Jednym z częstych problemów początkujących robotyków jest pisanie programów.
Bardzo szybko można nauczyć się podstaw programowania, natomiast pomija się wtedy takie aspekty jak korzystanie z not katalogowych, czy budowa i sposób działania mikrokontrolera.
Nie mówię, że szybkie kursy od zera są złe. Wręcz przeciwnie, są bardzo dobre. Dzięki nim można zbudować swoją pierwszą konstrukcje i sprawdzić, czy wciągnie Cię robotyka. Jeżeli już wiesz, że chcesz w przyszłości wziąć się za bardziej skomplikowane projekty, warto poznać również nieco teorii.
Dlatego właśnie postanowiłem napisać artykuł, zawierający informacje o budowie i sposobie działania mikrokontrolera oraz o dobrych nawykach z nim związanych. Jako że zdecydowanie największą popularnością cieszą się aktualnie 8-bitowe procesory Atmela z rodziny AVR, to właśnie na nich się skupię. Dokładniej na ATmedze16. Chciałbym jednak, aby informacje tutaj zawarte były dość uniwersalne, dlatego pokażę również, jak korzystać z noty katalogowej i gdzie znaleźć dane dotyczące naszego sprzętu.
Aby mikrokontroler spełniał swoje zadanie, potrzebuje kilku podstawowych elementów. Najważniejszym z nich jest procesor (ang. Central Processing Unit, w skrócie CPU). To on jest odpowiedzialny za realizację napisanego przez nas programu. Niezbędne są również pamięci, różniące się pojemnością, szybkością dostępu czy trwałością danych.
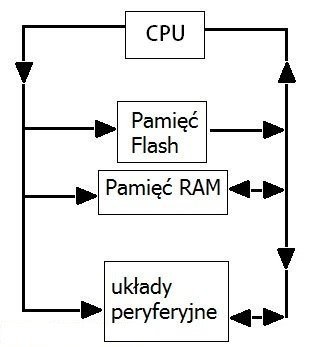
Innymi niezbędnymi elementami są urządzenia peryferyjne, które służą do komunikacji z otoczeniem. Najczęściej używane są równoległe porty wejściowo/wyjściowe. Zależności pomiędzy wyżej wymienionymi elementami można zobrazować na prostym schemacie:
Jak widać, za pomocą ścieżki po lewej stronie komunikacja zachodzi tylko w jedną stronę - od CPU do układu docelowego. Jest to szyna adresowa. Po prawej stronie natomiast znajduje się szyna danych, za pomocą której dane mogą płynąć w obu kierunkach.
Wielkość szyny danych ma diametralny wpływ na szybkość wykonywanych operacji.
W AVRach ma ona szerokość 8 bitów, przez co np. liczba typu int zajmująca 16 bitów musi zostać przetransportowana na 2 razy. Komputery osobiste są zwykle wykonane w architekturze 32- lub 64-bitowej. Nie ma się więc czemu dziwić, że komputer może dużo szybciej wykonywać te same zadania. W dalszej części artykułu będzie można zauważyć, jak szerokość szyny danych determinuje wielkość elementów służących do przechowywania informacji.
Komunikacja między procesorem, a innymi układami za pomocą szyny adresowej i szyny danych jest bardzo prosta. Najpierw procesor poprzez szynę adresową wybiera aktualnie potrzebny układ, a następnie, przez szynę danych, bajty wędrują z albo do procesora. Każdy układ ma unikalny adres, więc kiedy jedno urządzenie jest w użyciu, reszta nie korzysta z szyny danych. Warto jeszcze wspomnieć o układzie sygnału zegarowego. Odpowiada on za generowanie impulsów o stałej częstotliwości.
Sygnał zegara dociera do CPU oraz układów peryferyjnych i w jego takt wykonywane są wszystkie operacje. Jest on drugim ważnym czynnikiem, wpływającym na szybkość działania mikrokontrolera.
Teraz przejdziemy do dokładniejszego omówienia poszczególnych komponentów.
Procesor (CPU)
Jest to układ cyfrowy, sekwencyjny i synchroniczny. Cyfrowy oznacza, że rozróżnia tylko stan niski lub wysoki napięcia. Przeciwieństwem są układy analogowe. Sekwencyjny, bo każdy nowy stan zależy od aktualnego wejścia oraz poprzedniego stanu. Synchroniczny natomiast to taki, który pracuje w rytmie sygnału zegarowego.
Zadaniem procesora jest realizacja zapisanego w pamięci FLASH programu. Program podzielony jest na rozkazy, które kolejno są przesyłane do CPU i wykonywane. W pojedynczym rozkazie zawarte są informacje o rodzaju operacji (np. wczytanie z pamięci, czy dodanie dwóch liczb) oraz o argumentach, na jakich ma ona zostać wykonana.
Jednostka centralna składa się z kilku mniejszych elementów. Schemat blokowy można znaleźć w nocie katalogowej w rozdziale AVR CPU Core. Do przechowywania aktualnie potrzebnych danych oraz informacji o stanie przeznaczone są rejestry 8-bitowe.
Należą do nich:
Instruction Pointer (IP) - przechowuje w pamięci adres, z którego ma być pobrany następny rozkaz.
Instruction Register - przechowuje kod aktualnego rozkazu.
Rejestr Statusowy - przechowuje flagi (bity kontrolne), potrzebne do działania programu. Większość flag dotyczy operacji arytmetycznych i jest wykorzystywana tylko podczas programowania w asemblerze. Są to na przykład flagi pożyczki, przepełnienia czy zera. Znajduje się tu również flaga przerwań globalnych.
Rejestry ogólnego przeznaczenia - w procesorach z rodziny AVR są 32 takie rejestry i mają nazwy R0, R1 i tak dalej do R31. Jest to taka własna pamięć operacyjna procesora. Operacje na tych rejestrach wykonują się szybciej niż na danych z RAMu czy układów peryferyjnych. Tak naprawdę większość operacji składa się z wczytania danych do któregoś z tych rejestrów, wykonania na nim zadanych operacji i odesłania z powrotem przez szynę danych.
Częścią procesora odpowiedzialną za wykonywanie obliczeń jest ALU (Aritmetic Logic Unit). Z jego pomocą można wykonywać operacje arytmetyczne, logiczne oraz bitowe na liczbach zapisanych w rejestrach ogólnego przeznaczenia. Wyniki tych operacji oddziałują także na flagi w rejestrze statusowym.
Pamięć FLASH
Zwana również pamięcią programu. Jest to pamięć o największej pojemności, służąca głównie do przechowywania rozkazów. Po odłączeniu zasilania informacje nie są z niej usuwane. Jak można było zauważyć na schemacie budowy mikrokontrolera, strzałka między pamięcią FLASH, a szyną danych była skierowana tylko w jedną stroną.
Dzieje się tak dlatego, że CPU nie może na niej bezpośrednio zapisywać informacji. Z tego powodu wykorzystanie tego rodzaju pamięci jest dość ograniczone. Oprócz programu mogą się na niej znajdować również tablice stałych oraz sekcja bootloadera, umożliwiająca wgrywanie do FLASHa nowego programu bez użycia programatora.
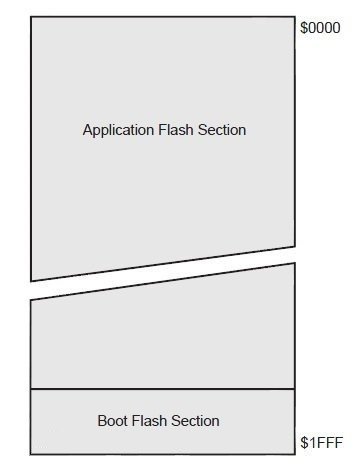
Pamięć FLASH ma ograniczoną żywotność. Można ją odczytać z noty katalogowej w rozdziale "AVR xxx Memories". Pamięć programu jest podzielona na komórki o określonej pojemności, zależnej od używanego mikrokontrolera. Pewnie nikogo nie zdziwi fakt, że w AVRach jest to 8 bitów. Każda komórka ma przypisany adres w kodzie szesnastkowym. Dokładne informacje można znaleźć w nocie katalogowej. Poniżej mapa pamięci ATmegi16:
Jak widać, pamięć jest podzielona na sekcję aplikacji oraz bootloadera. Wielkość sekcji bootloadera jest definiowana za pomocą fuse bitów. Po resecie procesor kolejno wczytuje rozkazy. W zależności od ustawienia fuse bitów, może startować od początku sekcji aplikacji albo od początku bootloadera.
Bootloaderami i fuse bitami nie będziemy się tutaj zajmować, bo to temat na oddzielny artykuł. Poza tym w datasheecie można znaleźć pewne informacje wraz z przykładowym kodem (rozdziały o bootloaderze oraz "Memory Programing"). W każdym razie, program może spokojnie działać, jeżeli w sekcji bootloadera nic nie będzie.
Pamięć RAM (Random Acces Memory)
Pamięć RAM, w przeciwieństwie do FLASH, przechowuje informacje jedynie, kiedy układ pracuje. Po każdym resecie zostaje wyczyszczona. W zamian za to, dostęp do niej jest dużo szybszy i nie ma limitu dopuszczalnych zapisów. Dlatego idealnie nadaje się do przechowywania zmiennych.
Dodatkowo jest używana jako stos sprzętowy. Zasada działania stosu jest prosta - można na niego wrzucać kolejne rzeczy (w tym wypadku bajty danych), a następnie zdejmować. Ostatni wrzucony bajt znajduje się na samym szczycie stosu, więc jest pierwszy do zdjęcia. Jeżeli wrzucimy na stos kolejny bajt, to przygniecie poprzedni i to on będzie pierwszy. Stos zwykle jest umieszczony na końcu pamięci i rośnie w stronę początku. Dlatego jeśli źle napiszemy program, to wartości odkładane na stosie w końcu nadpiszą nam inne dane, znajdujące się w pamięci.
Przestrzeń adresowa (czyli zbiór wszystkich adresów, które odpowiadają jakiejś komórce pamięci) pamięci SRAM (Static RAM) w AVRach zawiera również adresy rejestrów R0-R31 oraz rejestry kontrolne układów peryferyjnych. Poniżej mapa pamięci RAM dla ATmegi16:
Zwracam tutaj uwagę, że pamięci FLASH i RAM są od siebie całkowicie niezależne i mają oddzielne adresy, które nie są ze sobą w żaden sposób powiązane. Jako ciekawostkę mogę dodać, że takie rozwiązanie jest jedną z cech architektury harwardzkiej, według której została zbudowana znaczna część mikrokontrolerów.
Jeśli ktoś chciałby poznać więcej informacji na ten temat, polecam sprawdzić hasła RISC, CISC, architektura harwardzka, architektura von Neumanna.
Układy peryferyjne
To wszystkie te użyteczne rzeczy, z których dobrodziejstw korzystamy w naszych robotach. Najczęściej używane są standardowe porty równoległe wejściowo-wyjściowe, mogące odbierać sygnały cyfrowe z PINów.
Jest wiele innych układów mogących być alternatywnymi wejściami/wyjściami tych portów. Należą do nich timery, komparatory, generatory przerwań zewnętrznych i wiele innych. Więcej informacji dotyczących konkretnych modeli znajdziemy w datasheecie.
Każdy układ peryferyjny posiada rejestry konfiguracyjne, określające sposób jego działania. Np. dla portu standardowego w ATmegach mamy trzy rejestry:
DDRx - określa kierunek przepływu danych,
PORTx - wymusza stan na wyjściu,
PINx - sczytuje stan na wejściu.
Opis zastosowania i trybów pracy każdego z układów peryferyjnych to temat na całą serię artykułów. Na szczęście noty katalogowe zawierają ładne tabelki z nazwami poszczególnych bitów, trybami pracy w zależności od ustawień tych bitów i dokładnymi opisami konfiguracji.
Tworzenie i realizacja programu
Jak wspomniałem podczas omawiania pamięci programu, procesor po resecie w każdym cyklu wczytuje instrukcję wskazywaną przez Instruction Pointer (IP) i ją wykonuje. W trakcie wykonywania, zmieniana jest wartość IP, aby można było wczytać następną instrukcję. Wartość IP nie musi być zawsze zwiększana o 1, dzięki temu program nie będzie wykonywany zawsze w tej samej kolejności. Jest możliwe robienie skoków czyli np. pętli i instrukcji warunkowych.
Program na mikrokontroler powinien składać się z części inicjalizującej układy peryferyjne, a następnie przechodzić do nieskończonej pętli. Jeżeli taka pętla nie występuje, procesor po dojściu do ostatniego adresu w pamięci FLASH przechodzi z powrotem na początek i od nowa się inicjalizuje. Proces ten ma miejsce nawet, jeśli nie zapełnimy całej pamięci, ponieważ niezaprogramowane komórki mają domyślnie wartość 0xFF (255 szesnastkowo albo same jedynki binarnie). Odpowiada to kodowi rozkazu, który się wtedy wykonuje w każdej instrukcji do końca pamięci. Oczywiście z takiego programu nie ma żadnego pożytku.
Niektórzy mylą kod maszynowy z kodem asemblera.
Są to jednak dwie różne rzeczy. Kod maszynowy występuje w postaci binarnej i dzieli się na rozkazy. W procesorach z rodziny AVR rozkazy mają po 16 bitów i zawierają kod operacji, tryb adresowania i wartości lub adresy argumentów.
Kod maszynowy jest bardzo trudny do odczytania dla człowieka. Język asemblera natomiast składa się z kilkuliterowych instrukcji oraz argumentów. Przy odrobinie wprawy można go bez problemu przeczytać i zrozumieć ponieważ nazwy instrukcji to angielskie skróty np.: MOV - move. Pojedyncza instrukcja asemblera zwykle jest wykonywana w jednym cyklu zegara i odpowiada jednemu rozkazowi w kodzie maszynowym.
Każda rodzina procesorów ma swój własny kod maszynowy oraz język asemblera.
Listę komend AVR Assemblera można znaleźć w nocie, w rozdziale Instruction Set Summary. Dzięki zawartej tam tabelce można poznać komendę asemblerową, rodzaje argumentów, krótki opis oraz ilość taktów zegara potrzebnych na jej wykonanie. Możemy też sprawdzić, ile czasu wykonują się dane funkcje.
Wybrane rozkazy
Jeżeli piszemy nasz program w języku wyższego poziomu, na przykład w C, proces tworzenia pliku wykonywalnego, czyli kompilacja, przechodzi w kilku etapach.
Kompilator po dokonaniu optymalizacji zapisuje program w języku asemblera, a następnie dopiero przechodzi na kod maszynowy. Wszystkie te pliki możemy podejrzeć w katalogu z naszym projektem. .HEX, to plik wykonywalny, natomiast w plikach .LSS i .LST znajdują się komendy asemblerowe oraz ich maszynowe odpowiedniki.
Przerwania
Przerwania zostały stworzone, aby umożliwić zatrzymanie wykonywania głównej pętli programu i przejście do obsługi jakiegoś pilnego zdarzenia. Są one aktywowane za pomocą flagi w rejestrze statusowym. Jeżeli flaga ta jest ustawiona na 1, układy peryferyjne mogą pracować w trybie przerwaniowym. Niektóre z nich mogą generować po kilka różnych przerwań. Na przykład interfejsy do komunikacji mają możliwość generowania przerwania przy wysłaniu oraz odebraniu bajtu.
Kiedy procesor otrzyma żądanie przerwania, przechodzi do specjalnego adresu w pamięci (wektora przerwań), gdzie znajdują się instrukcje obsługi każdego przerwania i wybiera z nich odpowiednie.
Tabelę, mówiącą jaki adres w wektorze odpowiada któremu przerwaniu, znajdziecie oczywiście w nocie katalogowej w rozdziale Interrupts. Przed przejściem do przerwania, na stosie zapisywany jest rejestr IP, aby móc wrócić później do głównego programu w tym samym miejscu. Dlatego właśnie należy uważać, aby przed powrotem do głównej pętli wskaźnik stosu wskazywał to samo miejsce w pamięci, co na początku przerwania.
Oczywistą zaletą pracy w trybie przerwaniowym jest natychmiastowe odbieranie ważnych danych pomiarowych czy szybka komunikacja. Drugim plusem jest usprawnienie pętli głównej programu. Już nie trzeba za każdym razem sprawdzać stanu danego układu peryferyjnego. Można o nim kompletnie zapomnieć w głównej pętli, a obsługiwać jedynie za pomocą przerwania.
Ze względu na to, że przerwania zaburzają wykonywanie podstawowego programu, oczywiste jest, że ich obsługa powinna trwać jak najkrócej. Dzięki temu pozostaje więcej czasu na obsługę programu. Początkujący często o tym nie wiedzą i umieszczają w obsłudze przerwania długie pętle czy funkcje delay. Ogólnie funkcje delay nie współpracują dobrze z przerwaniami, nawet jeśli są w pętli głównej. Powodem jest wykorzystanie przez nie pętli i operacji asemblerowej nop (no operation) przez zadaną ilość cykli w głównej pętli programu. Łatwo więc się domyślić, że im częściej pętla ta będzie przerywana, tym bardziej czas wykonywania delaya będzie się różnić od zadanego. Oczywiście dla krótkich czasów, rzędu kilku mikrosekund, różnica nie musi negatywnie wpływać na program, jednak dla dłuższych delayów różnice mogą już być znaczące. Receptą jest tutaj panowanie nad kodem.
Możemy określić długość wykonywania przerwania dzięki tabeli z poprzedniego rozdziału i kodowi w asemblerze. Możemy też oszacować, ile razy przerwanie zostanie wywołane. Dzięki temu jesteśmy w stanie odpowiednio skorygować czas delaya. Oczywiście nigdy nie uda nam się trafić dokładnie, ale taki zabieg zawsze pomoże.
Jeżeli piszemy program wykorzystujący przerwania w języku C, możemy często nabrać się na pewną pułapkę związaną z kompilatorem i optymalizacją.
Otóż wszystkie deklarowane przez nas zmienne różnych typów podczas kompilacji i tak są zamieniane na taką samą postać zero-jedynkową, a następnie umieszczane gdzieś w pamięci. Mogą to być rejestry ogólnego przeznaczenia, pamięć RAM albo stos. Jeśli natomiast przestają być potrzebne, na ich miejsce może zostać zapisane co innego.
Kompilator stwierdza, czy dane są jeszcze potrzebne na podstawie analizy kodu i może nie wiedzieć, że dana zmienna globalna ma być wykorzystana także w przerwaniu. Przez to zmienna, która ma zmieniać swą wartość w przerwaniu często pozostaje niezmieniona.
Receptą jest dodawanie słowa kluczowego volatile podczas inicjalizacji zmiennej globalnej.
Typy zmiennych
Na pewno każdy, kto napisał jakikolwiek program, zna podstawowe typy zmiennych. Za to pewnie nie wszyscy się zastanawiali, w jaki sposób są składowane w pamięci i jakie działania można na nich wykonywać. Omówię tu zatem najbardziej popularne typy.
Char - zmienna reprezentująca jeden znak z klawiatury. W pamięci zajmuje 1 bajt (8 bitów). Mimo że początkujący często utożsamiają ten typ tylko z literami, tak naprawdę można go również traktować jako liczbę. Unsigned char może mieć wartości od 0 do 255 (czyli 2^8 - 1), a signed od -128 do 127.
Można na nim wykonywać działania matematyczne, niezależnie od tego czy wcześniej używaliśmy go jako liczby czy znaku. np 'a' + 1 = 'b'.
Odpowiednik liczbowy każdego znaku można znaleźć w tablicy ASCII.
Int (liczba całkowita) - jest to jeden z najczęściej używanych rodzajów zmiennych. Inty standardowo zajmują 16 bitów w pamięci i mogą przyjmować wartości od 0 do 65535 (2^16 - 1) w trybie bez znaku lub od -32 768 do 32 767 ze znakiem.
Zwykle nie potrzebujemy operować na tak dużych liczbach i zmienne 8-bitowe całkowicie nam wystarczą. Dlatego, jeżeli wiemy, że nie będą nam potrzebne liczby większe niż 8-bitowe, deklarowanie zmiennej jako int jest tylko marnowaniem miejsca w pamięci.
Float (liczba zmiennoprzecinkowa) - jest to typ przechowujący liczby ułamkowe, zajmuje 4 bajty (32 bity) w pamięci. O ile w poprzednich dwóch typach dane binarne były bezpośrednio zamieniane na dziesiętne, tutaj sytuacja ma się inaczej.
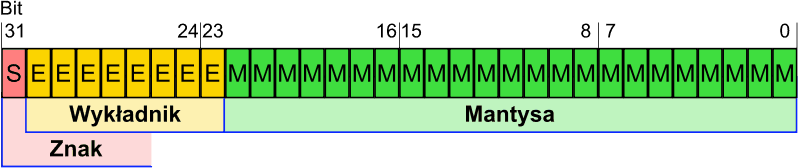
Posłużę się obrazkiem z Wikipedii:
Wartość liczby zmiennoprzecinkowej obliczana jest jako:
Gdzie S (sign) odpowiada za znak i ma wartość 1 albo -1, a E (exponent) to wykładnik potęgi, do której podnoszona jest podstawa systemu liczbowego na jakim aktualnie operujemy.
Oczywiście komputery działają w systemie binarnym stąd liczba 2. M natomiast to mantysa, czyli liczba z przedziału od 1 do 2 w naszym przypadku. Liczby zmiennoprzecinkowe mają dużo większą dokładność od zwykłych typów w pobliżu zera. Niestety, im większe wartości przyjmują, tym mniejszą mają dokładność. Dzieje się tak ze względu na ich wykładniczą naturę i przypisywanie różnym liczbom o podobnej wartości tej samej reprezentacji w pamięci.
Bardzo ważne jest, aby pamiętać, że arytmetyka na liczbach zmiennoprzecinkowych różni się od tej klasycznej.
Operacje na floatach są bardziej skomplikowane, poza tym działają na liczbach 32-bitowych. Ich użycie dużo bardziej obciąża procesor i negatywnie wpływa na szybkość wykonywania programu. Dlatego przed użyciem liczby float warto zastanowić się, czy na pewno potrzebujemy takiej dokładności. Być może lepiej będzie działać na liczbach całkowitych i zastosować jakąś sztuczkę matematyczną, taką jak skalowanie wartości, aby pozbyć się ułamka albo trzymanie w jednej zmiennej części całkowitej, a w drugiej ułamkowej.
Mimo że z naszego punktu widzenia wszystkie te typy są diametralnie różne, dla procesora zawsze są tylko ciągiem zer i jedynek. Dlatego właśnie na liczbach int, czy znakach można wykonywać choćby operacje przesunięcia bitowego. Można również zmusić kompilator, aby jeden typ odczytał jako inny. Na tym właśnie polega operacja rzutowania w C, z którą wiele osób ma problemy. W asemblerze natomiast każda zmienna to po prostu dane binarne w pamięci i to od programisty zależy jak je potraktuje.
Działania matematyczne
Jak zapewne zauważyliście, procesor dysponuje tylko kilkoma podstawowymi działaniami, takimi jak:
dodawanie,
odejmowanie,
mnożenie,
operacje bitowe.
Pierwsze, co rzuca się w oczy to brak dzielenia. Tak, nawet tak trywialna operacja matematyczna to dla mikrokontrolera nie lada wyzwanie. Procesor radzi sobie z tym tak samo, jak człowiek mający do dyspozycji kartkę. Algorytm jest dość zbliżony do zwykłego dzielenia pisemnego! Może on jednak zajmować kilkadziesiąt taktów zegara, a do tego potrzebuje wielu rejestrów procesora.
Jest jednak jeden wyjątek - dzielenie przez potęgi dwójki.
Operacja ta w systemie binarnym jest tak naprawdę przesunięciem liczby w lewo lub w prawo o daną ilość miejsc. Dokładnie tak samo, jak w systemie dziesiętnym, gdzie mnożenie/dzielenie przez potęgi dziesiątki sprowadza się do przesuwania przecinka. Dzielenie jest zatem kolejną rzeczą, którą należy stosować z umiarem.
Przykładowo: umieszczanie wielu ilorazów w przerwaniu nie jest zbyt dobrym pomysłem. Chyba, że korzystamy tylko z dzielenia przez potęgi dwójki.
Skoro tyle problemów sprawia mikrokontrolerom zwykłe dzielenie, to aż strach pomyśleć o trudniejszych operacjach takich jak funkcje trygonometryczne, logarytmiczne, pochodne czy całki. Tutaj z pomocą przychodzą nam tricki matematyczne. A dokładniej aproksymacja funkcji czyli przybliżanie ich wartości na danych przedziałach. Jeżeli chodzi o funkcje okresowe, czyli na przykład trygonometryczne, można również zastosować tablice obliczonych wartości, a następnie je skalować.
Aproksymacja funkcji za pomocą wielomianów (szereg Taylora) opiera się na obserwacji, że dla każdej funkcji można znaleźć wielomian, który na pewnym przedziale się z nią pokrywa. Im wyższy stopień wielomianu, tym dokładniejsze przybliżenie.
Oczywiście operacje związane z obliczaniem takiego wielomianu dobrze byłoby wykonać wcześniej, na przykład w Matlabie, a w programie używać gotowych współczynników.
Jeżeli chodzi o aproksymowanie całkowania i różniczkowania, na forum można znaleźć mnóstwo przykładów związanych z implementacją algorytmu PID. Do całkowania jest tam wykorzystana metoda prostokątów. Inne metody aproksymacji całkowania to metoda trapezów i metoda Newtona-Raphsona. Różniczkowanie natomiast jest tam zwykle realizowane jako iloraz różnicowy.
Istnieje wiele algorytmów służących do aproksymacji funkcji. Wymagają one jednak dobrej wiedzy matematycznej, obejmującej między innymi funkcje trygonometryczne, wielomiany, rachunek całkowy i różniczkowy.
Zakończenie
Artykuł okazał się bardzo obszerny i porusza wiele różnych kwestii. Zdaję sobie sprawę, że pewnie niewielu osobom będzie potrzebny w całości na raz. Niemniej jednak warto znać informacje tutaj zawarte i wiedzieć, gdzie szukać przydatnych fragmentów.
Przy pisaniu posiłkowałem się wiedzą wyniesioną z zajęć na uczelni i własnej praktyki a także korzystałem z ogólnie dostępnych źródeł internetowych. Do tekstu mogły wkraść się błędy, a niektóre rzeczy mogłem opisać niewystarczająco jasno. Dlatego chętnie wysłucham wszelkich uwag.
Dołącz do 30 tysięcy osób, które otrzymują powiadomienia o nowych artykułach! Zapisz się, a otrzymasz PDF-y ze ściągami (m.in. na temat mocy, tranzystorów, diod i schematów) oraz listę inspirujących DIY na bazie Arduino i Raspberry Pi.
To nie koniec, sprawdź również
Przeczytaj powiązane artykuły oraz aktualnie popularne wpisy lub losuj inny artykuł »
Dołącz do 30 tysięcy osób, które otrzymują powiadomienia o nowych artykułach! Zapisz się, a otrzymasz PDF-y ze ściągami (m.in. na temat mocy, tranzystorów, diod i schematów) oraz listę inspirujących DIY z Arduino i RPi.

























Trwa ładowanie komentarzy...