W tej części kursu zajmiemy się wprowadzeniem teoretycznym do bardziej skomplikowanego, ale niezwykle przydatnego zagadnienia, jakim jest przetwarzanie współbieżne.
Przy okazji omówimy takie zagadnienia jak: wątki, procesy, wielozadaniowość i wielowątkowość.
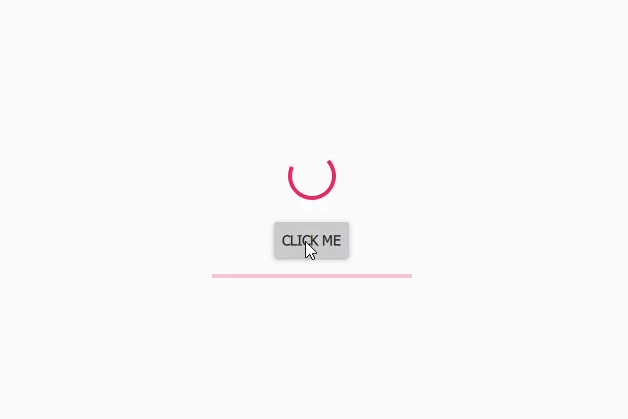
Zacznijmy od programu (projekt szablonu QtQuick), którego część została przedstawiona poniżej. Nasz program posiada GUI, na którym znajdują się trzy komponenty: BusyIndicator, Button oraz ProgressBar. Kliknięcie w przycisk rozpoczyna wykonywanie jakiś czasochłonnych obliczeń.
Przykładowe GUI
W tym przykładzie obliczenia symulujemy wewnątrz funkcji heavyCalculations(), która jest częścią klasy Worker. W trakcie wykonywania obliczeń chcielibyśmy obserwować postęp prac za pomocą kontrolki ProgressBar. Co więcej, na czas obliczeń chcielibyśmy zablokować przycisk.
Poniżej znajduje się zawartość plików main.qml oraz klasy Worker. Kompletny program dostępny jest do pobrania z załącznika. W tej części kursu zależy nam głównie na zrobieniu wstępu teoretycznego, więc nie będziemy tutaj odtwarzać tego programu krok po kroku (wszystko jest w załączniku).
W pliku main.cpp obiekt klasy Worker został zarejestrowany w QML pod nazwą calculations, w taki sam sposób, jak zostało to przedstawione w 6. części kursu.
Włączamy program, klikamy w przycisk, a po uruchomieniu obliczeń interfejs się blokuje i przestaje reagować na nasze akcje do czasu, aż czasochłonne obliczenia się zakończą. Działanie programu może też zależeć od konkretnej platformy. W niektórych sytuacjach animacje będą nadal działały, a w innych mogą być zupełnie blokowane.
Przykład z zablokowaniem animacji w Windows 10:
Z kolei po uruchomieniu programu w Ubuntu niektóre elementy interfejsu mogą się nadal animować:
Oczekiwaliśmy zupełnie czegoś innego, czyli responsywnego interfejsu, w którym nasz pasek postępu będzie pozwalał na podgląd postępu obliczeń.
Korzystanie z interfejsu, który przestaje reagować, jest niezwykle uciążliwe, w najgorszym przypadku taki program przestaje być użyteczny, bo użytkownik nie wie, co tak właściwie dzieje się w tle. Jak poradzić sobie z tym problemem? Można np. podzielić obliczenia na mniejsze fragmenty i wykonywać je z pewnym interwałem czasowym, dając interfejsowi czas na obsługę zdarzeń i animacji. Jednak wtedy czas wykonania takich obliczeń będzie znacznie dłuższy. Możemy też wykorzystać możliwości przetwarzania współbieżnego. Wówczas uda nam się osiągnąć efekt z poniższego nagrania (płynnie działający pasek postępu):
Czym jest przetwarzanie współbieżne?
Przetwarzanie współbieżne (ang. concurrent computing) to forma przetwarzania, w której kilka obliczeń jest wykonywanych w nakładających się okresach, czyli równolegle, a nie sekwencyjnie (jedno po drugim). Ciągi instrukcji wykonywane współbieżnie (wątki) uruchomione na tym samym procesorze są przełączane w krótkich przedziałach czasu, co sprawia wrażenie, że wykonują się równolegle.
W przypadku procesorów wielordzeniowych lub wielowątkowych możliwe jest faktycznie współbieżne przetwarzanie (jest to też możliwe w architekturach wieloprocesorowych).
Czym jest proces?
W informatyce proces jest instancją programu komputerowego wykonywanego przez jeden lub wiele wątków. Zawiera kod programu i jego aktywność. Podczas gdy program komputerowy jest pasywnym zbiorem instrukcji, procesem jest faktyczne wykonanie tych instrukcji. W celu wykonania programu system operacyjny przydziela procesowi zasoby: pamięć, czas procesora, dostęp do I/O lub plików.
Czym jest wątek?
Wątek (ang. thread) to fragment programu, który jest wykonywany współbieżnie w obrębie jednego procesu. Co ważne, w jednym procesie może istnieć wiele wątków.
Jak to wygląda w praktyce?
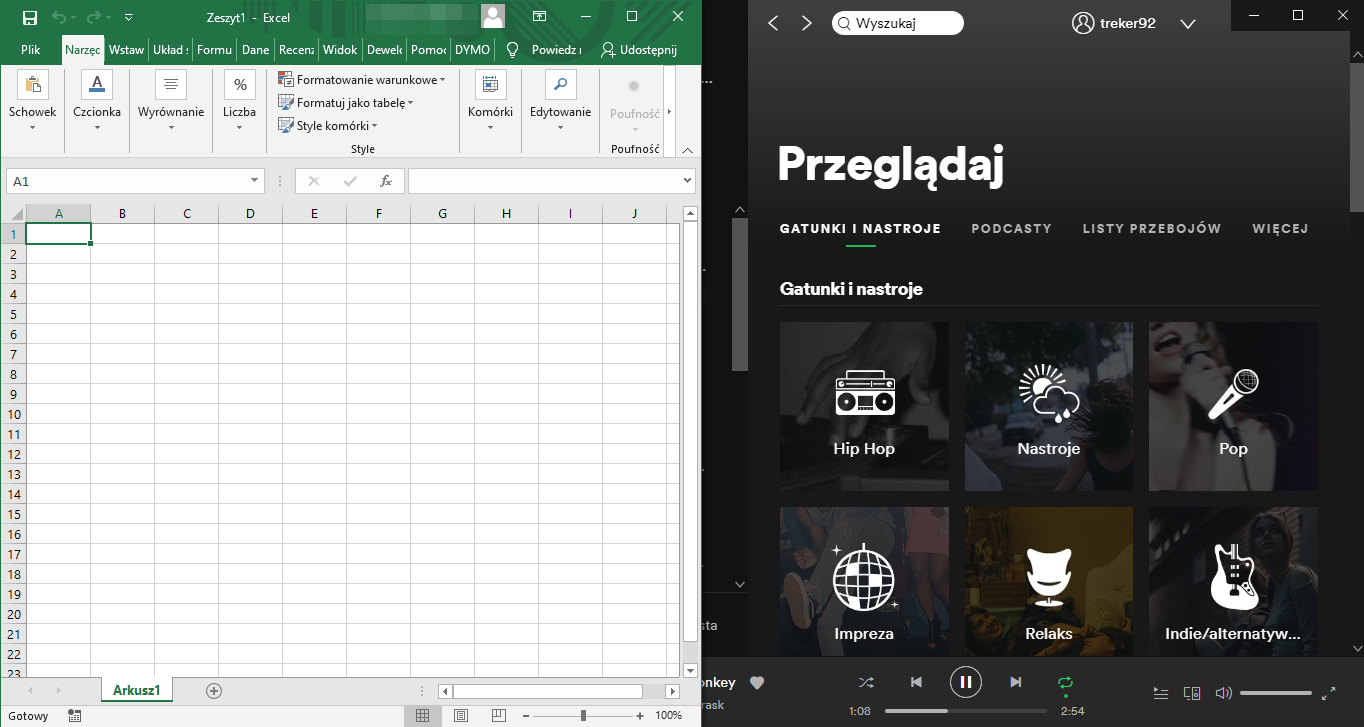
Spróbujmy teraz przedstawić powyższą teorię za pomocą przykładu. Podczas wykonywania obliczeń w arkuszu kalkulacyjnym możecie mieć włączony w tle odtwarzacz muzyki, który gra Wasze ulubione utwory. Jest to przykład dwóch procesów pracujących równolegle (współbieżnie): jeden to program do obsługi arkusza kalkulacyjnego, drugi to odtwarzacz multimedialny. Taką cechę systemu nazywamy wielozadaniowością – czyli zdolnością do równoczesnego wykonywania więcej niż jednego programu.
Przykład dwóch współbieżnych procesów na PC
Gdy w trakcie pracy stwierdzasz, że muzyka jest za głośna, to przełączasz się na okno z odtwarzaczem i ściszając muzykę, zauważasz, że w tym samym procesie znów rzeczy dzieją się równolegle – podczas gdy odtwarzacz multimedialny wysyła muzykę do sterownika audio, interfejs użytkownika z wszystkimi jego kontrolkami i wskaźnikami jest stale aktualizowany. Jest to przykład współbieżności w obrębie jednego procesu – taką cechę nazywamy wielowątkowością. Aby osiągnąć współbieżność w obrębie jednego programu, stosuje się wątki.
Zmiana głośności może odbywać się niezależnie od odtwarzania dźwięku i działania reszty interfejsu
Jak więc implementowana jest współbieżność? Równoległa praca na jednordzeniowych procesorach jest iluzją, która jest nieco podobna do szybko zmieniających się obrazów w kinie. W przypadku procesów iluzja powstaje przez przerwanie pracy procesora nad jednym procesem po bardzo krótkim czasie, a następnie przejście procesora do kolejnego procesu.
Obecne procesory posiadają coraz więcej rdzeni. Typowa aplikacja jednowątkowa może wykorzystywać tylko jeden rdzeń. Natomiast program z wieloma wątkami może być przypisany do wielu rdzeni, dzięki czemu wszystko może odbywać w naprawdę współbieżny sposób.
Czym jest wielowątkowość?
Wielowątkowość (ang. multithreading) to cecha systemu operacyjnego, dzięki której w ramach jednego procesu może być wykonywanych kilka zadań, nazywanych wątkami. Nowe zadania to kolejne ciągi instrukcji realizowane do pewnego stopnia niezależnie.
Czym jest wielozadaniowość?
Wielozadaniowość (ang. multitasking) to cecha systemu umożliwiająca równoczesne wykonywanie więcej niż jednego procesu. Zwykle za poprawną realizację wielozadaniowości odpowiedzialne jest jądro systemu operacyjnego. Równoczesność realizowania wielozadaniowości jest pozorna, gdy system komputerowy ma mniej wątków sprzętowych niż wykonywanych jednocześnie procesów.
W takiej sytuacji dla wrażenia wykonywania wielu zadań w tym samym czasie konieczne staje się zastosowanie mechanizmu podziału czasu – mechanizm ten przydziela każdemu procesowi określony przedział czasowy, w którym może być on przetwarzany przez procesor.
Różnica między procesem a wątkiem
Różnica między zwykłym procesem a wątkiem polega na współdzieleniu przez wszystkie wątki działające w danym procesie przestrzeni adresowej oraz wszystkich innych struktur systemowych (np. listy otwartych plików, gniazd itp.) – z kolei procesy posiadają niezależne zasoby. Ta cecha ma dwie ważne konsekwencje:
Wątki wymagają mniej zasobów do działania i też mniejszy jest czas ich tworzenia.
Dzięki współdzieleniu przestrzeni adresowej (pamięci) wątki jednego zadania mogą łatwo komunikować się między sobą (bez pomocy ze strony systemu operacyjnego).
Przekazanie dowolnie dużej ilości danych w obrębie jednego procesu wymaga jedynie przesłania wskaźnika lub referencji. Przesłanie danych między dwoma procesami wymaga już pomocy ze strony systemu operacyjnego i zastosowania mechanizmów komunikacji międzyprocesowej.
Jakie są konsekwencje stosowania współbieżności?
Czytając artykuł do tego momentu, macie pewnie wrażenie, że współbieżność jest rozwiązaniem na wszystkie problemy. Nic bardziej mylnego. Zastosowanie współbieżności w kontekście danego zadania może wygenerować liczne problemy.
Programy wykorzystujące współbieżność są bardziej złożone i trudniejsze do testowania – większa złożoność to więcej błędów, które mogą być trudne do wykrycia lub odtworzenia.
Wykorzystanie wielozadaniowości w kontekście rozbicia problemu na kilka programów wymaga od nas zastosowania komunikacji między tymi procesami (ang. inter-process communication). Mimo że komunikacja między wątkami w obrębie jednego procesu jest bardzo łatwa, to wiąże się z problemem zapewnienia ochrony zasobów współdzielonych między wątkami, czyli koniecznością zapewnienia synchronizacji w celu uniknięcia utraty integralności danych.
Niewątpliwie wykorzystanie współbieżności niesie szereg korzyści, jednak ostateczny efekt zależy od problemu, który rozwiązujemy. Warto przytoczyć tutaj zdanie z książki Biblioteki Qt. Zaawansowane programowanie przy użyciu C++:
Tak więc jeśli chcemy mieć pewność, że naprawdę tworzymy aplikację o lepszej wydajności, powinniśmy stworzyć różne implementacje, ich profile i porównać wyniki – najlepiej z wykorzystaniem takich samych konfiguracji sprzętu i oprogramowania, jakich używają docelowi użytkownicy.
– Mark Summerfield, Biblioteki Qt. Zaawansowane programowanie przy użyciu C++, rozdział Wielowątkowość z wykorzystaniem przestrzeni nazw QtConcurrent
Na szczęście Qt zapewnia szereg mechanizmów, dzięki którym wykorzystanie współbieżności jest całkiem łatwe. Programiści otrzymują np. dostęp do niskopoziomowych oraz wysokopoziomowych mechanizmów synchronizacji oraz kilku sposobów implementacji komunikacji międzyprocesowej.
Zadanie dodatkowe
Osoby, które chciałyby poznać lepiej ten temat, powinny zainteresować się poniższymi materiałami:
W tej części omówiliśmy fragment teorii związanej z przetwarzaniem współbieżnym. Przedstawiliśmy też problem, który może rozwiązać zastosowanie wielowątkowości. W następnych częściach pokażemy, jak rozwiązać zaprezentowany we wstępie problem z blokującym się interfejsem, oraz omówimy od praktycznej strony zastosowanie wielowątkowości. Zapoznamy się również z uruchamianiem nowych procesów, np. przez wywołanie AVRDUDE z naszej aplikacji. Przedstawimy także jeden ze sposobów na zrealizowanie komunikacji między dwoma procesami.
Co o tym sądzisz? Oceń ten wpis:
Średnia ocena 4.8 / 5. Głosów łącznie: 36
Nikt jeszcze nie głosował, bądź pierwszy!
Artykuł nie był pomocny? Jak możemy go poprawić? Wpisz swoje sugestie poniżej. Jeśli masz pytanie to zadaj je w komentarzu - ten formularz jest anonimowy, nie będziemy mogli Ci odpowiedzieć!
Autorem tej serii wpisów jest Mateusz Patyk, który zawodowo zajmuje się programowaniem systemów wbudowanych oraz rozwijaniem aplikacji na desktopy i urządzenia mobilne. Jego głównymi obszarami zainteresowań są systemy sterowania, egzoszkielety i urządzenia do wspomagania chodu człowieka. Prywatnie miłośnik dobrego kina i gier strategicznych.
Dołącz do 30 tysięcy osób, które otrzymują powiadomienia o nowych artykułach! Zapisz się, a otrzymasz PDF-y ze ściągami (m.in. na temat mocy, tranzystorów, diod i schematów) oraz listę inspirujących DIY na bazie Arduino i Raspberry Pi.
Dołącz do 30 tysięcy osób, które otrzymują powiadomienia o nowych artykułach! Zapisz się, a otrzymasz PDF-y ze ściągami (m.in. na temat mocy, tranzystorów, diod i schematów) oraz listę inspirujących DIY z Arduino i RPi.
























Trwa ładowanie komentarzy...