Przeszukaj forum
Pokazywanie wyników dla tagów 'konkurs2020'.
Znaleziono 40 wyników
-
Mit o naszym poznawczym uniwersalizmie, o naszej gotowości odebrania i zrozumienia informacji całkowicie, przez jej pozaziemskość, nowej - trwa niewzruszony, chociaż, otrzymawszy posłanie z gwiazd, zrobiliśmy z nim nie więcej, niżby zrobił dzikus, który, ogrzawszy się u płomienia podpalonych dzieł najmędrszych, uważa, że doskonale owe znalezisko wykorzystał! - Stanisław Lem Głos Pana Tymi słowami Stanisław Lem konkludował próbę odszyfrowania przez Człowieka tajemniczego sygnału z kosmosu, którego odkrycie było dziełem przypadku. Sygnał, pochodzący najprawdopodobniej od obcej cywilizacji z krańca Kosmosu stał się zagadką, poddającą w wątpliwość ludzką poznawczość. Pomimo licznych prób i wzajemnej współpracy grona naukowców, wiadomość udało się rozpracować tylko częściowo, a nawet uzyskany wynik stanowił dalsze ogniwo niezrozumienia i zdumienia. Chcąc opowiedzieć czym był sygnał, jak został odkryty i do jakich odkryć poprowadził grupę uczonych należy sięgnąć do książki Stanisława Lema „Głos Pana”. Ten wpis brał udział konkursie na najlepszy artykuł o elektronice lub programowaniu. Sprawdź wyniki oraz listę wszystkich prac » Partnerem tej edycji konkursu (marzec 2020) był popularny producent obwodów drukowanych, firma PCBWay. Dlaczego przytoczone zostały właśnie te słowa i w jaki sposób korespondują one z tematem artykułu? Jeżeli miałeś nadzieję, że przedstawione zostaną kulisy pierwszego kontaktu z obcą cywilizacją, to niestety możesz się lekko rozczarować, ale ta era (jeszcze) nie nadeszła - jakkolwiek byśmy tego nie chcieli i próbowali zaklinać czasoprzestrzeń. Pozwólmy, rzucić sobie światło na niemniej, a nawet równie ciekawą materię. Komunikacja Powracając do powieści Stanisława Lema, komunikacja, choć jednostronna przebiega tam zdalnie. Z otchłani kosmosu dobiega sygnał w postaci ciągu neutrin – cząstek nie posiadających masy, zdolnych do przenikania materii. Cząstki te nadawane są w pewnych odstępach czasowych. Uważnie przyglądając się całości emisji dostrzec można, pewne zależności powodujące, że w procesie widoczna jest pewna wiadomość. Komunikatu zostaje zapętlony, a zarówno nadawca jak i odbiorca kosmicznego komunikatu nie widzą się wzajemnie. Są przekonani o wzajemnym istnieniu, ale fizycznie, poza komunikatem nie mają ze sobą jakiegokolwiek innego kontaktu. Czy cała idea tego procesu nie wygląda w pewien sposób znajomo? Tak, to Test Turinga! Obca cywilizacja przesyłając komunikat zainicjowała proces Testu Turinga, w oczekiwaniu na sprzężenie zwrotne, które miało udowodnić naszą inteligencję. Barierą oddzielającą „komputer” od człowieka jest ogromna przestrzeń kosmiczna, a sam sygnał przyjmuje nieco inną formę, niż tą jaką przewidział w swoich założeniach Alan Turing. Niestety, cały mistycyzm pierwszego kontaktu sprowadzony zostaje do trochę bardziej prozaicznego, wcześniej znanego pojęcia. Ale czy spoglądanie w niebo to jedyny sposób na nawiązanie dialogu z przyszłością? Schodzimy na ziemię Dialog już trwa, rozmówcą jesteś również Ty, ale to Alan Turing jako jeden z pierwszych dostrzegł możliwość rozmowy Człowieka z maszyną. Tak, sztuczna inteligencja, bo o niej mowa, choć nieco bardziej ziemska posiada kosmiczne możliwości. To sztuczna inteligencja ma nasze dane, potrafi nimi skutecznie manipulować, gromadzić i na podstawie ich podejmować poważne decyzje. Prowadzi nasze auta, wynajduje nowe lekarstwa, decyduje czy będziesz wiarygodnym kredytobiorcą, a nawet bywa „zwyczajnym rozmówcą”. Komunikacja z SI przybiera różne formy, choć dysponujemy szeregiem języków programowania, gotowymi rozwiązaniami informatycznymi, a sama wiedza jest niemalże powszechnie dostępna to właśnie komunikacja stanowi najważniejsze zagadnienie rozwoju sztucznej inteligencji. O ile, gdy stworzone przez nas oprogramowanie zawarte w ryzach algorytmów jest nam niemal całkowicie posłuszne, o tyle sztuczna inteligencja w swojej idei zaczyna „żyć własnym życiem” – życiem tak autonomicznym, że język cyfrowy schodzi momentami na drugi plan, a nawet może nie być samodzielnie wystarczający. Oczywiście nic nie wskazuje na to, abyśmy mieli w całości zrezygnować z języków programowania na rzecz… no właśnie czego? Rozmowy? Siri, Asystent Google czy Alexa to systemy bazujące na sztucznej inteligencji, które uprzednio zaprogramowane dalszą część cybernetycznego życia spędzają komunikując się poprzez komunikację werbalną. Całość procesu: gromadzenie danych, przetwarzanie czy wydawane przez nią komunikaty to głównie wiadomości głosowe. Jest to oczywiste i zrozumiałe, ale pod postacią wygodnej dla nas funkcjonalności rozpoznawania głosowego oraz syntezatora mowy, ukryty pozostaje znaczący krok w rozwoju komunikacji na linii człowiek – maszyna. W sposób nowoczesny, komfortowy, ale jednocześnie pionierski przeszliśmy z zerojedynkowej narracji do „języka człowieka”. Choć nie zawsze precyzyjnie i składnie, to rzeczywiście – maszyna rozmawia z człowiekiem. Wygląda to jak pierwszy krok w drodze do tego czym zwykliśmy nazywać świadomością. Doskonale operuje liczbami, w przeciągu ułamka sekundy zna odpowiedzi na liczbowe problemy, tworzy skomplikowane modele cyfrowe, wszystko co deterministyczne i natury arytmetycznej jest w jej zasięgu. Ma natomiast problem z pojęciami, które ironicznie, człowiekowi przychodzą nieco łatwiej – pojęciami abstrakcyjnymi. Czy w milionach tranzystorów może popłynąć rewolucyjna idea, zupełnie abstrakcyjna myśl, zakodowana jako „kilka zer i jedynek” ? Wszystkie wyniki pracy systemów sztucznej inteligencji, a w konsekwencji jej osiągnięcia bazują na dużych ilościach danych którymi jest „karmiona” i kolejno trenowana. Choć ten ciąg przyczynowo-skutkowy wydaje się pozostawać niewzruszony to ludzki umysł, również wiedziony ogromną ilością danych, popularniej zwanych bagażem doświadczeń potrafi myśleć w sposób abstrakcyjny, definiować swój byt i być samoświadomy. Czy samoświadomość sztucznej inteligencji to kwestia większej ilości danych i nowych połączeń sieci neuronowej? Jeżeli tak, to hipotetycznie moglibyśmy wskazać konkretny punkt, w którym owa sieć osiąga świadomość. Czy jest to wykonalne - jest nam ciężko określić, chociaż sam temat świadomości cyfrowej stanowi nie tylko obiekt: badań specjalistów, westchnień futurologów, ale także.. Rozważań filozofów Czy prekursorzy inżynierii elektronicznej tworząc pierwsze układy scalone, mogli doszukiwać się głębszego metafizycznego sensu w sygnałach? Jest to wątpliwie, jednak przyszłość przygotowała własną wizję - mariaż teorii informacji z humanizmem. Dwie dziedziny należące do przeciwległych biegunów nauki, połączyła potrzeba współpracy na rzecz ustalenia wspólnych mianowników etycznych dla człowieka i maszyny. Choć z pozoru nierealna wizja potrzeby dzielenia się wykuwaną przez lata ludzką moralnością, z pieśni przyszłości staje się prozą współczesności. Autonomiczne auta wyposażane są w systemy decyzyjne, których zadaniem jest podjęcie odpowiedniego wyboru w sytuacji zagrożenia życia. Ale czy faktycznie potrafimy zdefiniować odpowiedni wybór? Czy nie jest tak, że już na przestrzeni dialogu międzyludzkiego napotykamy problem z jasnym zdefiniowaniem systemu norm, który byłby spójny? Subiektywność, rozumiana bliżej jako doświadczenia życiowe i system wyznawanych przez nas wartości powodują dywersyfikację wersji algorytmu prawidłowego działania. Czy w niemożliwym do uniknięcia przypadku potrącenia pieszego system postanowi potrącić dziecko czy osobę starszą, osobę schorowaną czy kobietę w ciąży? Odpowiedź nie jest prosta, o ile w ogóle takowa istnieje. Wizja Elon Musk – właściciel firmy Tesla, produkującej innowacyjne samochody elektryczne do projektowania systemów autonomicznej jazdy wśród specjalistów z dziedzin IoT, Data Science, programistów systemów embedded rekrutuje osoby odpowiedzialne za moralne uposażenie systemów decyzyjnych – ekspertów z dziedziny filozofii. To oni są odpowiedzialni za wszystkie potencjalne dylematy natury moralnej. Zatrudnienie filozofów, ale również humanistów ogólnie w sektorze AI (Artificial intelligence – ang. Sztuczna Inteligencja) będzie niewątpliwie rosło. Urzeczywistnia się coś, o czym wcześniej nawet nie myśleliśmy – cykl technologiczny zatacza koło, a my uczłowieczamy technologię. Nie chodzi tu o podniosłe zwroty i patetyczne doszukiwanie się archetypu stwórcy w programiście – technologia brnie do przodu, a wraz z nią rola nas – jej głównych odbiorców i współrozmówców ulega ewolucji.








-

Kurs ESP8266 - #4 - wykresy, zapis do FS, mini smartdom
Leoneq opublikował temat w Artykuły użytkowników
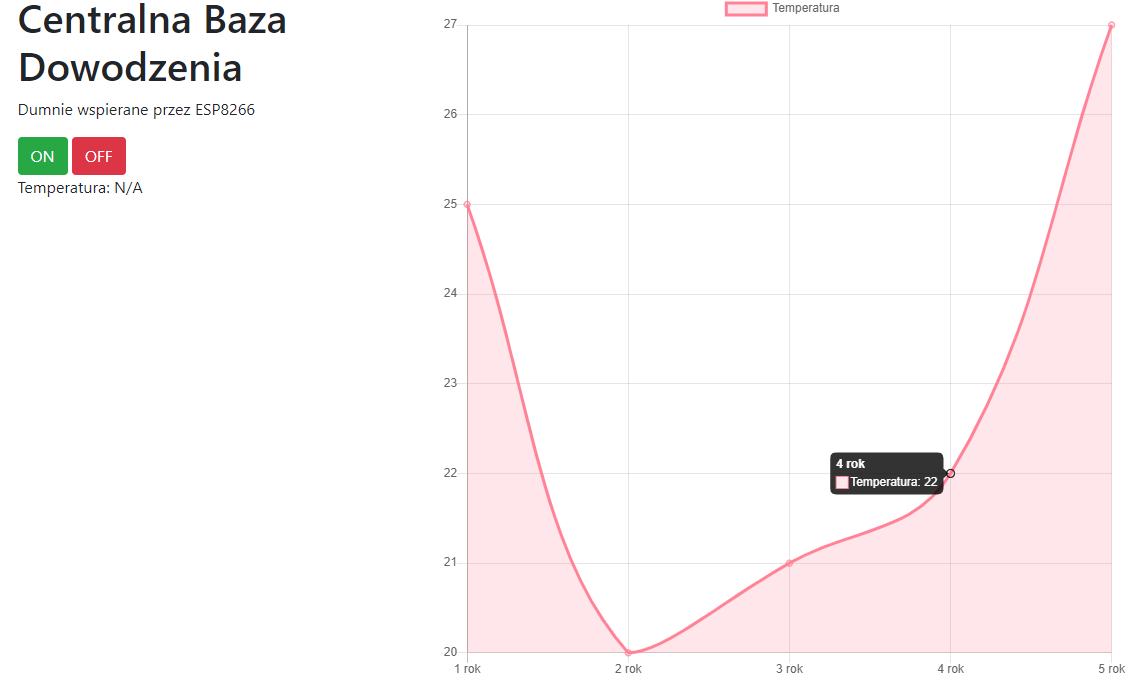
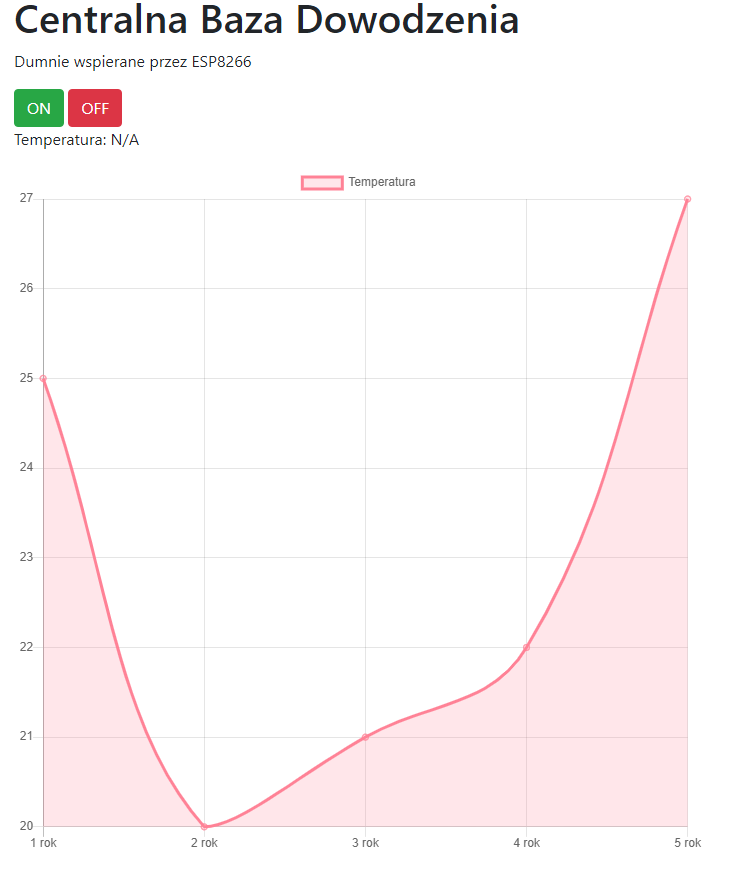
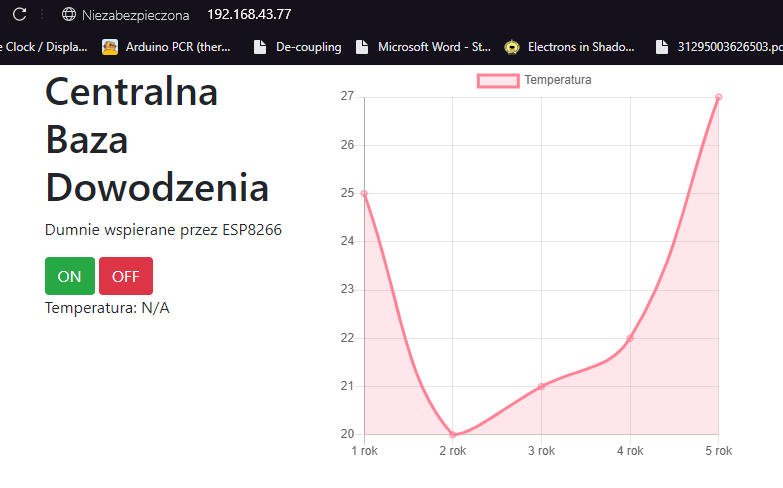
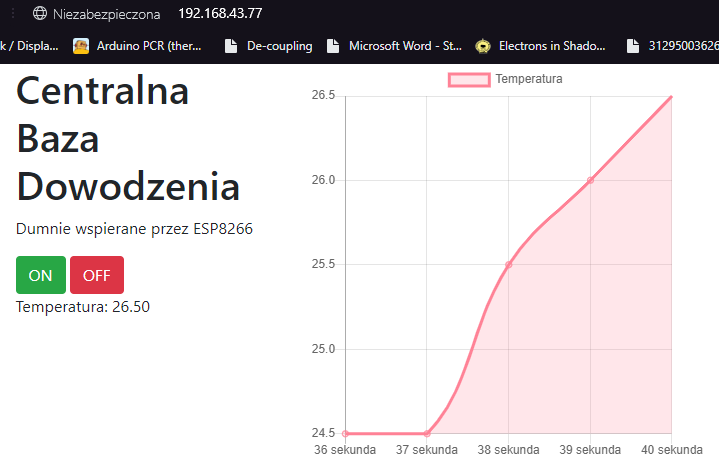
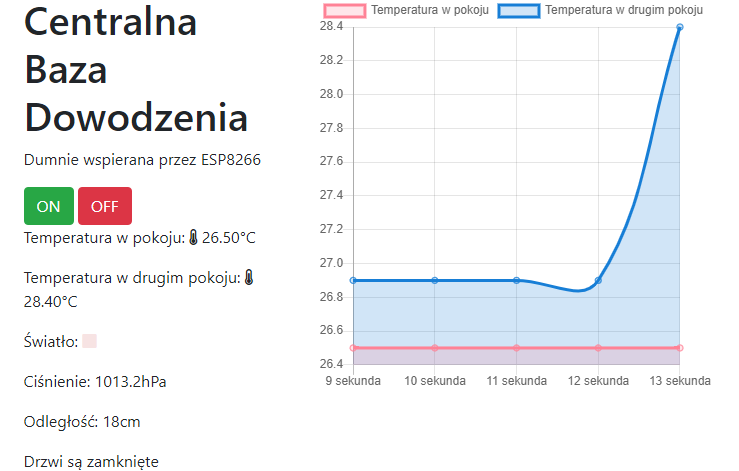
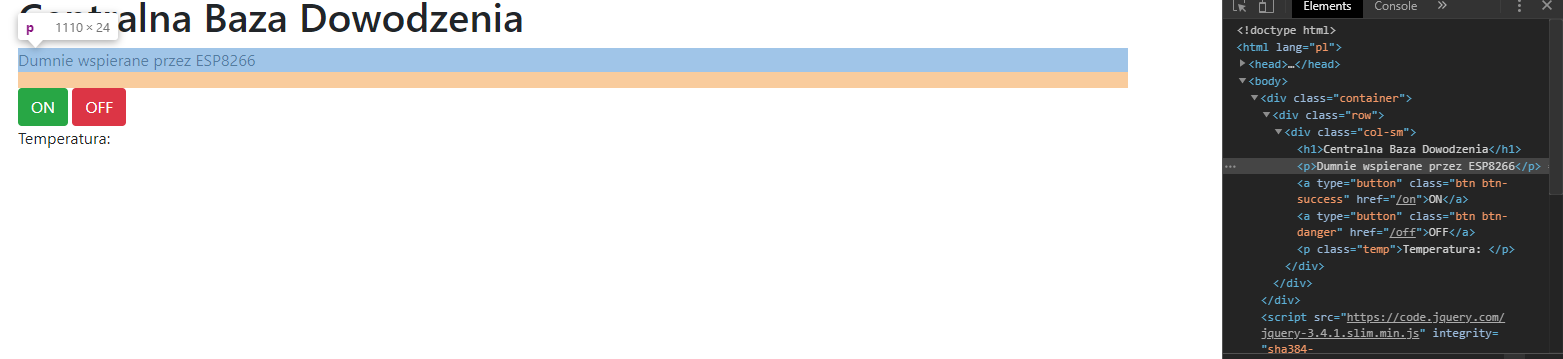
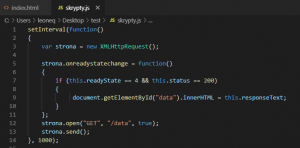
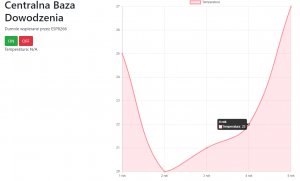
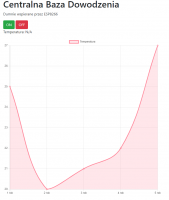
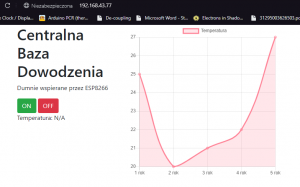
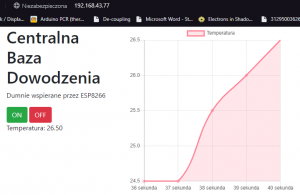
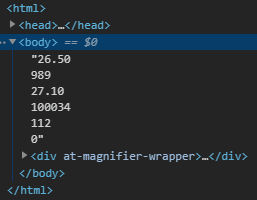
W poprzedniej części, nauczyliśmy się kodować rozbudowane i responsywne strony. Mam nadzieję, że przeczytałeś co nieco z linków na dole, ponieważ teraz będziemy mocniej kodować, aby stworzyć jeszcze ładniejszą i jeszcze bardziej funkcjonalną stronę. Zrobimy nawet mały smartdom! Do dzieła! Spis treści serii artykułów: 1. Omówienie, i przygotowanie środowiska 2. Zapoznanie z nowym środowiskiem, praca jako Arduino, prosty serwer WWW 3. Przyspieszony kurs na webmastera 4. Wykresy, zapis do SPIFFS, mini smart-dom 5. Odbiór danych z przeglądarki, stałe IP, łączenie modułów ESP Ten wpis brał udział konkursie na najlepszy artykuł o elektronice lub programowaniu. Sprawdź wyniki oraz listę wszystkich prac » Partnerem tej edycji konkursu (marzec 2020) był popularny producent obwodów drukowanych, firma PCBWay. Wykresy Wcześniej mieliśmy specjalną podstronę, gdzie zapisywaliśmy temperaturę co jedną sekundę. Jeżeli chcielibyśmy dodać drugi termometr musielibyśmy dodać drugą podstronę, itd... Ale dzięki jQuery, możemy odczytać z jednej podstrony więcej informacji, niż tylko jedna! Zacznijmy od zmodyfikowania poprzedniego kodu. Na rozgrzewkę, zmieńmy nazwę /temp na /data. server.on("/data", handleData); //setup() void handleData() { ds.requestTemperatures(); cls(); lcd.print("Temperatura: "); lcd.println(ds.getTempCByIndex(0)); server.send (200, "text/html", (String)ds.getTempCByIndex(0)); } Następnie przejdziemy od razu do wyświetlenia wykresu. Do tego będziemy potrzebować biblioteki ChartJS. Dopisujemy zatem kilka linijek kodu: <script src="https://cdnjs.cloudflare.com/ajax/libs/Chart.js/2.9.3/Chart.min.js" integrity="sha256-R4pqcOYV8lt7snxMQO/HSbVCFRPMdrhAFMH+vr9giYI=" crossorigin="anonymous"></script> <div class="col-sm"> <canvas id="wykres"></canvas> </div> Pierwsza linijka odpowiada za dołączenie biblioteki. W drugiej zaś, tworzymy nową małą kolumnę, w środku niej canvas. Canvas to znacznik wykorzystywany jako swego rodzaju płótno - będziemy tam rysować nasz wykres. Jak na razie w środku nie ma nic - ale zaraz coś namalujemy, dzięki nowej bibliotece. Pamiętajmy, że nową kolumnę umieszczamy obok pierwszej, w tym samym rzędzie! Jak się domyślasz, trzeba będzie dodać trochę kodu. Proponuję już nie używać znacznika <script>, tylko wszystkie nasze skrypty przenieść do nowego pliku. Dlatego, w folderze testowym, robimy nowy plik "skrypty.js". W środku przenosimy stary kawałek kodu: Cały kod JS w dokumencie HTML usuwamy. Znaczniki możemy zostawić, dopiszemy jedynie atrybut, gdzie jest nasz nowy plik. Przechodzimy do naszego nowo utworzonego pliku - zrobimy na razie wykres z stałych danych. Stwórzmy zatem tablice tych danych: var temperatura = [25, 20, 21, 22, 27]; var lata = ["1 rok", "2 rok", "3 rok", "4 rok", "5 rok"]; Przykładem tutaj będzie średnia temperatura pokoju na przestrzeni lat. Lata będą osią x (poziomą), temperatura y (pionową). Tablica labels przechowuje etykiety poszczególnych danych, var ctx = document.getElementById('wykres'); var wykres = new Chart(ctx, { type: 'line', data: { labels: lata, datasets: [ { label: 'Temperatura', data: temperatura, borderColor: 'rgba(255, 130, 150, 1', backgroundColor: 'rgba(255, 130, 150, 0.2)' } ] } }); Następnie przypisujemy nasze płótno do zmiennej. Kolejna zmienna to już stricte nasz wykres. Pierwszy atrybut mówi, że będzie to wykres liniowy (możemy zrobić kołowy, czy słupkowy). Potem zapisujemy dane wykresu: na początku definiujemy "labels" (etykiety) - to one będą naszą osią czasu. Datasets to paczki danych umieszczanych na tamtej osi - my mamy tylko jedną paczkę, temperatura. Przed każdą temperaturą wyświetlamy zatem tekst "Temperatura: ", informujemy jakie dane chcemy wyświetlić (po kolei!), następnie definiujemy jaki chcemy kolor kreski i kolor tła, jakie kreska wykreśli. Wrzucamy to wszystko do naszego dokumentu: $( document ).ready(function() { var temperatura = [25, 20, 21, 22, 27]; var lata = ["1 rok", "2 rok", "3 rok", "4 rok", "5 rok"]; var ctx = document.getElementById('wykres'); var wykres = new Chart(ctx, { type: 'line', data: { labels: lata, datasets: [ { label: 'Temperatura', data: temperatura, borderColor: 'rgba(255, 130, 150, 1', backgroundColor: 'rgba(255, 130, 150, 0.2)' } ] } }); setInterval(function() { var strona = new XMLHttpRequest(); strona.onreadystatechange = function() { if (this.readyState == 4 && this.status == 200) { document.getElementById("data").innerHTML = this.responseText; } }; strona.open("GET", "/data", true); strona.send(); }, 1000); }); Dlaczego wszystko jest w "ready"? Dzięki temu, nasz kod wykona się tylko wtedy, kiedy wszystko się załaduje. Bo jak kod w jQuery miałby się wykonać bez jQuery? Jeżeli dokument już zapisałeś, spróbuj uruchomić stronę: A teraz spróbuj zmienić rozmiar okna przeglądarki, czy uruchomić wszystko na telefonie. Jak to wygląda? Właśnie dzięki responsywności, dostajemy możliwość "łatwego" zmieniania rozmiarów strony. Dlatego będzie ona dobrze czytelna i na komputerze, i na telefonie. Wrzućmy zatem wszystko co mamy w folderze testowym, do folderu /data, i wgrajmy na ESP. Dokonujemy szybkich zmian w kodzie: String getScript() { String strona; File file = SPIFFS.open("/skrypty.js", "r"); while(file.available()) strona+=(char)file.read(); file.close(); return strona; } //skrypty server.on("skrypty.js", handleSkrypty); void handleSkrypty() { server.send(200, "text/javascript", getScript()); } I wgrywamy całość na ESP. Jak widzimy, wszystko pięknie działa: Wykresy w czasie rzeczywistym Spróbujmy teraz wyświetlić "rzeczywiste" dane. Niestety, to już jest trochę trudne - lecz na pewno sobie poradzimy. Na początku, dopóki nie dostaniemy odczytów z termometru, będziemy mieli 0 stopni: var temperatura = [0, 0, 0, 0, 0]; To, ile damy tutaj zmiennych, będzie decydować o "szerokości" naszego wykresu. var ctx = document.getElementById('wykres'); var wykres = new Chart(ctx, { type: 'line', data: { labels: ['', '', '', '', ''], datasets: [ { data: temperatura, label: 'Temperatura', borderColor: 'rgba(255, 130, 150, 1', backgroundColor: 'rgba(255, 130, 150, 0.2)' } ] } }); Pierwszych 5 temperatur tak naprawdę nie ma, więc damy im puste etykiety. Reszta zostaje tak samo. Teraz dodamy dwie funkcje: dodającą wartość, i usuwającą ostatnią wartość. function addData(chart, label, data) { chart.data.labels.push(label); chart.data.datasets[0].data.push(data); chart.update(); } Pierwszy argument, to wykres - bo w końcu możemy ich mieć kilka na stronie. Drugi argument to etykieta, trzeci to wartość. Na początku "popychamy" stos etykiet, dodając kolejną. Podobnie robimy z danymi, a na końcu aktualizujemy wykres. function popData(chart, index) { chart.data.labels.splice(index, 1); chart.data.datasets[0].data.splice(index, 1); chart.update(); } Kolejna funkcja usuwa nam etykietę na podanym indeksie, a potem dane. var sekundy = 0; setInterval(function() { var strona = new XMLHttpRequest(); sekundy++; var etykieta = "" + sekundy + " sekunda"; strona.onreadystatechange = function() { if (this.readyState == 4 && this.status == 200) { var zawartosc = this.responseText; var dane = zawartosc.split("\n"); document.getElementById('data').innerHTML = dane[0]; addData(wykres, etykieta, dane[0]); popData(wykres, 0); } }; strona.open("GET", "/data", true); strona.send(); }, 1000); }); Tak wygląda cała nowa funkcja, która nam aktualizowała temperaturę. Z racji tego, że wykonuje się co sekundę, zrobimy od razu licznik tych sekund - stąd zmienna na początku. W funkcji zwiększamy zmienną o 1, a potem tworzymy etykietę. W środku funkcji pobierającej temperaturę dokonało się jednak najwięcej zmian. Zawartość całej strony /dane przechowujemy w zmiennej, którą potem rozdzielamy na linie co znak nowej linii. Dlaczego tak, a nie po prostu odczytać? Dzięki temu, na jednej podstronie możemy odczytywać bardzo wiele informacji, zamiast tworzyć nowe podstrony. Temperatura będzie zapisana na pierwszej linijce strony - wypisujemy ją na stronie głównej, potem dodajemy ją do wykresu (z etykietą), a starą temperaturę usuwamy. Jeżeli nie będziemy usuwać starych danych, po pewnym czasie całość zrobi się mocno nieczytelna. Przechodzimy do kodu; modyfikujemy funkcję handleData: void handleData() { ds.requestTemperatures(); cls(); lcd.print("Temperatura: "); lcd.println(ds.getTempCByIndex(0)); String strona = (String)ds.getTempCByIndex(0); strona += "\n"; //dodamy zaraz więcej danych! server.send (200, "text/html", strona); } Praktycznie nic się nie zmieniło, jedyne co to dodaliśmy zmienną strona przechowującą podstronę /data. Jest ona pisana w locie, co umożliwia wypisanie tam danych z czujników. Po każdym dodaniu linii, dodajemy znak nowej linii dla rozdzielenia danych. Wszystko wgrywamy do ESP, i sprawdzamy czy działa: Zapisywanie plików To teraz spróbujmy zapisać temperaturę do pliku, żeby potem "na żądanie" robić wykres. Np. co godzinę zapisywać temperaturę, robić średnią, i pokazywać na wykresie. Akurat to jest dość proste, wystarczy nowa funkcja: void writeToFile(String plik, String tekst) { File file = SPIFFS.open(plik, "w"); if (file.print(tekst)) { cls(); lcd.println("Zapisano pomyslnie!"); } else { cls(); lcd.println("Blad zapisu!"); } file.close(); } Pierwszym argumentem jest plik. Musimy sami utworzyć taki pusty plik, aby do niego zapisać różne dane. Drugi argument to oczywiście zawartość, którą chcemy zapisać. Jako zadanie domowe (no dobra, zadanie dodatkowe), spróbuj zrobić program który zapisze temperaturę, a następnie odczyta i zapisze na wykresie. Praca na wielu danych No, to jak mamy już wszystko do pracy na wielu danych, dodanie czujników powinno być czystą przyjemnością. Dlatego dodamy: HC-SR04 przycisk (kontakron, co chcesz) barometr BMP180 fotorezystor a nawet WS2812. A co. Scenariusz jest prosty: mierzę temperaturę, odległość, stan przycisku, ilość światła, wysyłam to do WWW, a z WWW dostaję informacje o kolorze WS2812. W tym momencie instalujemy wszystkie potrzebne biblioteki, dodajemy je na początku kodu, i dodajemy je do naszej funkcji obsługującej /data: void handleData() { ds.requestTemperatures(); String strona = (String)ds.getTempCByIndex(0); strona += "\n"; strona += analogRead(PIN_FRES); strona += "\n"; strona += bmp.readTemperature(); strona += "\n"; strona += bmp.readPressure(); strona += "\n"; strona += zmierzOdleglosc(); strona += "\n"; strona += digitalRead(PIN_BTN); //temperatura ds //fotorezystor //temperatura bmp //cisnienie //odleglosc //przycisk server.send (200, "text/html", strona); } Jedyne co się zmieniło, to dodanie kilku odczytów oddzielonymi znakami nowej linii. Po wgraniu tego do kodu, powinieneś zobaczyć takie coś na stronie /data: Pierwsza wartość to zatem temperatura, druga ilość światła, trzecia to też temperatura (uznajmy że z innego pokoju), czwarta to ciśnienie w paskalach, piąta to odległość zmierzona przez HC-SR04, ostatnia to odczyt z kontaktronu. Wygląda na to, że muszę popracować z HC... Ale dlaczego wszystko jest w jednej linii, tylko porozdzielane spacjami? Otóż to są nowe linie, co możemy zobaczyć w narzędziach deweloperskch: Aby przejść do nowej linii, musielibyśmy dać znacznik <br>. Jak widać, przeglądarka także "sama" dodała <html> i <body>. No, jeżeli już masz wszystkie czujniki gotowe, przejdziemy do strony. Odpalamy plik skrypty.js. Ale chwila! Zanim zaczniemy kodować, musimy sobie odpowiedzieć na pytanie "co kodować". Zawsze przed kodowaniem zadaj sobie to pytanie! Mamy 6 odczytów. Dwa z nich wyświetlimy na wspólnym wykresie, światło możemy wyrazić kolorem barwy, ciśnienie pokażemy w hPa obok "surowych" danych. Będziemy wyświetlali napis, czy drzwi zostały otwarte (kontaktron). No, to teraz możemy kodować. Zacznijmy od zapisu tych wszystkich danych: if (this.readyState == 4 && this.status == 200) { var zawartosc = this.responseText; var dane = zawartosc.split("\n"); var temp1 = dane[0]; var fres = dane[1]; var temp2 = dane[2]; var cis = dane[3] / 100; var odl = dane[4]; var btn = dane[5]; document.getElementById('data').innerHTML = dane[0]; addData(wykres, etykieta, dane[0]); popData(wykres, 0); } To jest if z funkcji "setInterval". Tak jak wcześniej tylko dodaliśmy zapis danych, tak i teraz tylko dodaliśmy odczyty. Aby wyświetlić temperatury na jednym wykresie, musimy najpierw zmodyfikować funkcje pop i push: function addData(chart, data, dset) { chart.data.datasets[dset].data.push(data); chart.update(); } function addLabel(chart, label) { chart.data.labels.push(label); chart.update(); } function popData(chart, index) { chart.data.labels.splice(index, 1); chart.data.datasets.forEach((dataset) => { dataset.data.splice(index, 1); }); chart.update(); } Komenda "znikająca" została teraz obramowana pętlą forEach. Wykonuje się ona tyle razy, ile razy występuje coś (dosłownie - dla każdego). Dla każdego zatem zestawu danych, usuwamy zmienną. Aby dodać daną, od teraz musimy powiedzieć do którego zestawu danych ją dodać. Dodawanie etykiety dałem do osobnej funkcji, aby nie robić duplikatów etykiet. A tak wygląda nasz nowy wykres: var temperatura = [0, 0, 0, 0, 0]; var temperatura2 = [0, 0, 0, 0, 0]; var ctx = document.getElementById('wykres'); var wykres = new Chart(ctx, { type: 'line', data: { labels: ['', '', '', '', ''], datasets: [ { data: temperatura, label: 'Temperatura w pokoju', borderColor: 'rgba(255, 130, 150, 1)', backgroundColor: 'rgba(255, 130, 150, 0.2)' },{ data: temperatura2, label:'Temperatura w drugim pokoju', borderColor: 'rgba(23, 126, 214, 1)', backgroundColor: 'rgba(23, 126, 214, 0.2)', } ] } }); Dodaliśmy drugi zestaw danych. Ma on niebieską kreskę, i pusty zestaw początkowych danych. Etykiety teraz będą różne - dla dwóch różnych pokoi. Zostało nam dodać dodawanie i odejmowanie danych z wykresu: document.getElementById('temp1').innerHTML = temp1; document.getElementById('temp2').innerHTML = temp2; addLabel(wykres, etykieta); addData(wykres, temp1, 0); addData(wykres, temp2, 1); popData(wykres, 0); I szybkie zmiany w HTMLu: <p>Temperatura w pokoju: <span id="temp1">N/A</span></p> <p>Temperatura w drugim pokoju: <span id="temp2">N/A</span></p> Spróbujmy teraz to wgrać i zobaczyć efekt. Piękny efekt. No, to teraz może pobawimy się FontAwesome? Wchodzimy tutaj, i szukamy ikonki termometru: Niestety, dla nas dostępne są tylko te widoczne ikony - te szare są dla wersji płatnych. Wybierzmy ikonkę która nam najbardziej przypadła do gustu: Klikamy "Start using this icon", i kod kopiujemy tam, gdzie ma być ikonka. Ja sobie dam ją przed temperatury: <p>Temperatura w pokoju: <i class="fas fa-thermometer-three-quarters"></i> <span id="temp1">N/A</span></p> <p>Temperatura w drugim pokoju: <i class="fas fa-thermometer-three-quarters"></i> <span id="temp2">N/A</span></p> I po wgraniu dostajemy takie ładne ikonki: To teraz możemy dodać pozostałe dane. Spróbujemy zmienić kolor za pomocą jQuery - lecz musimy jakoś przekonwertować wartość z fotorezystora do koloru. Kolor możemy zapisać heksadecymalnie (#ffffff to biały), w formacie rgba (255, 255, 255, 255 to biały nieprzezroczysty), czy podać stałą (red - czerwony). Tutaj proponuję wyświetlić kolor w skali szarości. Dlatego odczyt od razu podzielimy przez 4, by mieć wartości 0-255: var fres = dane[1] / 4; 'Następnie stworzymy zmienną, która będzie przechowywać tekst atrybutu color. Dlaczego odejmowanie jest w nawiasach? Otóż bez nich, odjęlibyśmy tekst "20". Dlatego zapis 2+2 da nam 22, a zapis (2+2) da nam 4. Ale... dlaczego w ogóle odejmujemy? Jeżeli światło będzie białe, nie będziemy go widzieli na stronie z białym tłem. var color = 'rgb('+fres +','+(fres - 20)+','+(fres - 20)+')'; Oraz zmieniamy co sekundę kolor: document.getElementById('light').style.color = color; No dobra, ale czego zmieniamy? Ja sobie dodałem tekst "Światło" oraz ikonkę kwadratu z przypisanym id "light". To on będzie zmieniał kolor. <p>Światło: <i class="fas fa-square" id="light"></i> Teraz dodamy ciśnienie, oraz jednostki dla temperatur. W googlu szukamy "degree symbol" lub kopiujemy stąd: ° Cała kolumna będzie wyglądać tak: <div class="col-sm"> <h1>Centralna Baza Dowodzenia</h1> <p>Dumnie wspierana przez ESP8266</p> <a type="button" class="btn btn-success" href="/on">ON</a> <a type="button" class="btn btn-danger" href="/off">OFF</a> <p>Temperatura w pokoju: <i class="fas fa-thermometer-three-quarters"></i> <span id="temp1">N/A</span>°C</p> <p>Temperatura w drugim pokoju: <i class="fas fa-thermometer-three-quarters"></i> <span id="temp2">N/A</span>°C</p> <p>Światło: <i class="fas fa-square" id="light"></i></p> <p>Ciśnienie: <span id="cis"></span>hPa</p> <p>Odległość: <span id="odl"></span>cm</p> <p>Drzwi są <span id="drzwi"></span></p> </div> Pomiędzy znacznik </span> a </p> dodaliśmy tekst, z jednostką. Podobnie z ciśnieniem. Przechodzimy zatem do kodowania: document.getElementById('cis').innerHTML = cis; document.getElementById('odl').innerHTML = odl; if(!btn) document.getElementById('drzwi').innerHTML = 'otwarte!'; else document.getElementById('drzwi').innerHTML = 'zamknięte.'; Robimy prostego ifa, który nam wyświetli tekst "zamknięte", jeżeli odczyta HIGH. W przeciwnym razie wyświetli tekst "otwarte". Sprawdźmy, czy kod działa: Można powiedzieć, że zrobiliśmy już mini smartdom. Mamy sterowanie z poziomu aplikacji oraz wiele odczytów. W następnym odcinku spróbujemy dodać małego ESP, aby zbierał odczyty z innego pokoju, użyjemy WS2812, oraz zrobimy małe podsumowanie. Bądźcie kreatywni! Spróbujcie urozmaicić swój smartdom, stronę, i pokażcie w komentarzach wasze konstrukcje! Spis treści serii artykułów: 1. Omówienie, i przygotowanie środowiska 2. Zapoznanie z nowym środowiskiem, praca jako Arduino, prosty serwer WWW 3. Przyspieszony kurs na webmastera 4. Wykresy, zapis do SPIFFS, mini smart-dom 5. Odbiór danych z przeglądarki, stałe IP, łączenie modułów ESP
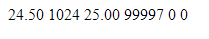




-
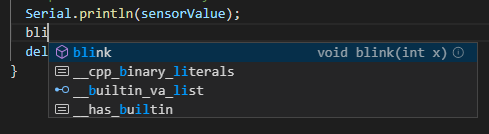
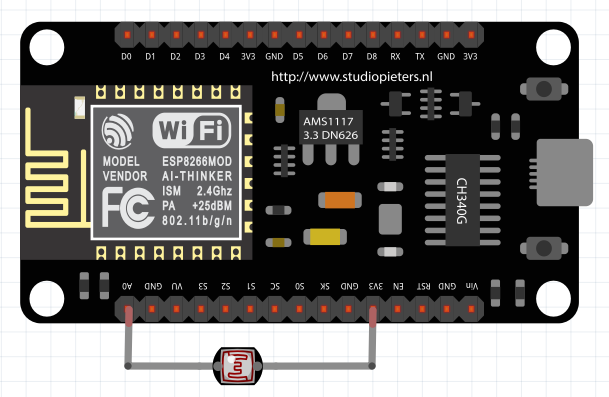
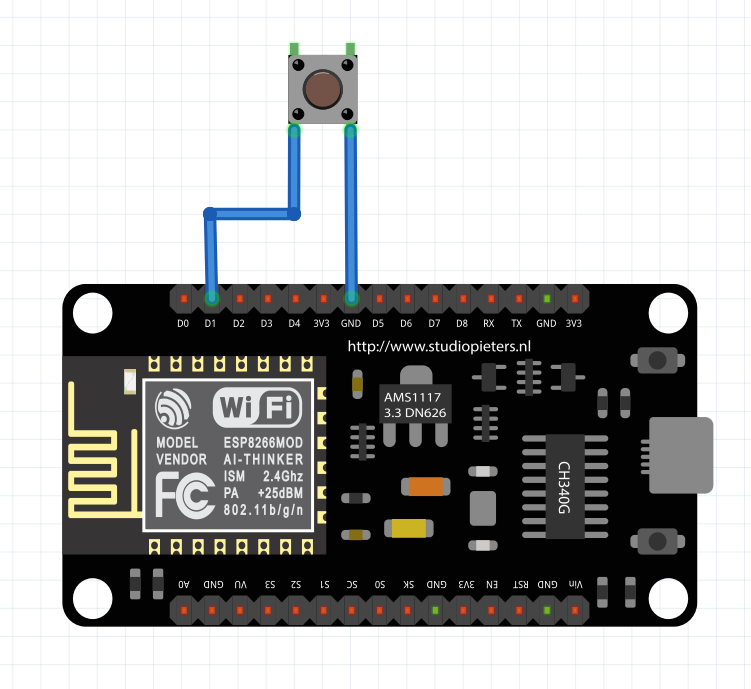
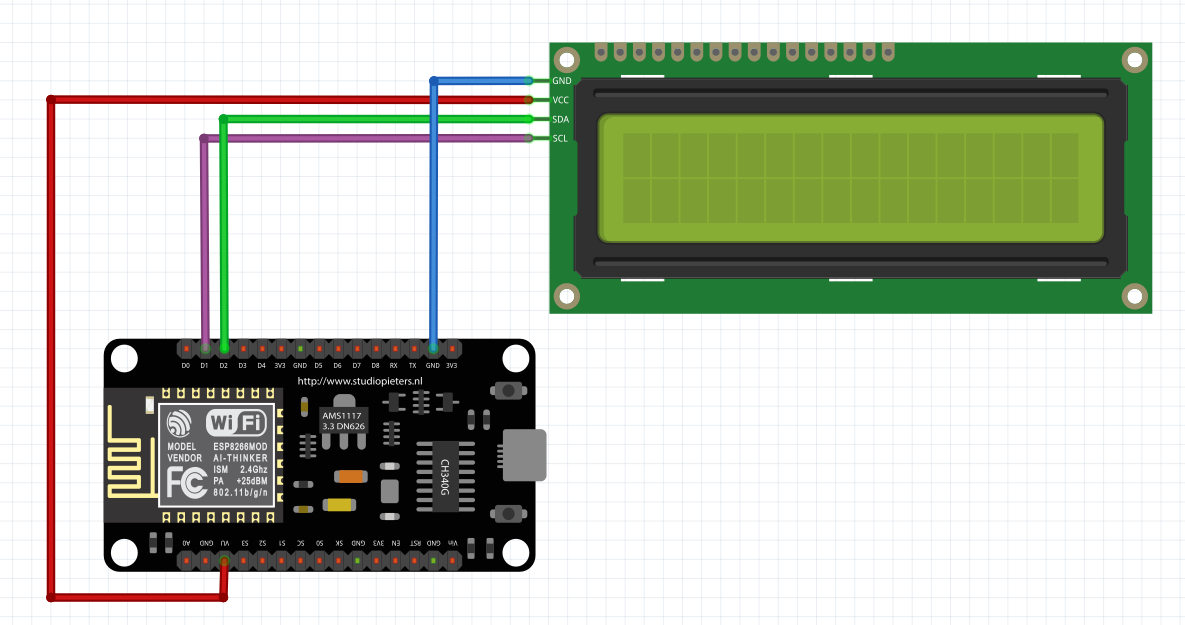
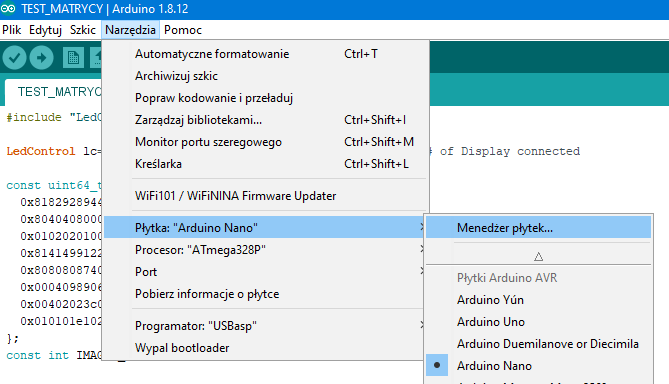
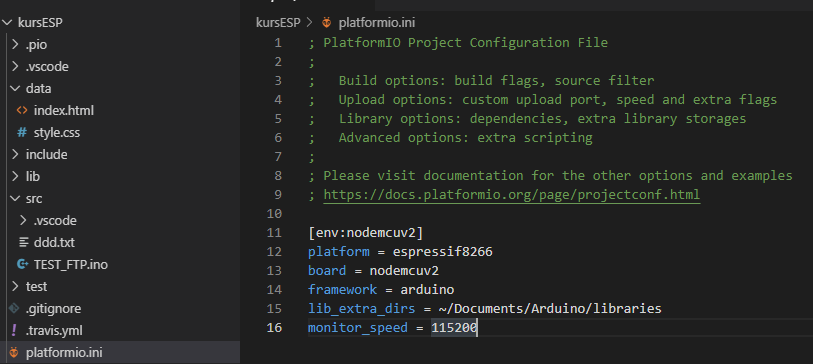
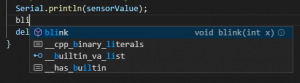
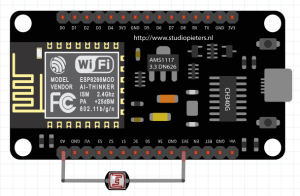
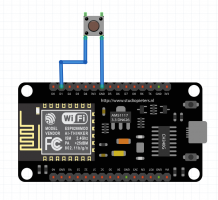
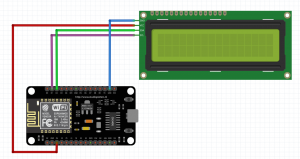
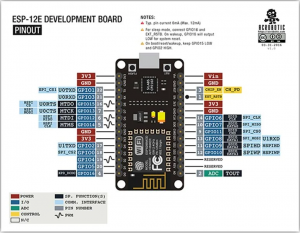
Witajcie w drugiej części kursu ESP8266! Dzisiaj omówimy sobie, co przynosi zmiana środowiska na VS Code, zobaczymy sprzętowe możliwości ESP, a także połączymy się z siecią WIFI. Do kursu będziecie potrzebowali: ESP8266 (najlepiej NodeMCU v3) Dioda LED (z rezystorem) Wyświetlacz HD44780 z konwerterem I2C (lub inny, ale będziesz musiał modyfikować kod) Fotorezystor lub potencjometr Płytkę stykową Przewody połączeniowe oraz oczywiście dobre chęci Zacznijmy od tego, co nam dała przeprowadzka na VS Code. Poza samym wyglądem (kwestia gustu), wsparciem wielu wtyczek (pluginów) czy po prostu większą wygodą pisania, VS Code oferuje wiele zwykłych, aczkolwiek przydatnych funkcji których brakuje w Arduino IDE. Ten wpis brał udział konkursie na najlepszy artykuł o elektronice lub programowaniu. Sprawdź wyniki oraz listę wszystkich prac » Partnerem tej edycji konkursu (marzec 2020) był popularny producent obwodów drukowanych, firma PCBWay. Spis treści serii artykułów: 1. Omówienie, i przygotowanie środowiska 2. Zapoznanie z nowym środowiskiem, praca jako Arduino, prosty serwer WWW 3. Przyspieszony kurs na webmastera 4. Wykresy, zapis do SPIFFS, mini smart-dom 5. Odbiór danych z przeglądarki, stałe IP, łączenie modułów ESP Praca na wielu plikach jednocześnie Nawet z jednym monitorem, wszystko wygląda dość czytelnie i elegancko. Po lewej stronie mamy przeglądarkę plików, gdzie możemy wczytać przykład z Arduino IDE czy otworzyć cały folder z projektem. Dzięki temu, będziemy mieli od razu łatwy dostęp do wszystkich plików projektu, jak pliki nagłówkowe, pliki tekstowe, czy nawet zdjęcia. Na dole zaś znajdziemy konsolę. Tam mamy dostęp do windowsowego PowerShella, arduinowego Serial Monitora, czy po prostu informacje o wgrywaniu/kompilowaniu programu. Na samym środku okna znajdziemy zakładki z otwartymi plikami. Możemy je jeszcze podzielić, co umożliwia nam pracę na wielu plikach jednocześnie. Typowe okno programu VS Code. Wygoda pisania VS Code o wiele bardziej potrafi się do nas przystosować. Poza zmianą ogólnego schematu kolorów, mamy możliwość zmiany kolorowania składni. Dostajemy także podpowiadanie (skrót CTRL+SPACJA), co często jest bardzo przydatną funkcją, oraz autouzupełnianie - czyli po zapisaniu pierwszego nawiasu, od razu piszemy drugi (magia IntelliSense). Po prawej stronie, obok suwaka, mamy widok na kod "z daleka". Umożliwia to wyszukiwanie konkretnych bloków kodu, np. obszernych tablic zmiennych, długich instrukcji switch-case czy innych dobrze widocznych rzeczy. Podpowiedź do własnej funkcji blink() VS Code oferuje oczywiście jeszcze wiele, wiele funkcji - lecz są one dla bardziej zaawansowanych programistów, i najzwyczajniej nam się nie przydadzą. Przejdźmy zatem do części praktycznej. Analog Read oraz Serial Sprawdźmy, czy ESP może pracować tak jak zwykłe Arduino. Ale czym by było Arduino bez przetwornika ADC i komunikacji z komputerem? Sprawdźmy, czy przykład "AnalogReadSerial" zadziała na NodeMCU. Wgrywamy poniższy kod: #define PIN_ANALOG A0 //pin analogowy. NodeMCU ma taki tylko jeden! int odczyt; //zmienna, w której zapisujemy odczyt void setup() { Serial.begin(115200); //uruchamiamy komunikację UART z prędkością 115200 bodów pinMode(PIN_ANALOG, INPUT); //ustawiamy pin analogowy jako wejście } void loop() { odczyt = analogRead(PIN_ANALOG); //odczytujemy wartość Serial.println(odczyt); //piszemy wartość delay(1); //czekamy chwilę } Oraz podłączamy NodeMCU zgodnie z poniższym schematem: Gdzie: pin pierwszy fotorezystora łączymy z pinem A0 pin drugi fotorezystora łączymy z zasilaniem 3.3V Po wgraniu przykładu i otworzeniu portu, powinniśmy zobaczyć ciągle wypisywane wartości. U mnie, przy zwykłym oświetleniu odczyt wskazywał 1024 (czyli maks. wartość), po przysłonięciu ręką ta wartość malała aż do 0 (kiedy fotorezystor włożyłem do pudełka). Oznacza to, że zarówno mierzenie wartości analogowych, jak i komunikacja przez port szeregowy działa. Przejdźmy zatem do następnego przykładu. Komunikacja w drugą stronę, przycisk, PWM Kolejny, prosty przykład. Chcemy, aby po odebraniu z komputera po Serialu liczby dioda zaświeciła się dzięki PWM, a po naciśnięciu przycisku zgasła. W tym celu utworzymy nowy projekt. Ja to robię trochę manualne, mianowicie tworzę nowy folder, a w nim "plik.ino". Aby taki plik utworzyć, po nazwie dajemy ".ino" - więc nadajemy rozszerzenie pliku Arduino. Musimy także wybrać typ pliku jako wszystkie pliki. Nazwa folderu i pliku są takie same. Teraz możemy przejść do kodu. #define PIN_BTN D1 #define PIN_LED BUILTIN_LED char znak = ' '; void setup() { Serial.begin(115200); pinMode(PIN_BTN, INPUT_PULLUP); } void loop() { if(Serial.available() > 0) znak = Serial.read(); //jak odbieramy coś, zapisujemy 1 znak switch (znak) { case '1': analogWrite(PIN_LED, 0); //maks break; case '2': analogWrite(PIN_LED, 400); //ok. 80% break; case '3': analogWrite(PIN_LED, 800); //ok. 30% break; case '4': analogWrite(PIN_LED, 1023); //0% break; } if(digitalRead(PIN_BTN) == LOW) znak = '4'; } Na początku definiujemy piny. W ESP używamy oznaczeń "Dx" - jeżeli chcielibyśmy podać samą liczbę, musielibyśmy podać numer GPIO zgodny z rozpiską. Następnie definiujemy zmienną "znak" typu char. Przechowuje ona jeden (!) znak. W funkcji setup uruchamiamy komunikację UART, oraz podpinamy rezystor podciągający do pinu przycisku. Zapobiegnie to "pływaniu" napięcia - nie wiadomo, jakie napięcie by wtedy było na tym pinie. W funkcji loop() na początku sprawdzamy, czy odebraliśmy dane - jeżeli tak, zapisujemy je do zmiennej. Następnie analizujemy zmienną - oraz ustawiamy PWM na pin z daną wartością. Tutaj warto zaznaczyć, że wartość podajemy w zakresie 0-1023 (w Arduino 0-255), oraz że wypełnienie też jest "odwrócone". Czyli "maksymalne wypełnienie" zgasi diodę, natomiast podanie "zera" po prostu ją zapali. Następnie, jeżeli przycisk jest zwarty z masą, gasimy diodę. Tak wygląda schemat: Pin D1 łączymy z pierwszym pinem przycisku, drugi pin łączymy z masą (G). Teraz spróbuj połączyć się Serial Monitor i wpisać kolejno 1,2,3,4, oraz przycisnąć przycisk gaszący diodę. Wszystko powinno sprawnie działać. Pierwsze kroki z WIFI - łączenie się z siecią Czas, aby nasze ESP mogło się połączyć z Wifi. Oczywiście, możemy także ustawić ESP w trybie "routera", lecz zajmiemy się tym później - najlepiej, gdybyś miał gotową domową sieć Wifi do której bezpiecznie można się podpiąć. Nawet jeżeli takiej nie masz, możesz uruchomić w telefonie "hotspota". Jeżeli zapewniłeś sobie już dostęp do Wifi, zapisz gdzieś SSID (nazwę) i hasło. Spróbujemy połączyć się z Wifi, a następnie wyświetlić to na wyświetlaczu sterowanym przez I2C. Tak jak mówiłem, I2C możemy skonfigurować na dowolnych pinach; domyślnie pin D1 to SCL, a D2 to SDA. Tak też zostawiamy, następnie uruchamiamy skaner adresów I2C, aby znaleźć jaki adres ma nasz wyświetlacz. Podłączenie nie powinno być problemem: I teraz prosty programik uruchamiający wyświetlacz: #include <Wire.h> //biblioteka od I2C #include <LiquidCrystal_I2C.h> //biblioteka od HD44780 po I2C LiquidCrystal_I2C lcd(0x3F, 20, 4); //adres, szerokość, wysokość void setup() { lcd.begin(); lcd.print("Hello, world!"); } void loop() {} Powinniśmy zobaczyć takie coś: Teraz spróbujemy połączyć się z Wifi. Do poprzedniego kodu dodajemy bibliotekę, odpowiadającą za obsługę Wifi. #include <ESP8266WiFi.h> Następnie tworzymy tablice charów zawierające naszą nazwę i hasło. Do tego tworzymy obiekt klienta. const char* ssid = "ssid"; const char* pass = "hasło"; WiFiClient client; Przechodzimy do funkcji setup. Tam dodajemy funkcję załączającą Wifi. Przyjmuje ona argument nazwy, a potem hasła. void setup() { lcd.begin(); WiFi.begin(ssid, pass); //połącz z Wifi lcd.setCursor(0, 0); lcd.print("Laczenie "); Potem możemy dodać animację, żeby zobaczyć czy nic się nie zacięło. while(WiFi.status() != WL_CONNECTED) //wyświetlaj animacje dopóki się nie połączyliśmy { lcd.setCursor(10,0); lcd.print("."); delay(400); lcd.setCursor(10,0); lcd.print(" "); delay(400); } Na końcu dodamy wiadomość, że już się połączyliśmy. Wyświetlimy nawet nasz adres IP! lcd.setCursor(0, 0); //napisz, że połączono i wyświetl IP lcd.print("Polaczono! "); lcd.setCursor(0, 1); lcd.print("IP: "); lcd.print(WiFi.localIP()); Całość zatem będzie wyglądać tak: #include <Wire.h> //biblioteka od I2C #include <LiquidCrystal_I2C.h> //biblioteka od HD44780 po I2C #include <ESP8266WiFi.h> LiquidCrystal_I2C lcd(0x3F, 20, 4); //adres, szerokość, wysokość const char* ssid = "nazwa"; //nazwa const char* pass = "haslo"; //hasło WiFiClient client; //obiekt wifi void setup() { lcd.begin(); WiFi.begin(ssid, pass); //połącz z Wifi lcd.setCursor(0, 0); lcd.print("Laczenie "); while(WiFi.status() != WL_CONNECTED) //wyświetlaj animacje dopóki się nie połączyliśmy { lcd.setCursor(10,0); lcd.print("."); delay(400); lcd.setCursor(10,0); lcd.print(" "); delay(400); } lcd.setCursor(0, 0); //napisz, że połączono i wyświetl IP lcd.print("Polaczono! "); lcd.setCursor(0, 1); lcd.print("IP: "); lcd.print(WiFi.localIP()); } void loop() //nie robimy już nic { } Pamiętaj, aby przed wgraniem programu wprowadzić swoje hasło i swoją nazwę sieci (a także adres LCD). Jeżeli nam się nie uda połączyć, lub coś pójdzie nie tak, zamiast adresu IP wyświetli nam się "IP unset". Spróbuj teraz w przeglądarkę wpisać adres IP, który odczytasz na wyświetlaczu. Oczywiście, teraz nic się nie wyświetli - ESP nie ma instrukcji, co zrobić w przypadku wejścia na jego adres IP. Zmieńmy to! ESP8266 jako prosty serwer WWW Nasze zadanie będzie proste: jeżeli wejdziemy na stronę główną (ip), wyświetla nam się tekst "witaj". Po wejściu w podstronę "on" (ip/on) zapalamy diodę, i podobnie w przypadku "off". Będziemy sterować wbudowaną diodą. Dodajemy zatem bibliotekę odpowiedzialną za serwer WWW: #include <ESP8266WebServer.h> Oraz jej obiekt. Liczba podana w nawiasie to port. Jeżeli chcesz wiedzieć więcej o HTTP i serwerach, odsyłam Ciebie do artykułu ethanaka. ESP8266WebServer server(80); Przechodzimy do funkcji setup. Na samym dole dodajemy kilka linijek - pierwsze 3 odpowiadają za funkcje, które się wykonają po wywołaniu strony. Ostatnia uruchamia serwer. server.on("/", handleRoot); server.on("/on", handleOn); server.on("/off", handleOff); server.begin(); Teraz jedynie w funkcji loop() zostało dodać obsługę całego serwera. server.handleClient(); Ostatnim krokiem zostało dodanie trzech funkcji, podanych wcześniej. Funkcja handleRoot wykona nam się za każdym razem, po wywołaniu strony głównej. Stwórzmy ją w takim razie: void handleRoot() { server.send ( 200, "text/html", "<p>witaj</p>"); } Wykonuje nam się tylko polecenie send. Wysyła ono informacje do klienta - pierwszą z nich jest kod 200 (wszystko jest w porządku), następnie tekst. Chwilowo po prostu przepisz ostatni argument, później omówimy HTMLa bardziej szczegółowo. Tak będzie wyglądać funkcja zapalająca oraz gasząca LED: void handleOn() { digitalWrite(PIN_LED, LOW); server.send(200, "text/html", "<p>dioda jest wlaczona</p>"); } void handleOff() { digitalWrite(PIN_LED, HIGH); server.send(200, "text/html", "<p>dioda jest wylaczona</p>"); } I, po dodaniu wszystkiego, całość będzie wyglądać tak: #define PIN_LED BUILTIN_LED #include <Wire.h> //biblioteka od I2C #include <LiquidCrystal_I2C.h> //biblioteka od HD44780 po I2C #include <ESP8266WiFi.h> #include <ESP8266WebServer.h> LiquidCrystal_I2C lcd(0x3F, 20, 4); //adres, szerokość, wysokość const char* ssid = ""; //nazwa const char* pass = ""; //hasło WiFiClient client; //obiekt wifi ESP8266WebServer server(80); void setup() { lcd.begin(); WiFi.begin(ssid, pass); //połącz z Wifi lcd.setCursor(0, 0); lcd.print("Laczenie "); pinMode(PIN_LED, OUTPUT); while(WiFi.status() != WL_CONNECTED) //wyświetlaj animacje dopóki się nie połączyliśmy { lcd.setCursor(10,0); lcd.print("."); delay(400); lcd.setCursor(10,0); lcd.print(" "); delay(400); } lcd.setCursor(0, 0); //napisz, że połączono i wyświetl IP lcd.print("Polaczono! "); lcd.setCursor(0, 1); lcd.print("IP: "); lcd.print(WiFi.localIP()); server.on("/", handleRoot); server.on("/on", handleOn); server.on("/off", handleOff); server.begin(); } void handleRoot() { server.send ( 200, "text/html", "<p>witaj</p>"); } void handleOn() { digitalWrite(PIN_LED, LOW); server.send(200, "text/html", "<p>dioda jest wlaczona</p>"); } void handleOff() { digitalWrite(PIN_LED, HIGH); server.send(200, "text/html", "<p>dioda jest wylaczona</p>"); } void loop() { server.handleClient(); //obsługa serwera } Teraz wpisz swoją nazwę i hasło, wgraj program, i wpisz w przeglądarkę adres IP. Powinien ci się ukazać tekst "witaj". Spróbuj teraz po adresie wpisać ukośnik, oraz "on". Dioda powinna się zapalić, oraz wyświetlić stosowny tekst. Tak samo będzie z podstroną off. Właśnie udało Ci się postawić serwer WWW na mikrokontrolerze za 20zł! W następnej części nauczymy się podstaw HTMLa, wczytamy stronę WWW z karty SD, a nawet zrobimy mini termometr IoT. W międzyczasie spróbuj zrobić program obsługujący dwie diody. Tak więc, do dzieła! Spis treści serii artykułów: 1. Omówienie, i przygotowanie środowiska 2. Zapoznanie z nowym środowiskiem, praca jako Arduino, prosty serwer WWW 3. Przyspieszony kurs na webmastera 4. Wykresy, zapis do SPIFFS, mini smart-dom 5. Odbiór danych z przeglądarki, stałe IP, łączenie modułów ESP






-

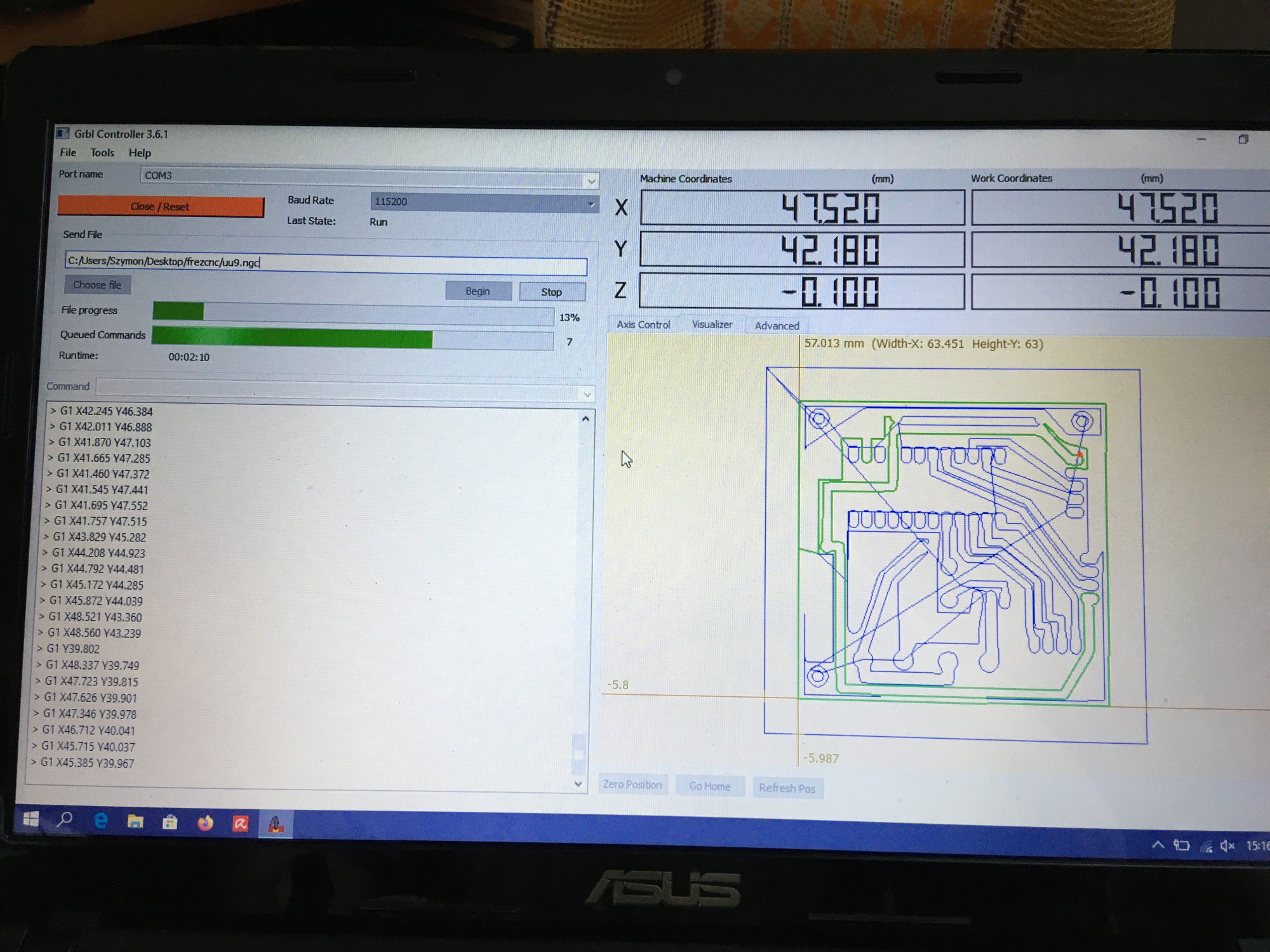
CNC Shield V4.0 czyli jak uruchomić trzyosiową maszynę
Gość opublikował temat w Artykuły użytkowników
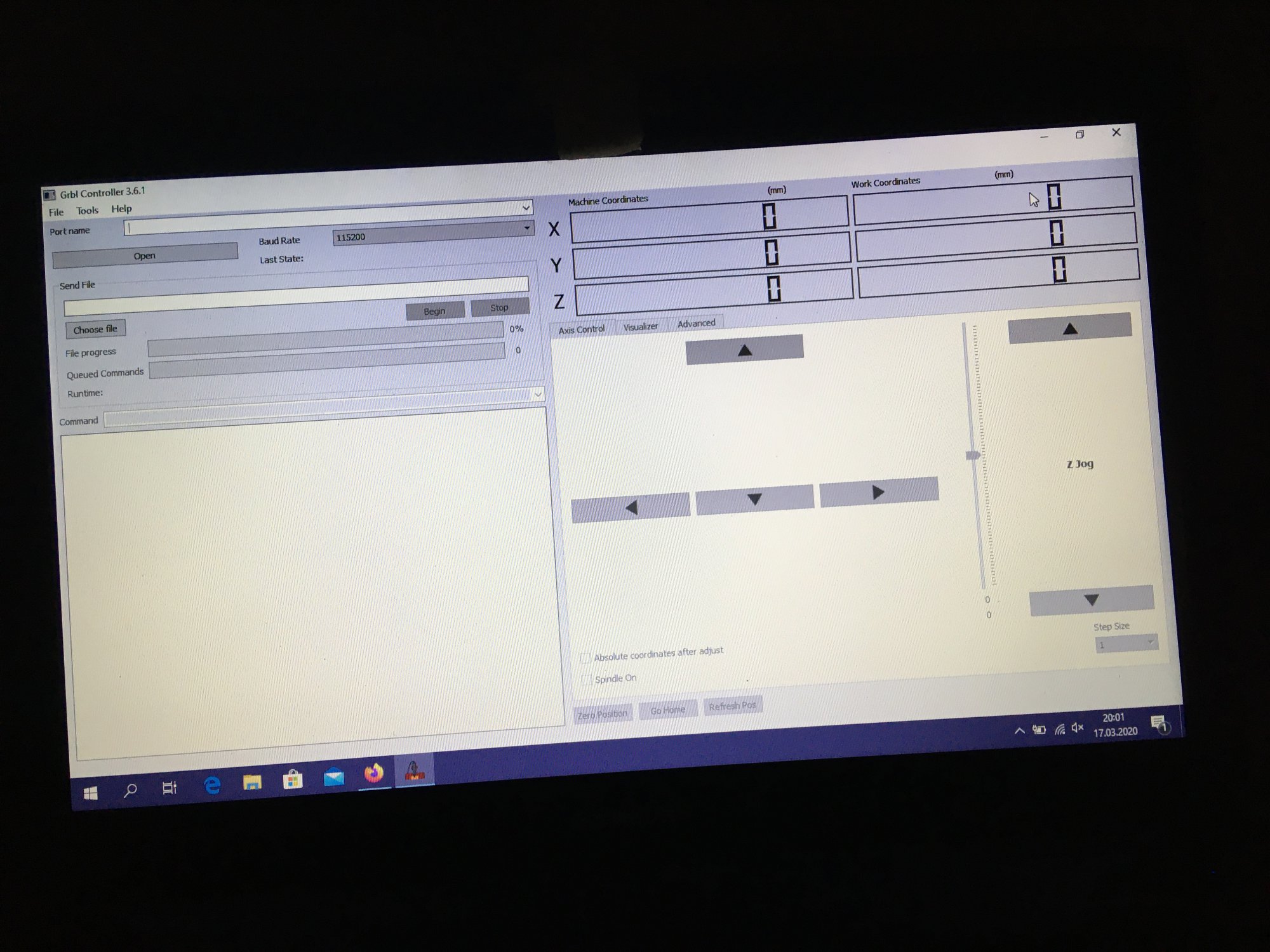
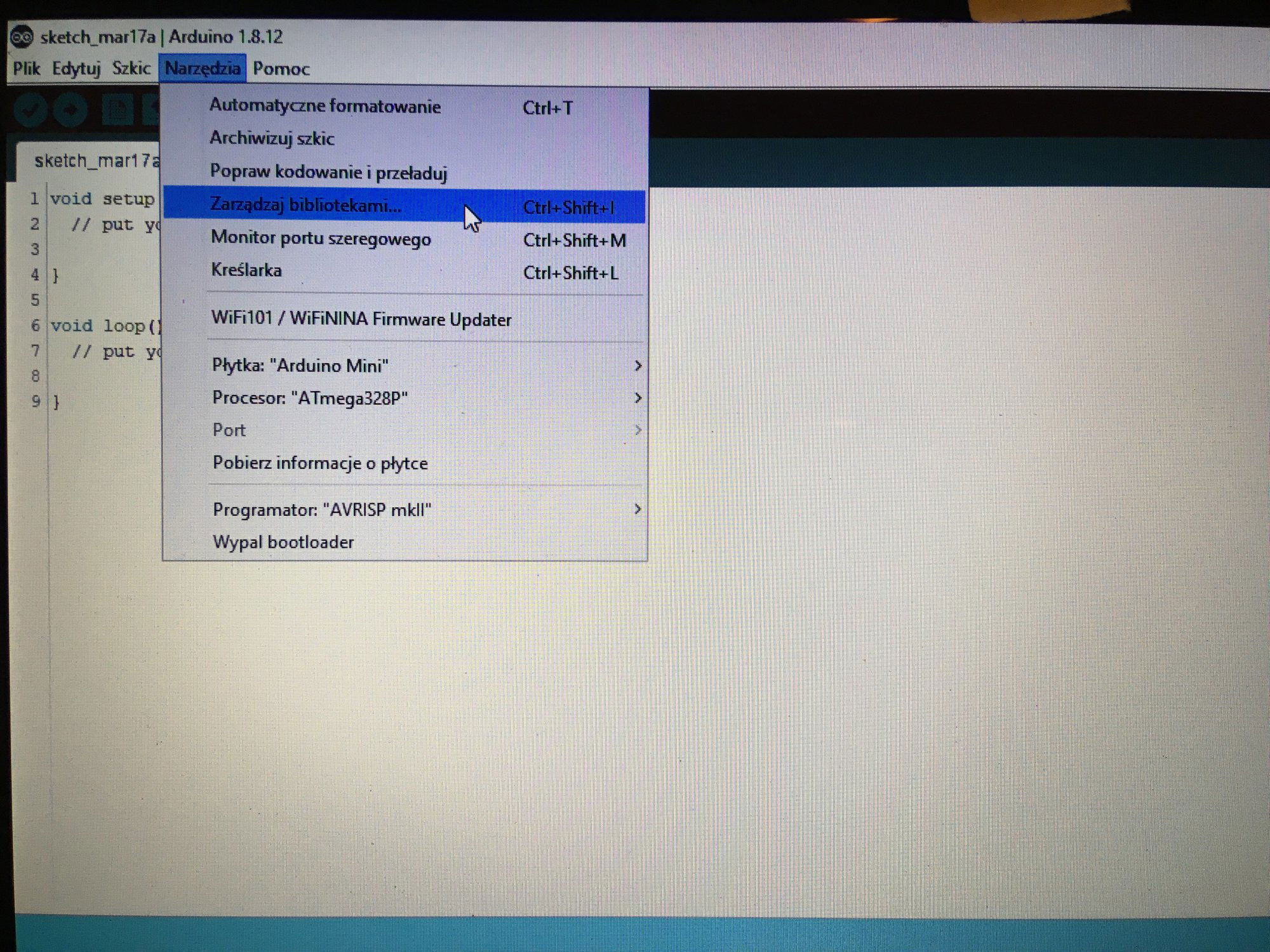
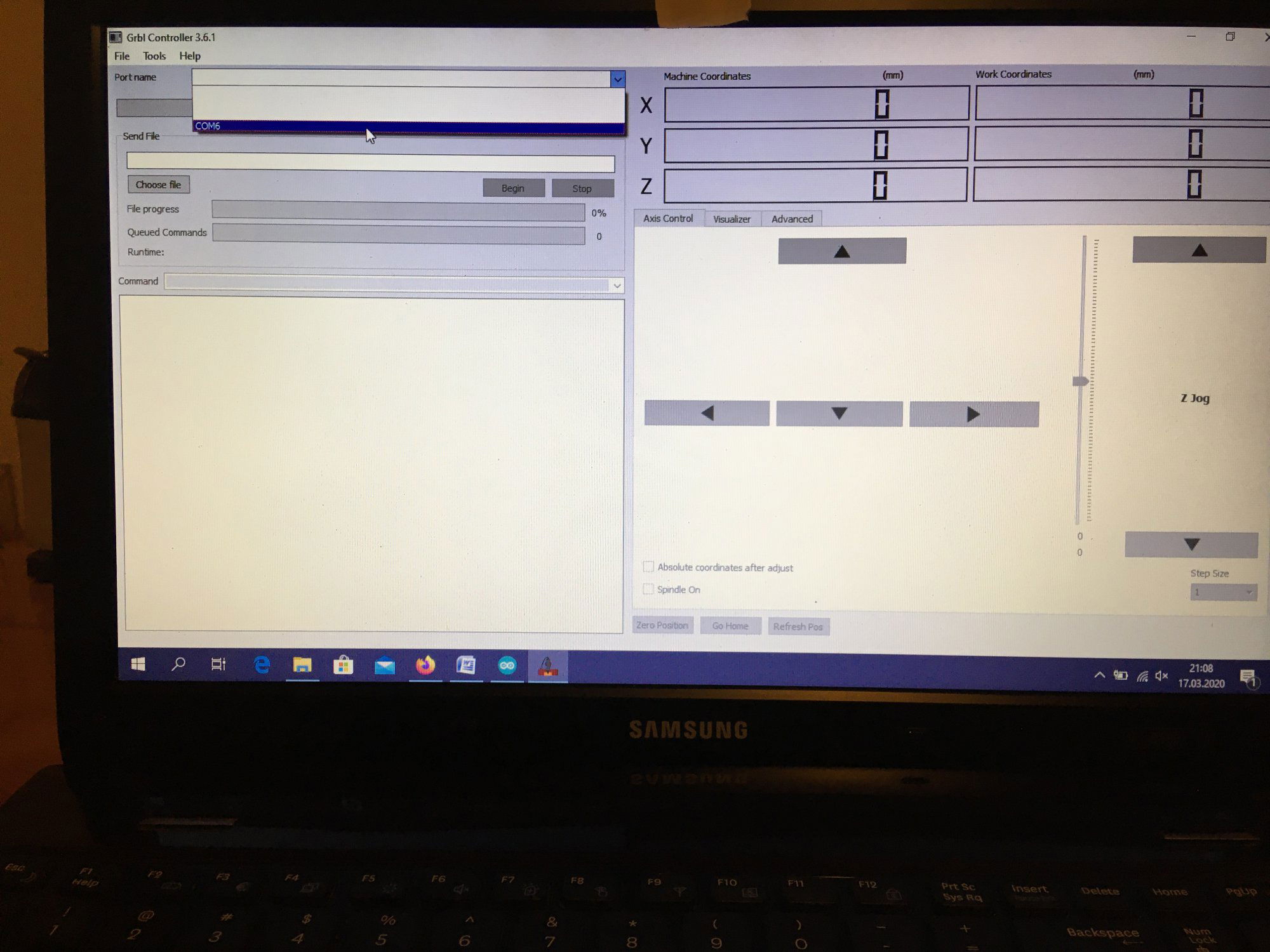
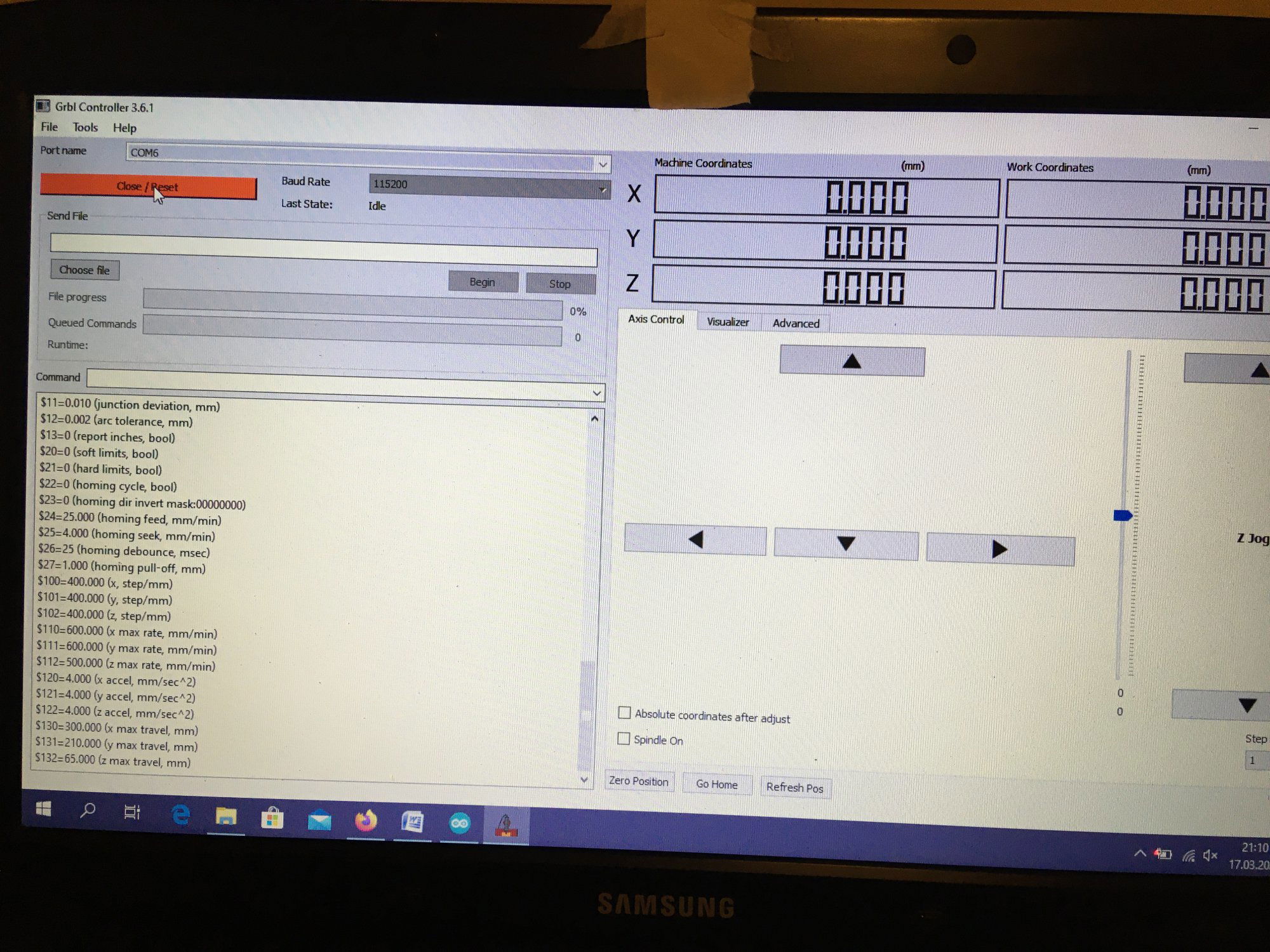
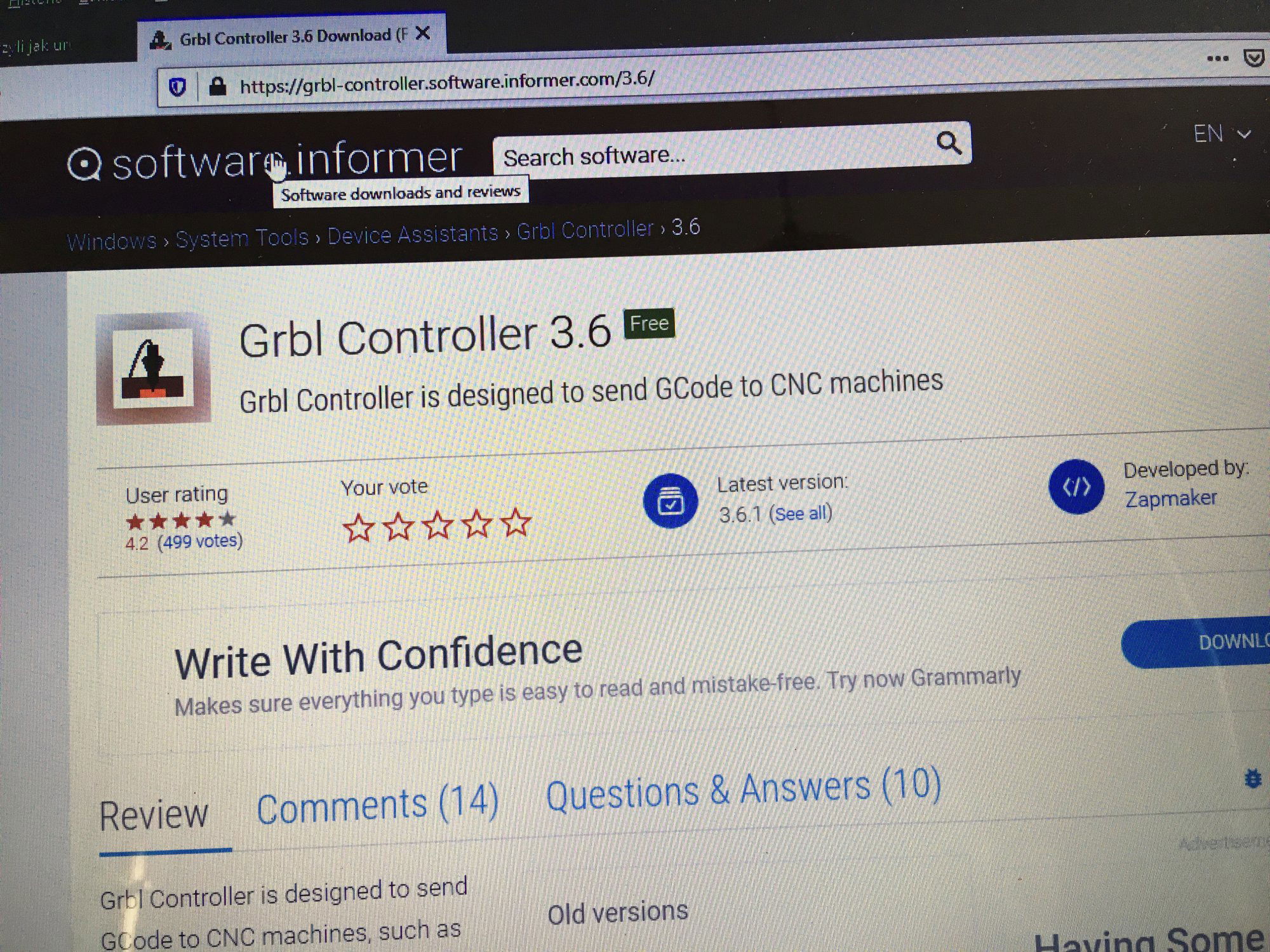
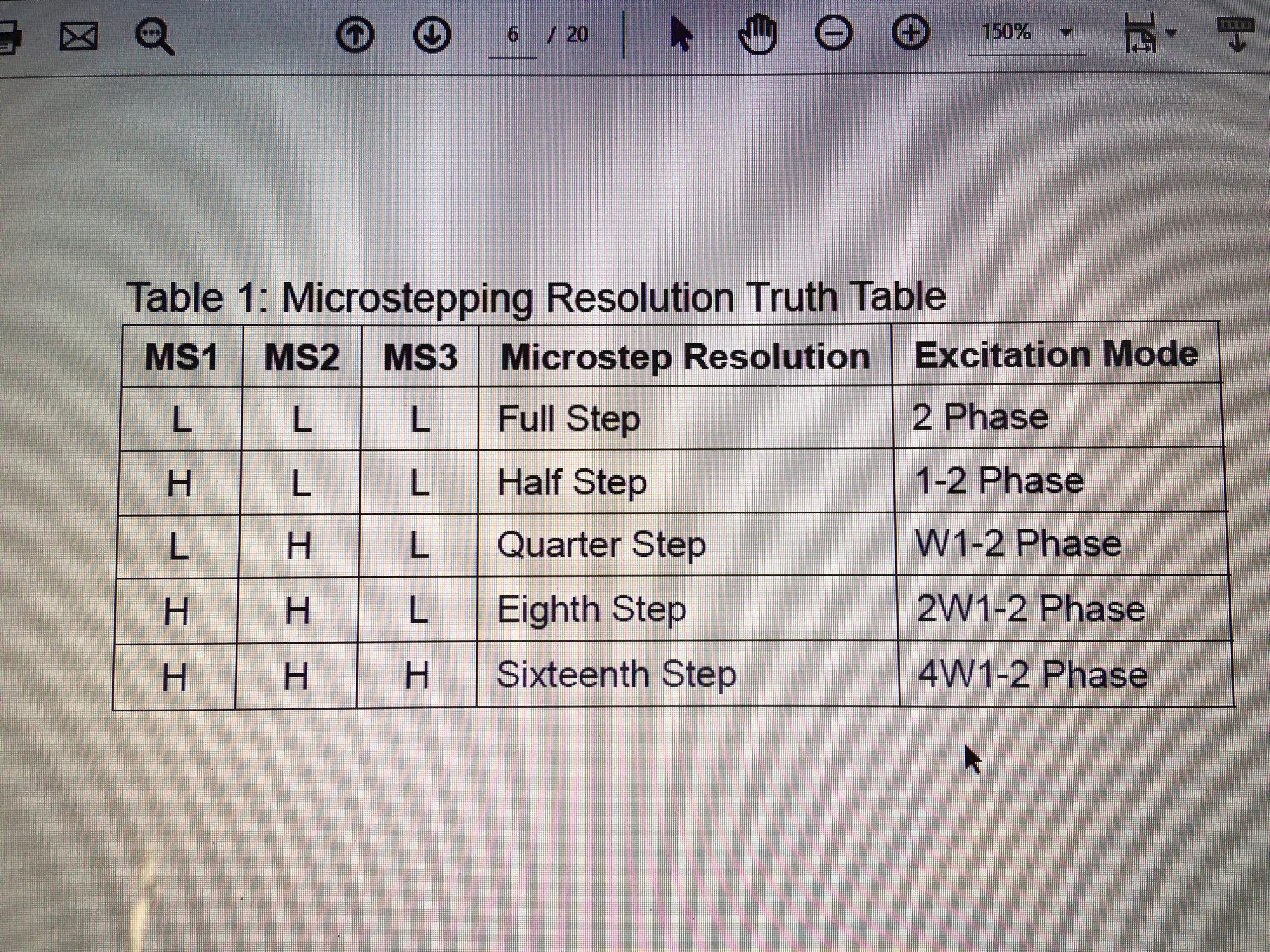
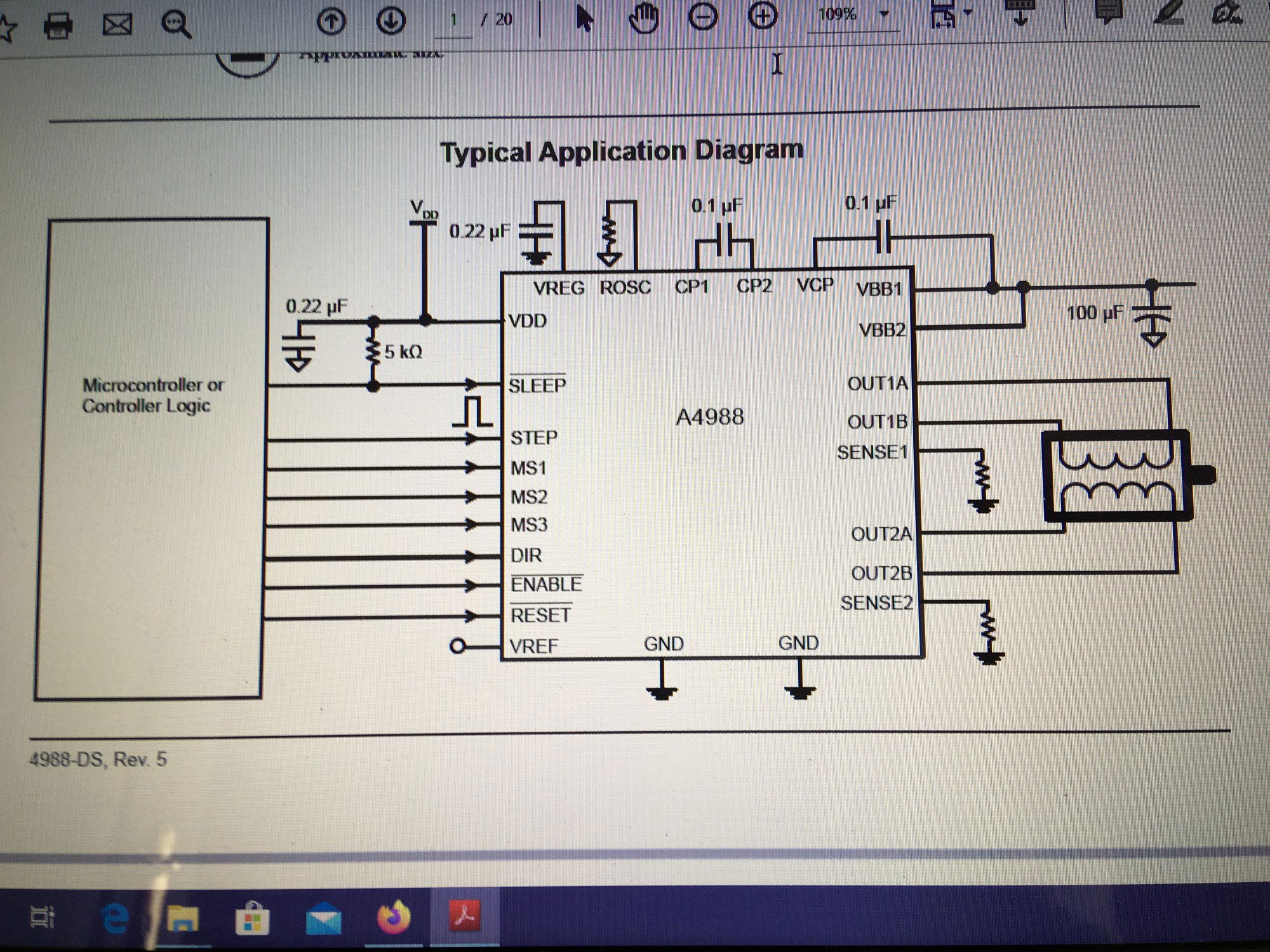
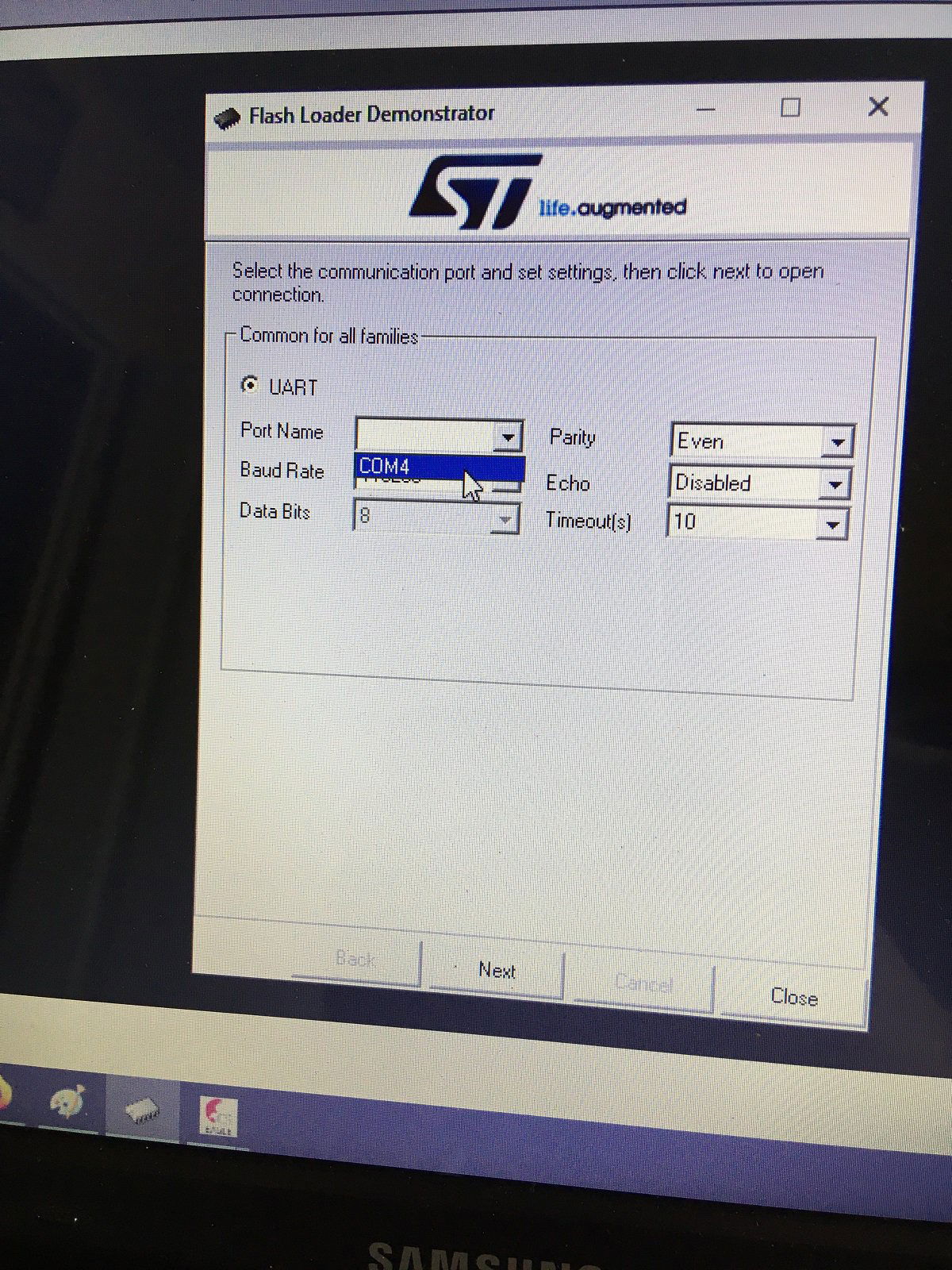
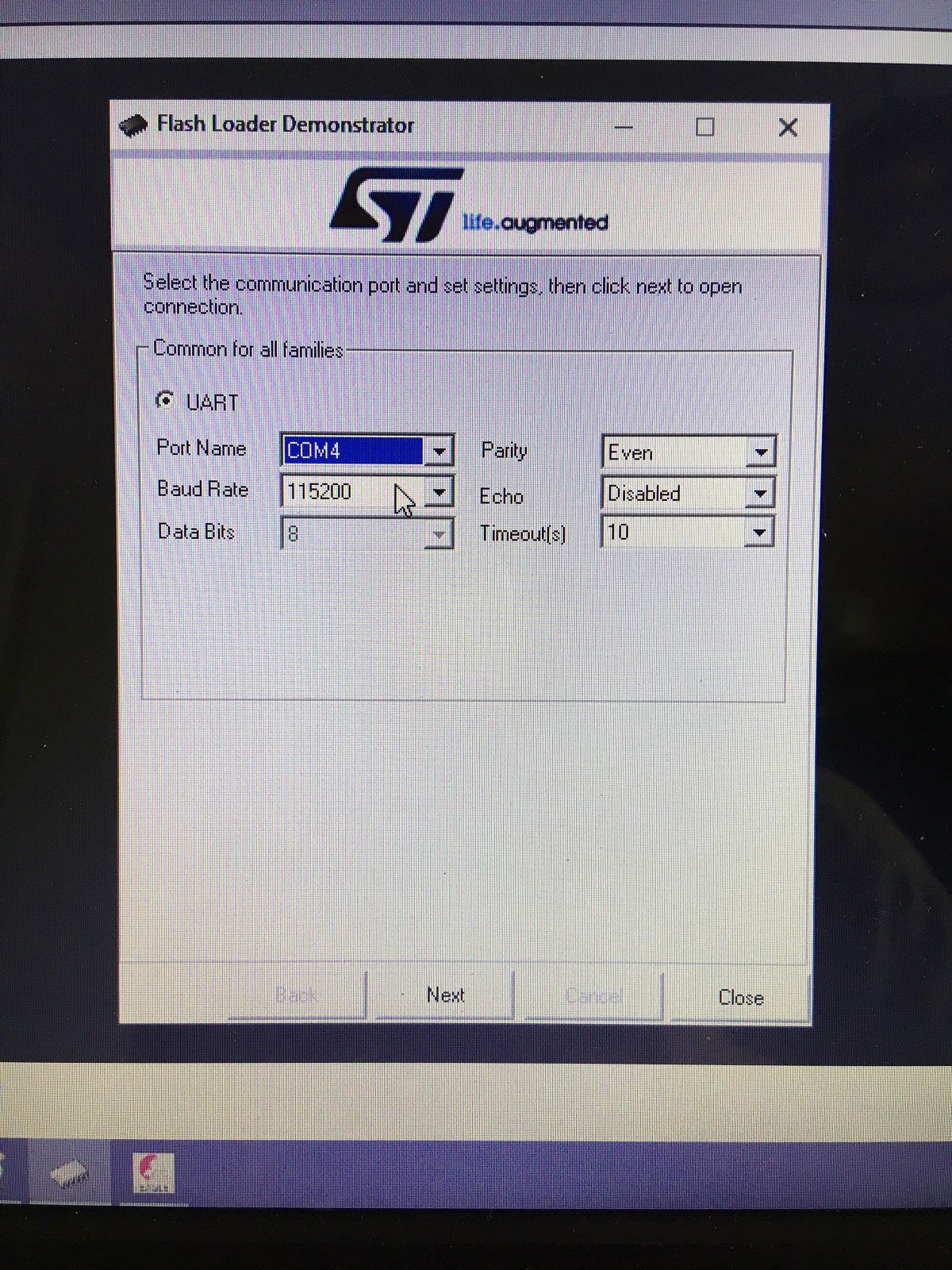
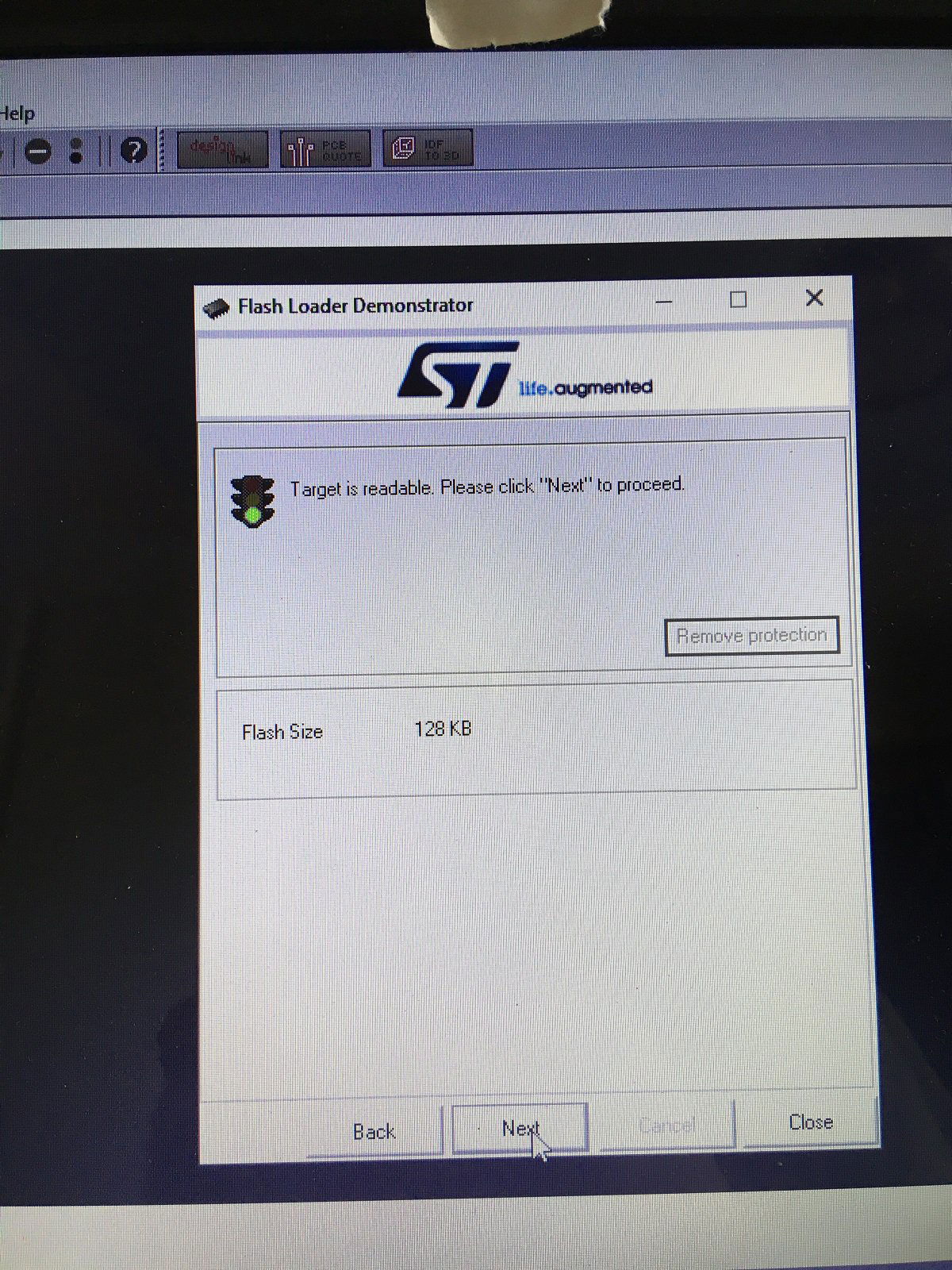
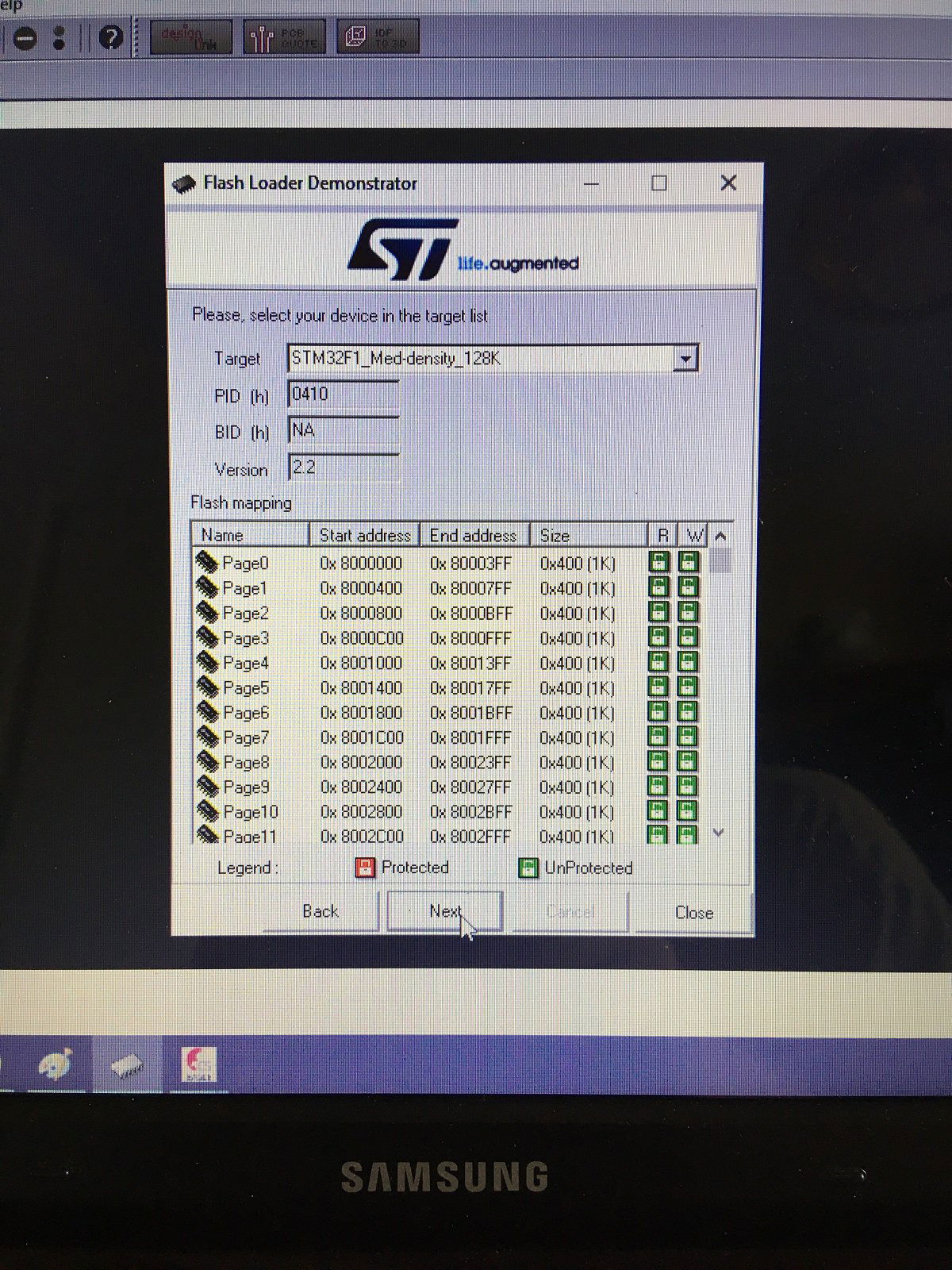
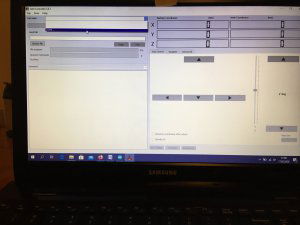
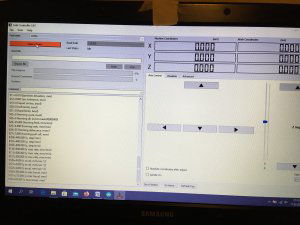
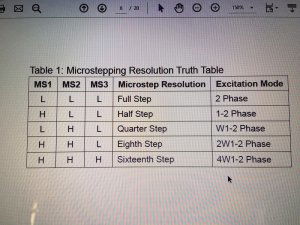
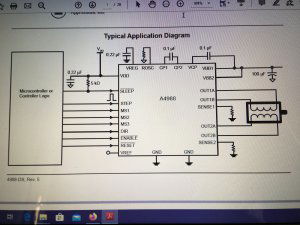
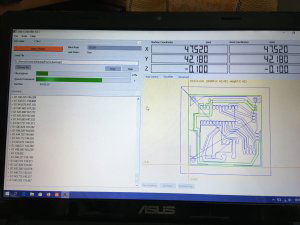
Ten artykuł poświęcony jest CNC Shield V4.0.Ci,którzy kupili ten moduł musieli zmierzyć się z problemami na każdym etapie uruchamiania. Być może większość z Was porzuciła tę płytkę stwierdzając,że nic się nie da z tym zrobić. Ten wpis brał udział konkursie na najlepszy artykuł o elektronice lub programowaniu. Sprawdź wyniki oraz listę wszystkich prac » Partnerem tej edycji konkursu (marzec 2020) był popularny producent obwodów drukowanych, firma PCBWay. Projektując swoją trzyosiową frezarkę postanowiłem,tak jak wielu z Was, użyć do sterowania modułu Arduino NANO + CNC Shield V4.0+A4988.Niska cena, CNC Shield V4.0 firmy KUONGSHUN to specjalnie dedykowany do tych celów moduł. Ponieważ ten artykuł ma być poradnikiem dla wszystkich to zacznijmy zatem od początku. Najpierw instalujemy najnowszą wersję Arduino IDE.Po czym otwieramy Arduino i klikamy w narzędzia->zarządzaj bibliotekami i wpisujemy w wyszukiwarkę GRBL.Po chwili wyświetli się wynik.Klikamy w grbl a następnie klikamy instaluj. Drugim krokiem jest zainstalowanie Grbl controller 3.6.1 https://grbl-controller.software.informer.com/3.6/ Ten program też instalujemy.Bez podłączania płytki możemy otworzyć program i zobaczymy ekran taki jak na poniższym zdjęciu. Czas uruchomień jest czasem weryfikacji, naszych założeń ,myśli technicznej. Po wykonaniu niezbędnych prac mechanicznych zawsze przychodzi czas na podłączenie elektroniki. Wgrałem GRBL i uruchomiłem. Pierwsze włączenie było bardzo rozczarowujące bo oprócz jakichś dźwięków w momencie włączenia sugerujących, że silniki krokowe coś chcą zrobić nie działo się nic. Nie od razu uświadomiłem sobie, że program GRBL został napisany dla Arduino Uno.Analizując problem doszedłem do wniosku, że sygnały DIR i STEP są zamienione.Szukając jakiejś podpowiedzi na forach świata w zasadzie niczego nie znalazłem .Natknąłem się na niesamowity post, którego autor proponował bezczelne przecięcie ścieżek po czym wlutowanie odpowiednich mostków. Cóż, można się tylko uśmiechnąć . Nie znalazłem rozwiązania na forach. Najpierw sprawdziłem z którymi pinami w Arduino Nano łączą się wejścia DIR , STEP oraz ENABLE w A4988.Postanowiłem przetestować całą płytkę to jest Arduino Nano+ Shield V4.0+A4988.W tym celu wgrałem program testowy z właściwie przypisanymi portami do wejść A4988.Uruchomiłem i urządzenie, ku mojej radości zaczęło działać zgodnie z tym co jest napisane w programie. Poniżej procedura i program testowy. //Program obsługuje trzy silniki krokowe i jest przeznaczony do testowania Arduino NANO + CNC Shield V4.0+A4988 #define EN 8 // włączanie silnika krokowego, aktywny niski poziom #define X_DIR 2 // Oś X, kontrola kierunku silnika krokowego #define Y_DIR 3 //Oś Y, kontrola kierunku silnika krokowego #define Z_DIR 4 //Oś Z, kontrola kierunku silnika krokowego #define X_STP 5 //oś x, sterowanie silnikiem krokowym #define Y_STP 6 //oś y, sterowanie silnikiem krokowym #define Z_STP 7 //oś z, sterowanie silnikiem krokowym void step(boolean dir, byte dirPin, byte stepperPin, int steps) { digitalWrite(dirPin, dir); delay(50); for (int i = 0; i < steps; i++) { digitalWrite(stepperPin, HIGH); delayMicroseconds(800); digitalWrite(stepperPin, LOW); delayMicroseconds(800); } } void setup(){ pinMode(X_DIR, OUTPUT); pinMode(X_STP, OUTPUT); pinMode(Y_DIR, OUTPUT); pinMode(Y_STP, OUTPUT); pinMode(Z_DIR, OUTPUT); pinMode(Z_STP, OUTPUT); pinMode(EN, OUTPUT); digitalWrite(EN, LOW); } void loop() { step(false, X_DIR, X_STP, 200); step(false, Y_DIR, Y_STP, 200); step(false, Z_DIR, Z_STP, 200); delay(1000); step(true, X_DIR, X_STP, 200); step(true, Y_DIR, Y_STP, 200) ; step(true, Z_DIR, Z_STP, 200); delay(1000); } Proszę ustawić głowicę maszyny na środku tak by była daleko do brzegów i włączyć.Śruby trapezowe powinny wykonać dokładnie jeden obrót w prawo a później jeden obrót w lewo i tak w kółko.W ten oto sposób Wasza maszyna stała się pierwszą prostą maszyną CNC. Następnym krokiem było odnalezienie właściwej biblioteki w GRBL i muszę powiedzieć, że się trochę naszukałem ale w końcu znalazłem. Od tego momentu wszystko potoczyło się szybko.Ta biblioteka jest umieszczona w dokumentach na dysku c, u mnie c:\Documents\Arduino\libraries\grbl\cpu_map\cpu_map_atmega328p.h którą należy otworzyć za pomocą notatnika(dla Windows10) i zmienić . Zanim zaczniesz zmieniać zrób sobie kopię tej biblioteki tak na wszelki wypadek, może się przyda do innych projektów z inną płytką ale tym samym mikrokontrolerem. GRBL w Arduino został napisany pod Arduino Uno a producent płytki Shield V4.0 nie zastosował ustawień portów Arduino Uno w Arduino Nano. Zmiany, których dokonałem są uwidocznione tłustym drukiem.Należy zmienić tylko cyferki ! // Define step pulse output pins. NOTE: All step bit pins must be on the same port. #define STEP_DDR DDRD #define STEP_PORT PORTD #define X_STEP_BIT 5 // Uno Digital Pin 2, dla Nano D5 #define Y_STEP_BIT 6 // Uno Digital Pin 3, dla Nano D6 #define Z_STEP_BIT 7 // Uno Digital Pin 4, dla Nano D7 #define STEP_MASK ((1<<X_STEP_BIT)|(1<<Y_STEP_BIT)|(1<<Z_STEP_BIT)) // All step bit // Define step direction output pins. NOTE: All direction pins must be on the same port #define DIRECTION_DDR DDRD #define DIRECTION_PORT PORTD #define X_DIRECTION_BIT 2 // Uno Digital Pin 5 dla Nano D2 #define Y_DIRECTION_BIT 3 // Uno Digital Pin 6, dla Nano D3 #define Z_DIRECTION_BIT 4 // Uno Digital Pin 7, dla Nano D4 Niestety nie są to wszystkie zmiany w oprogramowaniu bo po włączeniu będą chodzić tylko dwie osie X i Y.Oś Z nie wystartuje. Należy dokonać kolejnej zmiany w tym samym pliku trochę poniżej: #ifdef VARIABLE_SPINDLE // Z Limit pin and spindle enabled swapped to access hardware PWM on Pin 11. #define Z_LIMIT_BIT 3 // Uno Digital Pin 11 ,w oryginale 4 #else #define Z_LIMIT_BIT 4 // Uno Digital Pin 12, w oryginale 3 Zapisujemy zmiany i zamykamy plik.Następnym krokiem jest wyczyszczenie pamięci EEPROM za pomocą programu eeprom_clear,który jest umieszczony w przykładach dla Arduino.Jeśli nie ma wchodzimy do zarządzaj bibliotekami ,odnajdujemy i instalujemy a następnie wracamy do przykładów, odnajdujemy i wgrywamy do mikrokontrolera. Następnie wyszukujemy w przykładach Grbl kompilujemy a następnie wgrywamy.Następnie uruchamiamy Grbl controller i wyszukujemy port com klikając w port name Ustawiamy głowicę maszyny na środku tak by była daleko do brzegów. Klikamy dwa razy w start/reset.Czekamy cierpliwie aż wszystko się uruchomi.Ustawiamy step size na 1 i sprawdzamy najpierw oś Z a następnie pozostałe.Apeluję o ostrożność w klikaniu w strzałki na pulpicie.Jedno kliknięcie to jeden step size czyli np.200 kroków silnika.Osie X i Y nie wystartują dopóki nie ruszysz osi Z.Controller Grbl został tak napisny,że najpierw musi zostać wykonany ruch osi Z do góry a dopiero później dostępne są osie X,Y i jest to naturalne bo trzeba chronić narzędzie i materiał przed niepotrzebnym zniszczeniem. Wydawać by się mogło, że to już koniec zmian ale niestety twórca CNC Shield V4.0 zapomniał o jeszcze jednym jak się okazuje kluczowym drobiazgu a mianowicie o sterowaniu silnikami krokowymi zworkami M0,M1,M2.W tym stanie w jakim jest płytka zapomnijcie o 1/2,1/4 ,1/8,1/16 kroku. Otóż w A4988 M0,M1,M2 są na potencjale 0V(gdzieś w środku A4988 M0,M1,M2 są połączone przez rezystory M0 i M2 100k a M1 50k do GND) i by sterować musimy na nie podać 5V albo 0V.Zworka z jednej strony łączy pin z M0,M1,M2 a z drugiej powinna łączyć do +5V.W płytce CNC Shield V4.0 łączy do masy czyli 0V. Sytuacja którą zastałem jest ewidentnym błędem projektanta płytki,który pogubił się bo czy zworki będą zainstalowane czy też nie, zawsze będziemy mieć 200 kroków/obrót(patrz tabelka poniżej) co przy śrubie trapezowej o skoku 8mm oznacza 25 kroków na milimetr a to nie jest najlepszą opcją. Co zrobić w tej dramatycznej sytuacji?Są dwa wyjścia zwrócić sprzedawcy płytkę lub zainwestować w trzy druciki i 9 rezystorów SMD co jest kosztem rzędu 0,1-0,2 zł. Zastosowałem rezystory podciągające na M0,M1,M2 do potencjału 5V. W moim CNC Shield V4.0 wlutowałem 9 rezystorów smd o wartości 10k(takie miałem pod ręką) tak jak to widać na zdjęciu.Lutowanie należy przeprowadzić ostrożnie by nie naruszyć solder maski, która jest doskonałym izolatorem. Z jednej strony podłączone są do M0,M1,M2 a z drugiej strony rezystory są zwarte razem i podłączone do VDD(5V) A4988(jak sobie powiększycie obrazek to zobaczycie drucik łączący VDD A4988 z rezystorami) . Po tej zmianie wszystko działa tak jak należy. Gdyby komuś przyszło do głowy nie wlutowywać rezystorów a bezpośrednio podłączyć do 5V to przy zainstalowaniu zworki nastąpi zwarcie i układ zasilający powinien się uszkodzić a może coś więcej. W płytce CNC Shield V4.0 M0 to MS1, M1 to MS2,M2 to MS3 Poniższe zdjęcie pokazuje jak wygląda ekran controllera GRBL podczas pracy frezarki CNC. I to już wszystko.Nie poruszam tematu sterowania wrzecionem i pompą tłoczącą chłodziwo w przypadku wycinania w metalu.Jak widać nie wszystko stracone bo moduł można poprawić,program można przystosować.Nie poruszam tematu ustawień controllera grbl bo to znajdziedzie gdzieś na forum.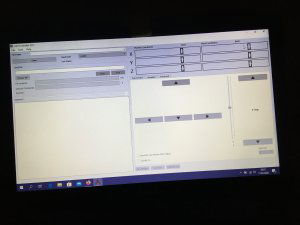


-
Kurs ESP8266 - #3 - przyspieszony kurs na Webmastera
Leoneq opublikował temat w Artykuły użytkowników
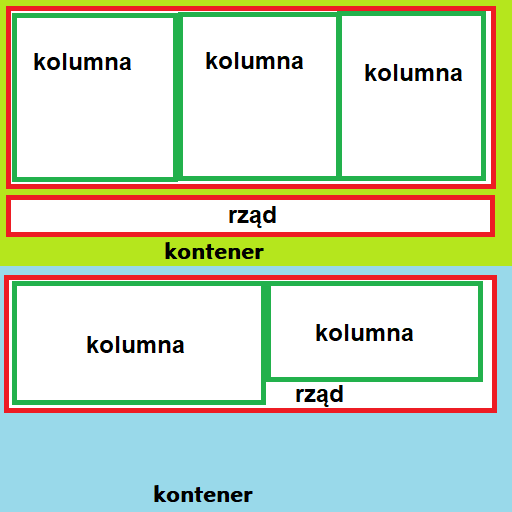
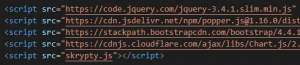
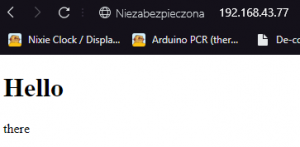
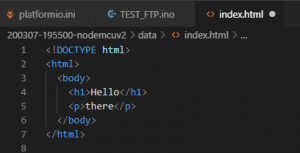
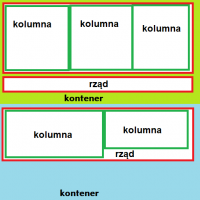
W poprzednim odcinku nauczyliśmy się włączać i wyłączać diodę LED przez Internet. Jedyne co wtedy zawierała strona, to krótki wyraz. Jeżeli chcemy, aby nasza strona była ładna, przejrzysta, i przede wszystkim - w 100% funkcjonalna, musimy się nauczyć podstaw HTMLa. Ale czym ten HTML jest? W skrócie, jest to język w którym piszemy strony WWW. To, jak strona ma wyglądać - piszemy w CSS, a co strona ma robić (animacje, skrypty) - piszemy w JavaScript (to pod żadnym pozorem nie jest zwykła Java). Zatem, zaczynamy! Ten wpis brał udział konkursie na najlepszy artykuł o elektronice lub programowaniu. Sprawdź wyniki oraz listę wszystkich prac » Partnerem tej edycji konkursu (marzec 2020) był popularny producent obwodów drukowanych, firma PCBWay. Spis treści serii artykułów: 1. Omówienie, i przygotowanie środowiska 2. Zapoznanie z nowym środowiskiem, praca jako Arduino, prosty serwer WWW 3. Przyspieszony kurs na webmastera 4. Wykresy, zapis do SPIFFS, mini smart-dom 5. Odbiór danych z przeglądarki, stałe IP, łączenie modułów ESP Plik index.html Proponuję zacząć od stworzenia strony na komputerze. Nie jest to trudne, a dopiero kiedy uznamy że strona jest gotowa - wgramy ja do mikrokontrolera. Stwórzmy zatem nowy folder: W środku tworzymy nowy plik: index.html. To będzie nasza strona główna. Otwieramy, i na razie wklejamy to: <!DOCTYPE html> <html> <body> <h1>Hello</h1> <p>there</p> </body> </html> Zapisujemy, i otwieramy w przeglądarce: Spróbujmy zrobić to samo na ESP. Możemy to zrobić na kilka sposobów: zrobić Stringa i co linijkę dodawać kod w htmlu (oof) wgrać na zewnętrzną pamięć i odczytać z np. karty sd (przekombinowane) na stałe zakodować stronę (to nie jest nasz cel) użyć SPIFFS (very nice) SPIFFS Już wyjaśniam co to SPIFFS. W pierwszym artykule wspomniałem, że na płytkach ESP są dwa układy: mikrokontroler i pamięć flash. Bardzo dobrze to widać na ESP01. Do tej drugiej kostki wgrywamy nasz program - ale co, gdyby na to wgrać coś innego? Espressif przewidział tą możliwość, i zrobił takie coś jak SPI Flash File System (SPIFFS). Oznacza to tyle, że dostajemy w pełni funkcjonalny (i wbudowany!) system plików. Jaka jest jego pojemność? Definiujemy to w konfiguracji płytki - zwykle dzielimy pamięć na kod i SPIFFS (dla NodeMCU może to być 2 i 2MB). Otwieramy folder z naszym projektem Platformio. Na tym samym poziomie co plik platformio.ini, tworzymy folder /data. Pliki w środku będą skopiowane do ESP. Przenieśmy zatem naszego indexa do /data, i odpalmy VS Code: VS Code jest na tyle mądry, że obsługuje składnię wielu języków - w tym i HTMLa. Po otworzeniu powinniśmy zobaczyć coś takiego: Aby wgrać naszą stronę, przechodzimy do zakładki Terminal → Run Task. Szukamy tam "Upload File System Image" - i czekamy aż się wgra nasz plik. Musimy teraz wprowadzić lekkie modyfikacje do kodu. Zaczynamy od biblioteki obsługującej nasz system plików. #include <FS.h> Zróbmy sobie teraz funkcję (tudzież zmienną) która zwróci nam całą stronę. W środku "getPage" robimy kolejnego stringa, do którego dodajemy po kolei znak po znaku. Plik musi być najpierw otwarty, potem zamknięty - możemy obsłużyć 1 plik naraz. Na końcu zwracamy stringa ze stroną. Co robi "r"? Spróbuj sam zobaczyć, naciskając Spację+CTRL. String getPage() { String strona; File file = SPIFFS.open("/index.html", "r"); while(file.available()) strona+=(char)file.read(); file.close(); return strona; } Na samym początku funkcji setup odpalamy bibliotekę. Ja to dodatkowo obudowałem w wyświetlanie wiadomości na LCD: lcd.setCursor(0, 0); lcd.print("SPIFFS "); if(!SPIFFS.begin()) lcd.println("x"); else lcd.println("√"); Na koniec zostało tylko dopisać do funkcji obsługujących klienta, że strona ma być brana z getPage. void handleRoot() { server.send (200, "text/html", getPage()); } void handleOn() { digitalWrite(PIN_LED, LOW); server.send(200, "text/html", getPage()); } void handleOff() { digitalWrite(PIN_LED, HIGH); server.send(200, "text/html", getPage()); } Wgrywamy program, i wpisujemy adres IP do przeglądarki: Można powiedzieć, że pierwsza część backendu (piękny slang informatyczny) za nami. Teraz zajmijmy się frontendem. Specjalnie do tego przygotujemy sobie DS18B20, do znalezienia w zestawach kursu na malinke lub Arduino II. Zrobimy sobie mały inteligenty domek. Nie bój się dodać kilka innych czujników, o ile wiesz co będziesz robił. Pierwsze kroki z HTML W językach z rodziny C każdą funkcję zapisujemy przez jej nazwę, i otwierając klamerki. W HTMLu piszemy <x> aby zacząć pewien element, </x> aby go zakończyć. Przeanalizujmy zatem nasz kod "hello there": <!DOCTYPE html> <html> <body> <h1>Hello</h1> <p>there</p> </body> </html> Na początku mamy doctype. Informuje on przeglądarkę o tym, z jakim rodzajem dokumentu ma ona do czynienia. Piszemy wszystko w HTML5, w starszym HTMLu deklaracja ta by wyglądała inaczej. Gdybyśmy tego nie dali, przeglądarka mogłaby pomyśleć że ma do czynienia z HTML 3 lub starszym. Po definicji, otwieramy cały dokument - <html>. Otwieramy także <body> - tam zapisujemy wszystko to, co widzimy. Mamy zatem już szkielet strony - możemy dodać nagłówek <h1> oraz tekst <p>. Ale nikt chyba nie lubi Times New Romana (chyba, że robimy gazetę) - spróbujmy zmienić czcionkę. Kiedyś, dawno temu wszystko się kodowało w HTMLu (strony z 2004/5 mocno to pokazują). Dzisiaj używamy CSS do określania stylów - Obok index.html tworzymy zatem style.css. W środku możemy zapisywać, co elementy o danym ID lub danej klasie będą miały za właściwości. h1 { font-family: Arial, Helvetica, sans-serif; } #idd { color: #ccc; } .klasa { font-size: 10px; } Plik style.css to zbiór wszystkich naszych właściwości danych elementów. W powyższym kodzie, na początku mówimy że każdy h1 będzie pisany Arialem. Elementy z id #idd będą miały kolor szarawy, a z klasą .klasa będą wysokie na 10px. Od razu powiem, czym klasa różni się od id: jeżeli mamy przyciski, które się mają różnić tylko kolorem, musielibyśmy robić prawie dwa identyczne id, a na klasach - tylko jedna pod przycisk, i dwie małe pod kolor. Ba, możemy potem klasy 'kolor' wykorzystać gdzie indziej (np. do tekstu). Zobaczmy teraz, czy style działają. Najpierw musimy jednak zmodyfikować indexa: <head> <link rel="stylesheet" type="text/css" href="style.css"> </head> <body> <h1>Hello</h1> <p class="klasa">there</p> <p id="idd">general kenobi</p> </body> Pojawił się znacznik <head>. Tam często linkujemy dokumenty niezbędne do funkcjonowania strony, oraz definiujemy takie rzeczy jak nazwa, ikona, charset, itd - jak mówiłem, body widzimy, head nie. Zauważyłeś także, że przy znacznikach <p> są przypisane klasy i id. Możemy w ten sam sposób (przy znaczniku) także podać kolory i inne właściwości, ale od tego się odchodzi (dlatego wam pokazuję css). Na końcu, musimy jeszcze podać obsługę żądania ip/style.css do kodu. Dodajemy drugiego stringa czytającego style.css, oraz obsługę dla klienta - analogicznie jak w indexie. String getStyle() { String strona; File file = SPIFFS.open("/style.css", "r"); while(file.available()) strona+=(char)file.read(); file.close(); return strona; } void handleStyle() { server.send(200, "text/css", getStyle()) } //setup() server.on("/style.css", handleStyle); Wgrywamy kod, pliki i sprawdzamy, czy działa: Spróbujmy teraz zaimplementować JavaScript. Daje nam to możliwość "podstawiania" zmiennych do tekstu i dynamiczną zmianę strony, bez jej ponownego wczytywania. Podłącz swój czujnik i napisz kod (poważnie, jeżeli termometr zrobiłeś na Arduino, to na ESP nie będziesz mieć problemu). Ja wykorzystam Dallas DS18B20, dostępnego w forbotowym zestawie z malinką i Arduino - jest to cyfrowy termometr. Link do artykułu jest tutaj, a jak już mamy do niego kod, czas modyfikować stronę. Pouczymy się teraz czystego HTMLa (no, a bardziej frameworków). Podstawowe znaczniki HTML Znaczników mamy kilka(naście). Najbardziej będą potrzebne: <p> - tekst <hX> - nagłówek, za X dajemy numer (wielkość) <div> - pusty blok <button> - przycisk <a> - link <img /> - zdjęcie (uwaga: zdjęcia nie otwieramy, tylko od razu zamykamy) <script>, <style> - tam umieszczamy fragmenty kodu JS lub CSS <html>, <body>, <head> - tworzą szkielet strony Aby te znaczniki ostylować, możemy "surowo" to zrobić w HTMLu, dodać własne CSS, lub skorzystać z gotowych frameworków. Ale jak z gotowych? Otóż Bootstrap to framework zawierający zestawy klas, umożliwiające stworzyć ładną, i responsywną stronę. Oznacza to tyle, że kodowania będzie mało, a dostaniemy własną, elegancką stronę do wyświetlenia na wszystkim co ma dostęp do internetu. Będziemy chcieli stworzyć ładną stronę z dwoma przyciskami, i etykietą pokazującą temperaturę. Bootstrap Otwieramy plik indexa. Wszystko w <head> usuwamy i wklejamy to: <meta charset="utf-8"> <link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.4.1/css/bootstrap.min.css" integrity="sha384-Vkoo8x4CGsO3+Hhxv8T/Q5PaXtkKtu6ug5TOeNV6gBiFeWPGFN9MuhOf23Q9Ifjh" crossorigin="anonymous"> <title>domek</title> Pierwszy znacznik informuje stronę o zestawie znaków - tutaj utf-8 (umożliwi to nam wyświetlanie polskich znaków). Następnie linkujemy arkusz bootstrapa, po czym nadajemy naszej stronie nazwę "domek". Przydałoby się jeszcze dodać FontAwesome, z tego linku (trzeba się zarejestrować). Pozwoli nam to na wyświetlanie różnych ikonek. Przechodzimy do samego dołu dokumentu. Tam dopisujemy: <script src="https://code.jquery.com/jquery-3.4.1.slim.min.js" integrity="sha384-J6qa4849blE2+poT4WnyKhv5vZF5SrPo0iEjwBvKU7imGFAV0wwj1yYfoRSJoZ+n" crossorigin="anonymous"></script> <script src="https://cdn.jsdelivr.net/npm/[email protected]/dist/umd/popper.min.js" integrity="sha384-Q6E9RHvbIyZFJoft+2mJbHaEWldlvI9IOYy5n3zV9zzTtmI3UksdQRVvoxMfooAo" crossorigin="anonymous"></script> <script src="https://stackpath.bootstrapcdn.com/bootstrap/4.4.1/js/bootstrap.min.js" integrity="sha384-wfSDF2E50Y2D1uUdj0O3uMBJnjuUD4Ih7YwaYd1iqfktj0Uod8GCExl3Og8ifwB6" crossorigin="anonymous"></script> </body> </html> Pierwszy skrypt ładuje jQuery (lekki javascript), następny Poppera (pomaga bootstrapowi w responsywności), ostatni skrypt uzupełnia Bootstrapa. Dlaczego je ładujemy na końcu? To są największe pliki do załadowania, i często da się skorzystać ze strony bez nich. Jest to optymalizacja ładowania strony przy wolnym łączu. Szkielet strony W boostrapie tak wygląda struktura strony: Mistrz painta w akcji. Strona zawiera kontenery (.container), rzędy (.row), i kolumny (.col-*-*). Umożliwia to stworzenie eleganckiej i responsywnej strony w kilku łatwych krokach. Chcemy mieć kontener, rząd i kolumnę: <div class="container"> <div class="row"> <div class="col-sm"> </div> </div> </div> "container" to klasa kontenera, "row" rzędu, a "col-sm" małej kolumny. Teraz dajmy nagłówek, opis, etykietę i dwa przyciski: <div class="container"> <div class="row"> <div class="col-sm"> <h1>Centralna Baza Dowodzenia</h1> <p>Dumnie wspierane przez ESP8266</p> <a type="button" class="btn btn-success" href="/on">ON</a> <a type="button" class="btn btn-danger" href="/off">OFF</a> <p>Temperatura: <span id="temp"> N/A </span></p> </div> </div> </div> Elementy <h1> oraz <p> są domyślnie w Bootstrapie ostylowane. Tworzymy dwa linki o typie przycisków (odsyłam do kursu HTML na dole strony), oraz przypisuję im klasy przycisku, potem konkretnie o kolorach zielony i czerwony. Odsyłają one do podstron /on i /off, tak jak było wcześniej. Na koniec dajemy tekst, oraz etykietę z id "temp" która się przyda do skryptowania. Spróbujmy zatem to wgrać do SPIFFS i uruchomić: Jeżeli chcemy podejrzeć strukturę strony, wystarczy kliknąć prawy przycisk myszy i wybrać Zbadaj Element (chrome/opera). Pierwsze przygody z jQuery Uznajmy, że skończyliśmy stronę. Teraz spróbujmy wyświetlić temperaturę. na samym dole, przed gotowymi skryptami, otwieramy <script>. <script> </script> Dodajemy funkcję setInterval, wykonującą się co sekundę. <script> setInterval(function() { }, 1000); </script> W tej funkcji dodajemy ten kod: var strona = new XMLHttpRequest(); strona.onreadystatechange = function() { if (this.readyState == 4 && this.status == 200) { document.getElementById("temp").innerHTML = this.responseText; } }; Tworzymy zmienną strona, która wywołuje żądanie do strony. Kiedy mamy naszą stronę, sprawdzamy, czy wszystko się poprawnie załadowało (status 200). Jeżeli tak, zmieniamy tekst. strona.open("GET", "/temp", true); strona.send(); Na koniec tworzymy żądanie, a potem je wysyłamy. Całość zatem powinna wyglądać tak: <script> setInterval(function() { var strona = new XMLHttpRequest(); strona.onreadystatechange = function() { if (this.readyState == 4 && this.status == 200) { document.getElementById("temp").innerHTML = this.responseText; } }; strona.open("GET", "/temp", true); strona.send(); }, 10000); </script> Zostało nam wgrać nową stronę do SPIFFS, i modyfikujemy kod: void handleTemp() { ds.requestTemperatures(); cls(); lcd.print("Temperatura: "); lcd.println(ds.getTempCByIndex(0)); server.send (200, "text/html", (String)ds.getTempCByIndex(0)); } server.on("/temp", handleTemp); Standardowo już, w setupie dodajemy obsługę /temp, a w funkcji ją zwracamy i wypisujemy przy okazji temperaturę na wyświetlaczu. Efekt: Przyciski działają, mamy temperaturę - zadanie wykonane. Spróbuj teraz dodać sterowanie np. serwem, i odczyt z kontaktronu. W następnym odcinku zgłębimy Bootstrapa, FontAwesome i podepniemy DNSy. Powodzenia! Jeżeli chcesz się bardziej pouczyć HTMLa, CSS i frameworków, masz tutaj garść przydatnych linków (po polsku!): Bootstrap jQuery HTML CSS Spis treści serii artykułów: 1. Omówienie, i przygotowanie środowiska 2. Zapoznanie z nowym środowiskiem, praca jako Arduino, prosty serwer WWW 3. Przyspieszony kurs na webmastera 4. Wykresy, zapis do SPIFFS, mini smart-dom 5. Odbiór danych z przeglądarki, stałe IP, łączenie modułów ESP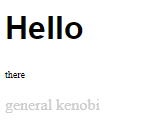




-
Kurs ESP8266 - #1 - omówienie, przygotowanie środowiska
Leoneq opublikował temat w Artykuły użytkowników
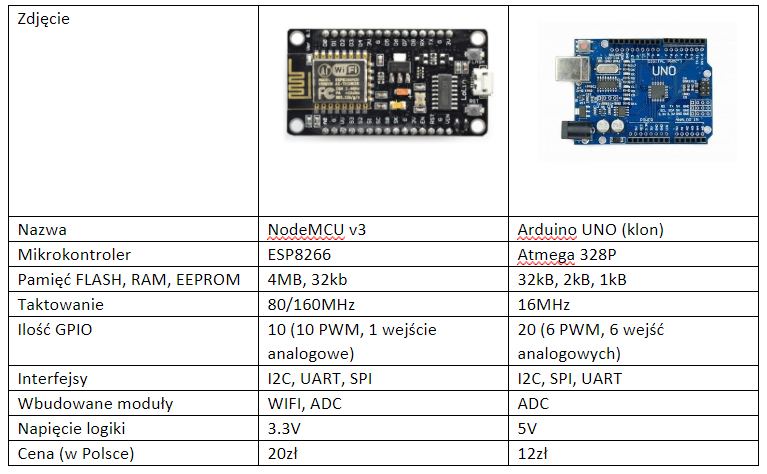
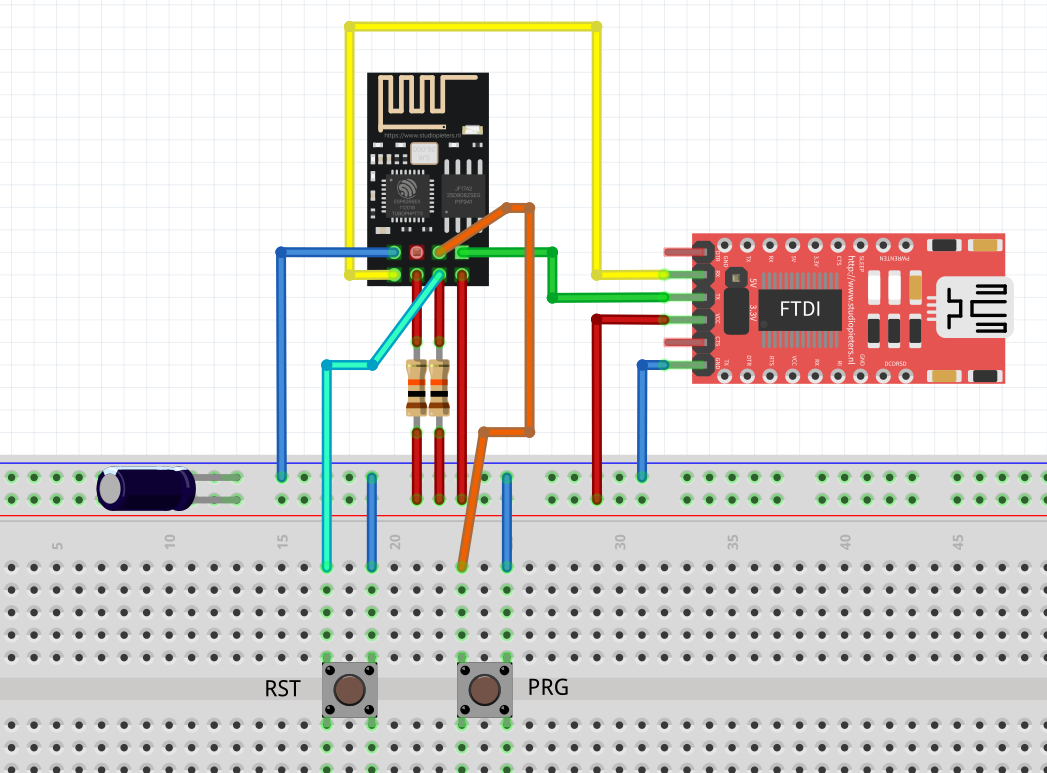
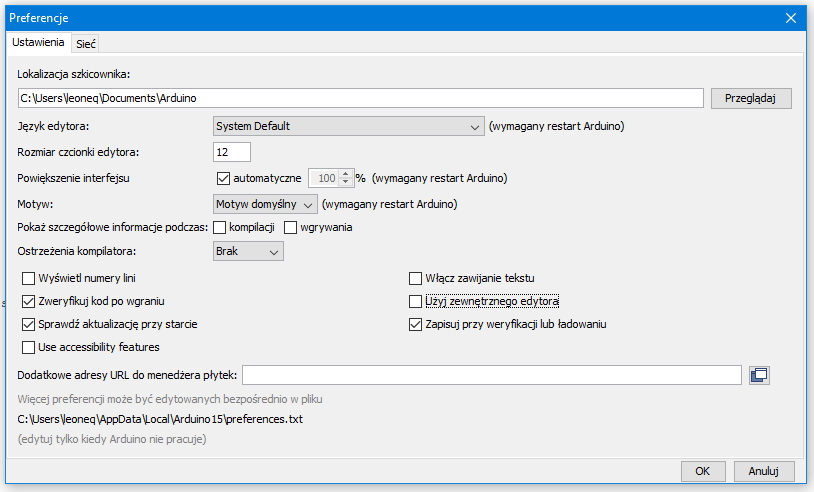
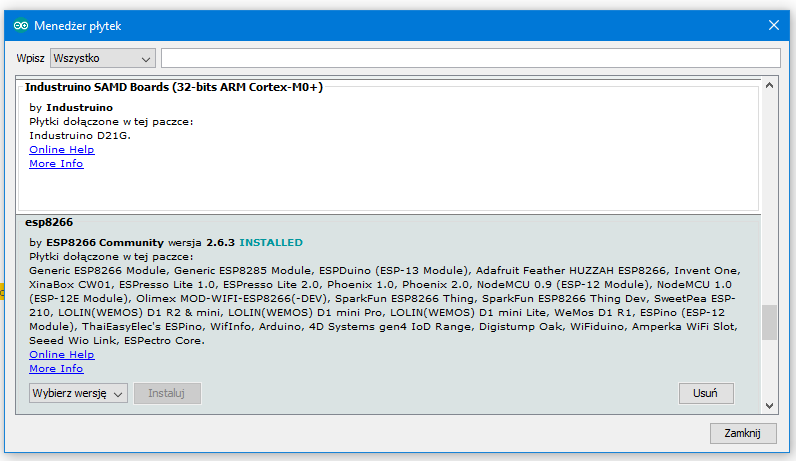
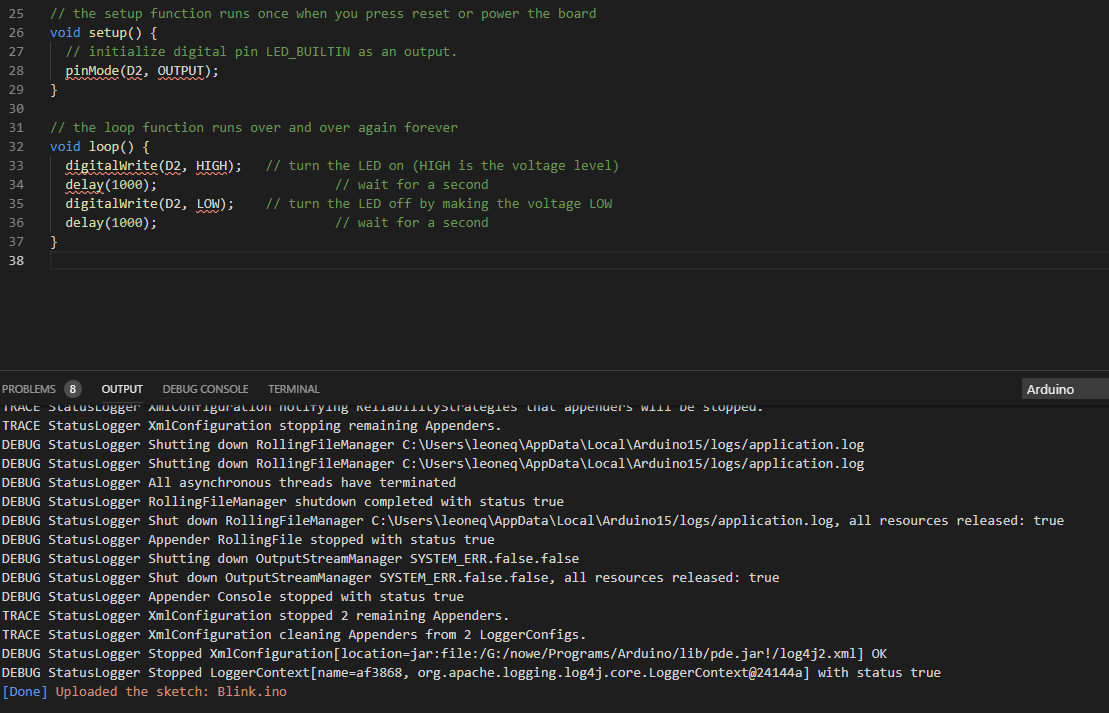
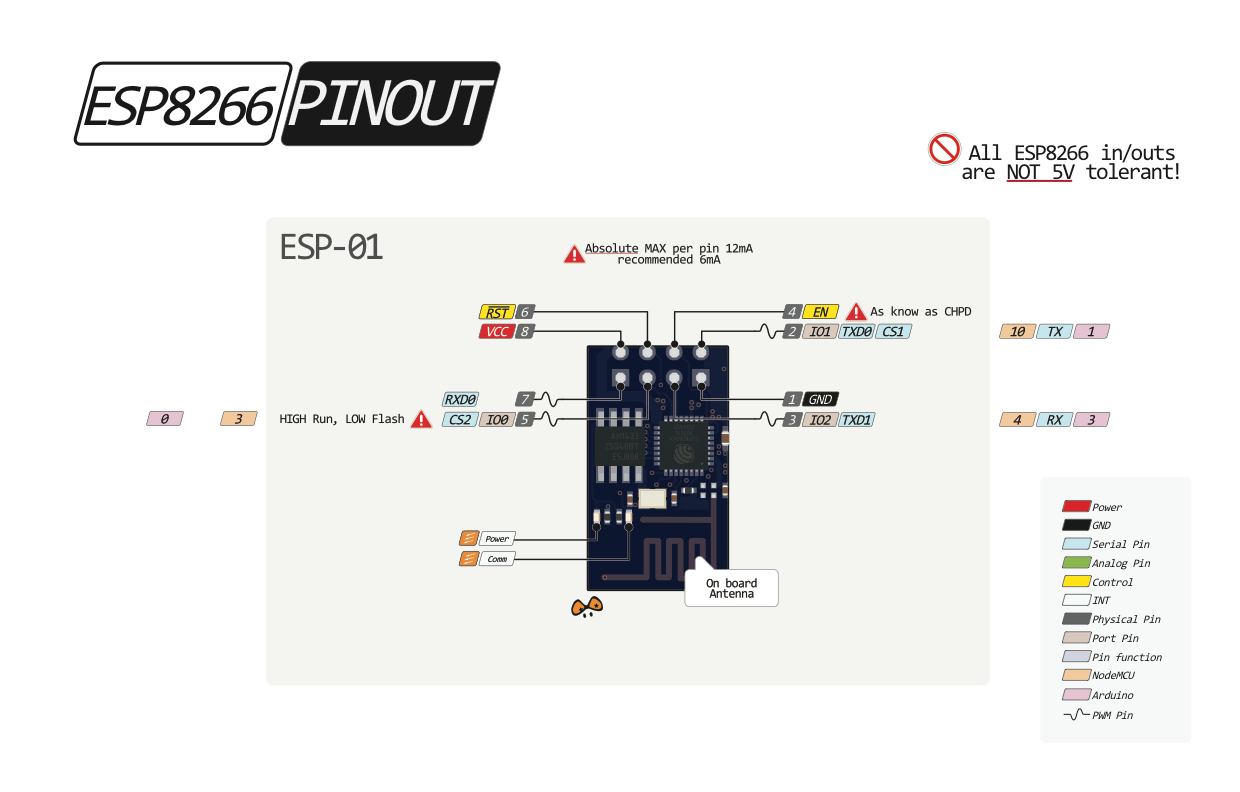
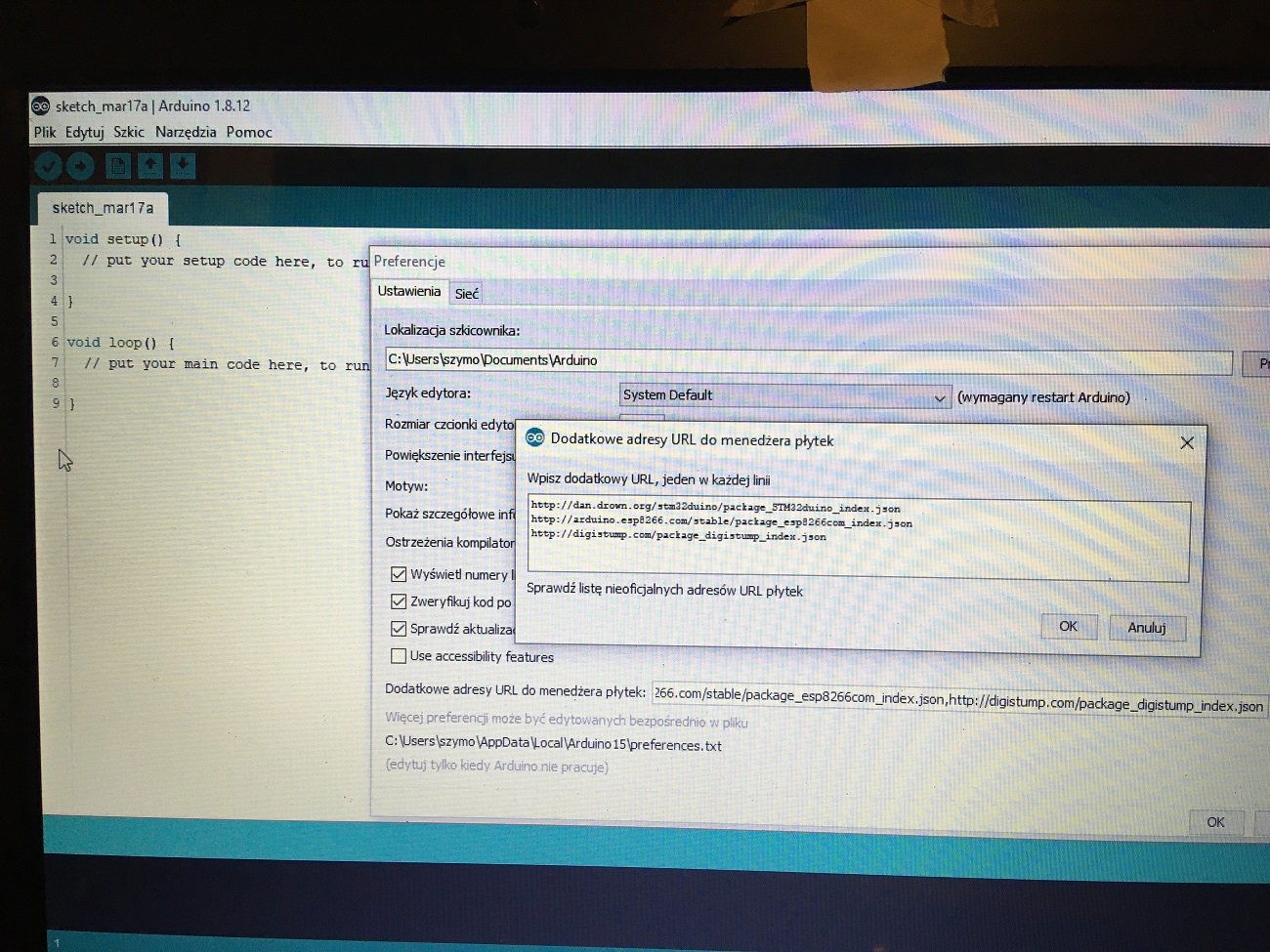
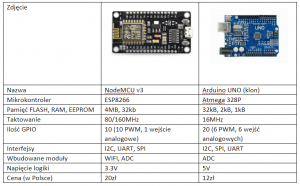
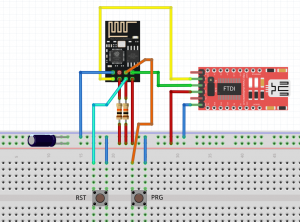
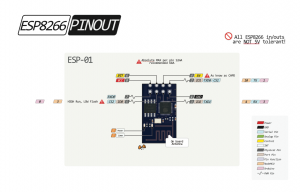
Po kursie Arduino chcesz nauczyć się czegoś jeszcze? Albo chcesz zrobić inteligenty dom? A może Arduino po prostu ci nie wystarcza - na to wszystko jest rozwiązanie! ESP8266 to wydajny i tani mikrokontroler. Znajdziemy go na wielu płytkach, od małego 01 na NodeMCU kończąc. Dzisiaj zobaczymy jakie są rodzaje płytek, co w sobie ukrywa kostka mikrokontrolera, oraz spróbujemy przygotować środowisko i wgrać Blinka. Niestety, tak nie robimy - tylko zewrzemy piny. Spis treści serii artykułów: 1. Omówienie, i przygotowanie środowiska 2. Zapoznanie z nowym środowiskiem, praca jako Arduino, prosty serwer WWW 3. Przyspieszony kurs na webmastera 4. Wykresy, zapis do SPIFFS, mini smart-dom 5. Odbiór danych z przeglądarki, stałe IP, łączenie modułów ESP Ten wpis brał udział konkursie na najlepszy artykuł o elektronice lub programowaniu. Sprawdź wyniki oraz listę wszystkich prac » Partnerem tej edycji konkursu (marzec 2020) był popularny producent obwodów drukowanych, firma PCBWay. Możliwości ESP8266 Uznałem, że najlepiej będzie zestawić NodeMCU v3 z Arduino UNO. Najważniejsze informacje podałem w tabeli. Pamiętamy, że ESP pracuje na napięciu 3.3v. Kiedy podłączałem do 5V (nie róbcie tego w domu) się tylko grzał, ale lepiej tego nie róbcie. ESP ma także pamięć FLASH w oddzielnej kostce - co pozwala na dużą jej pojemność (zależy to od wersji modułu). Co więcej, interfejsy możemy zdefiniować na (prawie) każdym pinie. ESP pracuje o wiele szybciej od Arduino - bo aż na 80MHz (z możliwością do 160!), i przede wszystkim ESP jest 32 bitowe. No, i ESP się lekko grzeje, ale to nic złego. Warianty ESP8266 Ten mały mikrokontroler możemy znaleźć na równie małych płytkach, lub znacznie większych i rozbudowanych modułach. Jednym z mniejszych, samodzielnych modułów jest ESP12. Posiada wiele wyprowadzeń, lecz nie jest (nawet z przejściówką) zbyt przyjazny dla płytki stykowej. Posiada natomiast aż 4MB pamięci FLASH (wersja ESP12F). Będzie to optymalny wybór dla rozwiązań wbudowanych (np. własnych płytek). ESP12 Jeżeli natomiast szukamy czegoś równie małego, ale bardziej przyjaznego dla nas, tutaj nadchodzi ESP01. Ten mały modulik ma niestety mniej pamięci (niebieska wersja 512kB, czarna 1MB), oraz tylko 8 wyprowadzonych pinów - lecz do konkretnego zastosowania, np. gniazdka z przekaźnikiem, wystarczy. ESP01 (niebieski) ESP03 i ESP07 to uboższe wersje ESP12, ale posiadają ceramiczną antenę - a ESP07 nawet złącze do zewnętrznej anteny. ESP07 Pozostałe moduły rzadko się spotyka, różnią się jedynie ilością wyprowadzeń, rozmiarem, i sposobem montażu. Przygotowanie ESP do programowania W zależności od tego, jaki moduł wybrałeś, będziesz musiał albo przylutować przewody do jego wyprowadzeń, lub podłączyć się przewodami do płytki stykowej. Dlatego na początek nauki, najlepiej zakupić NodeMCU (płytkę deweloperską z ESP12 na pokładzie), Wemos (troszkę mniejsze płytki z ESP12) - mają wszystko wbudowane. Jeżeli taką płytkę wybrałeś, możesz pominąć ten krok. Mając "surowe" ESP12 lub 01, musisz je odpowiednio podłączyć. Połączenie ESP01 z konwerterem USB ↔ UART. Rozpiska pinów dla ESP01. Do tego będziemy potrzebować dwóch przycisków tact switch, kondensatora elektrolitycznego (z zakresu 100-1000µF), dwóch rezystorów 10kΩ, przewodów, oraz oczywiście ESP i konwertera. Pokazałem to na przykładzie ESP01, ale każdy ESP też ma takie wyprowadzenia: pin CH_PD łączymy na stałe do napięcia zasilania przez rezystor 10kΩ pin RST podciągamy do VCC rezystorem 10kΩ, oraz podpinamy przycisk zwierający do masy pin GPIO0 podpinamy do przycisku zwierającego z masą między VCC a GND dajemy kondensator pin RX konwertera łączymy z pinem TX ESP, a pin TX konwertera z pinem RX ESP piny VCC i GND ESP łączymy z pinami VCC i GND konwertera napięcie na konwerterze ustawiamy na 3.3V! Na NodeMCU także znajdziemy dwa przyciski. Przycisk RST odpowiada ze reset mikrokontrolera - tak samo jak w Arduino. Ale co robi przycisk PRG? Otóż, jeżeli na pin GPIO0 podamy logiczne 0 podczas startu mikrokontrolera, wprowadzimy go w tryb programowania. Dzięki temu będziemy mogli wgrać do niego nasz kod. Jeżeli nie mamy zainstalowanych sterowników dla konwertera (np. CH340), powinniśmy je pobrać i zainstalować. Przygotowanie środowiska ESP możemy programować na dwa sposoby, w języku lua - oraz klasycznie, jak arduino, w c++. Opiszę wam sposób jak programować ESP jako Arduino - a do tego potrzebne będzie Arduino IDE. Jeżeli jeszcze takowego nie mamy, pobieramy najnowszą wersję stąd, po czym instalujemy. Dokładny proces instalacji został opisany na kursie Arduino - jeżeli mamy już zainstalowane środowisko, uruchamiamy je, a następnie przechodzimy do zakładki Plik → Preferencje. Powinno nam się otworzyć nowe okno. Szukamy okienka "Dodatkowe adresy URL do menedżera płytek", i wklejamy ten adres: https://arduino.esp8266.com/stable/package_esp8266com_index.json Całość powinna teraz wyglądać tak: Klikamy OK - następnie przechodzimy do zakładki Narzędzia → Płytka → Menedżer płytek Szukamy "esp8266", i klikamy Instaluj. Pobrane zostanie ok. 100MB danych. Od teraz możemy wybrać płytkę ESP jak zwykłą płytkę Arduino. ALE! Jeżeli już kiedyś programowałeś, w innym IDE, zapewne wiesz, że Arduino IDE jest troszkę przestarzałe. Brak autouzupełniania, podpowiedzi, rozbudowanego systemu plików, GIT, i innych funkcji. Jest na to sposób! Dlatego w tym poradniku także opiszę instalację i konfigurację Microsoft Visual Studio Code do pracy z Arduino. Dzięki temu będzie o wiele prościej i wygodniej pisać programy. Pobieramy zatem najnowsze VS Studio Code z tej strony. Jak widać jest ono dostępne na Windowsa, Linuxa, i MacOS. Po pobraniu i zainstalowaniu, powinniśmy zobaczyć taki widok: Jeżeli ciemny motyw nam nie odpowiada, możemy to zmienić naciskając koło zębate (lewy, dolny róg) i "Color Theme" - jasny motyw to Light+. Problemem dla niektórych może być język angielski - lecz w informatyce jest on niezbędny do funkcjonowania. Nie ma problemu aby wrócić do spolszczonego Arduino IDE. Jeżeli jednak chcesz zostać przy VS Code, musimy zainstalować rozszerzenie Platform.io. Dokładniej masz to opisane w tym forbotowym artykule. Po zainstalowaniu Platformio, klikamy magiczny przycisk F1 (musimy go zapamiętać!), i ukazuje nam się to okno: Znajdziemy tam wszystkie funkcje znane z Arduino IDE! Teraz możemy podpiąć nasz konwerter lub NodeMCU do komputera. Tworzymy nowy projekt, i szukamy po lewej pliku platformio.ini. Tam możemy wybrać inną płytkę niż ta, którą wybraliśmy podczas tworzenia projektu. Możemy także ustalić inne rzeczy - więcej w dokumentacji. Otwieramy podfolder src, i szukamy pliku main.cpp. Otworzyło nam się nowe okno - pierwsze co widzimy, to biblioteka Arduino. Dołączy ona wszystkie funkcje z starego IDE. Wklejamy poniższy kod. Największą różnicą ESP w stosunku do Arduino, jest tutaj zapalenie poprzez ustawienie LOW na pinie. #include <Arduino.h> void setup() { pinMode(LED_BUILTIN, OUTPUT); //pin drugi jako wyjście } void loop() { digitalWrite(LED_BUILTIN, LOW); //zapalamy diodę delay(1000); //czekamy sekundę digitalWrite(LED_BUILTIN, HIGH); //gasimy diodę delay(1000); //czekamy sekundę } Teraz przyszedł moment na wgranie szkicu. Klikamy przycisk PRG (gdzieniegdzie opisywany jako FLASH), trzymamy, a następnie RESET, i puszczamy. Dioda powinna raz mrugnąć - oznacza to, że ESP jest gotowe do zaprogramowania. Klikamy zatem znowu F1, a następnie "Platformio: Upload". Cierpliwie czekamy, aż program się wgra. Kiedy zobaczymy ten komunikat: Przyciskamy przycisk reset na naszej płytce - i dioda powinna zacząć mrugać. Na dole, po lewej, na niebieskim pasku są także małe ikonki pozwalające wgrać szkic. Gratulacje, udało Ci się zaprogramować ESP! Możesz je teraz wykorzystać jako moduł Wifi, samodzielne urządzenie, zastosowań jest tyle ile dla Arduino, a nawet i więcej. Udało Ci się także skonfigurować poprawnie VS Code do pracy z płytkami Arduino (i nie tylko!). W następnym odcinku zobaczymy co tak naprawdę oferuje przesiadka na VS Code, oraz spróbujemy połączyć się przez Wifi. Liźniemy nawet trochę HTMLa z CSSem, aby postawić stronę WWW! W przypadku jakichkolwiek problemów, nie bójcie się pisać komentarzy. Spis treści serii artykułów: 1. Omówienie, i przygotowanie środowiska 2. Zapoznanie z nowym środowiskiem, praca jako Arduino, prosty serwer WWW 3. Przyspieszony kurs na webmastera 4. Wykresy, zapis do SPIFFS, mini smart-dom 5. Odbiór danych z przeglądarki, stałe IP, łączenie modułów ESP




- 36 odpowiedzi
-
- 14
-

-

-
- konkurs2020
- esp
- (i 2 więcej)
-
statnio zrobiliśmy sobie smartdom z kilkoma czujnikami i obsługą przez przeglądarkę. Dzisiaj zajmiemy się bardziej frontendem, aby strona była bardziej przyjazna użytkownikom, oraz dodamy małego szpiega, który będzie nam przekazywał temperaturę do dużego ESP. Spis treści serii artykułów: 1. Omówienie, i przygotowanie środowiska 2. Zapoznanie z nowym środowiskiem, praca jako Arduino, prosty serwer WWW 3. Przyspieszony kurs na webmastera 4. Wykresy, zapis do SPIFFS, mini smart-dom 5. Odbiór danych z przeglądarki, stałe IP, łączenie modułów ESP Ten wpis brał udział konkursie na najlepszy artykuł o elektronice lub programowaniu. Sprawdź wyniki oraz listę wszystkich prac » Partnerem tej edycji konkursu (marzec 2020) był popularny producent obwodów drukowanych, firma PCBWay. Przekazywanie danych do ESP Teraz zadanie mamy takie, żeby stworzyć pole tekstowe i koło do wyboru kolorów. Tekst z textboxa wyświetlimy na LCD, a na wybrany kolor zaświecimy WS2812. Zacznijmy od tego prostszego, czyli tzw. textboxa (text field, pole tekstowe). W HTMLu mamy na to gotowy znacznik: <input type="textbox" value="koronaferie 2020" id="text"></input> Znacznik <input> to wejście ze strony użytkownika. Możemy także mieć wejście typu checkbox, radius, itd. Textbox to nasze pole tekstowe, a "value" to domyślny tekst naszego textboxa. No dobra, to było dość proste. Dane będziemy wysyłać do ESP dzięki metodzie get. Polega ona na wysyłaniu argumentów przy wywołaniu podstrony - u nas /set. Najlepiej będzie zrobić zmienną z całą stroną, i dopiero potem ją wysłać: var set = '/set?' + 'txt=' + $('#text').val(); $.post(set); Po wpisaniu "ip/set" dajemy znak zapytania - czyli wysyłamy już argumenty. Argumenty wysyłamy w formie "nazwa=dane". Tutaj będzie to "txt=", a dane to odczytanie wartości z textboxa o id #text. Kolejne argumenty zaraz dodamy - będziemy je oddzielać znakiem "&". Po przygotowaniu zmiennej wysyłamy żądanie. Najlepiej to umieścić w setInterval. Zostało nam zrobić kolejną podstronę. server.on("/set", setParams); void setParams() { String text = server.arg("txt"); lcd.print(text); server.send(200, "text/html", ""); //Send web page } Tworzymy zmienną "text" w której przechowujemy argument dla "txt". Wysyłamy jak zwykle kod 200, strony nie trzeba wysyłać - więc pozostawiamy pustą stronę. Spróbuj teraz załadować kod, i zmienić tekst w textboxie. Powinien się zmieniać także na wyświetlaczu, z niewielkim opóźnieniem. Czas na odrobinę magii Dodanie kolejnych argumentów nie będzie problemem. Dlatego to sobie zostawimy na później, a teraz zajmiemy się problemem "skąd wziąć argumenty". Dodamy sobie plugin "Spectrum" - dzięki niemu, będziemy mogli w łatwy i przyjemny sposób wybrać kolor naszych ledów. Szczegóły znajdziecie tutaj. Dodajemy zatem plik css na górze i js na dole strony: <link rel="stylesheet" type="text/css" href="https://cdn.jsdelivr.net/npm/[email protected]/dist/spectrum.min.css"> <script src="https://cdn.jsdelivr.net/npm/[email protected]/dist/spectrum.min.js"></script> W lewej kolumnie dodajemy tekst "LED:" oraz znacznik input - tam będziemy wprowadzać kolory. Argument "value" to początkowy kolor - podany heksadecymalnie. <p>LED: <input id="kolorki" value='#276cb8'/></p> W kodowaniu na razie tyle co nic. Dodajemy jedynie informację (w document.ready, nie w setInterval), jaki ma być typ naszego wybieracza kolorów. $('#kolorki').spectrum({ type: "color" }); Po otworzeniu i wgraniu strony, ujrzymy takie cudo: Ale to dopiero połowa magii! Druga połowa będzie fizyczna. Wyjście naszego pola z kolorkami to tekst, dosłownie: rgba(r,g,b,a) Dlatego musimy sobie zrobić funkcję, która nam to rozbije na poszczególne komponenty. Kanał alpha będzie sterował jasnością WS. function spliceRGB(input) { var color = input.slice(input.indexOf('(') + 1, input.indexOf(')')); // "r, g, b, a" var colors = color.split(','); return { r: colors[0], g: colors[1], b: colors[2], a: colors[3] } } Jest to dość prosta funkcja. Na początku usuwamy "rgba(" oraz ")", potem rozbijamy tekst na kawałki oddzielone ",". Zwracamy 4 wartości: r, g, b i a. var r = spliceRGB($("#kolorki").val()).r; var g = spliceRGB($("#kolorki").val()).g; var b = spliceRGB($("#kolorki").val()).b; var i = (spliceRGB($("#kolorki").val()).a * 255); Tak będą wyglądały zmienne, które przekażemy ESP. Do funkcji podajemy wartość którą wybraliśmy, i dajemy zmiennej tylko dany kolor. Z racji tego, że kanał alpha ma wartości od 0 do 1, mnożymy go x255 aby uzyskać liczbę przyjazną ESP. var set = '/set?txt=' + txt + '&r=' + r + '&g=' + g + '&b=' + b + '&i=' + i; $.post(set); Tworzymy dość długą zmienną, która po kolei zawiera wszystkie te wartości. Na końcu najzwyczajniej je wysyłamy. Jako zadanie dodatkowe spróbuj zrobić przycisk do włączania i wyłączania wbudowanego LEDa, ale już nie przez podstrony a get. void setParams() { int r = server.arg("r").toInt(); int g = server.arg("g").toInt(); int b = server.arg("b").toInt(); int i = server.arg("i").toInt(); String text = server.arg("txt"); cls(); lcd.print(text); for(int index=0; index<3; index++) { leds.setPixelColor(index, r, g, b); leds.setBrightness(i); leds.show(); } server.send(200, "text/html", ""); } Tak wygląda cała funkcja odczytująca dane. Odzyskujemy wartości kolorów, oraz tekst. Piszemy tekst na wyświetlaczu, po czym dla każdej diody ustawiamy wybrane kolory i jasność. Na końcu informujemy, że wszystko poszło sprawnie. Spróbuj teraz to wszystko odpalić na telefonie, i wygodnie z łóżka pobawić się LEDami - bardzo fajna zabawa, polecam :3 Suwak alpha nie dajemy na max. wartość - inaczej wyjście dostaniemy w postaci heksadecymalnej, z której nie wyciągniemy kolorów tak łatwo. Ustaw alpha na mniejszą od 1! ESP01 Na początku napisałem, że układy ESP01 są fajne dla dedykowanych rozwiązań. Zrobimy sobie w takim razie małego ESP odczytującego temperaturę z drugiego pokoju, przekazujące dane do "dużego" ESP. W związku z tym, "usuwamy" wykres z DS: void handleData() { //ds.requestTemperatures(); //String strona = (String)ds.getTempCByIndex(0); String strona = "0"; strona += "\n"; strona += analogRead(PIN_FRES); Temperatura 1 z "wyłączonym" DS18B20. Żeby zaprogramować teraz małe ESP, proponuję zrobić sobie do tego programator ze schematu. Tak wygląda mój: Dzięki niemu nie trzeba kombinować z kablami - wystarczy wsadzić ESP i wrzucić program. Jeżeli mowa o programie, warto sobie powiedzieć znowu, co chcemy napisać. Najlepiej będzie, jeżeli małe ESP w ten sam sposób co przeglądarka, wyśle nam temperaturę. Robimy nowy projekcik: Otwieramy plik main.cpp. Zacznijmy od dołączenia podstawowych bibliotek: #include <Arduino.h> #include <OneWire.h> #include <DallasTemperature.h> #include <ESP8266WiFi.h> #include <ESP8266WebServer.h> Z racji tego, że poprzedni projekt był konwertowany z projektu Arduino, biblioteki tym razem zainstalowałem przez platformio: Następnie definiujemy piny. Przyjmijmy, że zrobimy kilka małych ESP i wsadzimy je do gniazdek - każde będzie miało czujnik i przekaźnik (tutaj LED). #define PIN_LED 2 #define PIN_DS 0 Następnie tworzymy obiekty: klienta, DS, serwera. Stworzyliśmy także 4 adresy: IP, bramy, maski, i DNS. Dzięki nich będziemy mogli ustawić stałe IP naszemu ESP - w przeciwnym razie, jeżeli się zmieni, będziemy musieli zmieniać program i przepisywać wszystko. Pierwszy adres ustalamy sami - najlepiej zmienić po prostu ostatnią liczbę. DNSy zostawiamy, ponieważ z nich nie korzystamy - ale bramę i maskę możemy uzyskać z konsoli windowsowej CMD: Default gateway to nasza brama, którą przepisujemy. Podobnie z maską - prawdopodobnie będziesz miał taką samą. WiFiClient client; OneWire ow(PIN_DS); DallasTemperature ds(&ow); ESP8266WebServer server(80); IPAddress staleIP(192, 168, 43, 90); IPAddress gateway(192, 168, 43, 1); IPAddress subnet(255, 255, 255, 0); IPAddress dns(8, 8, 8, 8); Pamiętajmy o SSID i haśle naszego wifi - podaj tam wartości Twojego Wifi. const char* ssid = ""; //nazwa const char* pass = ""; //hasło Teraz zrobimy funkcję setup. Nic tajemniczego chyba tu nie ma - IP będzie takie, jakie ustawiliśmy. Obsługujemy potem dwie strony: główną i /set. void setup() { pinMode(PIN_LED, OUTPUT); Serial.begin(115200); Serial.print("Lacze z wifi"); ds.begin(); WiFi.begin(ssid, pass); WiFi.config(staticIP, gateway, subnet, dns); while(WiFi.status() != WL_CONNECTED) { Serial.print('.'); delay(400); } delay(500); Serial.println("Polaczono! IP:"); Serial.println(client.localIP()); server.on("/set", setParam); server.on("/", mainPage); server.begin(); } W loopie nic nie musimy robić poza obsługą serwera. void loop() { server.handleClient(); } Na stronie głównej będziemy wysyłać dane w tej samej formie co "duże" ESP. Dzięki temu bez problemu będziemy mogli pobrać temperaturę. Dodaliśmy także nagłówek "Access control allow origin", który pozwoli nam na łączenie się dużemu ESP. void mainPage() { ds.requestTemperatures(); server.sendHeader("Access-Control-Allow-Origin", "*"); server.send(200, "text/html", (String)ds.getTempCByIndex(0)); } Z kolei funkcja obsługująca LEDa zawiera prostego ifa - jeżeli wysłaliśmy "led=on" to włączy, "led=off" to wyłączy, a cokolwiek innego ominie. void setParam() { String led = server.arg("led"); if(led == "on") digitalWrite(PIN_LED, LOW); if(led == "off") digitalWrite(PIN_LED, HIGH); server.sendHeader("Access-Control-Allow-Origin", "*"); server.send(200, "text/html", ""); } Cały kod zatem będzie wyglądał tak: #include <Arduino.h> #include <OneWire.h> #include <DallasTemperature.h> #include <ESP8266WiFi.h> #include <ESP8266WebServer.h> #define PIN_LED 2 #define PIN_DS 0 WiFiClient client; OneWire ow(PIN_DS); DallasTemperature ds(&ow); ESP8266WebServer server(80); IPAddress staleIP(192, 168, 43, 90); IPAddress gateway(192, 168, 43, 1); IPAddress subnet(255, 255, 255, 0); IPAddress dns(8, 8, 8, 8); const char* ssid = "dobre pomaranczowe"; //nazwa const char* pass = "smerfysmerfy"; //hasło void setParam() { String led = server.arg("led"); if(led == "on") digitalWrite(PIN_LED, LOW); if(led == "off") digitalWrite(PIN_LED, HIGH); server.sendHeader("Access-Control-Allow-Origin", "*"); server.send(200, "text/html", ""); } void mainPage() { ds.requestTemperatures(); server.sendHeader("Access-Control-Allow-Origin", "*"); server.send(200, "text/html", (String)ds.getTempCByIndex(0)); } void setup() { pinMode(PIN_LED, OUTPUT); Serial.begin(115200); Serial.print("Lacze z wifi"); ds.begin(); WiFi.begin(ssid, pass); while(WiFi.status() != WL_CONNECTED) { Serial.print('.'); delay(400); } delay(500); Serial.println("Polaczono! IP:"); Serial.println(client.localIP()); server.on("/set", setParam); server.on("/", mainPage); server.begin(); } void loop() { server.handleClient(); } Wgrywamy kod do "małego" esp, podłączamy wszystko, i uruchamiamy Serial Monitor. Niestety, moje ESP się zbuntowało: Na to wystarczy pobrać "Advanced IP Scanner", który był wspomniany w malinkowym kursie. Uzyskany adres IP wpisujemy w przeglądarkę: No, to teraz małe ESP ukrywamy w innym pokoju. Pamiętajmy jedynie, żeby dalej miało zasięg naszego routera. Przechodzimy do kodu dużego ESP: var temp = new XMLHttpRequest(); temp.onreadystatechange = function() { if (this.readyState == 4 && this.status == 200) { var temperatura = this.responseText; document.getElementById('temp1').innerHTML = temperatura; addData(wykres, temperatura, 0); } }; temp.open("GET", "http://192.168.43.75", true); temp.send(); Obok całego kodu dla "strony" dodajemy praktycznie taki sam kod dla "temp". Pamiętaj, żeby w "temp.open()" wpisać IP małego ESP. Zostało nam z "dużej" funkcji usunąć stary kod (tutaj macie całą funkcję): if (this.readyState == 4 && this.status == 200) { var zawartosc = this.responseText; var dane = zawartosc.split("\n"); var temp1 = dane[0]; var fres = dane[1] / 4; var temp2 = dane[2]; var cis = dane[3] / 100; var odl = dane[4]; var btn = dane[5]; var color = 'rgba('+fres +','+(fres - 20)+','+(fres - 20)+','+'1)'; var r = spliceRGB($("#kolorki").val()).r; var g = spliceRGB($("#kolorki").val()).g; var b = spliceRGB($("#kolorki").val()).b; var i = (spliceRGB($("#kolorki").val()).a * 255); var txt = $('#text').val(); var set = '/set?txt=' + txt + '&r=' + r + '&g=' + g + '&b=' + b + '&i=' + i; document.getElementById('temp1').innerHTML = temp1; document.getElementById('temp2').innerHTML = temp2; document.getElementById('light').style.color = color; document.getElementById('cis').innerHTML = cis; document.getElementById('odl').innerHTML = odl; $.post(set); if(!btn) document.getElementById('drzwi').innerHTML = 'otwarte'; else document.getElementById('drzwi').innerHTML = 'zamknięte'; addLabel(wykres, etykieta); addData(wykres, temp2, 1); popData(wykres, 0); } }; Wgrywamy kod. Uruchamiamy oba ESP, patrzymy czy IP się nie zmieniło (jeżeli jednak nie dałeś stałego IP), i wszystko powinno działać. Jeżeli chodzi o kurs ESP - to chyba tyle. Myślę, że dzięki temu kursowi teraz będziesz mógł postawić swój własny smartdom (lub jakiekolwiek inne urządzenie IoT). Nauczyliśmy się stawiać dynamiczne i responsywne strony WWW, odczytywać i zapisywać dane zarówno przez przeglądarkę, i FS, i ogólnie udało nam się z ESP zrobić "arduino". Możemy nawet zrobić całą sieć ESP01, gdzie każde ESP może sterować chociażby przekaźnikiem - i komunikować się do dużego ESP, lub malinki. Tak wygląda mój setup: W razie jakichkolwiek pytań - śmiało pisz na dole. Zostawiam Ci jeszcze zipa z projektami do platformio, i bibliotekami - w razie gdybyś miał problemy z posklejaniem kodów w całość. Pamiętajcie - bądźcie kreatywni, i pochwalcie się poniżej swoimi projektami! kurs esp.zip Spis treści serii artykułów: 1. Omówienie, i przygotowanie środowiska 2. Zapoznanie z nowym środowiskiem, praca jako Arduino, prosty serwer WWW 3. Przyspieszony kurs na webmastera 4. Wykresy, zapis do SPIFFS, mini smart-dom 5. Odbiór danych z przeglądarki, stałe IP, łączenie modułów ESP
















-
System kontroli wersji to niezbędnik dla każdego programisty. Kopia plików, wracanie do stanu sprzed kilku dni i łatwe porównywanie różnych wersji kodu to tylko część zalet pracy z Gitem. Jednak czy ma to sens, jeśli projekt prowadzimy samodzielnie? Odpowiedź wraz z praktycznymi przykładami znajduje się w tym poradniku. [blog]https://forbot.pl/blog/git-dla-samotnych-czy-to-ma-sens-jak-zaczac-id41521[/blog]
-
Stali czytelnicy forbot.pl z pewnością wiedzą już czym jest oraz do czego przysłużyć może się framework Qt do C++. Jednym z nieodłącznych elementów tego frameworka jest moduł Qt Quick oparty na języku Qml. Pozwala on na budowanie multi-platformowych aplikacji w bardzo prosty i szybki sposób, a sam język jest bardzo naturalny. Ale co, jeżeli powiem Ci, że można pisać aplikacje w Qml jeszcze szybciej i jeszcze prościej? Przekonajmy się wspólnie czym jest Felgo SDK. Ten wpis brał udział konkursie na najlepszy artykuł o elektronice lub programowaniu. Sprawdź wyniki oraz listę wszystkich prac » Partnerem tej edycji konkursu (marzec 2020) był popularny producent obwodów drukowanych, firma PCBWay. Czym jest Felgo SDK? Felgo SDK rozszerza możliwości samego frameworka Qt dostarczając dodatkowe komponenty, których użycie ułatwia i przyspiesza programowanie z wykorzystaniem Qml przy czym projektami, na których SDK skupia się najbardziej są aplikacje oraz gry na platformy mobilne. Oczywiście nie oznacza to, że tych komponentów nie można zastosować w innych projektach opartych na Qml. Felgo świetnie sprawdza się w przypadku tworzenia oprogramowania desktopowego. Z uwagi na ogólną tendencję panującą w środowisku Qt, Felgo dostosowuje się do nowej rzeczywistości udostępniając swój silnik również dla tych, którzy chcą tworzyć efektywny interfejs użytkownika dla systemów wbudowanych. Kontynuując kwestię docelowych platform nie możemy pominąć kwestii przeglądarek i wykorzystania Qt for WebAssembly. Zgadza się, nie pomyliliśmy się tworząc ten artykuł. Już teraz możesz tworzyć aplikacje webowe z wykorzystaniem Qt! Co prawda projekt ten w dalszym ciągu nie działa do końca stabilnie, ale mam nadzieję, że wraz z Qt w wersji 6 wiele bolączek zostanie rozwiązanych. Niemniej wiele z tych problemów (np. z mechanizmem CORS przy wysyłaniu zapytań) zostanie rozwiązanych wraz z kolejną wersją Felgo, która powinna się pojawić w nadchodzących miesiącach. Oto lista platform, na które trafić może twoja aplikacja oparta na Felgo: Systemy wbudowane; Windows; Linux; macOS; Android; iOS; Web*; * Wsparcie dla projektów WebAssembly w Felgo powinno pojawić się w nadchodzących miesiącach. Korzyści programowania z Felgo Mamy już zarys tego czym jest Felgo i jakie projekty możemy w oparciu o to SDK rozwijać, ale pozostaje nam przyjrzeć się bliżej temu jakie konkretnie profity nam ono przyniesie. Felgo dla aplikacji mobilnych Jedną z głównych gałęzi Felgo jest wsparcie dla programistów tworzących rozwiązania w Qml na platformy mobilne. SDK dodaje do listy dostępnych w Qml typów własne komponenty, które albo rozszerzają możliwości tych już obecnych typów, albo dodają zupełnie nowe funkcjonalności. Spójrzmy na przykład na ten fragment kodu: import Felgo 3.0 import QtQuick 2.0 App { id: app NavigationStack { Page { title: "Forbot.pl" Column { anchors.centerIn: parent width: parent.width * 0.7 spacing: 40 AppTextField { width: parent.width inputMode: inputModeUsername } AppTextField { width: parent.width inputMode: inputModePassword } } } } } Efektem uruchomienia tego kodu będzie proste UI zawierające natywnie wyglądającą stronę z dwoma polami do wprowadzania tekstu. Typ AppTextField znacząco rozszerza dostępny w Qt Quick Controls typ TextField. Z jego wykorzystaniem możemy dodać kilka wizualnych detali bez konieczności tworzenia własnych, dodatkowych typów. Za tym z kolei idzie oszczędność przy pracy nad UI. Dodatkowo typ AppTextField posiada właściwość inputMode, której wartość wykorzystywana jest do automatycznego zmienienia zachowania pola. Na przykład wartość inputModePassword, zmieni maskowanie wprowadzonego tekstu i doda przycisk do zmiany tego maskowania. Z kolei wartości inputModeEmail i inputModeUrl mogą zostać wykorzystane, jeżeli chcemy walidować dane z wykorzystaniem właściwości acceptableInput. Tak prezentuje się aplikacja stworzona z wykorzystaniem powyższego kodu: Oczywiście wymieniony typ to tylko jeden z wielu udostępnionych komponentów. Pełną ich listę znajdziecie w dokumentacji. Natywna nawigacja Aplikacje dedykowane na iOS’a zwykły umożliwiać użytkownikowi nawigację po aplikacji z wykorzystaniem gestu przewijania w tył. Na Androidzie z kolei, aby wrócić do poprzedniej strony musisz kliknąć przycisk back. Na iOS menu wyświetlane jest u dołu ekranu, a na Androidzie z reguły dostępne jest po naciśnięciu na ikonę hamburgera. Co by nie mówić są różnice w implementacji nawigacji w aplikacjach mobilnych na różnych platformach i nie da się tego ukryć. Jeżeli chcielibyśmy zachować dedykowane danej platformie podejście musielibyśmy napisać dwa oddzielne i duże komponenty po jednym dla każdego z systemów. Felgo dostarcza własne typy ułatwiające implementację nawigacji. import Felgo 3.0 import QtQuick 2.0 App { Navigation { NavigationItem { title: "Panel" icon: IconType.listul NavigationStack { Page { id: page title: "Panel" AppText { anchors.centerIn: parent text: "Forbot.pl" } } } } NavigationItem { title: "Ustawienia" icon: IconType.suno NavigationStack { Page { title: "Ustawienia" } } } } } Spójrzmy na ten fragment kodu. Pozostaje on bez zmian bez względu na platformę. Wydaje mi się, że nie ma potrzeby na ten moment tłumaczyć tej implementacji. Teraz bardziej interesuje nas efekt: Jak sam widzisz na obu platformach zachowany został dedykowany sposób wyświetlania nawigacji. Podejście to co prawda kuleje, jeżeli nasza nawigacja jest bardziej zaawansowana i znacząco różni się wyglądem od tej natywnej, ale w dalszym ciągu Felgo pozwala programiście na zaoszczędzenie wielu godzin spędzonych na programowaniu tego samego. Zatem Felgo w szczególności nada się przy prototypowaniu aplikacji. Pluginy w Felgo SDK Wiele osób stwierdzi, że jest w stanie poradzić sobie bez typów dostarczonych wraz z Felgo. Dla bardziej wymagających dostępne są pluginy umożliwiające logowanie do aplikacji przy wykorzystaniu kont społecznościowych, monetyzację aplikacji, obsługę powiadomień, integrację z FireBase, raportowanie i statystyki. Wszystkie te rzeczy można zrobić oczywiście samemu, ale wyobraź sobie, ile czasu musiałbyś spędzić na implementację każdej z nich. Nie wszystkie pluginy dostępne są w ramach darmowej licencji Felgo. Na całe szczęście pluginy do monetyzacji aplikacji są dostępne w darmowej wersji, więc możesz zarabiać na swojej aplikacji bez konieczności inwestowania dodatkowych środków. Pełna lista pluginów w Felgo SDK. Czy tworzenie aplikacji mobilnych w Felgo ma sens? Wielu programistów zastanawia się nad tym czy warto oprzeć swoje rozwiązanie na danym frameworku. Na temat tego czy tworzenie aplikacji w Felgo na sens można byłoby napisać dużo porównując go do innych popularnych technologii takich jak React Native. Na własnym przykładzie, mogę powiedzieć, że da się stworzyć w pełni funkcjonalną aplikację korzystając właśnie z Felgo. W moim odczuciu prawdziwym Game Changerem jest kwestia oparcia swojej aplikacji na Qml co pozwala na efektywnie rozgraniczenie logiki od frontendu. Z kolei w kontekście tworzenia samego frontend’u, to Qml pozwala na zachowanie dużej elastyczności. Ta elastyczność jest zbawienna w momencie, gdy nasz projekt graficzny jest dość nietypowy. Na poparcie tych słów umieszczam skrina z aplikacji wykonanej w Qml ze wsparciem Felgo. Zatem wiemy już, że korzystając z Felgo jesteśmy w stanie stworzyć ładną aplikację. Za resztę, czyli za między innymi integrację z zewnętrznymi usługami odpowiadają wspomniane już pluginy. Z pewnością wielu nadal brakuje, ale nie ma technologii idealnej. Słowem podsumowania spójrzmy na grafikę porównującą ilość linii kodu potrzebnych do stworzenia aplikacji PropertyCross. Jak widać w tej statystyce Felgo góruje nad rywalami niepodzielnie, ale oczywiście objętość kodu nie jest ostatecznym wskaźnikiem przy takim wyborze. W samej statystyce nie ujęto też popularnego obecnie Flutter’a. Mimo to, liczby widoczne na tej statystyce wskazują na wysoką efektywność w pracy z Felgo. Efektywność w zawodzie programisty to słowo klucz. Pozwala zaoszczędzić czas, który w branży IT jest przecież czymś na kształt waluty. Felgo a Game Development Drugą z podstawowych gałęzi działalności Felgo jest wsparcie rozwoju gier, które z powodzeniem można wydać na każdej z obsługiwanych przez Felgo platform. W przypadku tworzenia gier sytuacja wygląda podobnie co do tworzenia aplikacji mobilnych, czyli Felgo SDK rozszerza listę obiektów dostępnych w Qml. Wśród najbardziej interesujących typów znajdują się te odpowiadające za: Backend gry, czyli między innymi: Dostarczanie darmowej chmury przechowującej dane graczy; Synchronizację pomiędzy urządzeniami; Integrację z Facebook’iem; Multi-platformowe rankingi; Wewnętrzny czat; Komponenty wizualne ułatwiające obsługę ekranów o różnych rozmiarach; Fizykę w grze; Przechwytywanie inputu użytkownika; Podstawową sztuczną inteligencję; Efekty dźwiękowe; Felgo SDK potrafi znacznie uprościć i przyśpieszyć pracę nad grą. Dostarczonych komponentów jest na tyle dużo, że bylibyśmy w stanie utworzyć dziesiątki wpisów poświęconych tylko i wyłącznie wykorzystaniu Felgo w Game Development’cie. Na szczęście możemy zacząć od tutoriali przygotowanych przez twórców SDK. Chciałbym w tym momencie nadmienić, że Felgo jest ciekawą alternatywą dla innych frameworków jak chociażby Unity. Oczywiście nad Felgo pracuje znacznie mniej osób, a sama społeczność jest też nieporównywalnie mniejsza. Niemniej pomoc od twórców można uzyskać niemal natychmiastowo. Ciekawą sprawą jest to, że w Unity nie ma dostępnego żadnego pluginu, który dostarczałby gotowe rozwiązanie chmurowe tak jak ma to miejsce w przypadku Felgo Game Network. Właściwie cały backend gry można postawić na chmurze dostarczonej od twórców. Do danych przechowywanych w chmurze i do statystyk gry mamy dostęp z poziomu internetowego panelu. Qml Live Reload – przeładowanie aplikacji w locie Postanowiłem, że tą funkcjonalność zostawię na koniec jako wisienkę na torcie. Felgo udostępnia narzędzie, które pozwala na automatyczne przeładowanie front-end’u aplikacji bez konieczności czekania na koniec kompilacji i uruchamiania na docelowym urządzeniu. Dzięki temu rozwiązaniu jesteśmy w stanie zaoszczędzić mnóstwo czasu w momencie, gdy pracujemy nad kodem napisanym w Qml. Po prostu za każdym razem, gdy zapisujemy dokonane zmiany to aplikacja przeładowuje się dosłownie w sekundę. Dzięki tej funkcjonalności jesteśmy też w stanie testować aplikację równocześnie na wielu urządzeniach bez względu na system operacyjny, na którym pracują. Nie muszę chyba mówić jak bardzo przyśpiesza to pracę. Możliwość przeładowania aplikacji jest szczególnie przydatna w momencie, gdy zmiany, których dokonujemy w kodzie są kosmetyczne. Qml Hot Reload Na obecną chwilę automatyczne przeładowanie aplikacji działa w ten sposób, że przeładowana aplikacja zaczyna z powrotem od głównego pliku Qml. Twórcy Felgo właśnie ulepszyli tą funkcjonalność i od teraz dokonane zmiany widoczne będą w czasie rzeczywistym. Udoskonalona funkcjonalność dostępna będzie w nadchodzącej aktualizacji Felgo w przeciągu kilku tygodni. Korzystać z niej będzie można również gdy docelową platformą projektu są systemy wbudowane. Na poniższym wideo widać jak wygląda praca z Qml Hot Reload: Podsumowanie Mam nadzieję, że po lekturze tego wpisu doskonale wiecie czym jest Felgo SDK oraz jakie są jego mocne strony. Felgo SDK znacznie przyśpiesza pracę nad projektami rozwijanymi w oparciu o Qml. Nawet jeżeli nie interesują Cię komponenty udostępnione przez twórców to z tego SDK warto korzystać chociażby ze względu na Qml Live Reload. Tym bardziej, że ta funkcjonalność nic nie kosztuje. Serdecznie zapraszam do zadawania pytań na temat Felgo SDK. samples.zip








-
Wyświetlacze stosowane w urządzeniach elektronicznych przeszły ogromną ewolucję. Można ją łatwo prześledzić chociażby na przykładzie telefonów komórkowych. Pierwsze modele miały monochromatyczne, często tekstowe wyświetlacze. W latach 90. ubiegłego wieku popularne były już wyświetlacze graficzne (oraz gra w węża). W kolejnych latach wyświetlacze monochromatyczne zostały prawie zupełnie wyparte przez modele z kolorową, aktywną matrycą, czyli popularne TFT. Spis treści: Sterowanie wyświetlaczem TFT - część 1 - wstęp, podstawowe informacje Sterowanie wyświetlaczem TFT - część 2 - analiza problemu Sterowanie wyświetlaczem TFT - część 3 - testy prędkości na STM32 Sterowanie wyświetlaczem TFT - część 4 - własny program Sterowanie wyświetlaczem TFT - część 5 - optymalizacja programu W przypadku urządzeń wbudowanych, wiele nowości dociera ze znacznym opóźnieniem. Podczas kursu Arduino wykorzystany został alfanumeryczny wyświetlacz 2x16 znaków, kursy STM32 F1 oraz STM32 F4 wykorzystywały graficzne, ale nadal monochromatyczne wyświetlacze (chociaż F4 o wiele nowocześniejszy OLED). Celem niniejszego artykułu jest pokazanie jak można we własnym projekcie wykorzystać kolorowy wyświetlacz TFT. Będzie to okazja do pokazania zarówno wad, jaki i zalet tego typu wyświetlaczy oraz podstawowych technik optymalizacji. Ten wpis brał udział konkursie na najlepszy artykuł o elektronice lub programowaniu. Sprawdź wyniki oraz listę wszystkich prac » Partnerem tej edycji konkursu (marzec 2020) był popularny producent obwodów drukowanych, firma PCBWay. Wybór wyświetlacza Jednym z dość istotnych powodów powolnego wzrostu zainteresowania wyświetlaczami TFT była ich dość wysoka cena (w szczególności w porównaniu ze starszymi modelami monochromatycznymi). Obecnie ceny wyświetlaczy TFT bardzo spadły i model o niewielkiej przekątnej można kupić za podobną cenę do starszych urządzeń. Jako przykład użyję wyświetlacza o przekątnej 1.8 cala i rozdzielczości 160 na 128 pikseli firmy WaveShare. Dokumentację wyświetlacza, użytego sterownika oraz przykładowe programy znajdziemy na stronie producenta: https://www.waveshare.com/wiki/1.8inch_LCD_Module Również z tej strony pochodzi zdjęcie modułu wyświetlacza: Jak widzimy na zdjęciu jest to kompletny moduł. Na stronie producenta znajdziemy zarówno instrukcję obsługi, jak i schemat, jednak jest on tak prosty, że raczej niezbyt interesujący. To na co powinniśmy zwrócić uwagę to opis wyprowadzeń: Kolejny ważny parametr to model kontrolera, czyli ST7735S oraz jego dokumentacja. Wszystkie wspomniane dokumenty warto oczywiście przeczytać. Ale jeśli nie mamy akurat czasu na czytanie nieco ponad 200 stron, powinniśmy chociaż pamiętać gdzie szukać informacji. Podłączenie wyświetlacza Czas wybrać mikrokontroler i podłączyć do niego wyświetlacz. Przykłady dostarczone przez WaveShare są przeznaczone dla Arduino UNO, STM32F103, Raspberry Pi oraz Jetson Nano. Sensowność podłączania tak małego wyświetlacza do potężnego komputera jakim jest Raspberry Pi (o Jetson Nano nawet nie wspominając) jest mocno dyskusyjna więc ograniczę się do Arduino oraz STM32. Na początek Arduino UNO, bo to chyba najlepiej znana wszystkim platforma. Oczywiście wiele osób pewnie stwierdzi, że układ atmega328 jest o wiele za słaby na sterowanie kolorowych wyświetlaczem, ale skoro producent dostarczył gotowe przykłady warto chociaż spróbować. Sam interfejs jest opisywany jako SPI, ale szybkie spojrzenie na listę wyprowadzeń może nieco zaskoczyć. Po pierwsze używane są nieco inne nazwy, po drugie komunikacja jest jednokierunkowa (można tylko wysyłać dane do wyświetlacza), a po trzecie wreszcie jest sporo linii, które nie są obecne w standardowym interfejsie SPI. Musimy również zadbać o zasilanie układu z napięcia 3.3V oraz konwersję napięć sterujących - Arduino UNO używa sygnałów o napięciu 5V, co może uszkodzić wyświetlacz TFT. Do podłączenia użyłem modułu opartego o układ 74LVC245, można to zrobić taniej, lepiej itd. ale akurat miałem taki moduł pod ręką. Krótki opis wyprowadzeń wyświetlacza: 3V3, GND - zasilanie DIN - linia danych, podłączamy do MOSI interfejsu SPI CLK - zegar interfejsu SPI CS - odpowiada linii CS interfejsu SPI DC - informuje o rodzaju przesyłanych danych, stan niski oznacza komendę sterującą, a wysoki dane RST - stan niski resetuje sterownik wyświetlacza BL - sterowanie podświetlaniem Podłączenie do Arduino UNO jest dość proste, linie interfejsu SPI, czyli DIN i CLK należy podłączyć do pinów zapewniających dostęp do sprzętowego modułu SPI, pozostałe linie są sterowane programowo (chociaż BL można podłączyć do wyjścia PWM, aby uzyskać sterowanie jasnością podświetlenia). W programie przykładowym użyte wyprowadzenia są zdefiniowane w pliku o nazwie DEV_config.h, powinniśmy więc ustawić je odpowiednio do wybranego sposobu podłączenia. U mnie ten kod wygląda następująco: //GPIO config //LCD #define LCD_CS 7 #define LCD_CS_0 digitalWrite(LCD_CS, LOW) #define LCD_CS_1 digitalWrite(LCD_CS, HIGH) #define LCD_RST 5 #define LCD_RST_0 digitalWrite(LCD_RST, LOW) #define LCD_RST_1 digitalWrite(LCD_RST, HIGH) #define LCD_DC 6 #define LCD_DC_0 digitalWrite(LCD_DC, LOW) #define LCD_DC_1 digitalWrite(LCD_DC, HIGH) #define LCD_BL 4 #define LCD_BL_0 digitalWrite(LCD_DC, LOW) #define LCD_BL_1 digitalWrite(LCD_DC, HIGH) #define SPI_Write_Byte(__DATA) SPI.transfer(__DATA) Pierwsze uruchomienie Czas skompilować i uruchomić program przykładowy. Po drobnych poprawkach oraz ustawieniu wybranych pinów powinno udać się program skompilować. Warto zwrócić uwagę na ilość użytej pamięci: Jak widzimy wykorzystane zostało raptem 9348 bajtów pamięci Flash (28%) oraz 453 bajtów pamięci RAM (22%). To bardzo mało i jak później się przekonamy to jeden z powodów "niedoskonałości" tego rozwiązania. Ale na razie czas zaprogramować Arduino i podłączyć zasilanie: Dobra wiadomość jest taka że działa - i to w wysokiej rozdzielczości (160x128) oraz w kolorze... Zła jest taka, że może "niezbyt szybko" działa. Zanim stwierdzimy, że wyświetlacz do niczego się nie nadaje, warto nieco dokładniej przyjrzeć się przyczynom takich, a nie innych osiągów. Dzięki temu może uda się działanie programu nieco poprawić. Czas rysowania zawartości ekranu Pomiary "na oko" to niezbyt doskonała metoda, nieco lepiej dodać wywołanie millis() przed rozpoczęciem i po zakończeniu rysowania ekranu. Różnica między zwróconymi czasami pozwoli nam oszacować jak szybko (albo wolno) działa pierwszy program. Przy okazji możemy jeszcze sprawdzić ile zajmuje skasowanie zawartości ekranu. Nowy program w pętli rysuje i kasuje zawartość ekranu: Wyniki pomiarów to ok. 1240 ms dla rysowania oraz 96 ms dla kasowania zawartości. "Not great, not terrible" chciałoby się powiedzieć... Prosta animacja Wyświetlanie ekranu demonstracyjnego jest oczywiście interesujące, ale może warto sprawdzić jak ekran zachowa się w nieco bardziej pasjonującym zastosowaniu. Zacznijmy od odbijającej się piłeczki, taki wstęp do napisania gry w "ponga". Pierwsze podejście jest mocno uproszczone - w pętli głównej kasujemy zawartość ekranu, obliczamy pozycję piłki i rysujemy: Jak widzimy tempo gry jest raczej spokojne, a miganie irytujące. Warto jeszcze przetestować ile czasu zajmuje naszemu programowi rysowanie: Wyszło trochę ponad 100ms, to nieco więcej niż czas samego kasowania ekranu, więc jak łatwo się domyślić właśnie ta czynność zajmuje najwięcej czasu. Optymalizacja Skoro już wiemy, że najwięcej czasu zajmuje kasowanie ekranu, to może zamiast kasować wszystko warto usuwać jedynie poprzednią pozycję "piłki" i rysować nową. Taki program działa już znacznie lepiej: Porównajmy jeszcze czasy rysowania: Jak widzimy skasowanie i narysowanie piłeczki zajmuje o wiele mniej czasu. Nieco jednak uprzedzając dalsze części, spróbujmy jeszcze zamiast okrągłej piłki użyć kwadratowej. Może nie brzmi to zachęcająco, ale efekt robi wrażenie: Podsumowanie To co zobaczyliśmy to pierwsze możliwości optymalizacji. Nawet jeśli odrysowanie całego ekranu zajmuje mnóstwo czasu, możemy uzyskać o wiele lepsze efekty zmieniając sposób rysowania. To jedna z metod optymalizacji - nie jedyna i w kolejnej części postaram się opisać dlaczego rysowanie działa tak wolno i o ile możemy poprawić wydajność. Spis treści: Sterowanie wyświetlaczem TFT - część 1 - wstęp, podstawowe informacje Sterowanie wyświetlaczem TFT - część 2 - analiza problemu Sterowanie wyświetlaczem TFT - część 3 - testy prędkości na STM32 Sterowanie wyświetlaczem TFT - część 4 - własny program Sterowanie wyświetlaczem TFT - część 5 - optymalizacja programu

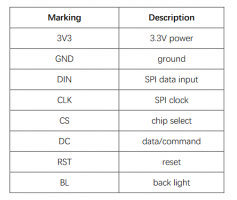




-
Sprzedaż samodzielnie zbudowanego urządzenia może być kuszącą wizją dla wielu początkujących elektroników. Czy jeśli układ działa, to można go od razu zacząć sprzedawać, np. na Allegro? W tym miejscu warto jednak uświadomić sobie, że każdy producent elektroniki jest zobowiązany do przestrzegania różnych przepisów. [blog]https://forbot.pl/blog/skonstruowalem-sobie-budzik-z-wifi-a-co-z-ce-id41631[/blog]
-

Kamera termowizyjna dla elektronika? Czy to ma sens?
satanistik opublikował temat w Artykuły użytkowników
Kamery termowizyjne, dzięki którym z łatwością poznamy temperaturę otaczającego nas świata, są coraz tańsze i mniejsze. Czy zakup kamery w formie małej przystawki do telefonu ma sens? O czym warto pamiętać przed zakupem kamery i gdzie może się ona przydać? [blog]https://forbot.pl/blog/kamera-termowizyjna-dla-elektronika-czy-to-ma-sens-id42118[/blog] -
Chcielibyście, aby urządzenie z ESP8266 wysyłało do Was e-maile lub powiadomienia push? Może zastanawialiście się, jak połączyć najnowsze DIY z asystentem głosowym od Google? Te pozornie trudne zadania można bardzo łatwo rozwiązać za pomocą popularnego IFTTT! [blog]https://forbot.pl/blog/praktyczny-poradnik-laczenia-esp-z-ifttt-if-this-then-that-id41663[/blog] IFTTT_przyklad_IO.zip
-
Regulator PID (proporcjonalno-całkująco-różniczkujący) jest jednym z podstawowych typów regulatorów. Znalazł swoje miejsce w niezliczonej liczbie układów regulacji. Implementacja i testowanie algorytmu sterowania na rzeczywistym obiekcie pozwoli na łatwiejsze zapoznamie się z zasadami nim rządzącymi. W artykule zostanie zwrócona uwaga na wpływ poszczególnych członów regulatora na zachowanie obiektu. Co więcej zwrócimy uwagę na problem nasycania się całki (ang. integral windup) i zrealizujemy przykładowy układ do jego przeciwdziałania. Ten wpis brał udział konkursie na najlepszy artykuł o elektronice lub programowaniu. Sprawdź wyniki oraz listę wszystkich prac » Partnerem tej edycji konkursu (marzec 2020) był popularny producent obwodów drukowanych, firma PCBWay. Zarys struktury Obiektem sterowania jest śmigło (opis projektu wkrótce) z 8-bitowym mikrokontrolerem AVR w którym zaimplementujemy nasz regulator. Urządzeniem wykonawczym jest silnik prądu stałego. Jego sterowanie odbywa się za pomocą 10-bitowej modulacji szerokości impulsu. Sprzężenie zwrotne pozyskiwane jest z czujnika odległości zamontowanego na płytce. Jednostką odczytywanych wartości jest milimetr. Celem regulacji jest utrzymanie śmigła na zadanej wysokości - w naszym przypadku 1m. Jak wygląda schemat blokowy zaimplementowanego układu regulacji? Wykorzystane rozwiązanie przedstawione jest na poniższym obrazku. Kod algorytmu Nazwy zmiennych w kodzie programu są nazwane analogiczne do nazw sygnałów na schemacie blokowym. Kod pętli głównej programu został przedstawiony poniżej. while(1) { // czas próbkowania Ts=50ms // kod odpowiedzialny za pobranie i zapisanie w zmiennej height odległości od powierzchni w mm while(dataReady == 0) VL53L1X_CheckForDataReady(dev, &dataReady); dataReady = 0; VL53L1X_GetDistance(dev, &height); VL53L1X_ClearInterrupt(dev); error = height_setpoint - height; // obliczanie wartości uchybu sterowania // sterowanie niebieską diodą led sygnalizującą zawieranie się wartości uchybu w przedziale +-5cm if(abs(error) < 50) PORTD |= (1<<PD3); else PORTD &= ~(1<<PD3); // obliczanie całki metodą prostokątów z uwzględznieniem sprzężenia od mechanizmu anti-windup integral = integral + error*Ts + Kaw*integral_correction; // obliczanie pochodnej derivative = (error-last_error)/Ts; // równanie obliczające wartość wielkości sterującej przed ograniczeniem cv_before_sat = Kp*error + Ki*integral + Kd*derivative; if(cv_before_sat > 1023) control_value = 1023; // ograniczenie wartości sterującej else if(cv_before_sat < 0) control_value = 0; else control_value = cv_before_sat; // warunek zatrzymujący śmigło na czas 3s w przypadku wysokości mniejszej niż 10cm if(height < 100) { control_value = 0; OCR1A = (uint16_t)control_value; for(int i = 0; i < 6; i++) { // mruganie diodą PORTD ^= (1<<PD3); _delay_ms(500); } integral = 0; // zerowanie całki } else OCR1A = (uint16_t)control_value; // przypisanie wartości cv jako wypełnienie PWM integral_correction = control_value - cv_before_sat // różnica wartości sterujących last_error = error; // zapamiętanie wartości uchybu jako ostatni uchyb } Badanie działania poszczególnych członów Wstępny dobór nastaw regulatora zrealizowano metodą testów symulacyjnych: Kp=1.6, Ki=0.75, Kd=0.3, Kaw=0.1. W celu przebadania sposobu działania regulatora sprawdzimy zachowanie obiektu w kilku przypadkach, włączając kolejne człony regulatora. Śmigło po włączeniu zapamiętuje 400 ostatnich próbek aktualnej wysokości, lub wielkości sterującej. Z mikrokontrolera wyciągniemy je dzięki komunikacji UART, a następnie naszkicujemy odpowiednie wykresy. Przejdźmy do analizy działania członu proporcjonalnego. Jaka jest jego idea? W skrócie generuje tym silniejszy sygnał im większa jest różnica między wartością zadaną a wartością sterującą. Niżej przedstawione zostało zachowanie naszego obiektu z regulatorem tylko wykorzystującym człon proporcjonalny. Odpowiedź obiektu sterowanego jest daleka od ideału. Korzystanie tylko z członu P w obiektach często prowadzi do utraty stabilności, tak jak w naszym przypadku. Zajmijmy się członem różniczkującym. Człon różniczkujący jak nazwa wskazuje liczy pochodną. Im większy przyrost uchybu tym większa wartość sygnału sterującego. Jak sprawił się w naszym przypadku razem z członem P? Zastosowanie członu D pozwoliło na stabilizację obiektu, jednak uchyb w stanie stanie ustalonym nie jest do przyjęcia. Rozwiązaniem problemu jest dodanie członu I. Działanie członu całkującego polega na obliczaniu całki, czyli w najprostszym wypadku w systemach dyskretnych na ciągłym sumowaniu kolejnych uchybów z uwzględnieniem czasu próbkowania. Regulator PI w naszym obiekcie zareagował dosyć drastycznie. Człon całkujący korzystnie wpływa na powstawanie oscylacji, oraz na destabilizowanie układu regulacji. Sprawdźmy zachowanie obiektu regulacji z wykorzystaniem pełnego regulatora PID. Szczęśliwie dla nas, po zastosowaniu różniczki obiekt został doprowadzony do stabilności, a dzięki całkowaniu uchyb w stanie ustalonym został wyeliminowany. Jednak przy członie całkującym należy zachować ostrożność i powrócić do wspomnianego wcześniej nasycania się całki. Brak mechanizmu anti-windup, może doprowadzić do zdominowania przez człon całkujący sygnału sterującego! W naszym przypadku taką sytuację możemy wygenerować przytrzymując przez chwilę śmigło w miejscu lekko oddalonym od wartości ustalonej. Lepszą analizę tego problemu można przeprowadzić obserwując wartość sterującą w czasie. Zaimplementowanie mechanizmu anti-windup do naszego regulatora spowodowało odpowiedzi jak niżej. Użyty przez nas mechanizm skutecznie osłabił człon I w chwilach kiedy całka została nasycona, a dodatkowo przyrost wartości sterującej został nieznacznie ograniczony. Moje zmagania z regulatorem PID prezentuje poniższy filmik. Podsumowanie Mam nadzieję, że temat regulatora PID został nieco bardziej przybliżony. Zrozumienie jego działania jest podstawą do poznania bardziej zaawansowanych algorytmów, które kiedyś będziesz mógł wykorzystać w swoich projektach! Cały kod programu dostępny jest na moim GitHubie. Pozdrawiam, Karol

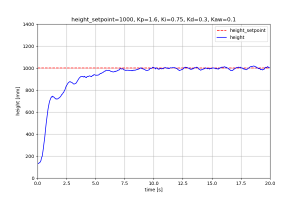
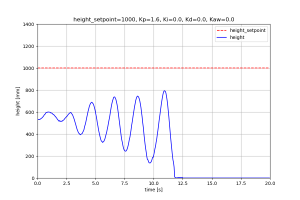
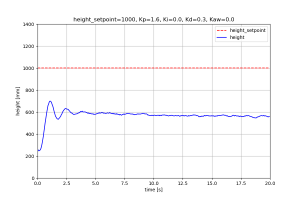
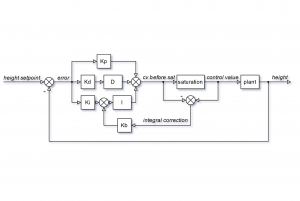
-
Port USB i bootloader w STM32f1C8T6 a Windows 10 i ARDUINO IDE
Gość opublikował temat w Artykuły użytkowników
Port USB i bootloader w STM32f1C8T6 a Windows 10 i ARDUINO IDE Kiedy po raz pierwszy wpadł mi w ręce moduł STM32f1C8T6 byłem zachwycony.Nie wiedziałem, że ładowanie programu przez port USB do STM32f1C8T6 jest niemożliwe bo jest kłopot z bootloaderem i sterownikami. Mój komputer ma Windows 10 i ten artykuł jest dedykowany do tych co mają ten sam system. Nie wiem jak to, co opisuję poniżej, stosuje się do wcześniejszych wersji Windows. Rozwiązanie problemu komunikacji poprzez port USB otwiera ogromne możliwości ot chociażby taniutka porządna karta A/D. Cóż, zawsze trzeba szukać właściwych rozwiązań. Jedno rozwiązanie zostało zaprezentowane na blogu Forbota. Ten wpis brał udział konkursie na najlepszy artykuł o elektronice lub programowaniu. Sprawdź wyniki oraz listę wszystkich prac » Partnerem tej edycji konkursu (marzec 2020) był popularny producent obwodów drukowanych, firma PCBWay. Czy jest proste? Nie. Dlatego poszukałem rozwiązania i je znalazłem. Ale nim do tego doszło próbowałem tworzenia rozwiązania opartego o program STM32CubeMX(doradził mi syn, który jest zawodowym programistą) ale dałem sobie spokój w momencie kiedy należało gdzieś coś dopisać, coś wyciąć. Chyba nie po to stworzono ten program by po wygenerowaniu odpowiednich plików coś dopisywać lub wycinać,przestawiać. Bez sensu. Pomyślałem, problem komunikacji kontroler STM32 - komputer via port USB wystąpił już dawno i dawno musiał zostać rozwiązany. Jest to prawda połowiczna bo w trakcie „życia” STM32 powstały co najmniej dwa nowe systemy Windows i jak się okazuje problem mimo rozwiązania na daną chwilę może się pojawić ponownie przy kolejnej nowelizacji systemu. W Polsce spotkałem dwa artykuły poświęcone temu zagadnieniu. Jeden przytoczyłem powyżej i w gruncie rzeczy jest przedrukiem z jednego z pism poświęconych elektronice a drugi nie działa pod Windows 10 ale działa pod wcześniejszymi wersjami Windows o czym poinformował użytkowników twórca kontrolerów STM32 STMicroelecronics w pliku STSW-STM32102 . Społeczność programistów dostarczyła sterowniki i jak zapewniają programiści prace nad ulepszeniem sterowników trwają. Rozwiązanie jest proste i każdy może je zastosować u siebie.Pozbieranie wszystkich informacji potrzebnych i ich przetworzenie w moim przypadku trwało ponad tydzień.W ostatnich latach Arduino i STMicroelectronics(STM) postanowiły wspólnie stworzyć platformę do obsługi 32 bitowych kontrolerów w środowisku Arduino. Wymiernym efektem współpracy jest cała rodzina kontrolerów STM obsługiwanych przez Arduino. Najnowsza wersja Arduino IDE 1.8.11 jest już na tym etapie, że nie trzeba przy przypisywaniu portów wpisywać np.PC13 a tylko13 tak jak to jest dla ATmegi ale jeśli komuś zależy na pisaniu przysłowiowego PC13 to dla kompilatora nie jest to problem. Programy napisane dla ATmegi kompilują się bez problemu dla STM32f1.Ponieważ artykuł ma być dla każdego to muszę zacząć od początku czyli od instalacji Arduino IDE. Ściągamy wersję Arduino IDE 1.8.11 lub nowszą i instalujemy. Następnie otwieramy Arduino i klikamy w zakładkę plik , następnie klikamy w preferencje po czym klikamy w dodatkowe adresyURL do menadżera płytek, ukaże się okno dodatkowe adresy URL do menadżera płytek. Należy wpisać trzy adresy http://dan.drown.org/stm32duino/package_STM32duino_index.json http://arduino.esp8266.com/stable/package_esp8266com_index.json http://digistump.com/package_digistump_index.json i klikamy OK i OK. Następnie przechodzimy do zakładki Narzędzia -> Płytka -> Menedżer płytek . W wyszukiwarce wpisujemy stm32f1.W efekcie wyświetli się wynik ,klikamy na niego a następnie klikamy Instaluj.Następnym krokiem jest zainstalowanie dodatkowych bibliotek,które są niezbędne to jest Arduino SAM Boards i Arduino SAMD Boards .Efektem powyższej instalacji będzie to,że w zakładce płytka pojawią się płytki STM. To tyle na temat instalacji Arduino IDE.Teraz zajmiemy się portem USB w STMf1xxxx,który jest nieaktywny. Rozwiązanie problemu komunikacji komputer STM32f1 via USB. Pierwszą rzeczą jest utworzenie konta na stronie STM,które jest niezbędne do ściągnięcia programu https://www.st.com/content/st_com/en.html (po prawej u góry jest zakładka Login). STM32f1 płytka podstawowa nie posiada bootloadera(to znaczy posiada ale….),który należy zainstalować w stm32f1. Windows 10 i Arduino IDE nie posiadają odpowiednich sterowników w związku z tym należy je zainstalować . Procedura: Należy ściągnąć trzy pliki en.flasher-stm.zip https://www.st.com/en/development-tools/flasher-stm32.html STM32duino-bootloader-master.zip https://github.com/rogerclarkmelbourne/STM32duino-bootloader Arduino_STM32-master.zip https://github.com/rogerclarkmelbourne/Arduino_STM32 Po rozpakowaniu w pierwszej kolejności instalujemy flash_loader_demo_v2.8.0.exe z folderu en.flasher-stm. Następnie używając przejściówki(FTDI) usb na uart podłączamy 3,3V(należy przestawić zworkę na 3,3V) z przejściówki do 3,3V płytki STM32f1C8T6,GND do GND płytki STM32f1C8T6 , Rx przejściówki do A9 STM32f1C8T6,Tx przejściówki do A10 STM32f1C8T6. Sprawdzamy prawidłowość połączeń! Zworkę BOOTO przestawiamy na1.Następnie uruchamiamy program demonstrator GUI który jest w folderze stmicroelectronics resetujemy STM32f1C8T6 ,wybieramy port com Klikamy Next Klikamy Next Klikamy Next lub Klikamy Download to device a następnie w kwadracik z kropkami i odnajdujemy plik ,który jest umieszczony w folderze STM32duino-bootloader-master -> binares-> generic_boot20_pc13.bin (21kB).Nie kombinujemy,wybieramy tylko ten albo ten drugi plik a nie jakiś inny, jesteśmy jak koń dorożkarski! Klikamy Next. Bootloader zostanie zainstalowany. Odłączamy kabel USB a następnie wypinamy kabelki z STM32f1,zworkę BOOTO przestawiamy na 0.Następnym krokiem jest zainstalowanie sterowników STM32f1 .Do tego służy program umieszczony w Arduino_STM32-master -> Arduino_STM32-master-> drivers->win-> install_drivers.bat i uruchamiamy w trybie administratora!! i po dłuższej chwili sterowniki są zainstalowane (cierpliwości, pojawi się komunikat sukces a właściwie dwa komunikaty sukces). Ostatnim krokiem jest sprawdzenie poprawności działania.Otwieramy Arduino IDE,podłączamy płytkę do przewodu USB A-B ( z jednej strony normalna wtyczka usb typA a drugiej strony usb mini typu B). Sprawdzamy czy port jest aktywny instalujemy(nie poruszam konfiguracji płytki bo to jest oczywiste). W Arduino odnajdujemy program np.Blink kompilujemy i jeśli jest wszystko ok. wgrywamy program. Po pomyślnym wgraniu dioda powinna migać zgodnie z tym co opisano w programie Blink. Zachwyt nad modułem STM32f1C8T6 wrócił.


-
Python to język wysokopoziomowy, który ma bardzo szerokie zastosowanie. Można w nim napisać grę (PyGame) albo zrobić komunikację mikrokontrolera z programem na komputerze/laptopie (PySerial), aby na przykład wysyłać komendy. W tym kursie zajmiemy się tą drugą biblioteką. W starszych komputerach istnieją porty szeregowe RS-232. W nowszych komputerach portu tego raczej się nie uraczy. Ten wpis brał udział konkursie na najlepszy artykuł o elektronice lub programowaniu. Sprawdź wyniki oraz listę wszystkich prac » Partnerem tej edycji konkursu (marzec 2020) był popularny producent obwodów drukowanych, firma PCBWay. Jest jednakże światełko w tym ciemnym tunelu, gdyż sterowniki niektórych urządzeń USB emulują port szeregowy COM umożliwiając tym samym proste komunikowanie się z takim urządzeniem na nowszych maszynach. Do takich urządzeń należą płytki rozwojowe Arduino RS-232(rys. 1) Prosta komunikacja pomiędzy uC (mikrokontrolerem) a PC (rys. 2) 1.Wysyłanie informacji z mikrokontrolera do komputera/laptopa. Konfiguracja połączenia z portem COM Zanim zacznie się przygodę z komunikacją za pośrednictwem portu COM konieczne jest zapoznanie się z podstawami jego działania. Port ten przesyła dane dwukierunkowo za pomocą jednego pinu przesyłającego i jednego odczytującego dane. Dane przesyłane są zawsze z określoną prędkością mierzoną w bitach na sekundę. Standardowe ustawienie prędkości transmisji z urządzeniem wynosi 9600 bitów na sekundę. Ważne aby, wysyłać i odbierać dane z taką samą częstotliwością w przeciwnym przypadku dane nie będą odbierane przez urządzenie w sposób poprawny jak również program nie będzie w stanie poprawnie odbierać danych. Przy podstawowej konfiguracji konieczne jest również posiadanie wiedzy o nazwie portu. Pod Windowsem nazwy portów zaczynają się od COM i kończą liczbą określającą numer portu. Można sprawdzić w systemie, jakie porty COM są dostępne w Menadżerze urządzeń co też i widać na poniższym rysunku (rys. 3) rys. 3 Przygotowanie środowiska na komputerze/laptopie Tak jak już mówiłem, będziemy potrzebować biblioteki PySerial omówię jej instalację w środowisku PyCharm: Wchodzimy w terminal, następnie wpisujemy: "pip install pyserial" Naciskamy enter Powinniśmy zobaczyć coś takiego (rys. 4) rys. 4 teraz przejdzmy do Arduino. Przygotowywanie Arduino (oczywiście zadziała komunikacja zadziała wszędzie gdzie użyjemy UART'a, nie tylko Arduino) Na razie jedyne co napiszemy to: void setup() { Serial.begin(9600); // Ustawienie Baud Rate(prędkość transmisji) na 9600Hz } void loop() { Serial.println("Proba Komunikacji"); delay(1000); } Wgrywamy nasz program, uruchamiamy Monitor Portu Szeregowego gdzie powinno sie pojawić się (rys. 5) rys. 5 i tak co około sekundę (przy okazji widzimy, że funkcja delay nie jest taka dokładna (dlatego nie stosuje sie jej gdy robimy na przykład zegar)) Teraz można przejść do PyCharma import serial arduino = serial.Serial('COM5', 9600, timeout=0.1) while True: data = arduino.readline() if data: data = data.decode() print(data) Można powiedzieć, że właśnie zrobiliśmy monitor portu szeregowego z ArduinoIDE Omówienie kodu: Importujemy bibliotekę, Ustawiamy port do któego mamy podłączone Arduino oraz Baud Rate, Przypisujemy do zmiennej to co aktualnie jest przesyłane, Jeżeli zmienna nie jest pusta to ją dekodujemy i wyświetlamy na ekranie. ZAWSZE MUSIMY PAMIĘTAĆ O ZDEKODOWANIU (tylko na komputerze)!!! Wyłączamy monitor portu szeregowego (ten z ArduinoIDE), kompilujemy program i naszym oczom powinno ukazać się (rys. 6) rys. 6 2. Wysyłanie komend z komputera/laptopa do mikrokontrolera. Przejdźmy do PyCharma import serial import time arduino = serial.Serial('COM5', 9600, timeout=0.01) while True: arduino.write('wlacz'.encode()) time.sleep(1) arduino.write('wylacz'.encode()) time.sleep(1) Importujemy bibliotekę time (nie trzeba jej instalować) oraz wysyłamy "wiadomości": "wlacz" oraz "wylacz" To by było na tyle w PyCharmie, przejdźmy więc do ArduinoIDE rys. 7 Jako że robimy komunikację używając UART'a, który może wysyłać maksymalnie jeden znak, ponieważ (rys. 7) jeden znak to jeden bajt (bajt ma 8bitów) a my wysyłamy komendy: "wlacz" oraz "wylacz" to musimy zrobić taki mały myczek elektryczek i użyć zmiennej oraz pętli. Będzie wyglądać to tak: wysyłamy: w Arduino: "odbiera" i zapisuje do zmiennej wysyłamy: l Arduino: "odbiera" i zapisuje do zmiennej wysyłamy: a Arduino: "odbiera" i zapisuje do zmiennej wysyłamy: c Arduino: "odbiera" i zapisuje do zmiennej wysyłamy: z Arduino: "odbiera" i zapisuje do zmiennej nie wysyłamy nic Arduino: wychodzi z pętli oraz porównuje zawartość zmiennej z komendami które ma zapisane Arduino: wykonuje komendę Arduino: czyści zawartość zmiennej z komendą Takie wybrnięcie z sytuacji int i = 12; //pin do którego podłączymy diodę String komenda=""; void setup() { Serial.begin(9600); pinMode(i, OUTPUT); digitalWrite(i, HIGH); } void loop() { if(Serial.available() > 0) { while(Serial.available() > 0) { komenda += char(Serial.read()); } Serial.println(komenda); if(komenda == "wlacz") { digitalWrite(i, HIGH); } if(komenda == "wylacz") { digitalWrite(i, LOW); } komenda = ""; } delay(100); } Oczywiście można wysłać do komputera/laptopa "informację zwrotną" na przykład: Dioda jest wlaczona Dioda jest wylaczona Tylko musimy pamiętać aby użyć .decode(), ale tak jak mówiłem, tylko w programie na komputrzez/laptopie Jeżeli nasze komendy będą miały tylko 1 znak na przykład: a, A, 1, B, c, C ,4 (ogólnie to dowolny znak z tabeli ASCII) nie trzeba używać pętli tylko: if(Serial.read() == 's') oczywiście też w tym ifie: if(Serial.available() > 0) Jeżeli wstawilibyśmy tam więcej znaków dostalibyśmy taki komuniukat: warning: multi-character character constant [-Wmultichar]. 3. Podsumowanie Wysyłanie oraz odbieranie informacji jest bardzo przydatne, nie musi być to tylko pomiędzy uC, a komputerem. Może to być komunikacja pomiędzy dwoma uC na przykład: karta microSD ma w sobie procesor który komunikuje sie z uC używając SPI, termometr DS18B20 który komunikuje z uC używając protokołu komunikacji OneWire (rys. 8), czujnik podczerwieni, procesor w naszych komputerach z mostkiem, pamięcią i GPU, ładowarka z telefonem, aby ustalić jaki prąd i napięcie. Komunikacja jest wszędzie (można powiedzieć, że urządzenia są bardziej komunikatywne od nas ). rys. 8









-
 Słowem wstępu, wyobraźmy sobie że jesteśmy na słonecznej, piaszczystej plaży wzdłuż której rosną wysokie, bogate w orzechy kokosowe palmy. Pod jedną z nich stoi lokalny, doświadczony, zbieracz kokosów, u którego mamy zamiar nauczyć się tego ciężkiego rzemiosła. Jako zaledwie początkujący adepci tej trudnej sztuki, nie mamy jednak zielonego pojęcia jak się do tego zabrać. Dlatego nasz nowy mentor musi nam wytłumaczyć co i jak powinniśmy zrobić. Może on nam wytłumaczyć wszystko krok po kroku. Opisać dokładne pozycje naszych kończyn, prędkość z jaką będziemy się wspinać i sposób odbierania kokosu. Oczywiście opisanie nam tego na tyle dokładnie, byśmy mogli bezbłędnie przystąpić do pracy wymagałoby dużo czasu i energii. Zamiast tego, może pokazać nam osobiście jak to zrobić i dać nam przystąpić do pracy. W krótkim i bogatym w informacje czasie, będziemy wiedzieli jak przystąpić do pracy. Ten wpis brał udział konkursie na najlepszy artykuł o elektronice lub programowaniu. Sprawdź wyniki oraz listę wszystkich prac » Partnerem tej edycji konkursu (marzec 2020) był popularny producent obwodów drukowanych, firma PCBWay. Po tym ciut przydługawym wstępie, którym starałem się nakreślić pewien problem, możemy przystąpić do właściwego omówienia tematu. Istnieje wiele metod programowania robotów przemysłowych (manipulatorów). Wykonują one precyzyjne prace, wymagające wielu skomplikowanych ruchów. Jednak poza nimi, roboty mogą też wykonywać mniej skomplikowane ruchy np. podczas zmiany pozycji lub przełączenia między poszczególnymi pracami. O ile do wykonania operacji precyzyjnych niezbędny jest szczegółowo opracowany program, o tyle podczas ruchów mniej skomplikowanych czas programowania można ukrócić do metod Online Programming. Krótki film przedstawiający podział metod programowania Metody te pozwalają operatorowi manualnie lub za pomocą odpowiedniego kontrolera ustawić poszczególne pozycje robota, które zostaną przez niego zapamiętane w czasie bieżącym oraz odtworzone w postaci pożądanego przez nas ruchu. Programowanie robota spawalniczego przy pomocy metody teach-in Programowanie robota Festo BionicCobot przy pomocy metody play-back Programowanie play-back opiera się na sczytywaniu przez oprogramowanie pozycji robota, zapisywanie ich oraz odtwarzanie poprzez bezpośrednie poruszanie jego konstrukcją. Aby było to możliwe, każdy stopień swobody robota musi posiadać sensor umożliwiający określenie jego dokładnej pozycji. Oprócz tego napęd robota musi działać w wyrachowany i delikatny sposób, aby konstrukcja była jednocześnie sztywna i można było nią poruszać ręcznie. Programowanie teach-in z kolei polega na ustawieniu robota w ustalonych pozycjach za pomocą odpowiedniego kontrolera, za pomocą którego te pozycje zostaną zapisane a następnie odtworzone. Odtwarzanie kolejno zapisanych pozycji daje w efekcie płynny, ciągły ruch maszyny. Wyżej wspomniane metody omówimy na realnym przykładzie. Za pomocą kontrolera będziemy mogli stosować na prostym manipulatorze metodę teach-in. Robot napędzany jest serwami modelarskimi oraz wykonany w technice druku 3D. Serwa posiadają wbudowane potencjometry sczytujące pozycje kątowe wałów, jednak bez ingerencji w ich budowę ciężko będzie korzystać z tych potencjometrów do określania pozycji robota. Dlatego manualne ustawienie pozycji manipulatora metodą play-back wypada z puli naszych opcji. Poza tym istniałaby duża szansa na uszkodzenie stosowanych w robocie serw. Zamiast tego, posłużymy się kontrolerem, który będzie kinetycznym modelem naszego manipulatora i pozwoli także zahaczyć o ideę play-back. Ramię manipulatora wydrukowane w 3D, poniżej link do źródła https://www.thingiverse.com/thing:1015238 Kontroler odpowiada kinematyce prezentowanego robota i ma umieszczone potencjometry w każdym jego punkcie swobody. Poruszając nim, możemy ustalić rzeczywistą pozycję naszego manipulatora. Budując r obota o mniej skomplikowanej budowie, możemy pozostać przy samych potencjometrach np. zamontowanych na płytce stykowej. Jednak w przypadku tego robota korzystanie z tego rozwiązania byłoby trudniejsze i mniej wygodne w użytku. Model kinematyczny manipulatora Znając już budowę kontrolera oraz manipulatora, należy je już tylko do siebie podłączyć. Oprócz tego do układu dodane zostaną przyciski nagrywania oraz odtwarzania ruchu. Elektronika opiera się o mikrokontroler atmega328p. Zasilanie układu odbywa się z sieci napięciem 230 V. W obudowie znajduje się układ prostujący, przetwornica step-down zasilająca serwomechanizmy oraz płytka arduino ze wspomnianym wcześniej mikrokontrolerem. Dla wygody wszystkie piny arduino zostały wyprowadzone na zewnątrz obudowy. Cały schemat przedstawianej konstrukcji znajduje się poniżej: Schemat układu Lista opisanych komponentów: -S1 – włącznik główny, -S2 – przycisk nagrywania, -S3 – przycisk odtwarzania, -D1 – mostek Graetza 400V ; 4A, -D2 – zielona dioda LED, -C1 – kondensator elektrolityczny 1000µF ; 50V, -C2 – kondensator elektrolityczny 220µF ; 25V, -C3 – kondensator elektrolityczny 22µF ; 25V, -C4 – kondensator ceramiczny 100nF, -C5 – kondensator ceramiczny 22pF, -C6 – kondensator ceramiczny 22pF, -C7 – kondensator ceramiczny 100nF, -R1 – rezystor 150 Ω, -R2, R3, R4 – rezystor 1 kΩ, -POT 1, POT 2, POT 3, POT 4, - 10 kΩ, -Stabilizator napięcia LM7805, -Przetwornica step-down LM2596, -X1 – kwarc 16 MHz, Połączenie układu Po podłączeniu całej elektroniki można przystąpić do omówienia kodu arduino. Program ten został już zaopatrzony w bogatą ilość komentarzy, które na pewno pomogą osobom dopiero rozpoczynającym swoją przygodę z arduino: //biblioteka umożliwiająca nie tylko sterowanie serwami, ale także ich prędkością //nie jest ona koniecznością, wystarczy standardowa biblioteka <servo.h> oraz pozbycie się zmiennej 'predkosc' z koduć #include <VarSpeedServo.h> //definiujemy serwa używane w robocie: VarSpeedServo servo1; VarSpeedServo servo2; VarSpeedServo servo3; VarSpeedServo servo4; //definiujemy przyciski nagrywania i odtwarzania: const int przycisk_A = 2; const int przycisk_B = 3; //definiujemy wartości dla wciśniętych przycisków nagrywania i odtwarzania: int przycisk_A_ON = 0; boolean przycisk_B_ON = false; //definiujemy potencjometry: const int potencjometr1 = A0; const int potencjometr2 = A1; const int potencjometr3 = A2; const int potencjometr4 = A3; //definiujemy zmienne służące do odczytu wartości napięć z potencjometrów: int potencjometr_1_odczyt; int potencjometr_2_odczyt; int potencjometr_3_odczyt; int potencjometr_4_odczyt; //definiujemy zmienne służące do zapisu wartości kąta położenia poszczególnego serwa: int potencjometr_1_zapis; int potencjometr_2_zapis; int potencjometr_3_zapis; int potencjometr_4_zapis; //definiujemy tablice zapisujące położenie serwa: int Pozycja_serva1[]={1,1,1,1,1}; int Pozycja_serva2[]={1,1,1,1,1}; int Pozycja_serva3[]={1,1,1,1,1}; int Pozycja_serva4[]={1,1,1,1,1}; void setup() { //definiujemy piny do których podłączone są serwa: servo1.attach(6); servo2.attach(9); servo3.attach(10); servo4.attach(11); //definiujemy piny wejściowe przycisków nagrywania i odtwarzania: pinMode(przycisk_A, INPUT_PULLUP); pinMode(przycisk_B, INPUT_PULLUP); //inicjalizacja portu szeregowego do podglądu działania programu: Serial.begin(9600); } void loop() { //ustalanie prędkości serw w zakresie od 0 do 180: int predkosc = 90; //zapis formuły umieszczania odczytanej z potencjometrów wartości do tabeli: potencjometr_1_odczyt = analogRead(potencjometr1); potencjometr_1_zapis = map (potencjometr_1_odczyt, 0, 1023, 20, 175); potencjometr_2_odczyt = analogRead(potencjometr2); potencjometr_2_zapis = map (potencjometr_2_odczyt, 0, 1023, 5, 175); potencjometr_3_odczyt = analogRead(potencjometr3); potencjometr_3_zapis = map (potencjometr_3_odczyt, 0, 1023, 5, 175); potencjometr_4_odczyt = analogRead(potencjometr4); potencjometr_4_zapis = map (potencjometr_4_odczyt, 0, 1023, 20, 160); //serwa przyjmują pozycje zapisane w tabelach: servo1.write(potencjometr_1_zapis, predkosc); servo2.write(potencjometr_2_zapis, predkosc); servo3.write(potencjometr_3_zapis, predkosc); servo4.write(potencjometr_4_zapis, predkosc); //przy kolejnym wciśnięciu przycisku nagrywania tabela każdego serwa zostanie //nadpisana, zapamiętując obecną pozycję serwa: if(digitalRead(przycisk_A) == HIGH) { przycisk_A_ON++; switch(przycisk_A_ON) { case 1: Pozycja_serva1[0] = potencjometr_1_zapis; Pozycja_serva2[0] = potencjometr_2_zapis; Pozycja_serva3[0] = potencjometr_3_zapis; Pozycja_serva4[0] = potencjometr_4_zapis; Serial.println("Pozycja pierwsza zapisana"); break; case 2: Pozycja_serva1[1] = potencjometr_1_zapis; Pozycja_serva2[1] = potencjometr_2_zapis; Pozycja_serva3[1] = potencjometr_3_zapis; Pozycja_serva4[1] = potencjometr_4_zapis; Serial.println("Pozycja druga zapisana"); break; case 3: Pozycja_serva1[2] = potencjometr_1_zapis; Pozycja_serva2[2] = potencjometr_2_zapis; Pozycja_serva3[2] = potencjometr_3_zapis; Pozycja_serva4[2] = potencjometr_4_zapis; Serial.println("Pozycja trzecia zapisana"); break; case 4: Pozycja_serva1[3] = potencjometr_1_zapis; Pozycja_serva2[3] = potencjometr_2_zapis; Pozycja_serva3[3] = potencjometr_3_zapis; Pozycja_serva4[3] = potencjometr_4_zapis; Serial.println("Pozycja czwarta zapisana"); break; case 5: Pozycja_serva1[4] = potencjometr_1_zapis; Pozycja_serva2[4] = potencjometr_2_zapis; Pozycja_serva3[4] = potencjometr_3_zapis; Pozycja_serva4[4] = potencjometr_4_zapis; Serial.println("Pozycja piąta zapisana"); break; } } //po wciśnięciu przycisku odtwarzania serwa będą przyjmować zapisane w tabelach pozycje //z odczekaniem 1.5 sekund w każdej pozycji: if(digitalRead(przycisk_B) == HIGH) { przycisk_B_ON = true; } if(przycisk_B_ON) { for(int i=0; i<5; i++) { servo1.write(Pozycja_serva1[i],predkosc); servo2.write(Pozycja_serva2[i],predkosc); servo3.write(Pozycja_serva3[i],predkosc); servo4.write(Pozycja_serva4[i],predkosc); Serial.println("Odtwórz ruchy"); delay(1500); } } //czas opóźnienia działania programu, od jego nastawy zależy płynnośc pracy robota: delay(200); } Program działa w sposób następujący: Po uruchomieniu programu, za pomocą modelu kinematycznego będzie można bezpośrednio kontrolować ruch manipulatora, Jeżeli wciśniemy przycisk S2 (nagrywania), obecnie ustawiona pozycja robota zostanie zapisana, Program umożliwia zapisanie pięciu różnych pozycji, Jeżeli wybierzemy przycisk S3 (odtwarzania), robot zacznie odtwarzać wybrane przez nas pozycje w nieskończonej pętli, Aby wytyczyć nową sekwencję ruchów należy zresetować układ. Efekt działania powyższego kodu przedstawia się następująco: Dzięki funkcji monitora szeregowego w arduino można obserwować pracę manipulatora bezpośrednio: Przepraszam wszystkich czytelników za jakość nagrań wideo, niestety ograniczały mnie możliwości sprzętowe. Przedstawiony wyżej kod jest prosty a przykład nieskomplikowany, jednak doskonale pokazuje podstawy działania tej metody. Nie mniej jednak mam nadzieję, że artykuł okaże się dla wielu osób pomocny. Oprócz tego zostawiam jeszcze bibliotekę <VarSpeedServo> VarSpeedServo-master.zip Powodzenia we wszelkich przyszłych projektach i przygodach z elektroniką!
Słowem wstępu, wyobraźmy sobie że jesteśmy na słonecznej, piaszczystej plaży wzdłuż której rosną wysokie, bogate w orzechy kokosowe palmy. Pod jedną z nich stoi lokalny, doświadczony, zbieracz kokosów, u którego mamy zamiar nauczyć się tego ciężkiego rzemiosła. Jako zaledwie początkujący adepci tej trudnej sztuki, nie mamy jednak zielonego pojęcia jak się do tego zabrać. Dlatego nasz nowy mentor musi nam wytłumaczyć co i jak powinniśmy zrobić. Może on nam wytłumaczyć wszystko krok po kroku. Opisać dokładne pozycje naszych kończyn, prędkość z jaką będziemy się wspinać i sposób odbierania kokosu. Oczywiście opisanie nam tego na tyle dokładnie, byśmy mogli bezbłędnie przystąpić do pracy wymagałoby dużo czasu i energii. Zamiast tego, może pokazać nam osobiście jak to zrobić i dać nam przystąpić do pracy. W krótkim i bogatym w informacje czasie, będziemy wiedzieli jak przystąpić do pracy. Ten wpis brał udział konkursie na najlepszy artykuł o elektronice lub programowaniu. Sprawdź wyniki oraz listę wszystkich prac » Partnerem tej edycji konkursu (marzec 2020) był popularny producent obwodów drukowanych, firma PCBWay. Po tym ciut przydługawym wstępie, którym starałem się nakreślić pewien problem, możemy przystąpić do właściwego omówienia tematu. Istnieje wiele metod programowania robotów przemysłowych (manipulatorów). Wykonują one precyzyjne prace, wymagające wielu skomplikowanych ruchów. Jednak poza nimi, roboty mogą też wykonywać mniej skomplikowane ruchy np. podczas zmiany pozycji lub przełączenia między poszczególnymi pracami. O ile do wykonania operacji precyzyjnych niezbędny jest szczegółowo opracowany program, o tyle podczas ruchów mniej skomplikowanych czas programowania można ukrócić do metod Online Programming. Krótki film przedstawiający podział metod programowania Metody te pozwalają operatorowi manualnie lub za pomocą odpowiedniego kontrolera ustawić poszczególne pozycje robota, które zostaną przez niego zapamiętane w czasie bieżącym oraz odtworzone w postaci pożądanego przez nas ruchu. Programowanie robota spawalniczego przy pomocy metody teach-in Programowanie robota Festo BionicCobot przy pomocy metody play-back Programowanie play-back opiera się na sczytywaniu przez oprogramowanie pozycji robota, zapisywanie ich oraz odtwarzanie poprzez bezpośrednie poruszanie jego konstrukcją. Aby było to możliwe, każdy stopień swobody robota musi posiadać sensor umożliwiający określenie jego dokładnej pozycji. Oprócz tego napęd robota musi działać w wyrachowany i delikatny sposób, aby konstrukcja była jednocześnie sztywna i można było nią poruszać ręcznie. Programowanie teach-in z kolei polega na ustawieniu robota w ustalonych pozycjach za pomocą odpowiedniego kontrolera, za pomocą którego te pozycje zostaną zapisane a następnie odtworzone. Odtwarzanie kolejno zapisanych pozycji daje w efekcie płynny, ciągły ruch maszyny. Wyżej wspomniane metody omówimy na realnym przykładzie. Za pomocą kontrolera będziemy mogli stosować na prostym manipulatorze metodę teach-in. Robot napędzany jest serwami modelarskimi oraz wykonany w technice druku 3D. Serwa posiadają wbudowane potencjometry sczytujące pozycje kątowe wałów, jednak bez ingerencji w ich budowę ciężko będzie korzystać z tych potencjometrów do określania pozycji robota. Dlatego manualne ustawienie pozycji manipulatora metodą play-back wypada z puli naszych opcji. Poza tym istniałaby duża szansa na uszkodzenie stosowanych w robocie serw. Zamiast tego, posłużymy się kontrolerem, który będzie kinetycznym modelem naszego manipulatora i pozwoli także zahaczyć o ideę play-back. Ramię manipulatora wydrukowane w 3D, poniżej link do źródła https://www.thingiverse.com/thing:1015238 Kontroler odpowiada kinematyce prezentowanego robota i ma umieszczone potencjometry w każdym jego punkcie swobody. Poruszając nim, możemy ustalić rzeczywistą pozycję naszego manipulatora. Budując r obota o mniej skomplikowanej budowie, możemy pozostać przy samych potencjometrach np. zamontowanych na płytce stykowej. Jednak w przypadku tego robota korzystanie z tego rozwiązania byłoby trudniejsze i mniej wygodne w użytku. Model kinematyczny manipulatora Znając już budowę kontrolera oraz manipulatora, należy je już tylko do siebie podłączyć. Oprócz tego do układu dodane zostaną przyciski nagrywania oraz odtwarzania ruchu. Elektronika opiera się o mikrokontroler atmega328p. Zasilanie układu odbywa się z sieci napięciem 230 V. W obudowie znajduje się układ prostujący, przetwornica step-down zasilająca serwomechanizmy oraz płytka arduino ze wspomnianym wcześniej mikrokontrolerem. Dla wygody wszystkie piny arduino zostały wyprowadzone na zewnątrz obudowy. Cały schemat przedstawianej konstrukcji znajduje się poniżej: Schemat układu Lista opisanych komponentów: -S1 – włącznik główny, -S2 – przycisk nagrywania, -S3 – przycisk odtwarzania, -D1 – mostek Graetza 400V ; 4A, -D2 – zielona dioda LED, -C1 – kondensator elektrolityczny 1000µF ; 50V, -C2 – kondensator elektrolityczny 220µF ; 25V, -C3 – kondensator elektrolityczny 22µF ; 25V, -C4 – kondensator ceramiczny 100nF, -C5 – kondensator ceramiczny 22pF, -C6 – kondensator ceramiczny 22pF, -C7 – kondensator ceramiczny 100nF, -R1 – rezystor 150 Ω, -R2, R3, R4 – rezystor 1 kΩ, -POT 1, POT 2, POT 3, POT 4, - 10 kΩ, -Stabilizator napięcia LM7805, -Przetwornica step-down LM2596, -X1 – kwarc 16 MHz, Połączenie układu Po podłączeniu całej elektroniki można przystąpić do omówienia kodu arduino. Program ten został już zaopatrzony w bogatą ilość komentarzy, które na pewno pomogą osobom dopiero rozpoczynającym swoją przygodę z arduino: //biblioteka umożliwiająca nie tylko sterowanie serwami, ale także ich prędkością //nie jest ona koniecznością, wystarczy standardowa biblioteka <servo.h> oraz pozbycie się zmiennej 'predkosc' z koduć #include <VarSpeedServo.h> //definiujemy serwa używane w robocie: VarSpeedServo servo1; VarSpeedServo servo2; VarSpeedServo servo3; VarSpeedServo servo4; //definiujemy przyciski nagrywania i odtwarzania: const int przycisk_A = 2; const int przycisk_B = 3; //definiujemy wartości dla wciśniętych przycisków nagrywania i odtwarzania: int przycisk_A_ON = 0; boolean przycisk_B_ON = false; //definiujemy potencjometry: const int potencjometr1 = A0; const int potencjometr2 = A1; const int potencjometr3 = A2; const int potencjometr4 = A3; //definiujemy zmienne służące do odczytu wartości napięć z potencjometrów: int potencjometr_1_odczyt; int potencjometr_2_odczyt; int potencjometr_3_odczyt; int potencjometr_4_odczyt; //definiujemy zmienne służące do zapisu wartości kąta położenia poszczególnego serwa: int potencjometr_1_zapis; int potencjometr_2_zapis; int potencjometr_3_zapis; int potencjometr_4_zapis; //definiujemy tablice zapisujące położenie serwa: int Pozycja_serva1[]={1,1,1,1,1}; int Pozycja_serva2[]={1,1,1,1,1}; int Pozycja_serva3[]={1,1,1,1,1}; int Pozycja_serva4[]={1,1,1,1,1}; void setup() { //definiujemy piny do których podłączone są serwa: servo1.attach(6); servo2.attach(9); servo3.attach(10); servo4.attach(11); //definiujemy piny wejściowe przycisków nagrywania i odtwarzania: pinMode(przycisk_A, INPUT_PULLUP); pinMode(przycisk_B, INPUT_PULLUP); //inicjalizacja portu szeregowego do podglądu działania programu: Serial.begin(9600); } void loop() { //ustalanie prędkości serw w zakresie od 0 do 180: int predkosc = 90; //zapis formuły umieszczania odczytanej z potencjometrów wartości do tabeli: potencjometr_1_odczyt = analogRead(potencjometr1); potencjometr_1_zapis = map (potencjometr_1_odczyt, 0, 1023, 20, 175); potencjometr_2_odczyt = analogRead(potencjometr2); potencjometr_2_zapis = map (potencjometr_2_odczyt, 0, 1023, 5, 175); potencjometr_3_odczyt = analogRead(potencjometr3); potencjometr_3_zapis = map (potencjometr_3_odczyt, 0, 1023, 5, 175); potencjometr_4_odczyt = analogRead(potencjometr4); potencjometr_4_zapis = map (potencjometr_4_odczyt, 0, 1023, 20, 160); //serwa przyjmują pozycje zapisane w tabelach: servo1.write(potencjometr_1_zapis, predkosc); servo2.write(potencjometr_2_zapis, predkosc); servo3.write(potencjometr_3_zapis, predkosc); servo4.write(potencjometr_4_zapis, predkosc); //przy kolejnym wciśnięciu przycisku nagrywania tabela każdego serwa zostanie //nadpisana, zapamiętując obecną pozycję serwa: if(digitalRead(przycisk_A) == HIGH) { przycisk_A_ON++; switch(przycisk_A_ON) { case 1: Pozycja_serva1[0] = potencjometr_1_zapis; Pozycja_serva2[0] = potencjometr_2_zapis; Pozycja_serva3[0] = potencjometr_3_zapis; Pozycja_serva4[0] = potencjometr_4_zapis; Serial.println("Pozycja pierwsza zapisana"); break; case 2: Pozycja_serva1[1] = potencjometr_1_zapis; Pozycja_serva2[1] = potencjometr_2_zapis; Pozycja_serva3[1] = potencjometr_3_zapis; Pozycja_serva4[1] = potencjometr_4_zapis; Serial.println("Pozycja druga zapisana"); break; case 3: Pozycja_serva1[2] = potencjometr_1_zapis; Pozycja_serva2[2] = potencjometr_2_zapis; Pozycja_serva3[2] = potencjometr_3_zapis; Pozycja_serva4[2] = potencjometr_4_zapis; Serial.println("Pozycja trzecia zapisana"); break; case 4: Pozycja_serva1[3] = potencjometr_1_zapis; Pozycja_serva2[3] = potencjometr_2_zapis; Pozycja_serva3[3] = potencjometr_3_zapis; Pozycja_serva4[3] = potencjometr_4_zapis; Serial.println("Pozycja czwarta zapisana"); break; case 5: Pozycja_serva1[4] = potencjometr_1_zapis; Pozycja_serva2[4] = potencjometr_2_zapis; Pozycja_serva3[4] = potencjometr_3_zapis; Pozycja_serva4[4] = potencjometr_4_zapis; Serial.println("Pozycja piąta zapisana"); break; } } //po wciśnięciu przycisku odtwarzania serwa będą przyjmować zapisane w tabelach pozycje //z odczekaniem 1.5 sekund w każdej pozycji: if(digitalRead(przycisk_B) == HIGH) { przycisk_B_ON = true; } if(przycisk_B_ON) { for(int i=0; i<5; i++) { servo1.write(Pozycja_serva1[i],predkosc); servo2.write(Pozycja_serva2[i],predkosc); servo3.write(Pozycja_serva3[i],predkosc); servo4.write(Pozycja_serva4[i],predkosc); Serial.println("Odtwórz ruchy"); delay(1500); } } //czas opóźnienia działania programu, od jego nastawy zależy płynnośc pracy robota: delay(200); } Program działa w sposób następujący: Po uruchomieniu programu, za pomocą modelu kinematycznego będzie można bezpośrednio kontrolować ruch manipulatora, Jeżeli wciśniemy przycisk S2 (nagrywania), obecnie ustawiona pozycja robota zostanie zapisana, Program umożliwia zapisanie pięciu różnych pozycji, Jeżeli wybierzemy przycisk S3 (odtwarzania), robot zacznie odtwarzać wybrane przez nas pozycje w nieskończonej pętli, Aby wytyczyć nową sekwencję ruchów należy zresetować układ. Efekt działania powyższego kodu przedstawia się następująco: Dzięki funkcji monitora szeregowego w arduino można obserwować pracę manipulatora bezpośrednio: Przepraszam wszystkich czytelników za jakość nagrań wideo, niestety ograniczały mnie możliwości sprzętowe. Przedstawiony wyżej kod jest prosty a przykład nieskomplikowany, jednak doskonale pokazuje podstawy działania tej metody. Nie mniej jednak mam nadzieję, że artykuł okaże się dla wielu osób pomocny. Oprócz tego zostawiam jeszcze bibliotekę <VarSpeedServo> VarSpeedServo-master.zip Powodzenia we wszelkich przyszłych projektach i przygodach z elektroniką!





- 2 odpowiedzi
-
- 3
-
-
- Robotyka
- Elektronika
- (i 3 więcej)
-
 Przetworniki analogowo-cyfrowe i cyfrowo-analgowe, Budujemy własny przetwornik ADC, metoda sukcesywnej aproksymacji - Część 3 W tym artykule poznasz najprostszy przetwornik analogow-cyfrowy, który jest bardzo szybki, ale daje wyniki o dość sporym błędzie, ale o tym w dalszej części artykułu. Ten wpis brał udział konkursie na najlepszy artykuł o elektronice lub programowaniu. Sprawdź wyniki oraz listę wszystkich prac » Partnerem tej edycji konkursu (marzec 2020) był popularny producent obwodów drukowanych, firma PCBWay. Spis treści serii artykułów: Wstęp Budujemy przetwornik cyfrowo-analogowy Budujemy przetwornik analogowo-cyfrowy, metoda sukcesywnej aproksymacji (ten artykuł) 1. Wstęp Przetwornik analogow-cyfrowy (zwany również ADC – Analog Digital Converter) jest układem który zamienia określone napięcie mierzone na ciąg 0 i 1 zwanych postacią binarną / liczbę (wartość cyfrową), proporcjonalną do napięcia mierzonego. W tym artykule poznasz przetwornik ADC który wykonuje pomiary za pomocą metody sukcesywnej aproksymacji (lub inaczej zwana metodą kompensacji wagowej). Wykonuje on odwrotną konwersję w stosunku do przetwornika cyfrowo-analogowego. Nie bez powodu 1 artykułem na temat przetworników był przetwornik cyfrowo-analogowy, gdyż jest on wykorzystywany w przetwornikach analogowo-cyfrowych jako źródło odniesienia. 2. Działanie przetwornika analogowo-cyfrowego. Działanie tego przetwornika polega na równoważeniu napięcia wejściowego z napięciem generowanym za pomocą przetwornika cyfrowo-analogowego, który próbuje kompensować/równoważyć napięcie mierzone. Układ dąży do jak najmniejszej różnicy pomiędzy napięciem mierzonym a generowanym (przez przetworonik cyfrowo-analogowy), tak by różnica Um – Ug = 0. W praktyce nie da się osiągnąć wartości 0 ze względu na skończoną rozdzielczość przetwornika. Schemat blokowy takiego układu wygląda następująco: W tym przetworniku napięcie mierzone jest porównywane z napięciem odniesienia, generowanego przez DAC, zwiększanym kolejno o wartości wagowe Um/2, Um/4, Um/8 itd. Um/n. Jeżeli napięcie wejściowe Uwe jest większe od kolejnych wartości wagowych to dany bit ustawiany jest na 1, w przeciwnym wypadku, gdy napięcie mierzone jest mniejsze od generowanego, to bit ustawiany jest na 0. Poniżej schemat przebiegu procesu przetwarzania. Przykład przebiegu przetwornica przetwornika ADC z sukcesywną aproksymacją. Pozioma linia oznacza poziom napięcia mierzonego. Układ dąży do zrównania się obu lini. 3. Budujemy przetwornik analogowo-cyfrowy z sukcesywną aproksymacją. Jak zostało wspomniane w poprzedniej części kursu, do budowy tego przetwornika wykorzystamy budowany poprzednio przetwornik cyfrowo-analogowy (DAC), do wyjścia którego podłączamy komparator, który będzie porównywał napięcie generowane przez DAC z napięciem mierzonym. W naszym przypadku napięcie mierzone możemy płynnie regulować potencjometrem (zamiast potencjometru możemy podłączyć dowolne źródło napięcia, np. baterię). By zbudować przetwornik ADC 8 bitowy potrzebujemy przetwornika DAC również 8-bitowego. Schemat układu, drabinka rezystorów do układ DAC z poprzedniej części kursu. Po prawej stronie główna część przetwornika ADC. Do komparatora należy podłączyć również zasilanie. Wygląd układu po złożeniu, komparator to LM393N (można zastąpić dowolnym), prezentuje się następująco: Przyszła pora na kod program, który wygląda następująco (nie zapomnij zmierzyć napięcia pomiędzy 5V a GND, tz. Uref i wstawić odpowiedni pin do którego podłączyłeś komparator oraz zmierzone napięcie): #define Uref 4.91 /* napięcie referencyjne/zasilania, należy zmierzyć i zmienić by otrzymać prawidłowe wyniki */ #define komparatorPin 12 /* Przy podłączeniu do innego pinu wyjścia komparatora, należy tu zmienić numer pinu na odpowiedni (nie zalecam pinu 13). */ void setup() { // Zastępuj instrukcje pinMode(An, OUTPUT);, ustawia piny na porcie F jako wyjściowe DDRF = B11111111; // Ustawia wszystkie piny portu F na 0, odpowiada digitalWrite(An, 0); PORTF = B000000; // ustawiamy pin komparatora jako wejście pinMode(komparatorPin, INPUT_PULLUP); Serial.begin(9600); } void loop() { // Czekamy aż zostanie przesłane żądanie z komputera. while (Serial.available() > 0) { Serial.read(); uint8_t wynik = pomiar(); // Wykonujemy pomiar i zapisujemy wynik do zmiennej 8-bitowej Serial.println("Wynik:"); Serial.print("BIN: B"); Serial.println(wynik, BIN); Serial.print("DEC: "); float napiecie = (wynik / 255.0) * Uref; // Wyliczamy napięcie Serial.print(napiecie, 3); // i wypisujemy je na port szeregowy. Serial.println("V \n"); } } uint8_t pomiar(){ uint8_t rejestr = 0; for(int i = 7; i >= 0; i--){ // 8 iteracji petli, przetwornik 8-bitowy rejestr |= (1<<i); // Wstawiamy jedynkę na i-te miejsce. PORTF = rejestr; /* ustawiamy wartość na port F, przez co wszystkie piny zmienią stan w zależności od liczby 8-bitowej, port F to piny od A0 do A7 (A7 najbardziej znaczący bit)*/ delay(2); // Czekamy na ustawienie się napiecia, na przetworniku DAC // Jeżeli wyjście komparatora jest w stanie niskim, if(digitalRead(komparatorPin) == LOW){ rejestr &= ~(1<<i); // to zerujemy wstawioną poprzednio jedynkę na odpowiednim bicie. } } PORTF = rejestr; return rejestr; } 4. Przetestujmy naszym przetwornikiem analogowo-cyfrowym By dokonać pomiaru należy otworzyć monitor portu szeregowego i wysłać dowolny znak do mikrokontrolera, następnie zostanie wyświetlony wynik pomiaru. Wysyłając kilka znaków zostanie wykonane kilka pomiarów, np. wysyłając 3 znaki otrzymamy 3 wyniki. Kod lekko poprawiony, teraz pokazują się 3 miejsca po przecinku, co zwiększa dokładność. Przykład otrzymanych wiadomości, pionowa linia oznacza kilka pomiarów pod rząd (wysłane kilka znaków), Uz to napięcie rzeczywiste zmierzone za pomocą multimetru Pomiar napięcia 2,76V ustawionego za pomocą potencjometru, w wiadomościach wyżej program pokazał napięcie 2,78V. Pomiar napięcia na akumulatorku, podłączamy go do masy (-) i zamiast potencjometru (+). Program pokazał napięcie 1,33V, jednak zachęcam do samodzielnego testu i sprawdzanie wyników z większą liczbą miejsc po przecinku. 5. Zastosowania Przetwornik tego typu jest używany w układach gdzie wymagana jest wysoka szybkość wykonywania pomiarów, ale przez co są one niższej rozdzielczości. Używany w układach gdzie sygnał wejściowy się nie zmienia podczas procesu próbkowania (n cyklowego, n to ilość bitów, tz. rozdzielczość). Można go wykorzystać do budowy układów, gdzie będzie wykonywał wiele pomiarów na sekundę, jednak będą one obarczone dużym błędem. Przetwornik zbudowany na podstawie metody sukcesywnej aproksymacji wykorzystuje się do budowy podstawowych wolnych oscyloskopów, Układ nie nadaje się do budowy typowego oscyloskopu który można kupić w sklepach (przy tego typu konstrukcjach wykorzystuje się przetwornik typu FLASH, który jest niezależny od zmian napięcia mierzonego). 6. Podsumowanie Przetwornik zbudowany na podstawie metody kompensacji wagowej (sukcesywnej aproksymacji) jest prostym do wykonania przetwornikiem który daje w miarę dobre wyniki przy dużej szybkości działać, może wykonywać wiele pomiarów na sekundę. W przetworniku tego typu, należy pilnować by napięcie wejściowe nie uległo zmianie przez cały okres przetwarzania sygnału. Układ nie jest odporny na zmiany napięcia wejściowego i daje błędne wyniki przy tego typu zmianach. W załączniku kod programu wraz ze schematami. plikiADC_sa.rar Spis treści serii artykułów: Wstęp Budujemy przetwornik cyfrowo-analogowy Budujemy przetwornik analogowo-cyfrowy, metoda sukcesywnej aproksymacji (ten artykuł)
Przetworniki analogowo-cyfrowe i cyfrowo-analgowe, Budujemy własny przetwornik ADC, metoda sukcesywnej aproksymacji - Część 3 W tym artykule poznasz najprostszy przetwornik analogow-cyfrowy, który jest bardzo szybki, ale daje wyniki o dość sporym błędzie, ale o tym w dalszej części artykułu. Ten wpis brał udział konkursie na najlepszy artykuł o elektronice lub programowaniu. Sprawdź wyniki oraz listę wszystkich prac » Partnerem tej edycji konkursu (marzec 2020) był popularny producent obwodów drukowanych, firma PCBWay. Spis treści serii artykułów: Wstęp Budujemy przetwornik cyfrowo-analogowy Budujemy przetwornik analogowo-cyfrowy, metoda sukcesywnej aproksymacji (ten artykuł) 1. Wstęp Przetwornik analogow-cyfrowy (zwany również ADC – Analog Digital Converter) jest układem który zamienia określone napięcie mierzone na ciąg 0 i 1 zwanych postacią binarną / liczbę (wartość cyfrową), proporcjonalną do napięcia mierzonego. W tym artykule poznasz przetwornik ADC który wykonuje pomiary za pomocą metody sukcesywnej aproksymacji (lub inaczej zwana metodą kompensacji wagowej). Wykonuje on odwrotną konwersję w stosunku do przetwornika cyfrowo-analogowego. Nie bez powodu 1 artykułem na temat przetworników był przetwornik cyfrowo-analogowy, gdyż jest on wykorzystywany w przetwornikach analogowo-cyfrowych jako źródło odniesienia. 2. Działanie przetwornika analogowo-cyfrowego. Działanie tego przetwornika polega na równoważeniu napięcia wejściowego z napięciem generowanym za pomocą przetwornika cyfrowo-analogowego, który próbuje kompensować/równoważyć napięcie mierzone. Układ dąży do jak najmniejszej różnicy pomiędzy napięciem mierzonym a generowanym (przez przetworonik cyfrowo-analogowy), tak by różnica Um – Ug = 0. W praktyce nie da się osiągnąć wartości 0 ze względu na skończoną rozdzielczość przetwornika. Schemat blokowy takiego układu wygląda następująco: W tym przetworniku napięcie mierzone jest porównywane z napięciem odniesienia, generowanego przez DAC, zwiększanym kolejno o wartości wagowe Um/2, Um/4, Um/8 itd. Um/n. Jeżeli napięcie wejściowe Uwe jest większe od kolejnych wartości wagowych to dany bit ustawiany jest na 1, w przeciwnym wypadku, gdy napięcie mierzone jest mniejsze od generowanego, to bit ustawiany jest na 0. Poniżej schemat przebiegu procesu przetwarzania. Przykład przebiegu przetwornica przetwornika ADC z sukcesywną aproksymacją. Pozioma linia oznacza poziom napięcia mierzonego. Układ dąży do zrównania się obu lini. 3. Budujemy przetwornik analogowo-cyfrowy z sukcesywną aproksymacją. Jak zostało wspomniane w poprzedniej części kursu, do budowy tego przetwornika wykorzystamy budowany poprzednio przetwornik cyfrowo-analogowy (DAC), do wyjścia którego podłączamy komparator, który będzie porównywał napięcie generowane przez DAC z napięciem mierzonym. W naszym przypadku napięcie mierzone możemy płynnie regulować potencjometrem (zamiast potencjometru możemy podłączyć dowolne źródło napięcia, np. baterię). By zbudować przetwornik ADC 8 bitowy potrzebujemy przetwornika DAC również 8-bitowego. Schemat układu, drabinka rezystorów do układ DAC z poprzedniej części kursu. Po prawej stronie główna część przetwornika ADC. Do komparatora należy podłączyć również zasilanie. Wygląd układu po złożeniu, komparator to LM393N (można zastąpić dowolnym), prezentuje się następująco: Przyszła pora na kod program, który wygląda następująco (nie zapomnij zmierzyć napięcia pomiędzy 5V a GND, tz. Uref i wstawić odpowiedni pin do którego podłączyłeś komparator oraz zmierzone napięcie): #define Uref 4.91 /* napięcie referencyjne/zasilania, należy zmierzyć i zmienić by otrzymać prawidłowe wyniki */ #define komparatorPin 12 /* Przy podłączeniu do innego pinu wyjścia komparatora, należy tu zmienić numer pinu na odpowiedni (nie zalecam pinu 13). */ void setup() { // Zastępuj instrukcje pinMode(An, OUTPUT);, ustawia piny na porcie F jako wyjściowe DDRF = B11111111; // Ustawia wszystkie piny portu F na 0, odpowiada digitalWrite(An, 0); PORTF = B000000; // ustawiamy pin komparatora jako wejście pinMode(komparatorPin, INPUT_PULLUP); Serial.begin(9600); } void loop() { // Czekamy aż zostanie przesłane żądanie z komputera. while (Serial.available() > 0) { Serial.read(); uint8_t wynik = pomiar(); // Wykonujemy pomiar i zapisujemy wynik do zmiennej 8-bitowej Serial.println("Wynik:"); Serial.print("BIN: B"); Serial.println(wynik, BIN); Serial.print("DEC: "); float napiecie = (wynik / 255.0) * Uref; // Wyliczamy napięcie Serial.print(napiecie, 3); // i wypisujemy je na port szeregowy. Serial.println("V \n"); } } uint8_t pomiar(){ uint8_t rejestr = 0; for(int i = 7; i >= 0; i--){ // 8 iteracji petli, przetwornik 8-bitowy rejestr |= (1<<i); // Wstawiamy jedynkę na i-te miejsce. PORTF = rejestr; /* ustawiamy wartość na port F, przez co wszystkie piny zmienią stan w zależności od liczby 8-bitowej, port F to piny od A0 do A7 (A7 najbardziej znaczący bit)*/ delay(2); // Czekamy na ustawienie się napiecia, na przetworniku DAC // Jeżeli wyjście komparatora jest w stanie niskim, if(digitalRead(komparatorPin) == LOW){ rejestr &= ~(1<<i); // to zerujemy wstawioną poprzednio jedynkę na odpowiednim bicie. } } PORTF = rejestr; return rejestr; } 4. Przetestujmy naszym przetwornikiem analogowo-cyfrowym By dokonać pomiaru należy otworzyć monitor portu szeregowego i wysłać dowolny znak do mikrokontrolera, następnie zostanie wyświetlony wynik pomiaru. Wysyłając kilka znaków zostanie wykonane kilka pomiarów, np. wysyłając 3 znaki otrzymamy 3 wyniki. Kod lekko poprawiony, teraz pokazują się 3 miejsca po przecinku, co zwiększa dokładność. Przykład otrzymanych wiadomości, pionowa linia oznacza kilka pomiarów pod rząd (wysłane kilka znaków), Uz to napięcie rzeczywiste zmierzone za pomocą multimetru Pomiar napięcia 2,76V ustawionego za pomocą potencjometru, w wiadomościach wyżej program pokazał napięcie 2,78V. Pomiar napięcia na akumulatorku, podłączamy go do masy (-) i zamiast potencjometru (+). Program pokazał napięcie 1,33V, jednak zachęcam do samodzielnego testu i sprawdzanie wyników z większą liczbą miejsc po przecinku. 5. Zastosowania Przetwornik tego typu jest używany w układach gdzie wymagana jest wysoka szybkość wykonywania pomiarów, ale przez co są one niższej rozdzielczości. Używany w układach gdzie sygnał wejściowy się nie zmienia podczas procesu próbkowania (n cyklowego, n to ilość bitów, tz. rozdzielczość). Można go wykorzystać do budowy układów, gdzie będzie wykonywał wiele pomiarów na sekundę, jednak będą one obarczone dużym błędem. Przetwornik zbudowany na podstawie metody sukcesywnej aproksymacji wykorzystuje się do budowy podstawowych wolnych oscyloskopów, Układ nie nadaje się do budowy typowego oscyloskopu który można kupić w sklepach (przy tego typu konstrukcjach wykorzystuje się przetwornik typu FLASH, który jest niezależny od zmian napięcia mierzonego). 6. Podsumowanie Przetwornik zbudowany na podstawie metody kompensacji wagowej (sukcesywnej aproksymacji) jest prostym do wykonania przetwornikiem który daje w miarę dobre wyniki przy dużej szybkości działać, może wykonywać wiele pomiarów na sekundę. W przetworniku tego typu, należy pilnować by napięcie wejściowe nie uległo zmianie przez cały okres przetwarzania sygnału. Układ nie jest odporny na zmiany napięcia wejściowego i daje błędne wyniki przy tego typu zmianach. W załączniku kod programu wraz ze schematami. plikiADC_sa.rar Spis treści serii artykułów: Wstęp Budujemy przetwornik cyfrowo-analogowy Budujemy przetwornik analogowo-cyfrowy, metoda sukcesywnej aproksymacji (ten artykuł)







-
Przetworniki analogowo-cyfrowe i cyfrowo-analogowe. Wstęp Ten artykuł jest wstępem teoretycznym do następnych, praktycznych już artykułów na temat przetworników. Tą serię artykułów, należy brać jako ciekawostkę, gdyż układy którymi się posługujemy (mikrokontrolery AVR, Arduino, ARM) posiadają w swojej budowie przetworniki ADC i bardziej rozbudowane modele posiadają również przetwornik DAC. Ta seria ma za zadanie pokazania budowy wewnętrznej przetworników i ich zasady działania. Ten wpis brał udział konkursie na najlepszy artykuł o elektronice lub programowaniu. Sprawdź wyniki oraz listę wszystkich prac » Partnerem tej edycji konkursu (marzec 2020) był popularny producent obwodów drukowanych, firma PCBWay. Spis treści serii artykułów: Wstęp (ten artykuł) Budujemy przetwornik cyfrowo-analogowy Budujemy przetwornik analogowo-cyfrowy, metoda sukcesywnej aproksymacji 1. Czym właściwie jest przetwarzanie sygnałów? W świecie rzeczywistym (analogowy) występuje wiele różnych wielkości fizycznych, takich jak temperatura, wilgotność, napięcie, natężenie prądu, natężenie światła i wiele więcej, natomiast w świecie komputerów (cyfrowym) występują tylko liczby. Do konwersji tych wielkości pomiędzy 2 światami służą przetworniki, odpowiednio: analogowo-cyfrowy (napięcie jest zamieniane na liczbę, w przypadku gdy chcemy zamienić inną wielkość to musimy najpierw ją przekonwertować w napięcie o odpowiednich proporcjach) cyfrowo-analogowy (zamienia liczby w napięcia, a później można zamienić napięcie w inną wielkość fizyczną) Odwrotnością przetwornika analogowo-cyfrowego jest przetwornik cyfrowo-analogowy, który dokonuje odwrotnej konwersji. 2. Rodzaje przetworników. przetwornik analgowo-cyfrowy – zwany ADC (Analog Digital Converter), zamienia sygnały analogowe w ich reprezentację liczbową (cyfrową). przetwornik cyfrowo-analogowy – zwany również DAC (Digital Analog Converter) – zamienia liczby (reprezentacja cyfrowa) w sygnały analogowe (napięcie). Jedyną metodą przetwarzania jest precyzyjna drabinka rezystorów o proporcjach R:2R. (szerzej opisany w artykule nr. 1) Główne metody przetwarzania sygnałów przez przetwornika ADC: porównanie bezpośrednie (zwany również flash) przetwornik z sukcesywną aproksymacją (metoda zwana również jako metoda kompensacji wagowej) – porównuje napięcie z kolejnymi wagami napięcia generowanym przez przetwornik DAC (dokładniej opisany w artykule nr. 2), nie odporny na zmianę napięcia mierzonego (daje błędne wyniki). przetwornik z podwójnym całkowaniem – mierzy czas ładowania kondensatora, napięciem mierzony i rozładowywania napięciem referencyjnym (niestety z powodu braku elementów nie byłem w stanie go szybko zbudować), uśrednia napięcie mierzone (jeżeli się zmienia). Przetwornik ADC w postaci układu scalonego, do budowy oscyloskopu, wykorzystuje metodę sukcesywnej aproksymacji (układ AD7492) Tabela porównująca właściwości przetworników analogowo-cyfrowych: Zależność pomiędzy szybkością wykonywania pomiarów (w samplach na sekundę) a ich rozdzielczością (w bitach). Elipsami oznaczone poszczególne główne metody dla przetworników ADC. Sygnał wejściowy nie jest idealnie przekształcany na sygnał cyfrowy z powodu skończonej ilości porównań sygnału. Porównanie sygnału wejściowego (siwego), z sygnałem cyfrowym (czerwonym). Jak widać sygnał cyfrowy nie pokrywają się idealnie z sygnałem analogowym, ale w miarę możliwości przybliża go. 3. Zastosowania w praktyce przetworników. Oscyloskop, przetwornik ADC z sukcesywną aproksymacją i generator DAC. Mierniki uniwersalne, przetwornik ADC, metoda podwójnego całkowania. Uśrednia wyniki przy zmieniającym się sygnale wejściowym. Przykład wykorzystania w cyfrowym systemach audio, gdzie sygnał analogowy (z mikrofonów i instrumentów) trafia do przetwornika ADC, który przetwarza sygnał wejściowy i przekształca na wersję bitową (cyfrową), na którą można nakładać efekty (jak w komputerze). Następnie sygnał trafia do przetwornika DAC, który generuje sygnał audio z liczb i przez wzmacniacz trafia on do głośników. 4. Podsumowanie Był to krótki wstęp do poszczególnych artykułów pokazujący zależności pomiędzy różnymi metodami przetwarzania przez przetworniki. Do budowy wszystkich przetworników użyję Arduino Mega. Zaznaczam że tą serię należy traktować jako ciekawostkę, gdyż większość mikrokontrolerów posiada wbudowany przetwornik ADC, a przetwornik DAC jest wbudowany w większe układy i jest rzadko używany (głównie do audio). Spis treści serii artykułów: Wstęp (ten artykuł) Budujemy przetwornik cyfrowo-analogowy Budujemy przetwornik analogowo-cyfrowy, metoda sukcesywnej aproksymacji









-
Przetworniki analogowo-cyfrowe i cyfrowo-analogowe. Budujemy własny przetwornik DAC. Na początku naszą przygodę z przetwornikami, powinniśmy zacząć od układu przetwornika cyfrowo-analogowego, gdyż kolejne układy przetwornikowe (ADC) korzystają z tego najprostszego rodzaju konwertera. Ten wpis brał udział konkursie na najlepszy artykuł o elektronice lub programowaniu. Sprawdź wyniki oraz listę wszystkich prac » Partnerem tej edycji konkursu (marzec 2020) był popularny producent obwodów drukowanych, firma PCBWay. Spis treści serii artykułów: Wstęp Budujemy przetwornik cyfrowo-analogowy (ten artykuł) Budujemy przetwornik analogowo-cyfrowy, metoda sukcesywnej aproksymacji 1. Wstęp Przetwornik cyfrowo-analogowy (zwany również DAC – od angielskiego: Digital Analog Conwerter) jest układem zamieniającym wartość liczbową (wartość liczbową) na określoną wartość napięcia (wartość analogową), proporcjonalną do liczby. W tym wpisie zajmiemy się przetwornikami równoległymi DAC, gdyż te są najczęściej stosowane i najprostsze w budowie. Wykonuje on odwrotną konwersję w stosunku do przetwornika analogowo-cyfrowego. 2. Jak właściwie działa konwersja z wartości cyfrowej na analogową. Przetwornik ten konwertuje liczbę n bitową w odpowiadające jej napięcie elektryczne. Napięcie wyjściowe przetwornika proporcjonalne jest do napięcia odniesienia i liczby zapisanej w systemie dwójkowym (dokładniej poszczególnych bitów tej liczby). Wzór na obliczenie napięcia wyjściowego: Gdzie: Uwy – napięcie wyjściowe, Uref – napięcie referencyjne (dla Arduino ok. 5V, w zależności od napięcia zasilania) n – ilość bitów wartości cyfrowej a0 do an – wartość bitowa 0 lub 1, odpowiadająca kolejnym bitom sygnału cyfrowego (liczby), a0 najbardziej znaczący bit (MSB), an – najmniej znaczący bit (LSB) Może wydawać się to skomplikowane, jednak takie nie jest. Pierwszy bit oznacza 1/2 napięcia referencyjnego, 2 oznacza 1/4 (połowę poprzedniego) Uref itd. 3. Budowa teoretyczna przetwornika cyfrowo-analogowego. Sercem przetwornika jest drabinka rezystorów, będących ze sobą w stosunku 1R do 2R (np. 1k do 2k itp.). Na wejście przetwornika podajemy liczbę w postaci binarnej, o n bitach (im większa ilość n, tym większa rozdzielczość przetwornika). Układ posiada 1 wyjście analogowe. Schemat najczęściej stosowanego przetwornika o rozdzielczości 8 bitów, przedstawia się następująco: Przykład budowy drabinki rezystorów 8 bitowego przetwornika DAC (wartość pod lub po prawej stronie to wartość rezystancji). Poziome rezystory o wartości R, pionowe o wartości 2R. Spróbujmy obliczyć wartość napięcia dla wartości 193 8-bitowej (o 256 wartościach). Liczba ta zapisana binarnie B11000001. Możemy podstawić do powyższego wzory, jednak jeżeli posiadamy wartość w systemie dziesiętnym (193) to możemy obliczyć w prostszy sposób: Uwy = wartość/rozdzielczość * Uref, w naszym przypadku Uwy = 5V * 193/255, co daje nam napięcie około 3,78V. Przykład podstawienia do wzoru: Gdy bit jest 1 zostaje podłączony do napięcia zasilania, gdy 0 do masy (co jest bardzo ważne, niepodłączony da błędne wyniki na wyjściu). Rozpływ prądów pokazany poniżej: 4. Budujemy naszego DAC'a. Do budowy prototypu przetwornika cyfrowo-analogowego, użyję Arduino MEGA, skorzystamy z powyższego schematu. Rezystory o wartości 2R będą mieć 2,2k, natomiast R będą to 2 połączone rezystory o wartościach 10k i 1,2k (co daje około 1080 omów, jednak powinno być 1,1k). Magistralę danych (8 bitów) podłączamy do portu F arduino mega(wybieramy 1 port, 8 pinów ułożonych w kolejności, dla prostszego programu), a dla uno port C. Porty analogowe są ułożone w odpowiedniej kolejności, oczywiście my używamy ich jako cyfrowe. W naszym przypadku zbudujemy prosty przetwornik ośmiobitowy. Kod programu do ustawiania napięcia na wyjściu przetwornika i obliczanie oczekiwanego napięcia, wygląda nastepująco: // Zastępuj instrukcje pinMode(An, OUTPUT);, ustawia piny na porcie F jako wyjściowe DDRF = B11111111; // Ustawia wszystkie piny portu F na 0, odpowiada digitalWrite(An, 0); PORTF = B000000; // Komunikacja z komputerem Serial.begin(9600); Serial.print("Podaj wartosc: "); } uint8_t wartosc = 0; void loop() { // Czekamy aż zostanie przesłana wartość z komputera. while (Serial.available() > 0) { wartosc = Serial.parseInt(); // Zamieniamy ciag bajtów na wartość 8 bitową Serial.println(wartosc); Serial.print("Ustawiona wartosc napiecia wynosi "); float napiecie = (wartosc / 255.0) * Uref; // Wyliczamy oczekiwane napiecie Serial.print(napiecie, 3); // i wypisujemy je na port szeregowy. Serial.println("V"); Serial.print("Podaj wartosc: "); PORTF = wartosc; /* ustawiamy wartość na port F, przez co wszystkie piny zmienią stan w zależności od liczby 8-bitowej, port F to piny od A0 do A7 (A7 najbardziej znaczący bit)*/ } } 5. Sprawdzenie poprawności działania, pomiary. Wchodzimy w monitor portu szeregowego i podajemy wartość dziesiętną (od 0 do 255) lub można w postaci binarnej poprzedzając, ciąg 8 zer lub jedynek, duża literą B. Mikrokontroler zwraca oczekiwaną wartość napięcia, którą należy zmierzyć w układzie by porównać błąd przetwornika DAC. Pomiar napięcia rzeczywistego dla ustawionego napięcia 2,46V (wartość 128). 2 pomiar napięcia rzeczywistego dla ustawionego napięcia 0.98V (wartość 51). Przykład komunikatów do powyższych pomiarów, w polu do wysyłania przykład wpisanej liczby w systemie binarnym. 6. Dokładność przetwornika cyfrowo-analogowego. Rezystory użyte przy budowie przetwornika DAC mają swoją określoną tolerancję w moim przypadku 5%, przez co niektóre rezystory mają lekko różne wartości co powoduje nierównomierny rozpływ prądu i lekko odmienne napięcie na wyjściu od oczekiwanego. Jeżeli chcemy uzyskać jak najlepsze wyniki musimy używać rezystorów o jak najmniejszej tolerancji (najczęściej jest to 1%) i zapewnić stabilne źródło zasilania. Mierząc rzeczywistą rezystancję rezystora 2,2k, o tolerancji 5%, otrzymujemy 2,16k (Rezystancja zaniżona o 40 omów). 7. Poprawiamy przetwornik cyfrowo-analogowy Ustawiamy połowę napięcia referencyjnego (wartość 128, Uref = 4.91) i podłączamy do układu obciążenie w postaci opornika 10k i teoretycznie powinniśmy otrzymać około 2,45V (połowę napięcia referencyjnego), ale ... Wynik powinien wyjść około 2,45V, a jednak otrzymujemy 2,19V. Przetwornik daje na wyjściu oczekiwane wartości napięcia, jednak gdy podłączymy obciążenie do układu (np. rezystor o wartości 10k), zauważymy że napięcie bardzo mocno spadło, z powodu słabej wydajności prądowej układu, aby temu zaradzić trzeba wzmocnić napięcie przy wykorzystaniu wzmacniacza operacyjnego, który zwiększy wydajność prądową naszego własnego przetwornika cyfrowo-analogowego. Schemat takiego układu wygląda następująco: Schemat przetwornika DAC z wzmacniaczem operacyjnym, rezystor R17 ma rezystancję 2 razy mniejszą od R (R/2). 8. Zastosowania Układy pomiarowe (generator wzorcowy, konwersja wartości cyfrowych na napięcie) Układy audio (karty dźwiękowe, generowanie dźwięku wyjściowego dla słuchawek lub głośników) Sprzęt wideo (analogowa transmisja sygnału video np. VGA) 9. Podsumowanie Budowa przetwornika analogowo-cyfrowego jest bardzo prosta, jednak uzyskanie dokładnych wyników jest bardzo ciężkie. Przetwornik DAC jest podstawą działania przyrządów pomiarowych i przetworników ADC, które dokonują odwrotnej konwersji w stosunku do przetwornika cyfrowo-analogowego. W dalszych częściach artykułu poznasz budowę i działanie przetworników analogowo-cyfrowych w których będziemy wykorzystywać przed chwilą poznany przetwornik. W załączniku kod programu wraz ze schematami. DAC_pliki.rar Spis treści serii artykułów: Wstęp Budujemy przetwornik cyfrowo-analogowy (ten artykuł) Budujemy przetwornik analogowo-cyfrowy, metoda sukcesywnej aproksymacji











- 1 odpowiedź
-
- 4
-
-
- Przetwornik
- budowa
- (i 2 więcej)
-
Hexapod w V-REP. Import i konfiguracja modelu. W niniejszym artykule opisany został proces importu i konfiguracji własnego modelu robota kroczącego do programu symulacyjnego V-REP. Virtual Robot Evaluation Platform (V-REP) jest środowiskiem programistycznym służącym do symulacji robotów. Jeśli dysponujesz modelami swojego robota, dobrałeś napędy i czujniki, ale masz wątpliwości czy wszystko zadziała jak należy to V-REP może znacznie ułatwić Ci pracę. Ze względu na mnogość rozwiązań i przykładów z zakresu robotów stacjonarnych, chciałbym skupić się na opisie przygotowania modelu robota kroczącego do symulacji. V-REP dostarcza środowisko edytorskie, w którym użytkownik może tworzyć własne modele robotów. Niestety dostarczany interfejs jest bardzo nieefektywny. Prostszym i mniej czasochłonnym rozwiązaniem jest import gotowego modelu z innego programu edytorskiego. Możemy dodawać obiekty zapisane w plikach *.dxf, *.obj, *.stl oraz *.3ds. Interfejs graficzny programu V-REP Import modelu z innego edytora 3D Modele, które posłużyły w tym przykładzie utworzono w programie AutodeskInventor 2020. Program ten umożliwia łatwy eksport części czy całego złożenia do dowolnego formatu obsługiwanego przez V-REP za wyjątkiem formatu *.3ds. W celu importu modelu (najlepiej importować złożenie) korzystamy z paska menu -> File -> Import -> Mesh… Model robota w programie Inventor (po lewej) oraz V-REP (po prawej) Po imporcie złożenia do symulatora łatwo zauważyć, że model stanowi jedną bryłę zamiast oddzielnych elementów robota. Należy taką bryłę odpowiednio pogrupować (klikamy pasek menu -> Edit -> Grouping/Merging -> Divide selected shapes), pamiętając o wcześniejszym zaznaczeniu naszego modelu. W wyniku takiej operacji pojawia się znacznie więcej elementów niż jest to pożądane. Dlatego też należy połączyć z powrotem części, które mają stanowić zespoły nieprzemieszczające się względem siebie (Edit -> Grouping/Merging -> Merge selected shapes). Przed przystąpieniem do grupowania, warto usunąć części, które powtarzają się wielokrotnie, w tym przypadku są to nogi robota. Do konfiguracji działania modelu w symulatorze wystarczy nam tylko jedna lub dwie nogi (w moim przypadku zostawiłem dwie nogi ponieważ miałem wykonane dwa typy nóg, jeśli się przyjrzycie, dostrzeżecie różnicę ). Model podzielony na poszczególne elementy oraz usunięty nadmiar części Tak przygotowany model gotowy jest do powielenia. Kopiujemy model do nowej sceny w celu uproszczenia go i nadania jego elementom właściwości obiektów dynamicznych. W celu uproszczenia części w tym przykładzie wykorzystano konwersję zaimportowanego modelu do postaci prostych kształtów (Edit -> Morph selection into convex shapes). Kształty takie (bryły) reprezentowane są przez trójkąty opisujące ich powierzchnię (MES). Liczba elementów skończonych rzutuje na złożoność obliczeń, dlatego należy starać się uzyskać jak najmniejszą ich liczbę przy zachowaniu zarysu kształtów oryginalnych części. Warstwa modeli dynamicznych konstrukcji jest niewidoczna podczas symulacji. Model dynamiczny części (po prawej) – przełączanie pomiędzy warstwami Przeguby Aby umożliwić ruch odpowiednim częściom robota, wprowadzamy do układu przeguby. W tym celu należy wybieramy z paska menu -> Add -> Joint -> Revolute. Następnie, po zaznaczeniu przegubu, korzystając z narzędzi Position oraz Orientation ustawiamy przegub w pożądanym miejscu (rysunek powyżej, na modelu po lewej widoczne są pomarańczowe przeguby). Operację tą wykonujemy dla kolejnych przegubów nogi. Dzięki usunięciu „nadmiarowych” nóg oszczędzamy mnóstwo czasu w tym momencie – tworzymy jedynie 3 lub 6 przegubów zamiast wszystkich 18. Elementy te symulują działanie napędów robota, dlatego istotne jest ustawienie odpowiedniego momentu obrotowego. Można to uzyskać korzystając z obliczeń lub doświadczalnie – wszystko zależy od przeznaczenia naszego modelu symulacyjnego. Każdemu z przegubów można zaimplementować regulator: Parametr proporcjonalny dostarcza część sygnału sterującego proporcjonalną do błędu pozycji. Im większy jest błąd, tym większy jest sygnał sterujący, wymuszający korekcję położenia. Człon całkujący rośnie z czasem i jest proporcjonalny do sumy błędów. Człon ten minimalizuje (tłumi) błąd jaki powstaje w wyniku stałego obciążenia i powoduje dojście do pozycji zadanej. Ostatni parametr – różniczkujący jest tym większy im większa jest różnica błędu w kolejnych próbkach. Jest więc odpowiedzialny za tłumienie zmian błędu (tłumi oscylacje). Parametry dynamiczne przegubu - napędu Łańcuch kinematyczny Po odpowiednim pogrupowaniu części, stworzeniu ich reprezentacji dynamicznej oraz dodaniu przegubów, musimy utworzyć łańcuch kinematyczny. Dodajemy dwa obiekty typu Dummy – jeden nazwany foot_Tip, drugi foot_Target. Tip jest swego rodzaju TCP (ang. Tool Central Point) nogi podczas Target będzie odpowiadać za docelowe położenia TCP podczas ruchu robota. Stworzono zatem połączenie pomiędzy tymi dwoma obiektami oraz zbudowano drzewo dziedziczenia pomiędzy obiektami reprezentującymi elementy robota. Model ze zdefiniowanym TCP oraz punktem docelowym Następnie dodano nową grupę kinematyczną w celu powiązania punktów ze sobą. Korzystając z okna parametrów kinematyki, dodano element TIP jako końcówkę łańcucha. Od tego momentu w chwili przesunięcia elementu TARGET, element TIP będzie za nim podążać. Na tym etapie konfiguracji modelu można sprawdzić jej poprawność, wyłączając dynamikę w oknie właściwości modułu obliczeniowego. Następnie należy włączyć symulację oraz wybrać i przesunąć obiekt TARGET. Jeśli wszystkie kroki zostały wykonane poprawnie, noga powinna podążać za celem. Definiowanie łańcucha kinematycznego Po wykonaniu powyższych instrukcji powielono przygotowany model nogi. Skopiowane nogi umieszczono w odpowiednich miejscach. Tak przygotowany model jest gotowy do wprawienia w ruch za pomocą skryptów napisanych w języku LUA. Model gotowy do implementacji kodu sterującego Skrypty W systemie V-REP każdy skrypt jest identyfikowany z obiektem np. robotem. Wyjątkiem jest skrypt odpowiadający za symulację otoczenia. Takie zastosowanie umożliwia użytkownikowi pełną elastyczność w tworzeniu modeli, korzystania z odczytów sensorów, sterowania przegubami. W efekcie daje to możliwość budowania systemów sterowania i testowania różnych algorytmów sterowania. Przebieg sterowania pomiędzy skryptami w V-REP Skrypt główny (MainScript) uruchamia kolejne skrypty potomne utożsamione z naszymi modelami (ChildScript), które są wykonywane w trybie wątkowym lub bezwątkowym. W trybie wątkowym skrypty te pracują przez cały czas w tle, natomiast bezwątkowe są wywoływane w każdym kroku symulacji, podejmują pewne akcje i kończą swoje działanie. Najszybszym sposobem, na sprawdzenie poprawności wykonania modelu w V-REP jest wykorzystanie skryptów z przykładów dostępnych w programie, np. „hexapod” . Należy jednak zaznaczyć, że skrypty te będą działały jedynie dla hexapodów posiadające trzy stopnie swobody na każdą nogę (skrypty dodałem również w załączniku). Dostępne skrypty obsługują ruch nóg robota względem środka ciężkości oraz ruch modelu w przestrzeni symulatora. Napisane są w języku Lua, który jest opisany między innymi na stronie producenta programu V-REP. Obydwa skrypty wykorzystywane w symulatorze przypisane są do konkretnego elementu (części) robota. W przypadku sterowania nogami jest on przypisany do wizualnej części odpowiadającej za korpus robota. Takie rozwiązanie pozwala na zapewnienie sterowania nogami bez konieczności tworzenia oddzielnych skryptów na każdą nogę z osobna. Należy zaznaczyć również, że sterowanie nogami robota polega na wyznaczeniu kolejnych położeń celu, do którego dana noga ma podążać (hexa_footTarget..i). Konfiguracja modelu w edytorze graficznym pozwala na rozwiązanie odwrotnego zadania kinematyki przez symulator. Układem odniesienia dla trajektorii opisanych w skrypcie jest układ współrzędnych części, do którego ten skrypt jest przypisany. Podczas inicjacji programu/symulacji skrypt odwołuje się do obiektów footTarget, a następnie tworzy listy celów oraz końcówek nóg robota. robotBase=sim.getObjectHandle('hexa_legBase') legTips[i]=sim.getObjectHandle('hexa_footTip'..i-1) legTargets[i]=sim.getObjectHandle('hexa_footTarget'..i-1) Na inicjację składa się również wyzerowanie pozycji bazowej oraz pobranie współrzędnych końcówek nóg. W celu zapewnienia odpowiedniej kolejności przenoszenia nóg podczas danego typu chodu zadeklarowano tablicę indeksów kolejnych nóg robota. Indeks ten jest wykorzystywany w funkcji określającej przesunięcie nóg względem początku układu odniesienia. W funkcji inicjacyjnej ustawiane są też domyślne wartości parametrów chodu takie jak prędkość kroku, wysokość kroku, kierunek ruchu itp.. legMovementIndex={1,4,2,6,3,5} stepProgression=0 stepVelocity=0.5 stepAmplitude=0.16 stepHeight=0.04 movementStrength=1 realMovementStrength=0 movementDirection=0*math.pi/180 rotation=0 Funkcja sysCall_init wykonywana jest tylko raz (podczas pierwszego wywołania skryptu) i odpowiada za przygotowanie symulacji. W tym przypadku wykorzystana jest do nadania parametrów bazowych modelom. Funkcja functionsysCall_actuation() jest wykonywana w każdym momencie działania symulacji podczas fazy sterowania, z częstotliwością ustawioną w programie. Kod zawarty w tej funkcji odpowiada za obsługę wszystkich funkcji sterujących, które zapewnia symulator (kinematyka odwrotna, dynamika itp.). Tutaj znajdują się odwołania do wartości parametrów chodu w czasie rzeczywistym. Zawarta w funkcji functionsysCall_actuation() pętla for odpowiada za ustawienie działania nóg robota w zależności od jej indeksu. Nadając odpowiednie indeksy nogom, zrealizowano ruch trójpodporowy. Ponadto w pętli tej zawarte są obliczenia wyznaczające położenie kolejnych końcówek nóg robota w każdym momencie jego ruchu. Trajektorie wyznaczane są na płaszczyźnie i realizowane są poprzez skręcenie kolejnych przegubów nogi. Zmienna md (ang. movement direction) zawiera informację o aktualnym kierunku ruchu robota, a za pomocą tablicy p przekazywana jest informacja o położeniu punktu docelowego w kolejnych chwilach symulacji. for leg=1,6,1 do sp=(stepProgression+(legMovementIndex[leg]-1)/6) % 1 offset={0,0,0} if (sp<(1/3)) then offset[1]=sp*3*stepAmplitude/2 else if (sp<(1/3+1/6)) then s=sp-1/3 offset[1]=stepAmplitude/2-stepAmplitude*s*6/2 offset[3]=s*6*stepHeight else if (sp<(2/3)) then s=sp-1/3-1/6 offset[1]=-stepAmplitude*s*6/2 offset[3]=(1-s*6)*stepHeight else s=sp-2/3 offset[1]=-stepAmplitude*(1-s*3)/2 end end end md=movementDirection+math.abs(rotation)*math.atan2(initialPos[leg][1]*rotation,-initialPos[leg][2]*rotation) offset2={offset[1]*math.cos(md)*realMovementStrength,offset[1]*math.sin(md)*realMovementStrength,offset[3]*realMovementStrength} p={initialPos[leg][1]+offset2[1],initialPos[leg][2]+offset2[2],initialPos[leg][3]+offset2[3]} sim.setObjectPosition(legTargets[leg],antBase,p) end Skrypt sterujący całym robotem zawiera funkcję odpowiadającą za przekazywanie wartości parametrów takich jak: prędkość chodu, wysokość kroku czy kierunek ruchu. Dodatkowo wykorzystano funkcję moveBody, w której zdefiniowano sekwencje ruchów. W funkcji głównej wywoływana jest ona z odpowiednim indeksem aby uruchomić sekwencję o tym samym indeksie. Do wywoływania danych funkcji służy funkcja sysCall_threadmain(). Część kodu w niej zawarta wykonywana jest w momencie rozpoczęcia danego wątku, aż do jego zakończenia. Wątek może rozpocząć się wraz ze startem symulacji, ale także w trakcie jej działania. Tutaj też pobierane są informacje z interfejsu graficznego o położeniu elementów bazowych układu, określana jest pozycja startowa robota oraz nadane zostają wartości zmiennych. Podsumowanie Powyższy tekst stanowi ogólny opis czynności, które należy wykonać w celu wykonania prostej symulacji w programie V-REP. Na proces ten składa się: Import modelu z edytora 3D oraz przygotowanie poszczególnych członów robota Wykonanie modelu dynamicznego robota wraz z dodaniem przegubów Zdefiniowanie łańcucha kinematyki Implementacja skryptów w celu weryfikacji modelu Tekst ten powstał ze względu na małą popularność opisywanego symulatora oraz jeszcze mniejszą dostępność kompletnych opracowań dotyczących robotów kroczących. Pisząc ten tekst miałem nadzieję na w miarę przystępne nakreślenie procesu modelowania robota w symulatorze, jednak w przypadku chęci praktycznego wykorzystania tych informacji należałoby się zaznajomić z podstawami obsługi V-REP. Dlatego też bardzo docenię każdą sugestię co przydałoby się opisać dokładniej lub gdzie przydałoby się zaprezentować różne podejścia (np. dobór nastaw regulatorów). Dla inspiracji dodam, że na podstawie testów w V-REP udało mi się opracować konstrukcję hexapoda (mam nadzieję że jest choć trochę podobny do tego z artykułu): skrypty.rar


-
Wprowadzenie W artykule zostanie przedstawiony sposób na optymalizację układów mikroprocesorowych pod względem wykorzystania zasilania. Celem jest przedstawienie prostych metod, które nie wymagają znacznych ingerencji w konstruowany układ, a jednocześnie dających wymierne korzyści. Efekty uzyskane na podstawie lektury tego artykułu pozwolą na lepsze zrozumienie konstrukcji procesora w kwestii budowy układu zegarowego. Ten wpis brał udział konkursie na najlepszy artykuł o elektronice lub programowaniu. Sprawdź wyniki oraz listę wszystkich prac » Partnerem tej edycji konkursu (marzec 2020) był popularny producent obwodów drukowanych, firma PCBWay. Zaczynamy na 8 bitach Na potrzeby zobrazowania toku myślenia zostaną wplątane w rozważania losy hipotetycznego młodego człowieka, którego nazwiemy Adam. Adam jest młodym elektronikiem, z pewnością przyszłym inżynierem, który od swoich rówieśników słyszał, że oni projektują, programują i uruchamiają. Adam zasięgnął informacji o co tu chodzi. Zakupił płytkę Arduino UNO, zasilacz sieciowy i pełen zapału zainstalował środowisko Arduino IDE. Chcąc wiedzieć jak pokierować swoim rozwojem, zapisał się do odpowiedniej grupy dyskusyjnej i zadał pytanie „mam arduino i co mogę na nim zrobić?” . Odpowiedź pełna sarkazmu, którego nie wyczuł, brzmiała: „Zamrugać diodą LED”. Ów młody człowiek znalazł przykład „blink.ino”, wczytał, skompilował i wgrał do płytki. Ku swemu wielkiemu zaskoczeniu na płytce zaczęła migać dioda LED. Z uśmiechem na twarzy, nie wiedząc tak naprawdę co zrobił, stwierdził: „Jestem programistą”. setup(){ pinMode(13, output); } main() { digitalWrite(13, HIGH); dely(1000); digitalWrite(13. LOW); delay(1000); } Rysunek 1. Arduino UNO Na listingu nr 1 znajduje się cały program, napisany w Arduino (zobacz ramkę „Dlaczego Arduino?”), mrugający diodą LED. Czy ten kod jest optymalny? Patrząc z punktu widzenia programisty, który nie wie jak jest zbudowany mikroprocesor: TAK, ten kod jest optymalny. Z punktu widzenia inżyniera, dobrze znającego architekturę wewnętrzną procesora oraz możliwości jakie daje programowanie niskopoziomowe: NIE, ponieważ to co powstanie po kompilacji będzie bardzo nadmiarowe. Prześledźmy co procesor będzie robić: W funkcji setup zostaje skonfigurowany pin nr 13 procesora jako wyjście. Nr 13 to tylko symboliczna nazwa jednego z wyjść płytki Arduino UNO. Nr 13 odnosi się w tym przypadku do PortB.5 procesora. Do tego pinu jest podłączona dioda LED poprzez rezystor o wartości 500 Ohm. W funkcji main, w pierwszej linii pin 13 jest ustawiany w stan wysoki, dioda LED świeci. Następnie, przez 1000 ms, procesor czeka, aż upłynie 1000 ms. Procesor zajmuje się tylko sobą, czekając aż upłynie 1000 ms. Po tym czasie pin 13 ustawiany jest w stan niski, dioda LED gaśnie. I znowu procesor nic innego nie robi, tylko czeka aż upłynie kolejne 1000 ms. I tak na okrągło, przez ponad 99,9% czasu procesor nic nie robi, tylko sprawdza, czy skończyło się 1000 ms. Schemat nr 1. Zobrazowanie podłączenia diody LED na płytce Arduino UNO W czasie oczekiwania na upłynięcie 1000 ms procesor mógłby robić pożyteczniejsze rzeczy niż tylko zajmowanie się samym sobą. Jeżeli już nie damy mu żadnego konkretnego zadania, to niech nic nie robi, dosłownie nic. Młodzi ludzie, tacy jak Adam, mając nikłą wiedzę elektronika, nie zważają na wykorzystanie energii. Podłączają zasilacz sieciowy do Arduino i nie przejmują się ile to zużyje energii. Płytka arduino UNO sama z siebie, bez procesora, pobiera 19,2 mA. Gdy włożymy procesor, który nie był jeszcze zaprogramowany, pobór prądu wzrośnie do 36,7 mA, a podłączona diod LED będzie pobierała kolejne 2,7mA. W tym momencie Adam się relaksuje. Natomiast my zajmiemy się optymalizacją układu, to będzie praca dla inżyniera. Wykorzystamy przy okazji notę katalogową naszego procesora. Optymalizacja W celu optymalizacji zużycia energii możemy zastosować diodę LED, która potrzebuje mniejszy prąd by świecić, możemy zmniejszyć zużycie energii przez procesor, a nawet możemy wymontować zbędne elementy z płytki Arduino UNO. To ostatnie nie jest wskazane, bo płytka ta jeszcze nie raz zostanie zapewne użyta. Z diodą LED jest tak, że została ona wlutowana z rezystorem na płytce i jej wymiana będzie kłopotliwa. Pozostaje nam zoptymalizowanie procesora, zmontowanie układu np. na płytce stykowej. Będziemy potrzebować procesor, rezonator kwarcowy 16MHz, diodę led, kilka rezystorów o różnej wartości, oczywiście płytkę stykową, kabelki, zasilacz, stabilizatory i programator AVR ISP lub dowolny inny pozwalający na programowanie procesora. Schemat nr 2. Podłączenie samego procesora Ale dlaczego prowadzimy takie rozważania? Nie zawsze będziemy mieli obok naszego urządzenia gniazdko zasilania o nieograniczonej energii i napięciu 230V. Wtedy zasilimy nasze urządzenie z baterii lub akumulatora. Co zrobić, żeby urządzenie pracowało nieprzerwanie przez 1 miesiąc? Należy dać taką baterię, która ma odpowiednią pojemność. To prawda. A co zrobić, żeby urządzenie pracowało przez cały rok? Czy należy dać 12 takich baterii? Po dobrej optymalizacji może się okazać, że nie musi to być konieczne. Przeanalizujemy, na przytoczonym wcześniej przykładzie Blink, jak optymalizacja programowa i sprzętowa przyczyni się do zmniejszenia zużycia energii. W tym celu zamiast używać płytki Arduino UNO użyjemy samego procesora Atmega328 i zasilimy go napięciem 6V poprzez stabilizator 5V, a wszystko będziemy montować na płytce stykowej. Pobór prądu w naszym układzie będzie wyglądał jak przebieg prostokątny o wypełnieniu 50%. Dolny poziom prądu będzie odpowiadał stanowi, gdy dioda LED jest zgaszona (poziom L), natomiast poziom górny będzie odpowiadał stanowi, gdy dioda LED świeci (poziom H).Sam procesor pobiera 14.5 mA, a dioda LED 2.7 mA. Będą to dla nas dane odniesienia. Średni prąd pobierany przez układ to 15,8mA. W ciągu doby układ pobierze 380 mAh. Chcąc zasilić układ z baterii 4 x 1.5V (np. AA o pojemności ok 2000 mAh) układ będzie pracować 5dni i 6 godzin. (dla płytki Arduino będzie to 2 dni i 4 godziny). W ten oto prosty sposób wydłużyliśmy czas pracy o ponad 100%. Optymalizacja nr 1: zmieniamy diodę LED na bardziej energooszczędną, zastosujemy inny rezystor. Zastosujemy diodę, która by świecić potrzebuje zaledwie 0,15 mA. W ten sposób zmniejszyliśmy prąd pobierany przez diodę. Czas pracy na baterii wydłuży się do 5 dni i 16 godzin. W ten sposób, niejako w gratisie, otrzymaliśmy 10 godzin pracy w stosunku do układu podstawowego na płytce stykowej oraz 84h w porównaniu do układu na oryginalnym Arduino. Wykres nr 1. Zależność prądu zasilania od napięcia zasilania dla dwóch przykładowych częstotliwości zegara Optymalizacja nr 2: zmniejszamy napięcie zasilania do 4.5 V, czyli wykorzystamy tylko 3 ogniwa AA. Nie używamy w tym momencie już żadnego stabilizatora Zwiększamy wartość rezystora zachowując parametry świecenia diody LED, możemy zauważyć że zmniejszył się prąd pobierany przez procesor. Teraz nasz układ pobiera średnio 11,35 mA i będzie pracował 7 dni i 8 godzin. Optymalizacja nr 3. Przełączymy pracę procesora na wewnętrzny układ zegarowy 8MHz. Wcześniej oczywiście należy zmodyfikować parametr funkcji delay, aby zachować odpowiednią częstotliwość migania diody LED. W tym przypadku, ponieważ zmniejszyliśmy częstotliwość o połowę, więc musimy ten parametr także zmniejszyć o połowę, czyli użyjemy delay(500). Nasz układ będzie pobierał średnio 7,55 mAh, a czas pracy na bateriach wydłuży się do 11 dni i 1 godzinę. Wykres nr 2. Pobór prądu w zależności od częstotliwości zegara i napięcia zasilania Optymalizacja nr 4. Procesor atmega328 ma możliwość zmiany konfiguracji, aby częstotliwość rezonatora była zmniejszona ośmiokrotnie. Wymagana jest tylko odpowiednia konfiguracja Fuse bitów. W tak prostym programie jak blink, nie musimy mieć tak szybkiego procesora. Ustawmy Fuse bit CKDIV8 na aktywny. Spowoduje to, że procesor będzie pracować z częstotliwością ośmiokrotnie mniejszą. Aby uzyskać tę samą częstotliwość migania diody LED musimy troszkę zmienić nasz program. W miejsce oryginalnego delay(1000) wstawmy delay(500/8) lub delay(65). Po kompilacji, wgraniu i przestawienie fuse bitu, dioda nadal miga, tak jak wcześniej, ale średni prąd pobierany przez układ zmniejszył się do 3.7 mA . W efekcie optymalizacji nr 4 nasz układ będzie pracować 22 dni i 13 godzin W nocie katalogowej, wykres powyżej, możemy zobaczyć, że napięcie zasilania możemy zmniejszyć aż do 1.8V. Niestety nie mamy takiej baterii, ale możemy odłączyć kolejną. Wykres nr 3. Maksymalna częstotliwość w zależności od napięcia zasilania Optymalizacja nr 5. Zasilamy nasz układ tym razem z dwóch baterii AA, czyli napięciem 3V. Oczywiście zmieniamy rezystor przy diodzie, aby zasilać ją tym samym prądem co poprzednio. Program, zegar i fuse bity zostawiamy niezmienione. Tym razem otrzymujemy zapotrzebowanie na prąd przez procesor na poziomie 1.1 mA. Nasz układ będzie pracować przez 75 dni i 22 godzin. Optymalizacja nr 6. Wykorzystamy wbudowany w procesor wewnętrzny układ zegarowy o częstotliwości 128kHz. W naszym przypadku, po korekcie w funkcji delay, nadal układ będzie migać diodą LED. Oczywiście pozostawiamy CKDIV8 aktywny uzyskując częstotliwość zegara 16kHz. Średni pobór prądu przez nasz układ wyniesie 0,5 mA, a czas pracy na dwóch bateriach AA, wyniesie 166 dni i 15 godziny. Można wykonać optymalizację nr 7 poprzez zmniejszenie napięcia zasilania do 2.4V, wykorzystując dwa ogniwa akumulatorków o pojemności 2000 mAh. Dioda LED już przestanie prawie świecić, ale układ nadal będzie pracować pobierając średnio 0.35 mA, a czas pracy osiągnie 238 dni i 2 godziny. Idąc dalej można wykonać optymalizacja nr 8. I wykorzystać wbudowany w procesor tryb zmniejszonego pobory prądu poprzez jego usypianie. Taki zabieg spowoduje, że procesor będzie pobierać jeszcze mniej prądu, ale to zadanie pozostawiam czytelnikowi. Krótkie podsumowanie tego co zrobiliśmy Tabela nr 1. Podsumowanie optymalizacji Atmega328 Dzięki zastosowaniu kilku optymalizacji wydłużyliśmy czas pracy naszego, bardzo prostego, układu. Poza tym zmniejszyliśmy o połowę ilość potrzebnych ogniw do zasilania, co zmniejszyło koszty eksploatacji. Wydłużyliśmy czas pracy naszego urządzenia 76 krotnie, wykorzystując o połowę mniej baterii. A jeżeli już kupimy 4 baterie, tak jak to miało miejsce w pierwszej wersji, ale podłączając je równolegle w pakiecie 2 x 2 baterie, to uzyskujemy ponad 150 krotne wydłużenie czasu pracy naszego układu w porównaniu do użycia oryginalnego Arduino UNO. Czytelnik może pokusić się o zgłębienie wiedzy o możliwościach procesorów w omawianej kwestii. Jest dostępna literatura omawiająca to zagadnienie. Ten artykuł ma za zadanie tylko przybliżyć to zagadnienie szerszemu gronu odbiorców, którzy dopiero zaczynają przygodę z mikroprocesorami. Można jeszcze zastosować bardziej ambitne metody zarządzania energią[ii], ale to już zostawiam czytelnikowi. Rozwinięcie na 32 bitach Nasz Adam o tym wszystkim co zrobiliśmy nie wiedział. Ale jego ambicja przerastała jego wiedzę. Napisał, czyli przekopiował swój pierwszy program i stwierdził: „ale przecież to tylko 8-bitowy procesor, użyję 32-bitowego”. Jak pomyślał, tak zrobił, zakupił Arduino M0, skorzystał ze swojego pierwszego programu, skompilował go, wgrał i…. dioda LED miga. Radość wielka, Adam „napisał” swój pierwszy program na procesor 32-bitowy. Znów jest szczęśliwy, choć nadal nie wie co robi procesor. Program wygląda identycznie jak poprzednio. Więc przypomnę co robi procesor. Procesor w funkcji main, w pierwszej linii pin 13 ustawia w stanie wysokim, dioda LED świeci. Następnie, przez 1000ms, procesor SAMD21G18 czeka, aż upłynie 1000ms, robi to szybciej, bo jest szybszy od Atmega328. Procesor zajmuje się tylko sobą, czekając aż upłynie 1000ms. Nudzi się. Po tym czasie pin 13 ustawiany jest w stanie niskim, dioda LED gaśnie. I znowu procesor nic innego nie robi, tylko czeka aż upłynie kolejne 1000ms. I tak na okrągło, przez 99,99% czasu procesor nic nie robi, tylko bardzo szybko sprawdza, czy skończyło się 1000ms. Rysunek 2. Arduino M0 Płytka Arduno M0 została zasilona z 4 baterii AAA, tak jak poprzednio. Średni pobór prądu wynosił 26.8 mA, a czas pracy układu, na używanych wcześniej bateriach, wynosi 3 dni i 2 godzin. Optymalizacja W przypadku procesora SAMD21G18 również możemy przeprowadzić podobną optymalizację. Ograniczymy się tylko dwóch etapów, w którym zasilimy płytkę z 2 baterii AAA . Optymalizacja nr 1. Aby ograniczyć zużycie prądy przez elementy dodatkowe na płytce wykorzystamy podobnie jak poprzednio sam procesor oraz tylko te elementy, które będą niezbędne do pracy. Po optymalizacji otrzymaliśmy średni prąd zasilania wynoszący 9,6 mA. Nasz układ będzie nieprzerwalnie pracować przez 8 dni i 14 godzin. Optymalizacja nr 2. Przy użyciu trybu pracy SLEEP dla omawianego procesora możemy obniżyć pobór prądu do ok 6uA. Mając takie możliwości możemy w czasie gdy dioda LED ma być zgaszona uśpimy procesor. Przy wcześniejszej optymalizacji osiągnęliśmy średni pobór prądu na poziomie 9,6 mA, teraz usypiając procesor przez połowę czas uzyskamy 4,8 mA. Wynik może nie powala bo i tak spora wartość, ale pamiętajmy, to jest o 50% mniej. Po tej optymalizacji otrzymaliśmy średni prąd zasilania wynoszący 4,8 mA. Nasz układ będzie nieprzerwalnie pracować przez 17 dni i 4 godzin. Jeżeli chodzi o optymalizację częstotliwości zapraszam do analizy noty katalogowej producenta i wykonania własnych testów. Krótkie podsumowanie tego co zrobiliśmy Tabela nr 2. Podsumowanie optymalizacji SAMD21G18 Podsumowanie Porównajmy teraz obie płytki Arduino. Obie posiadają podobną ilość pinów do wykorzystania, obie można zasilić albo z USB, albo z zewnętrznego zasilacza, obie pracują na maksymalnych prędkościach zegara jakie udostępnia producent. Procesor w Arduino Uno ma piny, które można obciążyć większym prądem niż w procesor w Arduino M0. Oba procesory mają możliwość korzystania z metod zarządzania zasilaniem, tym samym zmniejszania prądu zasilania procesora. Dla naszego Adama, jest bez znaczenia, która płytkę wykorzysta, ale dla czytelnika tego artykułu zapewne już nie. Nie zawsze jest sens używać najmocniejszy procesor, skoro słabszy i tańszy zrobi dokładnie to samo. Dla prostych aplikacji, które nie wymagają „super szybkości” procesor Atmega328 wydaje się być lepszym rozwiązaniem w porównaniu do SAMD21G18. Natomiast gdy budujemy aplikację bardzo skomplikowaną, wymagającą szybkich operacji i krótkich czasów reakcji to SAMD21G18 tym razem będzie lepszy od Atmega328. Wszystko należy przekalkulować. Jeżeli zoptymalizujemy nasz układ sprzętowo i programowo, to możemy podkusić się o zrobienie układu, który będzie niezależny od zasilania zewnętrznego. Możemy zasilać układ np. z energii słonecznej, która zostanie dostarczona przez ogniwo słoneczne. Podczas dnia nadmiar energii wytworzonej przez ogniwo można gromadzić w akumulatorze, z którego układ będzie zasilany nocą. Dobór ogniwa i akumulatora zależy już od tego jak skomplikowany mamy układ i jakie ma zapotrzebowanie na energię, ale ważne jest by układ działał cały czas. Ktoś mógłby powiedzieć perpetuum mobile, ale my powiemy że korzystamy z energii odnawialnej. Dlaczego Arduino Nie ma wątpliwości, że rozwój elektroniki sprawił, że wiele narzędzi i produktów stało się bardziej dostępnych dla zwykłego użytkownika. Idea Arduino doprowadziła to stanu, w którym to każdy może spróbować, w naszym przypadku, programowania i konstruowania elektroniki. Programowanie w Arduino jest bardzo proste, a programista nie musi znać budowy wewnętrznej procesorów, co w przypadku innych środowisk jest konieczne. Samo środowisko jest bezpłatne. Moduły Arduino stały się bardzo dostępne na naszym rynku, a za sprawą „specjalistów” z Chin również cenowo bardzo atrakcyjne. Wsparcie producenta i dostępność dokumentacji jest szczególnym ułatwieniem w budowaniu i programowaniu układów. Rozpowszechnienie Arduino na całym świecie sprawiło, że użytkowników i osób w nim programujących jest wielu. Jest bardzo wiele grup dyskusyjnych, forum internetowych czy repozytoriów na których jest omawianych całe mnóstwo problemów i ich rozwiązań, bibliotek napisanych przez użytkowników, czy po prostu opisów typu „jak zrobić…”. To wszystko sprawia, że zamieszczony w tym artykule opis dotyczy Arduino, od którego to zaczyna przygodę z programowaniem najwięcej osób.



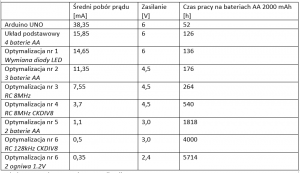

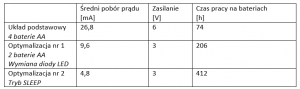
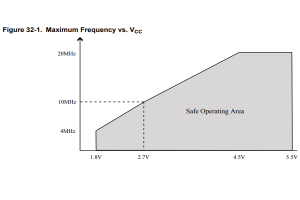
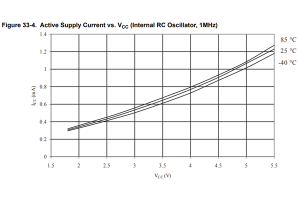

-
 Ki-Cad to program, a właściwie zbiór programów służących do tworzenia schematów elektrycznych i obwodów drukowanych. Cechuje się dużą możliwością personalizacji interfejsu i posiada kompleksowy zestaw narzędzi pozwalający na przeniesienie pomysłu na gotowy projekt układu. Pełny program można pobrać ze strony producenta: https://kicad-pcb.org/. Pobieramy program, instalujemy go i otwieramy. Ten wpis brał udział konkursie na najlepszy artykuł o elektronice lub programowaniu. Sprawdź wyniki oraz listę wszystkich prac » Partnerem tej edycji konkursu (marzec 2020) był popularny producent obwodów drukowanych, firma PCBWay. Tworzenie projektu Po otwarciu programu ukaże się nam takie oto okno: Tworzymy nowy projekt klikając ikonę z niebieskim folderem i nadajemy mu nazwę. W naszym przypadku będzie to “poradnik-forbot”. Gdy stworzymy nasz projekt razem z nim utworzą się dwa pliki. Pierwszy z rozszerzeniem “.kicad_pcb” służy do projektowania fizycznej wersji układu(tj. rysowania ścieżek na obwodzie drukowanym, stawiania footprintów itp.). Drugi plik z rozszerzeniem “.sch” służy do tworzenia schematu ideowego naszego układu(tj. tworzenie logicznych połączeń, dodawanie logicznym reprezentacji układów itp.). Najprostszym sposobem na stworzenie projektu jest rozpoczęcie go od schematu ideowego, gdyż gdy stworzymy schemat ideowy na schemacie fizycznym automatycznie pojawią się połączenia między footprintami, które ułatwią nam rysowanie ścieżek. Schemat ideowy i dodawanie elementów Schemat ideowy stworzymy za pomocą edytora schematów “Eeschema”. Po otwarciu ukaże się nam taki widok: Po zapoznaniu się z interfejsem możemy wejść w “Ustawienia strony”, aby zmienić jej wymiary, autora, datę itp. W tym projekcie spróbujemy zrobić prostego, okrojonego klona Arduino Pro Mini. Projektowanie warto rozpocząć od postawienia portów zasilania , wykonujemy to poprzez otwarcie interfejsu oznaczonego jako “D”. W “Dodawanie portów zasilania” znajdziemy możliwe do dodania porty zasilania. W moim naszym przypadku użyjemy portu 5V i GND. (widok po otwarciu okna “Dodawanie portów zasilania”) Dodanie portów zasilania w taki sposób jest istotne, aby program mógł poprawnie zinterpretować nasz układ. Gdy już mamy porty zasilania czas dodać elementy elektryczne, klikamy na przycisk “Dodaj Symbol”, ukaże się nam takie oto okno: Analogiczny do interfejsu “Dodawanie portów zasilania”, jednak z większą ilością zakładek. Najpierw dodamy ATmega 328p do naszego schematu. Jest to mikrokontroler używany w Arduino Pro Mini. Szukamy zakładki MCU microchip ATmega, rozwijamy ją i szukamy “ATmega328p-AU”. Skrót AU oznacza, że ten mikrokontroler jest w obudowie TQFP-32, taka sama jak w Arduino Pro Mini. Zaznaczamy i klikamy “ok”, aby dodać element do schematu. Taki element możemy podczas przesuwania obracać klawiszem R ,a także najeżdżając kursorem na element bądź napis kliknąć M ,aby poruszać elementem. Jest to wygodniejsze niż zaznaczanie gdyż zaznaczając możemy przez przypadek oznaczyć także inny element lub połączenie. Następnie, tak samo jak mikrokontroler dodajemy potrzebne rezystory , kondensatory oscylatory itd. Łączymy za pomocą narzędzia “Dodawanie połączeń”. Dodawanie Etykiet Podczas procesu łączenia elementów warto pomyśleć o dodaniu Etykiet. Etykiety pozwalają na połączenie wszystkich pinów do których mają być przyłączone. W ten sposób tworzy się sieć połączeń. Ma to dwie główne zalety w porównaniu do tradycyjnych połączeń. Po pierwsze schemat staje się bardziej czytelny, gdyż przy dużej ilości połączeń może wyjść nieczytelne spaghetti połączeń. Po drugie nadaje to nazwę naszej sieci połączeń, przyda się nam to szczególnie w trakcie projektowania samej PCB. Aby utworzyć Etykietę naciskamy przycisk “dodaj Etykietę globalną”. Nazywamy ją w polu “Etykieta” i umieszczamy na schemacie. Utworzyliśmy tym samym typ etykiety np.”VCC”. Aby dodać kolejną etykietę robimy to samo, tylko nie wpisujemy nazwy w pole etykieta, ale je rozwijamy. Wewnątrz powinna się znajdować nasza etykieta “VCC” wybieramy ją i klikamy “ok”. Tym sposobem dodaliśmy naszą etykietę do schematu. Podobnie jak elementy, etykiety można obracać klawiszem “R”. Teraz, gdy przyłączymy te etykiety do określonych pinów, program połączy je w sieć o nazwie “VCC”. Właściwości elementów i znacznik "niepołączone" Zaznaczając element i klikając przycisk “E” możemy wejść w właściwości danego elementu. Możemy tutaj edytować różne parametry, takie jak ułożenie, wyśrodkowanie napisów itp. A także wpisać wartość naszego elementu( tak jak na rysunku poniżej, oscylator o wartości 16 MHz). Zwróćcie uwagę na znak zapytania obok oznaczenia, oznacza on jeszcze nie nadaną numerację tego elementu. Ważne jest by każdy element był oznaczony, możemy to zrobić za pomocą pewnego narzędzia, które przedstawię wam później. Może się tak zdarzyć że niektóre piny np. w mikrokontrolerze nie będą przez nas używane i do niczego ich nie podłączymy. Należy wtedy użyć narzędzia "znacznik niepołączone" i oznaczyć nim nasze nieużywane piny. (Wtedy program nie będzie wskazywał błędów) (Wygląd gotowego schematu z ATmega328p) Gdy nasz układ jest już połączony zostały nam tylko trzy kroki. Są nimi: numeracja elementów, przypisywanie footprintów do elementów i generowanie listy sieci. Numeracja elementów: Klikamy przycisk “Numerowanie symboli na schemacie”, ukaże nam się taki widok: Klikamy “Numeruj”, narzędzie automatycznie ponumeruje nam elementy na schemacie. Przypisywanie footprintów do elementów: Elementy na schemacie są tylko ideowe, więc trzeba przypisać do nich footprinty, czyli fizyczne miejsca dla elementów na obwodzie drukowanym. Robimy to za pomocą przycisku “Przypisywanie footprintów do symboli”. Następnie ukazuje się nam takie oto okno: W pierwszej kolumnie mamy listę folderów zawierających footprinty, w drugiej symbole z naszego schematu, a w trzeciej rozwinięty, aktualnie otwarty, folder z lewej kolumny. ATmega328p-AU ma już przypisany swój footprint, z uwagi na dostępny tylko ten konkretny model obudowy. Możemy to zmienić, lecz ta obudowa jest w pełni kompatybilna. Do reszty elementów musimy konkretne footprinty przypisać sami. Wyszukujemy w pierwszej kolumnie odpowiedni folder, zaznaczamy go i w trzeciej kolumnie wyszukujemy footprint, który jest nam potrzebny. Klikamy dwa razy lewy przycisk myszy, aby przypisać footprint do naszego symbolu. Jeśli potrzebujemy mieć wgląd w dokładny wygląd footprintu, możemy go zaznaczyć prawym przyciskiem myszy i wyświetlić jego fizyczne przedstawienie na płytce. (Wygląd okna z przypisanymi footprintami) Generowanie listy sieci Gdy już to skończymy musimy jeszcze wyeksportować listę sieci z naszego schematu do pliku , które program Pcbnew (Ten w którym robimy już fizyczny obwód) mógł odczytać nasz schemat. Klikamy więc po zamknięciu przypisywanie footprintów klikamy przycisk “Generowanie listy sieci”. Zaznaczmy zakładkę Pcbnew i klikamy “generowanie listy sieci” . Plik ten zostanie utworzony w folderze naszego projektu. Pcbnew i właściwe tworzenie układu drukowanego Następnie otwieramy program Pcbnew , aby rozpocząć właściwe tworzenie obwodu drukowanego. Po otwarciu programu ukaże się nam taki oto widok: Interfejs jest bardzo podobny do programu Eeshema. Domyślnie program obsługuje dwie warstwy miedzi (warstwa F i warstwa B). Możemy to zmienić wchodząc w “Ustawienia projektowe płytki”. Kiedy zapoznamy się z interfejsem “Pcbnew” możemy przystąpić do załadowania listy sieci, którą zrobiliśmy przed chwilą. Klikamy “Załaduj listę sieci”, ukaże się nam taki widok: Klikamy na ikonkę folderu w prawym górnym rogu i wybieramy naszą wcześniej utworzoną listę sieci. Następnie klikamy przycisk “Uaktualnij PCB”. Dzięki temu wszystkie footprinty, które dodaliśmy do schematu zostaną dodane do naszego obwodu drukowanego. Powinno to wyglądać mniej więcej tak: Jak widać wszystkie footprinty zostały dodane. Dodatkowo zostały utworzone linie pomocnicze, które mówią nam co powinno być sobą połączone na podstawie schematu. Jest to bardzo pomocne, jeśli chcielibyśmy coś dodać do naszego układu, ale nie usuwać istniejących footprintów i połączeń. Możemy jeszcze raz załadować listę sieci. Wtedy zostaną zaaplikowane poprawki, które wykonaliśmy na schemacie. Pamiętajmy także o opcji “Odbuduj połączenia wspomagające”, aby zostały one uaktualnione. Ustawienia obwodu drukowanego Zanim zaczniemy rysować ścieżki warto jeszcze dostosować ich parametry . Robimy to wchodząc w “Ustawienia obwodu drukowanego”. Możemy tam dostosować różne parametry naszego obwodu drukowanego, np.szerokość ścieżek, odległość między ścieżkami itp. oraz przypisać te właściwości do konkretnych sieci w naszym układzie. W naszym przypadku dodamy tylko dwie klasy sieci domyślną oraz zasilania(trochę grubszą z uwagi na większe możliwe prądy przepływające przez te ścieżki). Przypiszemy też klasę zasilania do sieci GND i 5V. Klikamy “ok” i od teraz program automatycznie przełączy nam właściwą szerokość ścieżki w zależności od sieci którą będziemy rysować. Skróty klawiszowe Pcbnew Przejdźmy do właściwego układania footprintów i rysowania ścieżek. Skróty klawiszowe są podobne jak w programie “Eeschema”, też klawisz “M” używamy aby przemieścić obiekt, “R” aby obracać obiekt. Ważny skrót klawiszowy to “V”, gdyż nim przełączmy między warstwami miedzi. Można też, gdy trzymamy obiekt tym klawiszem, przełożyć go na drugą stronę płytki oraz podczas rysowania ścieżki możemy utworzyć przelotkę. Jest to mała metalizowana dziura która pozwala na przejście wertykalne przez płytkę i np. połączyć elementy na dwóch różnych warstwach, stworzyć przejście pod ścieżką która nas blokuje na innej warstwie itp. Istnieje możliwość przełączania się tym klawiszem między warstwami, gdy nie jest zaznaczony żaden element. Strefy Warto pomyśleć o dodaniu warstw miedzi jako masę na całej dolnej warstwie naszej płytki. Nie tylko ułatwi to nam dołączanie elementów do uziemienia ale także zapewni proste ekranowanie układu. Robimy to za pomocą narzędzia “Dodaj strefy”. Naszym oczom ukaże się takie oto okno: Zaznaczamy warstwę “B.Cu” oraz wybieramy sieć “GND”, resztę ustawień pozostawiamy domyślne. Następnie klikamy “OK”. Potem fizycznie musimy narysować obrys strefy na naszym układzie. Strefa następnie zostanie dodana na całym obrysowanym przez nas obszarze. Musimy też pamiętać że podczas rysowania w obszarze strefy nie aktualizuje się on w czasie rzeczywistym i musimy po dokonaniu jakiś zmian nacisnąć klawisz “B”, aby na nowo wypełnić strefę (np. strefa usuwa się z utworzonych przez nas ścieżek, elementów oraz wypełniła puste miejsca na płytce) Po tym możemy już spokojnie połączyć wszystkie elementy układu. Oto efekt: (Gotowy układ z uruchomioną kontrolą DRC. Wszystko jest dobrze , nie ma błedów) Warto po zakończonej pracy sprawdzić układ kontrolą DRC, aby upewnić się że wszystko jest odpowiednio połączone, itp. Należy też pamiętać że : Ścieżki powinny zginać się pod kątem 45 stopni nie 90 stopni Napisy warstwy opisowej (np. C1 , R2 itp. zaznaczone kolorem zielonym) nie powinny się znajdować na padach lutowniczych naszych footprintów) (Przegląd 3D naszego układu) Po kliknięciu przycisku ALT+3 możemy włączyć widok 3D naszej płytki , aby zobaczyć jak wygląda i czy napisy są umieszczone czytelnie. Eksportowanie projektu Na końcu, aby wyeksportować naszą płytkę tak, aby fabryka PCB mogła ją zrobić należy wejść w “Rysuj”. Ukaże się nam takie okno. Zależnie od fabryki, w której będziemy chcieli wyprodukować płytkę, możemy użyć różnych formatów projektu. Zazwyczaj potrzeba plików w formacie GERBER. Zaznaczamy, więc warstwy jakie chcemy wyeksportować, wybieramy format wyjściowy i folder wyjściowy(jeśli tutaj nic nie wybierzemy program utworzy nam pliki w folderze projektu). Następnie klikamy “Rysuj”, a potem “Generuj pliki wierceń”, aby stworzyć pliki wierceń (wyświetli nam się podobne okienko w którym możemy wybrać format wyjściowy itp.). I takim sposobem stworzyliśmy swoją pierwszą płytę w KiCadzie. Dziękuję za uwagę! Aleksander Flont
Ki-Cad to program, a właściwie zbiór programów służących do tworzenia schematów elektrycznych i obwodów drukowanych. Cechuje się dużą możliwością personalizacji interfejsu i posiada kompleksowy zestaw narzędzi pozwalający na przeniesienie pomysłu na gotowy projekt układu. Pełny program można pobrać ze strony producenta: https://kicad-pcb.org/. Pobieramy program, instalujemy go i otwieramy. Ten wpis brał udział konkursie na najlepszy artykuł o elektronice lub programowaniu. Sprawdź wyniki oraz listę wszystkich prac » Partnerem tej edycji konkursu (marzec 2020) był popularny producent obwodów drukowanych, firma PCBWay. Tworzenie projektu Po otwarciu programu ukaże się nam takie oto okno: Tworzymy nowy projekt klikając ikonę z niebieskim folderem i nadajemy mu nazwę. W naszym przypadku będzie to “poradnik-forbot”. Gdy stworzymy nasz projekt razem z nim utworzą się dwa pliki. Pierwszy z rozszerzeniem “.kicad_pcb” służy do projektowania fizycznej wersji układu(tj. rysowania ścieżek na obwodzie drukowanym, stawiania footprintów itp.). Drugi plik z rozszerzeniem “.sch” służy do tworzenia schematu ideowego naszego układu(tj. tworzenie logicznych połączeń, dodawanie logicznym reprezentacji układów itp.). Najprostszym sposobem na stworzenie projektu jest rozpoczęcie go od schematu ideowego, gdyż gdy stworzymy schemat ideowy na schemacie fizycznym automatycznie pojawią się połączenia między footprintami, które ułatwią nam rysowanie ścieżek. Schemat ideowy i dodawanie elementów Schemat ideowy stworzymy za pomocą edytora schematów “Eeschema”. Po otwarciu ukaże się nam taki widok: Po zapoznaniu się z interfejsem możemy wejść w “Ustawienia strony”, aby zmienić jej wymiary, autora, datę itp. W tym projekcie spróbujemy zrobić prostego, okrojonego klona Arduino Pro Mini. Projektowanie warto rozpocząć od postawienia portów zasilania , wykonujemy to poprzez otwarcie interfejsu oznaczonego jako “D”. W “Dodawanie portów zasilania” znajdziemy możliwe do dodania porty zasilania. W moim naszym przypadku użyjemy portu 5V i GND. (widok po otwarciu okna “Dodawanie portów zasilania”) Dodanie portów zasilania w taki sposób jest istotne, aby program mógł poprawnie zinterpretować nasz układ. Gdy już mamy porty zasilania czas dodać elementy elektryczne, klikamy na przycisk “Dodaj Symbol”, ukaże się nam takie oto okno: Analogiczny do interfejsu “Dodawanie portów zasilania”, jednak z większą ilością zakładek. Najpierw dodamy ATmega 328p do naszego schematu. Jest to mikrokontroler używany w Arduino Pro Mini. Szukamy zakładki MCU microchip ATmega, rozwijamy ją i szukamy “ATmega328p-AU”. Skrót AU oznacza, że ten mikrokontroler jest w obudowie TQFP-32, taka sama jak w Arduino Pro Mini. Zaznaczamy i klikamy “ok”, aby dodać element do schematu. Taki element możemy podczas przesuwania obracać klawiszem R ,a także najeżdżając kursorem na element bądź napis kliknąć M ,aby poruszać elementem. Jest to wygodniejsze niż zaznaczanie gdyż zaznaczając możemy przez przypadek oznaczyć także inny element lub połączenie. Następnie, tak samo jak mikrokontroler dodajemy potrzebne rezystory , kondensatory oscylatory itd. Łączymy za pomocą narzędzia “Dodawanie połączeń”. Dodawanie Etykiet Podczas procesu łączenia elementów warto pomyśleć o dodaniu Etykiet. Etykiety pozwalają na połączenie wszystkich pinów do których mają być przyłączone. W ten sposób tworzy się sieć połączeń. Ma to dwie główne zalety w porównaniu do tradycyjnych połączeń. Po pierwsze schemat staje się bardziej czytelny, gdyż przy dużej ilości połączeń może wyjść nieczytelne spaghetti połączeń. Po drugie nadaje to nazwę naszej sieci połączeń, przyda się nam to szczególnie w trakcie projektowania samej PCB. Aby utworzyć Etykietę naciskamy przycisk “dodaj Etykietę globalną”. Nazywamy ją w polu “Etykieta” i umieszczamy na schemacie. Utworzyliśmy tym samym typ etykiety np.”VCC”. Aby dodać kolejną etykietę robimy to samo, tylko nie wpisujemy nazwy w pole etykieta, ale je rozwijamy. Wewnątrz powinna się znajdować nasza etykieta “VCC” wybieramy ją i klikamy “ok”. Tym sposobem dodaliśmy naszą etykietę do schematu. Podobnie jak elementy, etykiety można obracać klawiszem “R”. Teraz, gdy przyłączymy te etykiety do określonych pinów, program połączy je w sieć o nazwie “VCC”. Właściwości elementów i znacznik "niepołączone" Zaznaczając element i klikając przycisk “E” możemy wejść w właściwości danego elementu. Możemy tutaj edytować różne parametry, takie jak ułożenie, wyśrodkowanie napisów itp. A także wpisać wartość naszego elementu( tak jak na rysunku poniżej, oscylator o wartości 16 MHz). Zwróćcie uwagę na znak zapytania obok oznaczenia, oznacza on jeszcze nie nadaną numerację tego elementu. Ważne jest by każdy element był oznaczony, możemy to zrobić za pomocą pewnego narzędzia, które przedstawię wam później. Może się tak zdarzyć że niektóre piny np. w mikrokontrolerze nie będą przez nas używane i do niczego ich nie podłączymy. Należy wtedy użyć narzędzia "znacznik niepołączone" i oznaczyć nim nasze nieużywane piny. (Wtedy program nie będzie wskazywał błędów) (Wygląd gotowego schematu z ATmega328p) Gdy nasz układ jest już połączony zostały nam tylko trzy kroki. Są nimi: numeracja elementów, przypisywanie footprintów do elementów i generowanie listy sieci. Numeracja elementów: Klikamy przycisk “Numerowanie symboli na schemacie”, ukaże nam się taki widok: Klikamy “Numeruj”, narzędzie automatycznie ponumeruje nam elementy na schemacie. Przypisywanie footprintów do elementów: Elementy na schemacie są tylko ideowe, więc trzeba przypisać do nich footprinty, czyli fizyczne miejsca dla elementów na obwodzie drukowanym. Robimy to za pomocą przycisku “Przypisywanie footprintów do symboli”. Następnie ukazuje się nam takie oto okno: W pierwszej kolumnie mamy listę folderów zawierających footprinty, w drugiej symbole z naszego schematu, a w trzeciej rozwinięty, aktualnie otwarty, folder z lewej kolumny. ATmega328p-AU ma już przypisany swój footprint, z uwagi na dostępny tylko ten konkretny model obudowy. Możemy to zmienić, lecz ta obudowa jest w pełni kompatybilna. Do reszty elementów musimy konkretne footprinty przypisać sami. Wyszukujemy w pierwszej kolumnie odpowiedni folder, zaznaczamy go i w trzeciej kolumnie wyszukujemy footprint, który jest nam potrzebny. Klikamy dwa razy lewy przycisk myszy, aby przypisać footprint do naszego symbolu. Jeśli potrzebujemy mieć wgląd w dokładny wygląd footprintu, możemy go zaznaczyć prawym przyciskiem myszy i wyświetlić jego fizyczne przedstawienie na płytce. (Wygląd okna z przypisanymi footprintami) Generowanie listy sieci Gdy już to skończymy musimy jeszcze wyeksportować listę sieci z naszego schematu do pliku , które program Pcbnew (Ten w którym robimy już fizyczny obwód) mógł odczytać nasz schemat. Klikamy więc po zamknięciu przypisywanie footprintów klikamy przycisk “Generowanie listy sieci”. Zaznaczmy zakładkę Pcbnew i klikamy “generowanie listy sieci” . Plik ten zostanie utworzony w folderze naszego projektu. Pcbnew i właściwe tworzenie układu drukowanego Następnie otwieramy program Pcbnew , aby rozpocząć właściwe tworzenie obwodu drukowanego. Po otwarciu programu ukaże się nam taki oto widok: Interfejs jest bardzo podobny do programu Eeshema. Domyślnie program obsługuje dwie warstwy miedzi (warstwa F i warstwa B). Możemy to zmienić wchodząc w “Ustawienia projektowe płytki”. Kiedy zapoznamy się z interfejsem “Pcbnew” możemy przystąpić do załadowania listy sieci, którą zrobiliśmy przed chwilą. Klikamy “Załaduj listę sieci”, ukaże się nam taki widok: Klikamy na ikonkę folderu w prawym górnym rogu i wybieramy naszą wcześniej utworzoną listę sieci. Następnie klikamy przycisk “Uaktualnij PCB”. Dzięki temu wszystkie footprinty, które dodaliśmy do schematu zostaną dodane do naszego obwodu drukowanego. Powinno to wyglądać mniej więcej tak: Jak widać wszystkie footprinty zostały dodane. Dodatkowo zostały utworzone linie pomocnicze, które mówią nam co powinno być sobą połączone na podstawie schematu. Jest to bardzo pomocne, jeśli chcielibyśmy coś dodać do naszego układu, ale nie usuwać istniejących footprintów i połączeń. Możemy jeszcze raz załadować listę sieci. Wtedy zostaną zaaplikowane poprawki, które wykonaliśmy na schemacie. Pamiętajmy także o opcji “Odbuduj połączenia wspomagające”, aby zostały one uaktualnione. Ustawienia obwodu drukowanego Zanim zaczniemy rysować ścieżki warto jeszcze dostosować ich parametry . Robimy to wchodząc w “Ustawienia obwodu drukowanego”. Możemy tam dostosować różne parametry naszego obwodu drukowanego, np.szerokość ścieżek, odległość między ścieżkami itp. oraz przypisać te właściwości do konkretnych sieci w naszym układzie. W naszym przypadku dodamy tylko dwie klasy sieci domyślną oraz zasilania(trochę grubszą z uwagi na większe możliwe prądy przepływające przez te ścieżki). Przypiszemy też klasę zasilania do sieci GND i 5V. Klikamy “ok” i od teraz program automatycznie przełączy nam właściwą szerokość ścieżki w zależności od sieci którą będziemy rysować. Skróty klawiszowe Pcbnew Przejdźmy do właściwego układania footprintów i rysowania ścieżek. Skróty klawiszowe są podobne jak w programie “Eeschema”, też klawisz “M” używamy aby przemieścić obiekt, “R” aby obracać obiekt. Ważny skrót klawiszowy to “V”, gdyż nim przełączmy między warstwami miedzi. Można też, gdy trzymamy obiekt tym klawiszem, przełożyć go na drugą stronę płytki oraz podczas rysowania ścieżki możemy utworzyć przelotkę. Jest to mała metalizowana dziura która pozwala na przejście wertykalne przez płytkę i np. połączyć elementy na dwóch różnych warstwach, stworzyć przejście pod ścieżką która nas blokuje na innej warstwie itp. Istnieje możliwość przełączania się tym klawiszem między warstwami, gdy nie jest zaznaczony żaden element. Strefy Warto pomyśleć o dodaniu warstw miedzi jako masę na całej dolnej warstwie naszej płytki. Nie tylko ułatwi to nam dołączanie elementów do uziemienia ale także zapewni proste ekranowanie układu. Robimy to za pomocą narzędzia “Dodaj strefy”. Naszym oczom ukaże się takie oto okno: Zaznaczamy warstwę “B.Cu” oraz wybieramy sieć “GND”, resztę ustawień pozostawiamy domyślne. Następnie klikamy “OK”. Potem fizycznie musimy narysować obrys strefy na naszym układzie. Strefa następnie zostanie dodana na całym obrysowanym przez nas obszarze. Musimy też pamiętać że podczas rysowania w obszarze strefy nie aktualizuje się on w czasie rzeczywistym i musimy po dokonaniu jakiś zmian nacisnąć klawisz “B”, aby na nowo wypełnić strefę (np. strefa usuwa się z utworzonych przez nas ścieżek, elementów oraz wypełniła puste miejsca na płytce) Po tym możemy już spokojnie połączyć wszystkie elementy układu. Oto efekt: (Gotowy układ z uruchomioną kontrolą DRC. Wszystko jest dobrze , nie ma błedów) Warto po zakończonej pracy sprawdzić układ kontrolą DRC, aby upewnić się że wszystko jest odpowiednio połączone, itp. Należy też pamiętać że : Ścieżki powinny zginać się pod kątem 45 stopni nie 90 stopni Napisy warstwy opisowej (np. C1 , R2 itp. zaznaczone kolorem zielonym) nie powinny się znajdować na padach lutowniczych naszych footprintów) (Przegląd 3D naszego układu) Po kliknięciu przycisku ALT+3 możemy włączyć widok 3D naszej płytki , aby zobaczyć jak wygląda i czy napisy są umieszczone czytelnie. Eksportowanie projektu Na końcu, aby wyeksportować naszą płytkę tak, aby fabryka PCB mogła ją zrobić należy wejść w “Rysuj”. Ukaże się nam takie okno. Zależnie od fabryki, w której będziemy chcieli wyprodukować płytkę, możemy użyć różnych formatów projektu. Zazwyczaj potrzeba plików w formacie GERBER. Zaznaczamy, więc warstwy jakie chcemy wyeksportować, wybieramy format wyjściowy i folder wyjściowy(jeśli tutaj nic nie wybierzemy program utworzy nam pliki w folderze projektu). Następnie klikamy “Rysuj”, a potem “Generuj pliki wierceń”, aby stworzyć pliki wierceń (wyświetli nam się podobne okienko w którym możemy wybrać format wyjściowy itp.). I takim sposobem stworzyliśmy swoją pierwszą płytę w KiCadzie. Dziękuję za uwagę! Aleksander Flont









- 1 odpowiedź
-
- 7
-
-
- projektowanie
- Ki-Cad
- (i 2 więcej)
-
 Po przeczytaniu dwóch poprzednich części znamy już pobieżnie zasady działania HTTP, potrafimy już stworzyć prosty (choć prawdopodobnie użyteczny) serwer. Ale przecież serwer to dopiero połowa - drugą, równie ważną jest klient. I znów będziemy próbować przesyłać między serwerem a klientem dane dotyczące stanu wejść naszego Arduino (czyli najprawdopodobniej jakichś czujników). Ten wpis brał udział konkursie na najlepszy artykuł o elektronice lub programowaniu. Sprawdź wyniki oraz listę wszystkich prac » Partnerem tej edycji konkursu (marzec 2020) był popularny producent obwodów drukowanych, firma PCBWay. Spis treści serii artykułów: Protokół HTTP w zastosowaniach IoT - część 1: trochę teorii Protokół HTTP w zastosowaniach IoT - część 2: budujemy serwer Protokół HTTP w zastosowaniach IoT - część 3: tworzymy klienta I tu uwaga: ponieważ musimy użyć dwóch urządzeń, potrzebne byłyby dwie identyczne płytki. Ponieważ nie każdy ma akurat w szufladzie dwa takie same układy - możemy zasymulować działanie takiego serwera używając naszego komputera. W tym celu w załączniku znajduje się krótki program napisany w Pythonie. Serwer działa na porcie 8001 zamast 80. Gdybyśmy jednak chcieli zmienić to zachowanie, musimy pamiętać, że: na naszym serwerze nie może działać żaden inny serwer na porcie 80; w przypadku Linuksa aby serwer mógł działać na porcie 80, musimy go uruchamiać z konta root (np. przez sudo) - normalny użytkownik nie może uruchamiać serwerów na portach niższych niż 1024. Jeśli chcemy, aby nasz serwer uruchamiał się na inym porcie niż 8001 - po prostu musimy znaleźć linijkę: port = 8001 i zamienić liczbę 8001 na numer portu. Serwer uruchamiamy z konsoli po wejściu do katalogu zawierającego program poleceniem: python3 miniserver.py lub odpowiednikiem dla naszego systemu operacyjnego. Jeśli nasz komputer ma zainstalowanego firewalla, należy zezwolić na dostęp z zewnątrz dla naszego serwera. Ponieważ różne firewalle mają różne metody służące do takowego zezwalania - odsyłam do dokumentacji naszego firewalla. Po uruchomieniu serwera możemy sprawdzić jego działanie wchodząc przeglądarką na adres http://ip_naszego_komputera:8001/ lub http://localhost:8001/ - powinny ukazać się trzy liczby. Jako że nasz komputer nie ma najprawdopodobniej podłączonych żadnych potencjometrów czy przycisków - liczba odpowiadająca potencjometrowi jest po prostu brana z generatora losowego, a klawiszowi zmienia się za każdym wywołaniem. Tyle tytułem przydługiego wstępu, możemy wreszcie zabrać się za tworzenie... klienta HTTP Ponieważ do klienta będą potrzebne takie same płytki jak do serwera, przypominam układy połączeń dla Arduino z shieldem Ethernet oraz płytek ESP3266 i ESP32: I znów jak poprzednio użyjemy wspólnego fragmentu kodu. Będzie on bardzo podobny do kodu używanego przy pisaniu serwera. Jedynymi różnicami są brak deklaracji i uruchomienia serwera oraz zdefiniowanie wielkości bufora (różne dla małego Arduino i większych płytek). Należy pamiętać, że w przypadku Ethernetu musimy zapewnić unikalność adresów MAC! #ifdef AVR // część dla Arduino i Ethernet Shield #include <SPI.h> #include <Ethernet.h> #define POT_PIN A1 #define KEY_PIN A0 byte mac[] = { 0xDE, 0xAD, 0xBE, 0xEF, 0xFE, 0xEE }; #define MyServer EthernetServer #define MyClient EthernetClient #define SERIAL_SPEED 9600 void init_network(void) { Ethernet.begin(mac); while (Ethernet.linkStatus() == LinkOFF) { Serial.println(F("Ethernet cable is not connected.")); delay(500); } // dajmy mu trochę czasu na połączenie delay(1000); Serial.print(F("Adres: ")); Serial.println(Ethernet.localIP()); } #else // część dla ESP #ifdef ESP32 #include <WiFi.h> #define POT_PIN 32 #define KEY_PIN 16 #else #include <ESP8266WiFi.h> #define POT_PIN A0 #define KEY_PIN 4 #endif const char* ssid = "My_SSID"; const char* password = "My_Password"; #define MyServer WiFiServer #define MyClient WiFiClient #define SERIAL_SPEED 115200 void init_network(void) { WiFi.mode(WIFI_STA); WiFi.begin(ssid, password); while (WiFi.status() != WL_CONNECTED) { delay(500); Serial.print("."); } Serial.println(); Serial.print("Połączono z WiFi, adres: "); Serial.println(WiFi.localIP()); } #endif void setup(void) { Serial.begin(SERIAL_SPEED); #ifdef __AVR_ATmega32U4__ while (!Serial); // potrzebne tylko dla Leonardo/Micro #endif init_network(); pinMode(KEY_PIN, INPUT_PULLUP); } #ifdef AVR #define BUFFER_LENGTH 128 #else #define BUFFER_LENGTH 1024 #endif Pierwszy klient będzie bardzo prosty. Nie musimy na razie uruchamiać naszego serwera, zamiast tego połączymy się z serwerem Google: const char Server[]="www.google.pl"; const int ServerPort = 80; void loop() { MyClient client; if (!client.connect(Server, ServerPort)) { Serial.println(F("Brak połączenia z serwerem")); delay(5000); return; } // pytamy googla o stronę główną client.print(F("GET / HTTP/1.1\r\nHost: www.google.pl\r\nCpnnection: Close\r\n\r\n")); // po prostu wypisujemy na monitorze serial // wszystko co dostaliśmy z serwera while (client.connected()) { if (client.available()) { char c = client.read(); Serial.print(c); } else { delay(5); // poczekamy chwilę aż serwer wyśle coś więcej } } client.stop(); while(1) delay(1); // koniec pracy! } Po uruchomieniu - o ile nasz klient ma dostęp do Internetu - powinien połączyć się z serwerem Google, pobrać zawartość strony głównej i wypisać ją na monitorze Serial: Jak widać, klient bardzo grzecznie pobrał wszystko co mu google wysłał i bez wnikania w szczegóły wyrzucił na wyjście. No nic - od klienta powinniśmy oczekiwać czegoś więcej. Przede wszystkim reakcji na błędy... a już na pewno stwierdzenia, czy nie wystąpił błąd. Spróbujmy więc stworzyć... sprytniejszego klienta HTTP Tym razem będziemy łączyć się z naszym serwerem, więc musimy pamiętać, aby go uruchomić! // Podaj właściwy adres i port serwera IPAddress Server(192,168,1,5); const int ServerPort = 8001; void loop() { MyClient client; char bufor[BUFFER_LENGTH]; if (!client.connect(Server, ServerPort)) { Serial.println(F("Brak połączenia z serwerem")); delay(5000); return; } client.setTimeout(5000); client.print(F("GET / HTTP/1.0\r\n\r\n")); // wczytujemy pierwszą linię odpowiedzi serwera int n = client.readBytesUntil('\n',bufor, BUFFER_LENGTH-1); bufor[n]=0; // uzupełniamy kończące '\0' // teraz po prostu sprawdzimy, czy w buforze znajduje się // string " 200 " - jeśli nie, jest to błąd! if (!strstr(bufor, " 200 ")) { client.stop(); // dalej nie gadamy Serial.print(F("Otrzymano odpowiedź: ")); Serial.println(bufor); delay(10000); // czekamy 10 sekund return; } // możemy pominąć pozostałe nagłówki jako mało interesujące: bool naglowki_wczytane = false; while(client.connected()) { n = client.readBytesUntil('\n',bufor,BUFFER_LENGTH-1); bufor[n]=0; Serial.print("Nagłówek: "); Serial.println(bufor); if (n == 1) { // w buforze jest jeden znak '\r' naglowki_wczytane = true; break; } } if (!naglowki_wczytane) { Serial.println(F("Błąd odczytu nagłówków")); client.stop(); delay(10000); return; } // teraz całą resztę wczytujemy do bufora n=client.readBytes(bufor, BUFFER_LENGTH-1); bufor[n]=0; client.stop(); Serial.print(F("Odpowiedź serwera: ")); Serial.println(bufor); delay(5000); } Trochę tu pooszukiwaliśmy - nie sprawdzamy całej pierwszej linii, ale wystarczy aby linia zawierała napis "<spacja>200<spacja>" - możemy to uznać za potwierdzenie. Tym razem zobaczymy, jak działa serwer w połączenia z dwoma klientami. Po ukazaniu się pierwszej informacji wchodzimy przeglądarką na adres: http://adres_ip_serwera/set/123 Po powrocie do monitora widzimy, że serwer zapamiętał tę liczbę i bardzo grzecznie nam ją przekazuje. A więc już teraz możemy zobaczyć, że serwer może służyć jako pośrednik wymiany danych między dwoma klientami! Jeśli jednak przyjrzymy się uważniej temu, co wypisuje monitor serial, zobaczymy że coś jest nie w porządku. Na wszelki wypadek możemy włączyć opcję "pokaż znacznik czasu" w monitorze i... O właśnie. Między odebraniem ostatniej linii nagłówków a odebraniem właściwych danych mija dokładnie 5 sekund. Czyżby serwer opóźniał w jakiś sposób wysyłanie danych? Nie - serwer wysyła tak jak trzeba. Po prostu dla bezpieczeństwa ustawiliśmy w kodzie: client.timeout(5000); i w związku z tym klient nie jest w stanie stwierdzić, czy serwer rzeczywiście się rozłączył - na wszelki wypadek czekając 5 sekund. Jak temu zaradzić? Otóż na razie korzystaliśmy z najprostszej metody: czytamy z klienta aż do końca. Problematyczna jest tu po prostu klasa Stream i jej metoda read(), która nie potrafi jednoznacznie zasygnalizować czy klient już zakończył połączenie, czy namyśla się nad wysłaniem dalszych danych. A readBytes na wszelki wypadek czeka te 5 sekund zanim zwróci wynik... Co w takiej sytuacji? Teoretycznie można by czytać sobie po znaku i w przypadku braku owego sprawdzać, czy klient się przypadkiem nie rozłączył. Nie byłoby to specjalnie efektywne - poza tym metoda "czytaj do końca" ma jedną zasadniczą wadę: tak naprawdę nie wiemy, z jakich powodów ów koniec nastąpił; być może swerwer wysłał już wszystko co ma do wysłania - a być może jakaś awaria (serwera czy któregoś z pośredniczących routerów) uniemożliwiła mu wysłanie wszystkiego do końca. Na szczęście istnieje na to bardzo prosty sposób. Serwer wysyła nagłówek ContentLength informujący, ile bajtów będzie liczyła właściwa odpowiedź. Klient powinien zanalizować ten nagłówek i po odebraniu tylu bajtów nie czekać więcej, tylko zamykać połączenie, a w przypadku przedwczesnego zakończenia transmicji (czyli odebrania mniejszej ilości bajtów od zadeklarowanej i wykrycia końca transmisji) zasygnalizować błąd. Jeśli korzystamy z serwera w pythonie ma on już wbudowaną taką funkcjonalność. Jeśli natomiast jako serwera używamy drugiego egzemplarza płytki - należy nieco zmodyfikować kod serwera. Nowy fragment kodu będzie wyglądać tak: int pot = analogRead(POT_PIN); int key = digitalRead(KEY_PIN); int length = sprintf(bufor, "%d %d %d\n", pot, key, nasza_zmienna); // wypisujemy nagłówki client.print(F("HTTP/1.1 200 OK\r\nContent-Type: text/plain\r\nContent-Length=")); client.print(length); client.print(F("\r\n\r\n")); // teraz jeśli zapytanie było GET wysyłamy przygotowane dane if (!isHead) { client.print(bufor); } a kompletny kod dostępny jest w załączniku. Teraz zajmiemy się klientem. Nie możemu już sobie pozwolić na pominięcie wszystkiego aż do pustej linii - musimy analizować wszystkie nagłówki, bo nie wiadomo w którym (i czy w ogóle) będzie interesująca nas wartość. Przyjmijmy, że jeśli nagłówek ContentLength nie wystąpił - wracamy do poprzedniej metody czytania aż do końca połączenia. A więc stwórzmy teraz... szybszego klienta HTTP Nowy kod wygląda w ten sposób: // Podaj właściwy adres i port serwera IPAddress Server(192,168,1,5); const int ServerPort = 8001; #define LENGTH_UNKNOWN -1 void loop() { MyClient client; char bufor[BUFFER_LENGTH]; if (!client.connect(Server, ServerPort)) { Serial.println(F("Brak połączenia z serwerem")); delay(5000); return; } client.setTimeout(5000); client.print(F("GET / HTTP/1.0\r\n\r\n")); // wczytujemy pierwszą linię odpowiedzi serwera int n = client.readBytesUntil('\n',bufor, BUFFER_LENGTH-1); bufor[n]=0; // uzupełniamy kończące '\0' // teraz po prostu sprawdzimy, czy w buforze znajduje się // string " 200 " - jeśli nie, jest to błąd! if (!strstr(bufor, " 200 ")) { client.stop(); // dalej nie gadamy Serial.print(F("Otrzymano odpowiedź: ")); Serial.println(bufor); delay(10000); // czekamy 10 sekund return; } // wczytujemy po kolei nagłówki, szukając Content-Length int ContentLength = LENGTH_UNKNOWN; bool naglowki_wczytane = false; while(client.connected()) { n = client.readBytesUntil('\n',bufor,BUFFER_LENGTH-1); bufor[n]=0; Serial.print("Nagłówek: "); Serial.println(bufor); if (n == 1) { // w buforze jest jeden znak '\r' naglowki_wczytane = true; break; } if (!strncasecmp(bufor,"content-length:", 15)) { ContentLength = atoi(bufor+15); } } if (!naglowki_wczytane) { Serial.println(F("Błąd odczytu nagłówków")); client.stop(); delay(10000); return; } Serial.print(F("Rozmiar danych: ")); Serial.println(ContentLength); // teraz całą resztę wczytujemy do bufora if (ContentLength > BUFFER_LENGTH -1 || ContentLength == LENGTH_UNKNOWN) { ContentLength = BUFFER_LENGTH - 1; } n=client.readBytes(bufor, ContentLength); bufor[n]=0; client.stop(); if (n < ContentLength) { Serial.println(F("Odpowiedź niekompletna")); } else { Serial.print(F("Odpowiedź serwera: ")); Serial.println(bufor); } delay(5000); } Jak widać nieco się skomplikował. Pewnie nie wymaga objaśnień poza jednym drobiazgiem: Zmienna ContentLength jest zdeklarowana jako int. Nasuwałoby się od razu - dlaczego nie unsigned int? Przecież długość nie może być ujemna... Owszem, moglibyśmy zdeklarować ją jako unsigned. Tyle że wtedy musielibyśmy wprowadzić dodatkową zmienną tylko do tego, aby zasygnalizować wystąpienie tego nagłówka (bo wartość zero jest jak najbardziej prawidłowa). W tym przypadku podstawiamy liczbę ujemną przed czytaniem nagłówków i po ich odczytaniu od razu wiemy: jeśli liczba jest nieujemna mamy tam wielkość przesyłanych danych, w przeciwnym przypadku wielkość jest nieznana. Po uruchomieniu wyniki wyglądają następująco: Jak widać nie ma tu żadnego oczekiwania, wyniki pokazują się natychmiast. No, to już wiemy po co są nagłówki (przynajmniej niektóre). Jak widać - niosą one ze sobą różne informacje: w przypadku klienta - np. o tym, w jakiej postaci chaciałby najchętniej mieć podane dane; w przpadku serwera - w jakiej postaci te dane podano. Ale może czas już na coś konkretnego... w końcu do płytki mamy podłączony jakiś potencjometr i przycisk a dotychczas go nie używaliśmy... A więc naprawmy tę sytuację tworząc... prawdziwego klienta HTTP dla IoT Tym razem nie będziemy jednak wrzucać całego kodu do loop(), stworzymy funkcję, której zadaniem będzie: wysłanie na serwer wartości parametru; odebranie danych z serwera i wypisanie ich na monitorze serial; zwrócenie informacji czy operacja się udała. Ta funkcja powinna być wywołana po wciśnięciu przycisku, a argumentem funkcji niech będzie wartość odczytana z wejścia analogowego. Tym razem musimy skonstruować zapytanie. Wbrew pozorom jest to bardzo proste - za pomocą funkcji sprintf umieszczamy w buforze odpowiedni napis i wysyłamy zawartość bufora na serwer. Nowy kod będzie wyglądać następująco: // Podaj właściwy adres i port serwera IPAddress Server(192,168,1,5); const int ServerPort = 8001; #define LENGTH_UNKNOWN -1 bool zapisz(int dane) { // funkcja zwraca true jeśli udało się zapisać dane // false jeśli wystąpił błąd MyClient client; char bufor[BUFFER_LENGTH]; Serial.print(F("Wartość parametru: ")); Serial.println(dane); if (!client.connect(Server, ServerPort)) { Serial.println(F("Brak połączenia z serwerem")); delay(50); return false; } client.setTimeout(5000); // tworzymy zapytanie do serwera sprintf(bufor,"GET /set/%d HTTP/1.0\r\n\r\n", dane); client.print(bufor); // nie stosujemy Serial.println() gdyż w buforze // są już znaki końca linii Serial.print(F("Wysyłam zapytanie: ")); Serial.print(bufor); // wczytujemy pierwszą linię odpowiedzi serwera int n = client.readBytesUntil('\n',bufor, BUFFER_LENGTH-1); bufor[n]=0; // uzupełniamy kończące '\0' // teraz po prostu sprawdzimy, czy w buforze znajduje się // string " 200 " - jeśli nie, jest to błąd! if (!strstr(bufor, " 200 ")) { client.stop(); // dalej nie gadamy Serial.print(F("Otrzymano odpowiedź: ")); Serial.println(bufor); delay(1000); // czekamy sekundę return false; } // wczytujemy po kolei nagłówki, szukając Content-Length int ContentLength = LENGTH_UNKNOWN; bool naglowki_wczytane = false; while(client.connected()) { n = client.readBytesUntil('\n',bufor,BUFFER_LENGTH-1); bufor[n]=0; Serial.print(F("Nagłówek: ")); Serial.println(bufor); if (n == 1) { // w buforze jest jeden znak '\r' naglowki_wczytane = true; break; } if (!strncasecmp(bufor,"content-length:", 15)) { ContentLength = atoi(bufor+15); } } if (!naglowki_wczytane) { Serial.println(F("Błąd odczytu nagłówków")); client.stop(); delay(1000); return false; } Serial.print(F("Rozmiar danych: ")); Serial.println(ContentLength); // teraz całą resztę wczytujemy do bufora if (ContentLength > BUFFER_LENGTH -1 || ContentLength == LENGTH_UNKNOWN) { ContentLength = BUFFER_LENGTH - 1; } n=client.readBytes(bufor, ContentLength); bufor[n]=0; client.stop(); if (n < ContentLength) { Serial.println(F("Odpowiedź niekompletna")); } else { Serial.print(F("Odpowiedź serwera: ")); Serial.println(bufor); } return true; } void loop() { static int lastKey = digitalRead(KEY_PIN); int key = digitalRead(KEY_PIN); // jeśli klawisz został wciśnięty, wysyłamy wartość // odczytaną z wejścia analogowego na serwer if (lastKey && !key) { int i,pot; pot = analogRead(POT_PIN); for (i=0; i<10; i++) { // więcej niż 10 prób wysłania nie ma sensu if (zapisz(pot)) break; } if (i==10) { Serial.println(F("Nie udało się wysłać danych")); } } lastKey=key; } Po uruchomieniu programu możemy zobaczyć, że każde naciśnięcie przycisku powoduje zmianę wartości podawanej przez serwer: Aby to lepiej zobrazować możemy spróbować podejrzeć co się dzieje na serwerze w czasie rzeczywistym. Jeśli mamy jakiegoś linuksa (prawdopodobnie na maku też to zadziała) możemy wpisać po prostu polecenie: watch -n 5 wget -q -O - http://127.0.0.1:8001 Oczywiście jeśli korzystamy z innego serwera niż nasz pythonowy musimy wpisać zamiast 127.0.0.1:8001 właściwy adres i port. Wykonanie tego polecenia spowoduje, że polecenie wget będzie wykonywane co 5 sekund, a wartość odczytana z serwera będzie wyświetlana na ekranie. W przypadku windowsa nie jest to już takie proste... ale od czego mamy nagłówki serwera? W pliku miniserver.py znajdujemy linię zawierającą: #self.send_header("Refresh", 5) i odkomentowujemy polecenie usuwając znak #: self.send_header("Refresh", 5) i oczywiście restartujemy serwer. Spowoduje to wysłanie dodatkowego nagłówka Refresh: 5 Jeśli teraz wejdziemy na ten adres zwykłą przeglądarką - będzie ona odświeżać wyświetlane wyniki co 5 sekund. Oczywiście zadziała to również na Linuksie i Maku! Niezależnie od metody - możemy teraz zobaczyć jak po wciśnięciu przycisku dane wędrują od naszego klienta poprzez serwer do przeglądarki. I to by było na tyle. Miała być co prawda jeszcze czwarta część poświęcona praktycznym rozwiązaniom - okazało się jednak, że ilość materiału który należałoby omówić wymaga osobnego, kilkuczęściowego artykułu. Toteż na tym na razie musimy poprzestać i pożegnać się do następnego spotkania. Kody wszystkich programów dostępne są w załączniku: klient.zip Spis treści serii artykułów: Protokół HTTP w zastosowaniach IoT - część 1: trochę teorii Protokół HTTP w zastosowaniach IoT - część 2: budujemy serwer Protokół HTTP w zastosowaniach IoT - część 3: tworzymy klienta
Po przeczytaniu dwóch poprzednich części znamy już pobieżnie zasady działania HTTP, potrafimy już stworzyć prosty (choć prawdopodobnie użyteczny) serwer. Ale przecież serwer to dopiero połowa - drugą, równie ważną jest klient. I znów będziemy próbować przesyłać między serwerem a klientem dane dotyczące stanu wejść naszego Arduino (czyli najprawdopodobniej jakichś czujników). Ten wpis brał udział konkursie na najlepszy artykuł o elektronice lub programowaniu. Sprawdź wyniki oraz listę wszystkich prac » Partnerem tej edycji konkursu (marzec 2020) był popularny producent obwodów drukowanych, firma PCBWay. Spis treści serii artykułów: Protokół HTTP w zastosowaniach IoT - część 1: trochę teorii Protokół HTTP w zastosowaniach IoT - część 2: budujemy serwer Protokół HTTP w zastosowaniach IoT - część 3: tworzymy klienta I tu uwaga: ponieważ musimy użyć dwóch urządzeń, potrzebne byłyby dwie identyczne płytki. Ponieważ nie każdy ma akurat w szufladzie dwa takie same układy - możemy zasymulować działanie takiego serwera używając naszego komputera. W tym celu w załączniku znajduje się krótki program napisany w Pythonie. Serwer działa na porcie 8001 zamast 80. Gdybyśmy jednak chcieli zmienić to zachowanie, musimy pamiętać, że: na naszym serwerze nie może działać żaden inny serwer na porcie 80; w przypadku Linuksa aby serwer mógł działać na porcie 80, musimy go uruchamiać z konta root (np. przez sudo) - normalny użytkownik nie może uruchamiać serwerów na portach niższych niż 1024. Jeśli chcemy, aby nasz serwer uruchamiał się na inym porcie niż 8001 - po prostu musimy znaleźć linijkę: port = 8001 i zamienić liczbę 8001 na numer portu. Serwer uruchamiamy z konsoli po wejściu do katalogu zawierającego program poleceniem: python3 miniserver.py lub odpowiednikiem dla naszego systemu operacyjnego. Jeśli nasz komputer ma zainstalowanego firewalla, należy zezwolić na dostęp z zewnątrz dla naszego serwera. Ponieważ różne firewalle mają różne metody służące do takowego zezwalania - odsyłam do dokumentacji naszego firewalla. Po uruchomieniu serwera możemy sprawdzić jego działanie wchodząc przeglądarką na adres http://ip_naszego_komputera:8001/ lub http://localhost:8001/ - powinny ukazać się trzy liczby. Jako że nasz komputer nie ma najprawdopodobniej podłączonych żadnych potencjometrów czy przycisków - liczba odpowiadająca potencjometrowi jest po prostu brana z generatora losowego, a klawiszowi zmienia się za każdym wywołaniem. Tyle tytułem przydługiego wstępu, możemy wreszcie zabrać się za tworzenie... klienta HTTP Ponieważ do klienta będą potrzebne takie same płytki jak do serwera, przypominam układy połączeń dla Arduino z shieldem Ethernet oraz płytek ESP3266 i ESP32: I znów jak poprzednio użyjemy wspólnego fragmentu kodu. Będzie on bardzo podobny do kodu używanego przy pisaniu serwera. Jedynymi różnicami są brak deklaracji i uruchomienia serwera oraz zdefiniowanie wielkości bufora (różne dla małego Arduino i większych płytek). Należy pamiętać, że w przypadku Ethernetu musimy zapewnić unikalność adresów MAC! #ifdef AVR // część dla Arduino i Ethernet Shield #include <SPI.h> #include <Ethernet.h> #define POT_PIN A1 #define KEY_PIN A0 byte mac[] = { 0xDE, 0xAD, 0xBE, 0xEF, 0xFE, 0xEE }; #define MyServer EthernetServer #define MyClient EthernetClient #define SERIAL_SPEED 9600 void init_network(void) { Ethernet.begin(mac); while (Ethernet.linkStatus() == LinkOFF) { Serial.println(F("Ethernet cable is not connected.")); delay(500); } // dajmy mu trochę czasu na połączenie delay(1000); Serial.print(F("Adres: ")); Serial.println(Ethernet.localIP()); } #else // część dla ESP #ifdef ESP32 #include <WiFi.h> #define POT_PIN 32 #define KEY_PIN 16 #else #include <ESP8266WiFi.h> #define POT_PIN A0 #define KEY_PIN 4 #endif const char* ssid = "My_SSID"; const char* password = "My_Password"; #define MyServer WiFiServer #define MyClient WiFiClient #define SERIAL_SPEED 115200 void init_network(void) { WiFi.mode(WIFI_STA); WiFi.begin(ssid, password); while (WiFi.status() != WL_CONNECTED) { delay(500); Serial.print("."); } Serial.println(); Serial.print("Połączono z WiFi, adres: "); Serial.println(WiFi.localIP()); } #endif void setup(void) { Serial.begin(SERIAL_SPEED); #ifdef __AVR_ATmega32U4__ while (!Serial); // potrzebne tylko dla Leonardo/Micro #endif init_network(); pinMode(KEY_PIN, INPUT_PULLUP); } #ifdef AVR #define BUFFER_LENGTH 128 #else #define BUFFER_LENGTH 1024 #endif Pierwszy klient będzie bardzo prosty. Nie musimy na razie uruchamiać naszego serwera, zamiast tego połączymy się z serwerem Google: const char Server[]="www.google.pl"; const int ServerPort = 80; void loop() { MyClient client; if (!client.connect(Server, ServerPort)) { Serial.println(F("Brak połączenia z serwerem")); delay(5000); return; } // pytamy googla o stronę główną client.print(F("GET / HTTP/1.1\r\nHost: www.google.pl\r\nCpnnection: Close\r\n\r\n")); // po prostu wypisujemy na monitorze serial // wszystko co dostaliśmy z serwera while (client.connected()) { if (client.available()) { char c = client.read(); Serial.print(c); } else { delay(5); // poczekamy chwilę aż serwer wyśle coś więcej } } client.stop(); while(1) delay(1); // koniec pracy! } Po uruchomieniu - o ile nasz klient ma dostęp do Internetu - powinien połączyć się z serwerem Google, pobrać zawartość strony głównej i wypisać ją na monitorze Serial: Jak widać, klient bardzo grzecznie pobrał wszystko co mu google wysłał i bez wnikania w szczegóły wyrzucił na wyjście. No nic - od klienta powinniśmy oczekiwać czegoś więcej. Przede wszystkim reakcji na błędy... a już na pewno stwierdzenia, czy nie wystąpił błąd. Spróbujmy więc stworzyć... sprytniejszego klienta HTTP Tym razem będziemy łączyć się z naszym serwerem, więc musimy pamiętać, aby go uruchomić! // Podaj właściwy adres i port serwera IPAddress Server(192,168,1,5); const int ServerPort = 8001; void loop() { MyClient client; char bufor[BUFFER_LENGTH]; if (!client.connect(Server, ServerPort)) { Serial.println(F("Brak połączenia z serwerem")); delay(5000); return; } client.setTimeout(5000); client.print(F("GET / HTTP/1.0\r\n\r\n")); // wczytujemy pierwszą linię odpowiedzi serwera int n = client.readBytesUntil('\n',bufor, BUFFER_LENGTH-1); bufor[n]=0; // uzupełniamy kończące '\0' // teraz po prostu sprawdzimy, czy w buforze znajduje się // string " 200 " - jeśli nie, jest to błąd! if (!strstr(bufor, " 200 ")) { client.stop(); // dalej nie gadamy Serial.print(F("Otrzymano odpowiedź: ")); Serial.println(bufor); delay(10000); // czekamy 10 sekund return; } // możemy pominąć pozostałe nagłówki jako mało interesujące: bool naglowki_wczytane = false; while(client.connected()) { n = client.readBytesUntil('\n',bufor,BUFFER_LENGTH-1); bufor[n]=0; Serial.print("Nagłówek: "); Serial.println(bufor); if (n == 1) { // w buforze jest jeden znak '\r' naglowki_wczytane = true; break; } } if (!naglowki_wczytane) { Serial.println(F("Błąd odczytu nagłówków")); client.stop(); delay(10000); return; } // teraz całą resztę wczytujemy do bufora n=client.readBytes(bufor, BUFFER_LENGTH-1); bufor[n]=0; client.stop(); Serial.print(F("Odpowiedź serwera: ")); Serial.println(bufor); delay(5000); } Trochę tu pooszukiwaliśmy - nie sprawdzamy całej pierwszej linii, ale wystarczy aby linia zawierała napis "<spacja>200<spacja>" - możemy to uznać za potwierdzenie. Tym razem zobaczymy, jak działa serwer w połączenia z dwoma klientami. Po ukazaniu się pierwszej informacji wchodzimy przeglądarką na adres: http://adres_ip_serwera/set/123 Po powrocie do monitora widzimy, że serwer zapamiętał tę liczbę i bardzo grzecznie nam ją przekazuje. A więc już teraz możemy zobaczyć, że serwer może służyć jako pośrednik wymiany danych między dwoma klientami! Jeśli jednak przyjrzymy się uważniej temu, co wypisuje monitor serial, zobaczymy że coś jest nie w porządku. Na wszelki wypadek możemy włączyć opcję "pokaż znacznik czasu" w monitorze i... O właśnie. Między odebraniem ostatniej linii nagłówków a odebraniem właściwych danych mija dokładnie 5 sekund. Czyżby serwer opóźniał w jakiś sposób wysyłanie danych? Nie - serwer wysyła tak jak trzeba. Po prostu dla bezpieczeństwa ustawiliśmy w kodzie: client.timeout(5000); i w związku z tym klient nie jest w stanie stwierdzić, czy serwer rzeczywiście się rozłączył - na wszelki wypadek czekając 5 sekund. Jak temu zaradzić? Otóż na razie korzystaliśmy z najprostszej metody: czytamy z klienta aż do końca. Problematyczna jest tu po prostu klasa Stream i jej metoda read(), która nie potrafi jednoznacznie zasygnalizować czy klient już zakończył połączenie, czy namyśla się nad wysłaniem dalszych danych. A readBytes na wszelki wypadek czeka te 5 sekund zanim zwróci wynik... Co w takiej sytuacji? Teoretycznie można by czytać sobie po znaku i w przypadku braku owego sprawdzać, czy klient się przypadkiem nie rozłączył. Nie byłoby to specjalnie efektywne - poza tym metoda "czytaj do końca" ma jedną zasadniczą wadę: tak naprawdę nie wiemy, z jakich powodów ów koniec nastąpił; być może swerwer wysłał już wszystko co ma do wysłania - a być może jakaś awaria (serwera czy któregoś z pośredniczących routerów) uniemożliwiła mu wysłanie wszystkiego do końca. Na szczęście istnieje na to bardzo prosty sposób. Serwer wysyła nagłówek ContentLength informujący, ile bajtów będzie liczyła właściwa odpowiedź. Klient powinien zanalizować ten nagłówek i po odebraniu tylu bajtów nie czekać więcej, tylko zamykać połączenie, a w przypadku przedwczesnego zakończenia transmicji (czyli odebrania mniejszej ilości bajtów od zadeklarowanej i wykrycia końca transmisji) zasygnalizować błąd. Jeśli korzystamy z serwera w pythonie ma on już wbudowaną taką funkcjonalność. Jeśli natomiast jako serwera używamy drugiego egzemplarza płytki - należy nieco zmodyfikować kod serwera. Nowy fragment kodu będzie wyglądać tak: int pot = analogRead(POT_PIN); int key = digitalRead(KEY_PIN); int length = sprintf(bufor, "%d %d %d\n", pot, key, nasza_zmienna); // wypisujemy nagłówki client.print(F("HTTP/1.1 200 OK\r\nContent-Type: text/plain\r\nContent-Length=")); client.print(length); client.print(F("\r\n\r\n")); // teraz jeśli zapytanie było GET wysyłamy przygotowane dane if (!isHead) { client.print(bufor); } a kompletny kod dostępny jest w załączniku. Teraz zajmiemy się klientem. Nie możemu już sobie pozwolić na pominięcie wszystkiego aż do pustej linii - musimy analizować wszystkie nagłówki, bo nie wiadomo w którym (i czy w ogóle) będzie interesująca nas wartość. Przyjmijmy, że jeśli nagłówek ContentLength nie wystąpił - wracamy do poprzedniej metody czytania aż do końca połączenia. A więc stwórzmy teraz... szybszego klienta HTTP Nowy kod wygląda w ten sposób: // Podaj właściwy adres i port serwera IPAddress Server(192,168,1,5); const int ServerPort = 8001; #define LENGTH_UNKNOWN -1 void loop() { MyClient client; char bufor[BUFFER_LENGTH]; if (!client.connect(Server, ServerPort)) { Serial.println(F("Brak połączenia z serwerem")); delay(5000); return; } client.setTimeout(5000); client.print(F("GET / HTTP/1.0\r\n\r\n")); // wczytujemy pierwszą linię odpowiedzi serwera int n = client.readBytesUntil('\n',bufor, BUFFER_LENGTH-1); bufor[n]=0; // uzupełniamy kończące '\0' // teraz po prostu sprawdzimy, czy w buforze znajduje się // string " 200 " - jeśli nie, jest to błąd! if (!strstr(bufor, " 200 ")) { client.stop(); // dalej nie gadamy Serial.print(F("Otrzymano odpowiedź: ")); Serial.println(bufor); delay(10000); // czekamy 10 sekund return; } // wczytujemy po kolei nagłówki, szukając Content-Length int ContentLength = LENGTH_UNKNOWN; bool naglowki_wczytane = false; while(client.connected()) { n = client.readBytesUntil('\n',bufor,BUFFER_LENGTH-1); bufor[n]=0; Serial.print("Nagłówek: "); Serial.println(bufor); if (n == 1) { // w buforze jest jeden znak '\r' naglowki_wczytane = true; break; } if (!strncasecmp(bufor,"content-length:", 15)) { ContentLength = atoi(bufor+15); } } if (!naglowki_wczytane) { Serial.println(F("Błąd odczytu nagłówków")); client.stop(); delay(10000); return; } Serial.print(F("Rozmiar danych: ")); Serial.println(ContentLength); // teraz całą resztę wczytujemy do bufora if (ContentLength > BUFFER_LENGTH -1 || ContentLength == LENGTH_UNKNOWN) { ContentLength = BUFFER_LENGTH - 1; } n=client.readBytes(bufor, ContentLength); bufor[n]=0; client.stop(); if (n < ContentLength) { Serial.println(F("Odpowiedź niekompletna")); } else { Serial.print(F("Odpowiedź serwera: ")); Serial.println(bufor); } delay(5000); } Jak widać nieco się skomplikował. Pewnie nie wymaga objaśnień poza jednym drobiazgiem: Zmienna ContentLength jest zdeklarowana jako int. Nasuwałoby się od razu - dlaczego nie unsigned int? Przecież długość nie może być ujemna... Owszem, moglibyśmy zdeklarować ją jako unsigned. Tyle że wtedy musielibyśmy wprowadzić dodatkową zmienną tylko do tego, aby zasygnalizować wystąpienie tego nagłówka (bo wartość zero jest jak najbardziej prawidłowa). W tym przypadku podstawiamy liczbę ujemną przed czytaniem nagłówków i po ich odczytaniu od razu wiemy: jeśli liczba jest nieujemna mamy tam wielkość przesyłanych danych, w przeciwnym przypadku wielkość jest nieznana. Po uruchomieniu wyniki wyglądają następująco: Jak widać nie ma tu żadnego oczekiwania, wyniki pokazują się natychmiast. No, to już wiemy po co są nagłówki (przynajmniej niektóre). Jak widać - niosą one ze sobą różne informacje: w przypadku klienta - np. o tym, w jakiej postaci chaciałby najchętniej mieć podane dane; w przpadku serwera - w jakiej postaci te dane podano. Ale może czas już na coś konkretnego... w końcu do płytki mamy podłączony jakiś potencjometr i przycisk a dotychczas go nie używaliśmy... A więc naprawmy tę sytuację tworząc... prawdziwego klienta HTTP dla IoT Tym razem nie będziemy jednak wrzucać całego kodu do loop(), stworzymy funkcję, której zadaniem będzie: wysłanie na serwer wartości parametru; odebranie danych z serwera i wypisanie ich na monitorze serial; zwrócenie informacji czy operacja się udała. Ta funkcja powinna być wywołana po wciśnięciu przycisku, a argumentem funkcji niech będzie wartość odczytana z wejścia analogowego. Tym razem musimy skonstruować zapytanie. Wbrew pozorom jest to bardzo proste - za pomocą funkcji sprintf umieszczamy w buforze odpowiedni napis i wysyłamy zawartość bufora na serwer. Nowy kod będzie wyglądać następująco: // Podaj właściwy adres i port serwera IPAddress Server(192,168,1,5); const int ServerPort = 8001; #define LENGTH_UNKNOWN -1 bool zapisz(int dane) { // funkcja zwraca true jeśli udało się zapisać dane // false jeśli wystąpił błąd MyClient client; char bufor[BUFFER_LENGTH]; Serial.print(F("Wartość parametru: ")); Serial.println(dane); if (!client.connect(Server, ServerPort)) { Serial.println(F("Brak połączenia z serwerem")); delay(50); return false; } client.setTimeout(5000); // tworzymy zapytanie do serwera sprintf(bufor,"GET /set/%d HTTP/1.0\r\n\r\n", dane); client.print(bufor); // nie stosujemy Serial.println() gdyż w buforze // są już znaki końca linii Serial.print(F("Wysyłam zapytanie: ")); Serial.print(bufor); // wczytujemy pierwszą linię odpowiedzi serwera int n = client.readBytesUntil('\n',bufor, BUFFER_LENGTH-1); bufor[n]=0; // uzupełniamy kończące '\0' // teraz po prostu sprawdzimy, czy w buforze znajduje się // string " 200 " - jeśli nie, jest to błąd! if (!strstr(bufor, " 200 ")) { client.stop(); // dalej nie gadamy Serial.print(F("Otrzymano odpowiedź: ")); Serial.println(bufor); delay(1000); // czekamy sekundę return false; } // wczytujemy po kolei nagłówki, szukając Content-Length int ContentLength = LENGTH_UNKNOWN; bool naglowki_wczytane = false; while(client.connected()) { n = client.readBytesUntil('\n',bufor,BUFFER_LENGTH-1); bufor[n]=0; Serial.print(F("Nagłówek: ")); Serial.println(bufor); if (n == 1) { // w buforze jest jeden znak '\r' naglowki_wczytane = true; break; } if (!strncasecmp(bufor,"content-length:", 15)) { ContentLength = atoi(bufor+15); } } if (!naglowki_wczytane) { Serial.println(F("Błąd odczytu nagłówków")); client.stop(); delay(1000); return false; } Serial.print(F("Rozmiar danych: ")); Serial.println(ContentLength); // teraz całą resztę wczytujemy do bufora if (ContentLength > BUFFER_LENGTH -1 || ContentLength == LENGTH_UNKNOWN) { ContentLength = BUFFER_LENGTH - 1; } n=client.readBytes(bufor, ContentLength); bufor[n]=0; client.stop(); if (n < ContentLength) { Serial.println(F("Odpowiedź niekompletna")); } else { Serial.print(F("Odpowiedź serwera: ")); Serial.println(bufor); } return true; } void loop() { static int lastKey = digitalRead(KEY_PIN); int key = digitalRead(KEY_PIN); // jeśli klawisz został wciśnięty, wysyłamy wartość // odczytaną z wejścia analogowego na serwer if (lastKey && !key) { int i,pot; pot = analogRead(POT_PIN); for (i=0; i<10; i++) { // więcej niż 10 prób wysłania nie ma sensu if (zapisz(pot)) break; } if (i==10) { Serial.println(F("Nie udało się wysłać danych")); } } lastKey=key; } Po uruchomieniu programu możemy zobaczyć, że każde naciśnięcie przycisku powoduje zmianę wartości podawanej przez serwer: Aby to lepiej zobrazować możemy spróbować podejrzeć co się dzieje na serwerze w czasie rzeczywistym. Jeśli mamy jakiegoś linuksa (prawdopodobnie na maku też to zadziała) możemy wpisać po prostu polecenie: watch -n 5 wget -q -O - http://127.0.0.1:8001 Oczywiście jeśli korzystamy z innego serwera niż nasz pythonowy musimy wpisać zamiast 127.0.0.1:8001 właściwy adres i port. Wykonanie tego polecenia spowoduje, że polecenie wget będzie wykonywane co 5 sekund, a wartość odczytana z serwera będzie wyświetlana na ekranie. W przypadku windowsa nie jest to już takie proste... ale od czego mamy nagłówki serwera? W pliku miniserver.py znajdujemy linię zawierającą: #self.send_header("Refresh", 5) i odkomentowujemy polecenie usuwając znak #: self.send_header("Refresh", 5) i oczywiście restartujemy serwer. Spowoduje to wysłanie dodatkowego nagłówka Refresh: 5 Jeśli teraz wejdziemy na ten adres zwykłą przeglądarką - będzie ona odświeżać wyświetlane wyniki co 5 sekund. Oczywiście zadziała to również na Linuksie i Maku! Niezależnie od metody - możemy teraz zobaczyć jak po wciśnięciu przycisku dane wędrują od naszego klienta poprzez serwer do przeglądarki. I to by było na tyle. Miała być co prawda jeszcze czwarta część poświęcona praktycznym rozwiązaniom - okazało się jednak, że ilość materiału który należałoby omówić wymaga osobnego, kilkuczęściowego artykułu. Toteż na tym na razie musimy poprzestać i pożegnać się do następnego spotkania. Kody wszystkich programów dostępne są w załączniku: klient.zip Spis treści serii artykułów: Protokół HTTP w zastosowaniach IoT - część 1: trochę teorii Protokół HTTP w zastosowaniach IoT - część 2: budujemy serwer Protokół HTTP w zastosowaniach IoT - część 3: tworzymy klienta








-
Z poprzedniej części mogliśmy się dowiedzieć, co to takiego ten cały HTTP -jak się okazało, nic strasznie skomplikowanego. Dzisiaj zajmiemy się praktyczną stroną - czyli napisaniem najprostszego serwera. Oczywiście - jako że temat traktuje o IoT - serwer będzie udostępniał dane odczytane z jakichś czujników. Już słyszę: a dlaczego serwer a nie klient, przecież klient powinien być łatwiejszy? Ten wpis brał udział konkursie na najlepszy artykuł o elektronice lub programowaniu. Sprawdź wyniki oraz listę wszystkich prac » Partnerem tej edycji konkursu (marzec 2020) był popularny producent obwodów drukowanych, firma PCBWay. A dlatego, że aby sprawdzić działanie klienta, należy mieć serwer a takiego na razie nie mamy. Natomiast klienta HTTP ma tu raczej każdy - począwszy od przeglądarek, poprzez przeróżne wgety i curle kończąc na PuTTY i netcacie. Przyjrzyjmy się więc dokładniej, jak działa. Spis treści serii artykułów: Protokół HTTP w zastosowaniach IoT - część 1: trochę teorii Protokół HTTP w zastosowaniach IoT - część 2: budujemy serwer Protokół HTTP w zastosowaniach IoT - część 3: tworzymy klienta Serwer HTTP W najprostszym przypadku serwer po podłączeniu do sieci po prostu czeka na zgłoszenie klienta, wykonuje jakąś tam funkcję obsługi, rozłącza się z klientem i powraca do czekania. Spróbujmy napisać taki program. Ponieważ dla różnych płytek i modułów łączenia z siecią program może być różny, spróbujmy stworzyć przynajmniej dwa (czyli Arduino z Ethernet Shield i dla ESP8266/ESP32). Zacznijmy od jakichś założeń. A więc: Do płytki podłączony jest potencjometr 10 kΩ i przycisk; Serwer w odpowiedzi na zapytanie podaje wartości odczytu potencjometru i przycisku; Serwer nie sprawdza poprawności zapytania, zakłada że jeśli ktoś coś od niego chce to tylko tego co wypisuje; Serwer wypisuje wartości czystym tekstem, bez zabawy w jakieś HTML-e i podobne wymysły. Najpierw więc przygotujmy wszystko, co nam będzie potrzebne. Przede wszystkim musimy sobie przygotować płytkę i podłączyć do niej potencjometr i przycisk. W przypadku Arduino będzie to wyglądać tak: Podobnie dla ESP8266 i ESP32: Zanim zabierzemy się do pisania programu - kilka słów wstępu. Otóż różne biblioteki (WiFi, Ethernet) operujące na połączeniach sieciowych TCP/IP zawsze mają swoje klasy serwera i klienta, będące pochodnymi ogólnych klas Server i Client. Funkcje obsługi połączeń (spoza tych bibliotek) zawsze wymagają właśnie obiektów tych klas, a nie konkretnych (np. EthernetServer). A co robią takie obiekty? To są po prostu elementy najprostszego połączenia TCP/IP. Obiekt klasy Server nasłuchuje na określonym porcie i w przypadku przychodzącego połączenia tworzy nowy obiekt typu Client, już połączony ze stroną nawiązującą połączenie: EthernetClient client=server.available(); if (client) { // obsługa połączenia } Obiekt klasy Client można również utworzyć ręcznie - i wtedy trzeba mu podać adres i port serwera, z którym ma się połączyć: if (client.connect(ADRES_IP_SERWERA, PORT_SERWERA)) { // rozmowa z serwerem } else { Serial.println("Nie mogę nawiązać połączenia"); } Ponieważ Client dziedziczy po klasie Stream (a Stream po Print) - możemy tu używać wszystkich metod pochodzących z tej klasy (podobnie jak w obiektach klasy Serial) Dobra, wystarczy tego wstępu. Zabierzmy się wreszcie za napisanie prostego serwera. Zacznijmy od tego, co będzie się powtarzać we wszystkich następnych programach, czyli od tych wszystkich beginów, initów i innych powtarzalnych rzeczy. Spróbujmy od razu zrobić to tak, aby jak najmniej ingerować w późniejsze programy czy to przy zmianie płytki (Arduino - ESP), czy przy dalszych eksperymentach z programami (serwer i klient). Taki typowy kod (dla Arduino) wygląda tak: #include <SPI.h> #include <Ethernet.h> #define POT_PIN A1 #define KEY_PIN A0 byte mac[] = { 0xDE, 0xAD, 0xBE, 0xEF, 0xFE, 0xED }; EthernetServer server(80); void setup() { Serial.begin(9600); while (!Serial); // dla Leonardo Ethernet.begin(mac); while (Ethernet.linkStatus() == LinkOFF) { Serial.println(F("Ethernet cable is not connected.")); delay(500); } // dajmy mu trochę czasu na połączenie delay(1000); Serial.print(F("Adres serwera: ")); Serial.println(Ethernet.localIP()); pinMode(KEY_PIN, INPUT_PULLUP); server.begin(); } Oczywiście jest to najprostszy z możliwych sposobów połączenia z siecią, więcej informacji można znaleźć w dokumentacji i przykładach biblioteki Ethernet. Porównajmy to z kodem dla ESP8266 i ESP32: #ifdef ESP32 #include <WiFi.h> #define POT_PIN 32 #define KEY_PIN 16 #else #include <ESP8266WiFi.h> #define POT_PIN A0 #define KEY_PIN 4 #endif const char* ssid = "My_SSID"; const char* password = "My_PASSWORD"; WiFiServer server(80); void setup(void) { Serial.begin(115200); WiFi.mode(WIFI_STA); WiFi.begin(ssid, password); while (WiFi.status() != WL_CONNECTED) { delay(500); Serial.print("."); } Serial.println(); Serial.print("Połączono z WiFi, adres serwera: "); Serial.println(WiFi.localIP()); pinMode(KEY_PIN, INPUT_PULLUP); server.begin(); } I znów procedura łąćzenia jest maksymalnie uproszczona - ale nie czas to i nie miejsce na omawianie niuansów różnych rodzajów połączeń:) Jak widać kody dla ESP8266 i ESP32 są na tyle podobne, że mogliśmy użyć wspólnego kodu zmieniając tylko bibliotekę i definicje pinów. Spróbujmy jednak pójść dalej i stworzyć wspólny kod dla Arduino/Ethernet i ESP. #ifdef AVR // część dla Arduino i Ethernet Shield #include <SPI.h> #include <Ethernet.h> #define POT_PIN A1 #define KEY_PIN A0 byte mac[] = { 0xDE, 0xAD, 0xBE, 0xEF, 0xFE, 0xED }; #define MyServer EthernetServer #define MyClient EthernetClient #define SERIAL_SPEED 9600 void init_network(void) { Ethernet.begin(mac); while (Ethernet.linkStatus() == LinkOFF) { Serial.println(F("Ethernet cable is not connected.")); delay(500); } // dajmy mu trochę czasu na połączenie delay(1000); Serial.print(F("Adres serwera: ")); Serial.println(Ethernet.localIP()); } #else // część dla ESP #ifdef ESP32 #include <WiFi.h> #define POT_PIN 32 #define KEY_PIN 16 #else #include <ESP8266WiFi.h> #define POT_PIN A0 #define KEY_PIN 4 #endif const char* ssid = "My_SSID"; const char* password = "My_PASSWORD"; #define MyServer WiFiServer #define MyClient WiFiClient #define SERIAL_SPEED 115200 void init_network(void) { WiFi.mode(WIFI_STA); WiFi.begin(ssid, password); while (WiFi.status() != WL_CONNECTED) { delay(500); Serial.print("."); } Serial.println(); Serial.print("Połączono z WiFi, adres serwera: "); Serial.println(WiFi.localIP()); } #endif MyServer server(80); void setup(void) { Serial.begin(SERIAL_SPEED); #ifdef __AVR_ATmega32U4__ while (!Serial); // potrzebne tylko dla Leonardo/Micro #endif init_network(); pinMode(KEY_PIN, INPUT_PULLUP); server.begin(); } Możemy teraz zobaczyć, że: wszystkie zależne od płytki wywołania funkcji inicjalizujących połączenie zostały przeniesione do funkcji init_network(); nazwy klas zależnych od płytki i typu połączenia z siecią zostały "zamaskowane" definicjami MyClient i MyServer W ten sposób pisząc dalej program nie będziemy musieli zawracać sobie głowy różnicami między płytkami, bibliotekami i sposobami połączeń z siecią. I teraz mając wszystko przygotowane, możemy na spokojnie zająć się... pierwszą wersją serwera Kod jest tu banalnie prosty i chyba nie wymaga komentarza. Po połączeniu klienta pobieramy od niego wszystko jak leci nigdzie tego nie zapamiętując, aż do napotkania pustej linii. W tym momencie zakładamy, że klient nic więcej wysyłać nie będzie. W odpowiedzi wysyłamy dwa nagłówki: HTTP/1.1 200 OK - potwierdzenie, że wszystko się udało Content-Type: text/plain - czyli, że odpowiadamy czystym tekstem Po nagłówkach wysyłamy linię zawierającą obie odczytane z wejść wartości i zamykamy połączenie. void loop() { // Sprawdzamy, czy klient się połączył MyClient client = server.available(); if (!client) { // nie połączył się return; } Serial.println(F("Nowe połączenie")); // Czytamy znak po znaku aż do napotkania pustej linii: bool linia_pusta = true; bool naglowki_wczytane = false; while (client.connected()) { if (!client.available()) continue; char c = client.read(); Serial.print(c); if (c == '\n') { // koniec linii if (linia_pusta) { naglowki_wczytane = true; // wczytaliśmy wszystko break; } linia_pusta = true; } else if (c != '\r') { // znak '\r' po prostu pomijamy linia_pusta = false; } } // czy na pewno wszystko wczytaliśmy? if (!naglowki_wczytane) { // klient zniknał Serial.println(); Serial.println(F("Klient rozwiał się we mgle")); } else { // Wypisujemy ważne nagłówki i pustą linię client.print(F("HTTP/1.1 200 OK\r\nContent-Type: text/plain\r\n\r\n")); int pot = analogRead(POT_PIN); int key = digitalRead(KEY_PIN); client.print(pot); client.print(' '); client.println(key); } client.stop(); } Możemy teraz w praktyce przetestować nasz serwer. Możemy do tego użyć przeglądarki, wpisując następujący URL: http://adres_ip_serwera/ My jednak chcielibyśmy obejrzeć całą transmisję, więc znów użyjemy PuTTY lub nc: Jak się przekonaliśmy, napisanie prostego serwera nie jest wcale takie trudne, a nawet taki banalny program może byc użyteczny (np. w czujniku temperatury, odpytywanym periodycznie przez główny komputer w domu). Tym niemniej program może się niespecjalnie podobać. Przede wszystkim - czego byśmy nie wpisali, dostaniemy w odpowiedzi wartości z czujników. Podglądając komunikację widzimy, że przeglądarka wysłała dodatkowy request prosząc o ikonkę serwisu - a takiej przecież nie mamy. Spróbujmy więc ulepszyć nieco nasz serwer, tworząc... ulepszoną wersję serwera Poczyńmy znów pewne założenia: Oprócz potencjometru i przycisku serwer podaje wartość jakiejś zmiennej (nazwijmy ją po prostu nasza_zmienna); Serwer oprócz metody GET obsługuje również HEAD; W przypadku otrzymania nieprawidłowej linii serwer odpowiada komunikatem błędu; Z poziomu przeglądarki możemy ustawić wartość "nasza_zmienna" wpisując URL typu http://adres_ip_serwera/set/wartość; Jeśli serwer otrzyma żądanie /favicon.ico, odpowiada błędem 404 (Not Found). #ifdef AVR #define BUFFER_LENGTH 128 #else #define BUFFER_LENGTH 1024 #endif int nasza_zmienna=0; void error400(MyClient& client) { client.println(F("HTTP/1.1 400 Bad Request\r\n\ Content-type: text/plain\r\n\r\n\ Bad request")); client.stop(); } void error404(MyClient& client) { client.println(F("HTTP/1.1 404 Not Found\r\n\ Content-type: text/plain\r\n\r\n\ Not found")); client.stop(); } void error405(MyClient& client) { client.println(F("HTTP/1.1 405 Method Not Allowed\r\n\ Allow: GET,HEAD\r\n\ Content-type: text/plain\r\n\r\n\ Method not allowed")); client.stop(); } void loop(void) { char bufor[BUFFER_LENGTH]; bool isHead; // Sprawdzamy, czy klient się połączył MyClient client = server.available(); if (!client) { // nie połączył się return; } Serial.println(F("Nowe połączenie")); // dajmy sobie czas na wpisanie czegoś do PuTTY client.setTimeout(20000); // Wczytujemy pierwszą linię int n = client.readBytesUntil('\n',bufor, BUFFER_LENGTH-1); if (!n) { // nic nie wczytano? Serial.println(F("Klient się rozmyślił")); client.stop(); return; } bufor[n] = 0; // dopisujemy '\0' na końcu stringu Serial.println(bufor); // teraz pomijamy resztę nagłówków bool linia_pusta = true; bool naglowki_wczytane = false; while (client.connected()) { if (!client.available()) continue; char c = client.read(); Serial.print(c); if (c == '\n') { // koniec linii if (linia_pusta) { naglowki_wczytane = true; // wczytaliśmy wszystko break; } linia_pusta = true; } else if (c != '\r') { // znak '\r' po prostu pomijamy linia_pusta = false; } } // czy na pewno wszystko wczytaliśmy? if (!naglowki_wczytane) { // klient zniknał Serial.println(); Serial.println(F("Klient rozwiał się we mgle")); client.stop(); return; } char *path=strchr(bufor,' '); if (!path) { error400(client); return; } *path++=0; // wstawiamy zero w miejsce spacji // oddzielającej metodę od ścieżki if (!strcmp(bufor, "GET")) { isHead = false; } else if (!strcmp(bufor, "HEAD")) { isHead = true; } else { error405(client); return; } char *proto = strchr(path, ' '); if (!proto) { error400(client); return; } *proto++=0; // nie przesadzajmy, uwierzmy na słowo że to HTTP :) // nie będziemy sprawdzać co siedzi w proto if (!strcmp(path,"/favicon.ico")) { error404(client); return; } if (!strncmp(path, "/set/", 5)) { nasza_zmienna = atoi(path+5); Serial.print(F("Ustawiamy nową wartość zmiennej: ")); Serial.println(nasza_zmienna); } // wypisujemy nagłówki client.print(F("HTTP/1.1 200 OK\r\nContent-Type: text/plain\r\n\r\n")); // teraz możemy odpowiedzieć trzema wartościami: // potencjometr, przycisk i nasza zmienna if (!isHead) { int pot = analogRead(POT_PIN); int key = digitalRead(KEY_PIN); client.print(pot); client.print(' '); client.print(key); client.print(' '); client.println(nasza_zmienna); } client.stop(); } Kod powinien być zrozumiały bez szczegółowego omawiania każdej linii, być może z dwiema uwagami: dotychczas nie mówiliśmy o metodzie HEAD. Działa ona podobnie jak GET, ale serwer kończy transmisję po wysłaniu nagłówków. zamiast błędu 405 (Method Not Allowed) należałoby użyć 501 (Not Implemented). Sugerowałoby to jednak błąd oprogramowania serwera tymczasem to klient przeznaczony do współpracy z urządzeniami IoT powinien wiedzieć jakie pytanie można zadać serwerowi. Dodatkowo obsługa błędu 405 wymaga wysłania dodatkowego nagłówka informującego klienta, jakich metod może używać. A oto wyniki działania naszego serwera: Widzimy więc, że zgodnie z naszymi założeniami: Metoda HEAD powoduje wysłanie tylko nagłówków; Nieznana metoda powoduje wystąpienie błędu 405 Prośba o /favicon.ico powoduje wystąpienie błędu 404 URI o specialnej postaci: /set/<liczba> powoduje zapisanie liczby w pamięci serwera. Możemy również zauważyć, ze odpowiedź informująca o błędzie ma taką samą postać jak prawidłowa, czyli składa się z głównego nagłówka odpowiedzi (tzw. "status line"), nagłówka typu, ewentualnie dodatkowych nagłówków i odpowiedzi w postaci zrozumiałej dla człowieka. Dodatkowym efektem wysłania 404 w odpowiedzi na favicon.ico jest zapamiętanie tej informacji przez przeglądarkę i nie proszenie o nią za każdym razem. Taki serwer może już służyć bardziej praktycznym celom - np. sterowaniem różnych domowych urządzeń za pomocą przeglądarki. I tyle na dziś. Kody obu programów znajdziemy w załączniku: servers.zip - a w następnej części spróbujemy stworzyć klienta, czyli skomunikować się z naszym serwerem. Spis treści serii artykułów: Protokół HTTP w zastosowaniach IoT - część 1: trochę teorii Protokół HTTP w zastosowaniach IoT - część 2: budujemy serwer Protokół HTTP w zastosowaniach IoT - część 3: tworzymy klienta