzorców do ignorowania.
Zawartość naszego pliku .gitignore (bez żadnego rozszerzenia):
> git status
Untracked files:
(use "git add <file>..." to include in what will be committed)
.gitignore
Zgodnie z oczekiwaniami plik wynikowy jest zignorowany. Jednak sam plik .gitignore powinniśmy zcommitować. Zrób to sam w ramach dodatkowego ćwiczenia!
Wycofywanie zmian
Okej, potrafimy już dodawać zmiany. A co z ich usuwaniem?
Scenariusz 1: Przypadkiem zmodyfikowaliśmy plik i chcemy wrócić do wersji z ostatniego commita. Załóżmy, że kot przebiegł nam po klawiaturze i README wygląda teraz tak:
# git-forbot-tutorial
A small repository for git tutorial.
asdhawgdagwdkaw
Sprawdzamy status naszego repozytorium:
> git status
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: README.md
Aby wrócić do wersji z ostatniego commita, możemy wykonać:
> git restore README.md
To wszystko. Zmiany w pliku zostaną automatycznie cofnięte! Warto wiedzieć, że git restore jest dosyć nowym poleceniem (dlatego jeszcze mało popularnym). Inną metodą jest wydanie polecenia:
> git checkout -- README.md
Scenariusz 2: Dodaliśmy zmiany do indeksu, ale jednak nie chcemy ich commitować – co robić? Dla testu wprowadźmy najpierw zmiany do pliku main.c:
#include <stdio.h>
int main(int argc, char** argv){
puts("Hello from git-managed world!");
puts("I can handle args");
return 0;
}
I dodajemy je do staging area:
> git add main.c
Niestety zaszła pomyłka i nowy commit miał wyglądać tak:
#include <stdio.h>
int main(int argc, char **argv){
puts("Hello from git-managed world!");
puts("I can handle args");
return 0;
}
Nie ma problemu! Popraw plik i zobaczmy, co pokaże status:
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
modified: main.c
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: main.c
Widać, że plik main.c pojawił się zarówno w staging area, jak i jako not staged. Interpretacja jest prosta – część zmian została dodana do indeksu, a część jeszcze nie. Jeżeli teraz wykonamy commit, to znajdą się tam tylko poprzednio dodane zmiany. My jednak teraz chcemy dodać poprawki – wykonaj git add main.c i sprawdź status, a następnie wykonaj commit.
Scenariusz 3: A co, jeśli nie chcemy poprawiać zmian, tylko po prostu je wycofać ze staging area? Tutaj przyda się poniższe polecenie – po jego wykonaniu zmiany zostaną wycofane z indeksu, ale pozostaną w kopii roboczej.
> git restore --staged <file>
Dla testu modyfikujemy ręcznie plik README, a następnie wydajemy kolejno poniższe polecenia, oczywiście analizując przy okazji to, co zwraca nam za każdym razem git status.
> git add README.md
> git status
> git restore --staged
> git status README.md
Jak usuwać pliki z repozytorium?
A co, jeżeli chcę całkowicie usunąć jakiś plik z repozytorium? Na początek utwórzmy i dodajmy nowy plik (może być pusty):
Changes not staged for commit:
(use "git add/rm <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
deleted: info.txt
Git zarejestrował usunięcie pliku, teraz wystarczy git add info.txt i git commit – gotowe!
Tworzenie tagów
Wspomnieliśmy, że Git pozwala dopasowywać dodatkowe etykiety do commitów. Zrób to teraz! Wydaj polecenie git log, wybierz dowolny commit i skopiuj pierwsze 6 znaków jego SHA-1. Następnie wyjdź z logów (naciskając klawisz Q) i wywołaj:
> git tag -a -m "Version 1.0" v1.0 WYBRANE_SHA
Parametr -a tworzy tzw. annotated tag, który zawiera autora, komentarz (dodany parametrem -m). Z kolei v1.0 to nazwa tagu. Na końcu znajduje się hash commita, który ma być otagowany. Jeżeli go pominiesz, to Git wybierze aktualny tag (ten, gdzie wskazuje HEAD, ale o tym jeszcze za chwilę).
Istnieją również tzw. lightweight tag, które zawierają tylko nazwę taga (bez parametrów -a i -m). Osobiście rekomenduję głównie używanie tagów zanotowanych – ze względu na większą ilość informacji lekkich używam tylko do tagów tymczasowych.
Przeglądanie historii
Na początku wspomniałem, że Git pozwoli Ci cofać się w czasie – zobaczmy, jak to działa. Załóżmy, że chcesz wrócić do konkretnego stanu repozytorium. Zacznijmy od tego otagowanego. Na początek upewnij się, że zarówno working copy, jak i indeks są czyste – nie jest to wymagane, ale będzie ułatwieniem. Aby przejść do historycznej wersji kodu, wpisz:
> git checkout v1.0
Zamiast v1.0 może być dowolny istniejący tag lub ID commita. Git wyświetla długi komunikat – w skrócie repozytorium jest w stanie detached HEAD. Oznacza to, że nie jesteś w żadnej gałęzi. Na tym etapie rekomenduję uznać, że taki stan oznacza „nie rób żadnych zmian w kodzie, które możesz chcieć zachować”.
To, co nas w tej chwili interesuje, to np.: HEAD is now at 6146854 Added .gitignore – w kopii roboczej znajduje się wersja kodu z tego konkretnego commita i HEAD (czyli wskaźnik „aktualnego” commita). Możesz np. sprawdzić, jakie są różnice w pliku main.c względem najnowszego:
Przed wykonaniem poniższego polecenia trzeba się upewnić jaka jest nazwa głównej gałęzi w repozytorium. W niektórych sytuacjach zamiast „master” będzie to „main”.
> git diff HEAD master main.c
Czyli „pokaż mi różnicę między commitami HEAD oraz master w pliku main.c”. Polecenie to zwróci nam wynik, jeśli pliki będą się faktycznie różniły. Wiesz, co oznacza HEAD. Przypomnę, że master jest etykietą najnowszego commita w gałęzi master.
Git diff ma dużo więcej możliwości – warto zapoznać się jego z dokumentacją!
Okej, zrobiliśmy inspekcję i chcemy wrócić do mastera. Co zrobić? Wystarczy wywołać:
> git checkout master
Po wydaniu tego polecenia wrócimy do naszej gałęzi, HEAD zostanie również odpowiednio ustawiony!
Przywracanie plików w wersji historycznej
Załóżmy, że znalazłeś, w którym miejscu historii wprowadziłeś błąd, i chcesz przywrócić historyczną wersję pliku. Wystarczy wykonać:
> git checkout ID_COMMITA nazwa_pliku
Czyli „przywróć plik nazwa_pliku z commita o id ID_COMMITA”, gdzie za id można podstawić skrócony hash lub tag. Zmiana od razu wyląduje w staging area.
Podsumowanie (niektórych) operacji
Synchronizacja ze zdalnym repozytorium
Kiedy wejdziesz na swoje repozytorium na GitHubie, zobaczysz, że… nic się nie zmieniło – taka jest idea Gita – system jest rozproszony i wszystkie zmiany dzieją się lokalnie. Aby przekazać swoje zmiany do zdalnego repozytorium, wydaj polecenie:
> git push
Git poprosi Cię o zalogowanie się do konta na GitHubie. Po pomyślnym wykonaniu polecenia odśwież stronę. Wszystkie swoje zmiany zobaczysz na stronie projektu.
Git, jak każde zaawansowane narzędzie, pokazuje pełnię mocy, jeśli jest używany poprawnie. Wymaga to nieco doświadczenia, ale jest kilka dobrych praktyk, które możesz wdrożyć od razu:
Wiadomości w commitach powinny być dokładne.
Jeden commit = jedna zmiana (w sensie logicznym jak najbardziej może to być wiele plików).
Staraj trzymać się working copy czyste; sytuacja, kiedy przez tygodnie masz untracked files i nie dodałeś ich do gitignore, „bo później się przydadzą”, to proszenie się o kłopoty.
Commituj często – w pracy zwykle robię około 10 commitów dziennie.
Często używaj poleceń log oraz status.
Zanim zaczniesz używać Gita w swojej pracy magisterskiej, nabierz nieco doświadczenia na mniejszym, hobbystycznym projekcie.
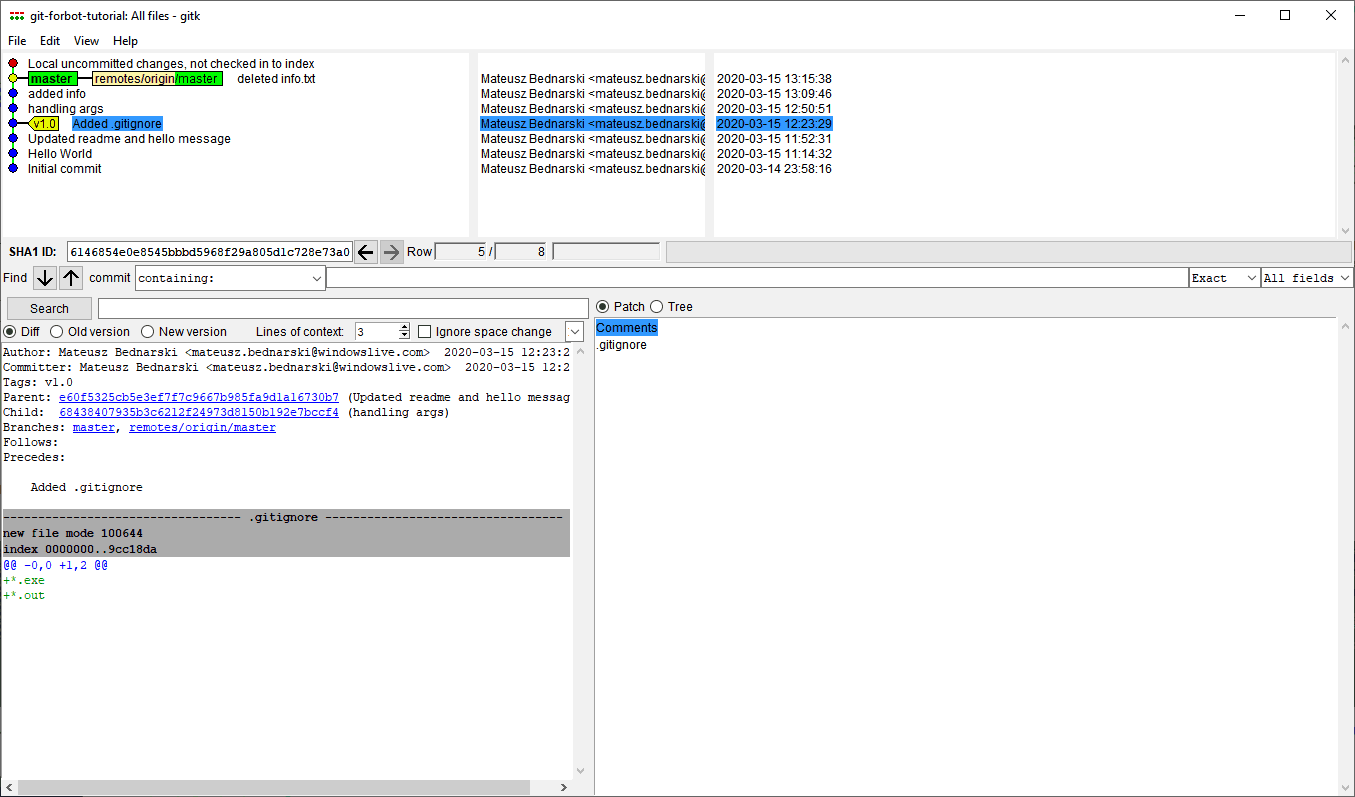
Wypróbuj narzędzie gitk do graficznego przeglądania drzewa.
Nie rekomenduję używania narzędzi do obsługi Gita wbudowanych w IDE – często robią one więcej, niż sugerują nazwy poleceń.
Git miejscami jest mało intuicyjny – nie zrażaj się, że czegoś od razu nie rozumiesz, to bardzo ważne narzędzie w rękach każdego świadomego programisty.
Interfejs programu gitk
Podsumowanie
Za nami krótki wstęp do Gita, który miał ekspresowo przeprowadzić początkujących przez największe podstawy. Praca z Gitem wymaga wprawy, ale ma dużo zalet. Właściwie każdy programista, który podchodzi do tematu poważnie, korzysta z jakiegoś systemu kontroli wersji.
Co o tym sądzisz? Oceń ten wpis:
Średnia ocena 4.8 / 5. Głosów łącznie: 64
Nikt jeszcze nie głosował, bądź pierwszy!
Artykuł nie był pomocny? Jak możemy go poprawić? Wpisz swoje sugestie poniżej. Jeśli masz pytanie to zadaj je w komentarzu - ten formularz jest anonimowy, nie będziemy mogli Ci odpowiedzieć!
Warto oswajać się z tym systemem od początku. Kiedyś nadejdzie moment, że przywrócenie plików z Gita uratuje projekt (lub uchroni Cię przed godzinami żmudnego debuggowania), i wtedy nie będziesz mieć wątpliwości, że warto było poświęcić czas na „git commit”.
W pewnym momencie każdy programista musi przestawić się z hobbystycznego kodowania na bardziej profesjonalne podejście do tematu. Czym różni... Czytaj dalej »
Dołącz do 30 tysięcy osób, które otrzymują powiadomienia o nowych artykułach! Zapisz się, a otrzymasz PDF-y ze ściągami (m.in. na temat mocy, tranzystorów, diod i schematów) oraz listę inspirujących DIY na bazie Arduino i Raspberry Pi.
To nie koniec, sprawdź również
Przeczytaj powiązane artykuły oraz aktualnie popularne wpisy lub losuj inny artykuł »
Dołącz do 30 tysięcy osób, które otrzymują powiadomienia o nowych artykułach! Zapisz się, a otrzymasz PDF-y ze ściągami (m.in. na temat mocy, tranzystorów, diod i schematów) oraz listę inspirujących DIY z Arduino i RPi.



























Trwa ładowanie komentarzy...