Komunikacja z mikrokontrolerem przez UART ma wiele praktycznych zastosowań. Dlatego już teraz omówimy najprostsze podejście do obsługi takiej transmisji (i połączymy ją z funkcją printf).
Wskażemy też kilka częstych błędów związanych ze znakami końca linii i kodowaniem. Przy okazji skorzystamy także z debuggera.
GPIO w STM32 to podstawowy sposób komunikacji mikrokontrolera z otoczeniem (dioda, która miga, też coś sygnalizuje). Tym razem zajmiemy się jednak „prawdziwą” komunikacją, czyli np. przesyłaniem tekstu do i z komputera. Ćwiczenia z tej części kursu sprawią, że poznasz UART (na razie w najprostszej konfiguracji), dowiesz się, jak połączyć go z funkcją printf i jak korzystać z debuggera.
Czym jest RS-232, UART i USART?
Kiedyś właściwie wszystkie komputery PC były wyposażone w interfejs szeregowy RS-232, obecnie USB prawie zupełnie wyparło ten sposób komunikacji. Złącze szeregowe miało jedną ogromną zaletę: było proste w obsłudze (szczególnie porównując z USB).
W przypadku mikrokontrolerów (i zastosowań przemysłowych) port szeregowy jest nadal popularny, chociaż często w nieco innej postaci. RS-232 działał na dość nietypowych napięciach ±11 V (w praktyce tolerował od 3 V do 15 V), dlatego do jego obsługi potrzebny był jeszcze dodatkowy układ konwertera napięcia, np. popularny niegdyś MAX232.
Stary przewód do komunikacji przez RS-232
W mikrokontrolerach stosuje się jednak najczęściej uproszczoną wersję tego interfejsu, która działa np. na napięciach 0 V i 3,3 V. Moduł odpowiedzialny za obsługę takiej komunikacji nazywany jest UART (ang. universal asynchronous receiver and transmitter) lub też jako USART (ang. universal synchronous asynchronous receiver-transmitter). Druga wersja oznacza po prostu, że ten sam moduł może działać jako interfejs synchroniczny lub asynchroniczny (z tej części korzysta się najczęściej).
W dużym skrócie i uproszczeniu: transmisja synchroniczna wymaga przesyłania sygnału zegarowego, który jest wspólny dla nadajnika oraz odbiornika. Transmisja asynchroniczna nie potrzebuje linii z sygnałem zegarowym, bo każdy układ korzysta ze swojego zegara.
W przypadku UART-u transmisja rozpoczyna się od bitu startu (na rysunku jako BS); zawsze jest to bit będący logicznym zerem (0 V). Potem, zależnie od konfiguracji, następuje po sobie 7, 8 lub 9 bitów danych (na rysunku jest ich 8, od B0-B7), które są wysyłaną informacją (najczęściej jeden bajt). Z kolei bit stopu (tutaj jako BK) to bit będący logiczną jedynką – mówi o końcu transmisji. Format ramki oraz sposób transmisji UART-u jest właściwie niezmieniony względem RS-232.
Przykładowy przebieg UART-u
Płytka Nucleo, z której korzystamy podczas tego kursu, posiada wbudowany konwerter z UART na USB. Nie mamy więc po drodze nigdzie „prawdziwego” RS-232. Po podłączeniu do PC przejściówka z płytki Nucleo będzie widziana jako port COM, czyli nasz port szeregowy. To dla nas duża wygoda, bo inaczej musielibyśmy stosować jeszcze osobną przejściówkę USB<>UART.
STM32 i UART – pierwszy projekt
Krótki wstęp teoretyczny za nami, więc możemy przejść do praktyki. Zaczynamy od utworzenia nowego projektu z układem STM32L476RG (tak samo jak w poprzednich częściach kursu).
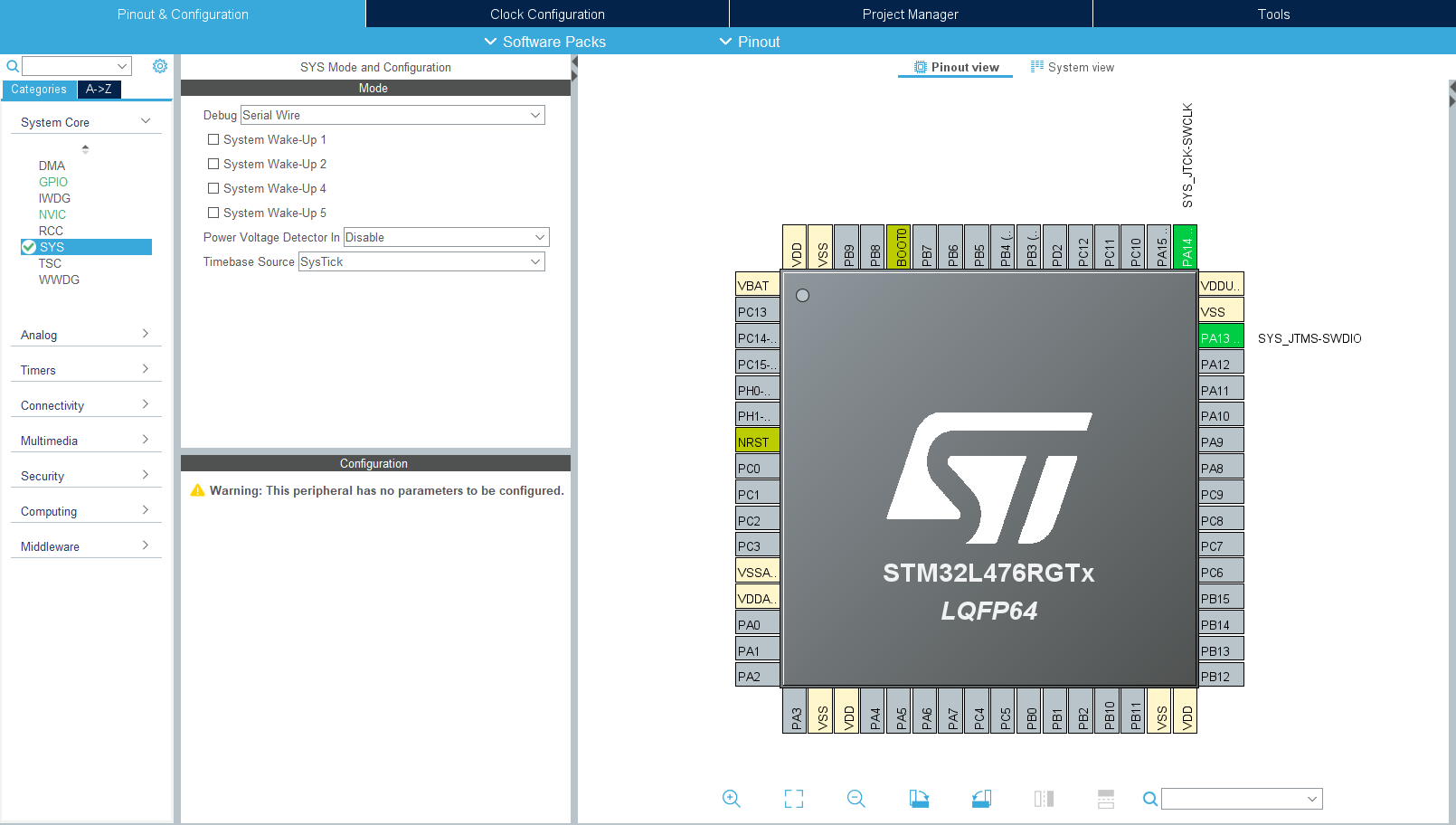
Ręczna konfiguracja pinów debuggera
Zanim przejdziemy do samej komunikacji, przyda się jednak jeszcze małe uzupełnienie konfiguracji naszego projektu. Na płytce Nucleo znajduje się programator, którego używaliśmy do uruchamiania programów na naszym mikrokontrolerze. Komunikacja między tym układem a programatorem odbywa się za pomocą pinów PA13 oraz PA14. Jednak w naszych projektach w żaden sposób nie konfigurowaliśmy tych GPIO. Jak to więc możliwe, że programator działał?
Okazuje się, że domyślnie na pinach PA13 i PA14 są już włączone funkcje SWDIO oraz SWDCLK, czyli jeśli nic z tym nie zrobimy, to programator będzie działał domyślnie. Właśnie z takiej domyślnej opcji korzystaliśmy do tej pory. Jednak poleganie na domyślnych ustawieniach jest czasem dość ryzykowne, uzupełnijmy zatem nasz projekt o konfigurację wyprowadzeń podłączonych do programatora.
Na liście modułów peryferyjnych musimy odszukać moduł SYS. Jeśli używamy widoku z podziałem na kategorie, to znajdziemy go w grupie System Core. Po wybraniu tego modułu zobaczymy dostępne opcje konfiguracyjne. Nas interesuje pierwsza z nich, czyli Debug. Z listy możliwych opcji debugowania wybieramy Serial Wire – CubeMX ustawi automatycznie odpowiednie funkcje dla pinów PA13 i PA14.
Ręczna konfiguracja pinów odpowiedzialnych za komunikację z programatorem
Dzięki wybraniu opcji Serial Wire od teraz STM32CubeMX będzie dbał o to, żebyśmy przypadkiem nie zmienili ustawień pinów programatora, co mogłoby doprowadzić do problemów z komunikacją. Jest to jedno z tych ustawień, które teoretycznie nie jest potrzebne, ale warto o nim pamiętać.
Konfiguracja UART-a na STM32
Teraz możemy już przejść do głównego tematu tej części kursu. Nasz mikrokontroler ma w sobie liczne peryferia, niektóre występują nawet w kilku egzemplarzach. Tak właśnie jest np. z UART-em – wewnątrz tego mikrokontrolera znajdziemy aż sześć sprzętowych UART-ów.
Występują między nimi różnice, jednak w bardzo dużym uproszczeniu można przyjąć, że ten układ ma sprzętowe peryferia, dzięki którym potrafi nawiązać komunikację równocześnie aż z sześcioma różnymi urządzeniami (w przypadku Arduino UNO mamy tylko jedną sztukę sprzętowego UART-a).
Jednym z sześciu UART-ów jest tzw. LPUART (ang. low-power UART), czyli interfejs, który daje nam trochę mniej możliwości konfiguracyjnych, ale za to jest energooszczędny.
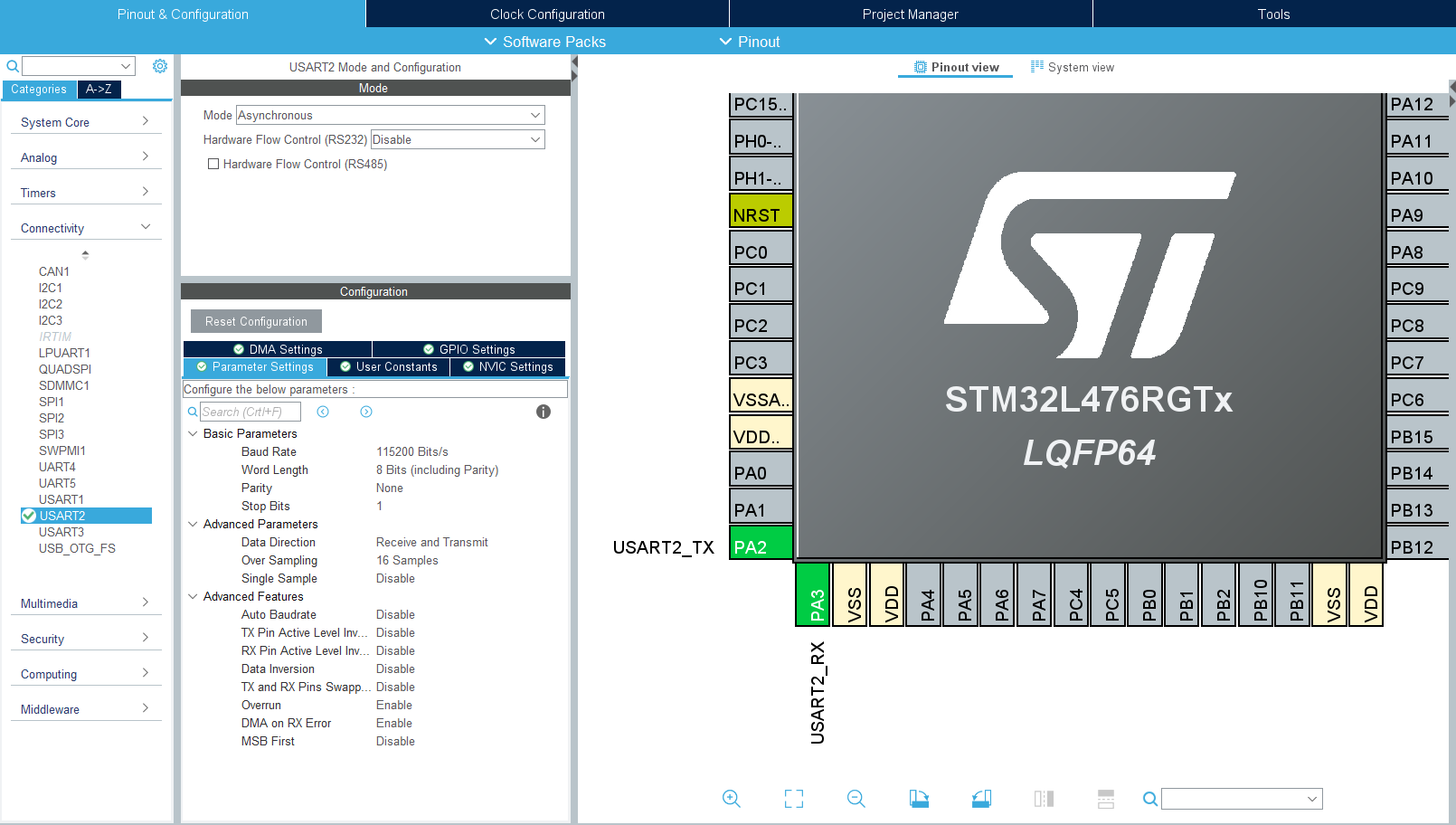
Podczas naszych eksperymentów będziemy korzystać z interfejsu USART2, ponieważ jest on domyślnie połączony z przejściówką USB, która wbudowana jest w programator. Dzięki temu będziemy mogli bardzo łatwo wysyłać dane do PC.
Tym razem w widoku modułów odnajdujemy więc USART2 (w kategorii Connectivity). W ustawieniach wybieramy tryb asynchroniczny (Mode na Asynchronous). Wszystkie pozostałe ustawienia zostawiamy domyślne, warto jednak wyjaśnić chociaż najważniejsze z nich:
Baud Rate – to prędkość komunikacji przez nasz port szeregowy; domyślna wartość to standardowe 115 200 bitów na sekundę (tyle nam teraz wystarczy).
Word Length – domyślnie przesyłamy dane 8-bitowe, co odpowiada wielkości typowego bajta. Można jednak wysyłać też dane w formacie 7- lub 9-bitowym.
Parity – bit parzystości; nie używamy go, więc zostawiamy opcję None.
Stop Bits – jeden bit stopu jest bardzo popularnym trybem, ale warto wiedzieć, że można używać też innych wartości.
Konfiguracja UART-a na STM32 w STM32CubeIDE
Wspomniane ustawienia dają nam standardowy tryb komunikacji: 115 200 bitów na sekundę, jeden bit stopu oraz brak kontroli parzystości. Wybór tych opcji sprawił, że CubeMX od razu opisał odpowiednio dwa piny mikrokontrolera – to właśnie one będą wykorzystywane do transmisji. Po zapisaniu zmian i wygenerowaniu szkieletu programu możemy przystąpić do pisania naszego kodu.
Gotowe zestawy do kursów Forbota
Komplet elementów Gwarancja pomocy Wysyłka w 24h
Zamów zestaw elementów i wykonaj ćwiczenia z tego kursu! W komplecie płytka NUCLEO-L476RG oraz m.in. wyświetlacz graficzny, joystick, enkoder, czujniki (światła, temperatury, wysokości, odległości), pilot IR i wiele innych.
CubeMX wygenerował za nas kod niezbędny do konfiguracji modułu USART2, utworzył też zmienną o nazwie huart2, której adres przekażemy jako pierwszy parametr. Kolejne dwa parametry opisują dane, które chcemy wysłać, natomiast ostatnia wartość pozwala ograniczyć czas, jaki funkcja może czekać na wysłanie danych. Jeśli nie spodziewamy się żadnych problemów, możemy pozwolić na dowolnie długie oczekiwanie – w tym celu można wykorzystać definicję HAL_MAX_DELAY.
Wartością zwracaną przez tę funkcję jest status operacji. Będzie to najczęściej HAL_OK, ale możliwe są również powiadomienia o przekroczeniu czasu oczekiwania (HAL_TIMEOUT), zajętości modułu UART (HAL_BUSY) lub o błędzie (HAL_ERROR).
W ramach pierwszego przykładu wyślemy do komputera oczywiście napis „Hello world!”. W minimalnej wersji mogłoby to wyglądać następująco:
Mamy tam wpisany tekst, który ma się wyświetlić, oraz liczbę znaków. Taki program zadziała, ale jest mało wygodny (nie będziemy przecież zawsze ręcznie liczyć znaków). Dlatego rozbijmy to na dwie linie. Pierwsza z nich to tablica znaków, które tworzą napis, a druga linijka to właściwe wysłanie danych. Tym razem chcemy użyć funkcji strlen, która sama policzy długość wiadomości. Poniższy kod dodajemy oczywiście w odpowiednim miejscu, czyli np. nad pętlą while (aby wysłać ten napis tylko raz).
/* USER CODE BEGIN 2 */
const char message[] = "Hello world!\r\n";
HAL_UART_Transmit(&huart2, message, strlen(message), HAL_MAX_DELAY);
/* USER CODE END 2 */
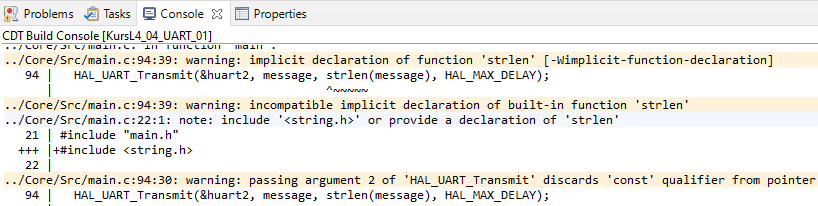
Taki program kompiluje się bez błędów, ale pojawiają się jednak ostrzeżenia. Najważniejsze ostrzeżenie dotyczy funkcji strlen, która została przez nas użyta do zmierzenia długości wysyłanej wiadomości.
Ostrzeżenia dotyczące funkcji strlen podczas kompilacji
Funkcja ta jest częścią standardowej biblioteki języka C, ale musimy jeszcze dołączyć plik string.h, aby kompilator widział jej sygnaturę. W odpowiednim miejscu kodu dodajemy więc stosowną linijkę:
/* USER CODE BEGIN Includes */
#include <string.h>
/* USER CODE END Includes */
Drugie ostrzeżenie dotyczy niepoprawnego typu drugiego parametru, który przekazaliśmy do funkcji HAL_UART_Transmit. W rzeczywistości są to dwa ostrzeżenia. Nasza wiadomość ma typ const char *, bo jest to wskaźnik do stałego napisu. Natomiast funkcja HAL_UART_Transmit oczekuje parametru typu uint8_t * (bo tak założyli sobie autorzy biblioteki). Czyli pierwszy problem to modyfikator const, a drugi dotyczy typu uint8_t zamiast char.
Natomiast różnica między char a uint8_t dotyczy znaku. Typ char, w zależności od kompilatora, może być typem ze znakiem lub bez i w naszym przypadku ma znak, natomiast uint8_t jest typem bez znaku. Jeśli chcemy pozbyć się tych ostrzeżeń kompilatora, to najprostszym rozwiązaniem będzie zwyczajne, jawne rzutowanie typu wskaźnika przez poprzedzenie zmiennej z wiadomością przez „(uint8_t*)”.
Taka zmiana sprawi, że nasz program skompiluje się już bez żadnych ostrzeżeń. Od razu warto zwrócić uwagę na jeszcze jedną ważną wartość, czyli rozmiar programu wynikowego. Jest to 11,74 KiB, czyli zaledwie 1,15% dostępnej pamięci flash. To świetny wynik!
Podsumowanie informacji na temat gotowego programu
Uruchomienie programu
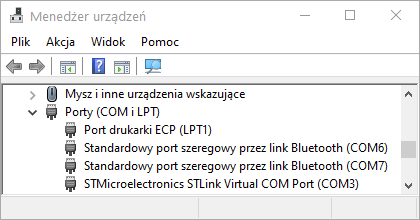
Wgranie programu i uruchomienie kodu to nie problem – proces ten został już wcześniej omówiony. Tym razem musimy jednak odebrać dane, które przesyłane są do komputera przez UART. W tym celu trzeba poznać nr portu COM, który został przypisany do naszego Nucleo. Informację tę znajdziemy jak zawsze w menedżerze urządzeń systemu Windows.
Widoczność płytki jako portu COM
Gdy upewnimy się, że port szeregowy został poprawnie rozpoznany, i znamy już jego numer, mamy teraz dwie opcje. Możemy wykorzystać terminal, który jest wbudowany w STM32CubeIDE, możemy też posłużyć się zewnętrznym programem, np. popularnym Tera Term – i właśnie z tej opcji skorzystamy, by przetestować ten przykład. Zaraz po tym sprawdzimy również jednak, jak działa terminal, który jest wbudowany w nasze środowisko, ale to już tylko w ramach ciekawostki „dla chętnych”.
Odbieranie danych przez Tera Term
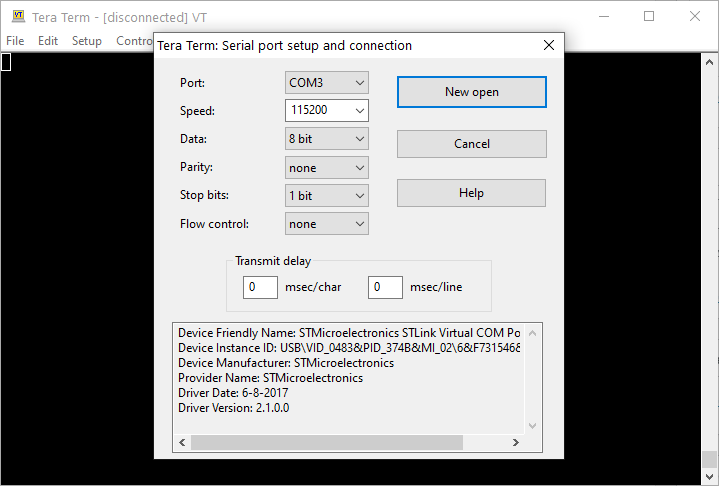
Program można oczywiście pobrać za darmo ze strony projektu. Po uruchomieniu Tera Term musimy ustawić konfigurację naszego portu. W tym celu z menu Setup wybieramy opcję Serial port. W nowym oknie wybieramy odpowiedni numer portu COM i ustawiamy parametry transmisji: prędkość 115 200, osiem bitów danych, brak parzystości, brak kontroli przepływu oraz jeden bit stopu.
Ustawienia dla pierwszego połączenia Tera Term z Nucleo
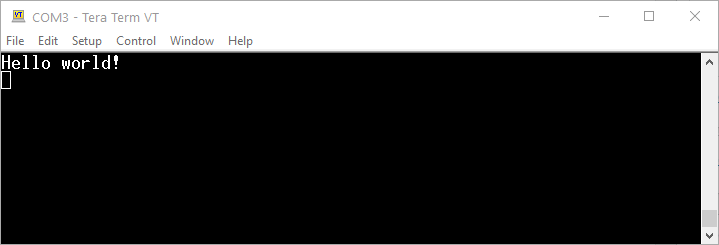
Ustawienia zatwierdzamy przyciskiem OK – teraz możemy przetestować działanie transmisji. Komunikat w naszym programie wysyłany jest tylko raz. Musimy więc od nowa uruchomić program, który został wgrany na mikrokontroler (możemy też po prostu nacisnąć przycisk resetu na Nucleo). Jeśli wszystko przebiegnie poprawnie, to na ekranie wyświetli się nasze upragnione „Hello world!”.
Pierwszy komunikat, który został poprawnie odebrany
Terminal wbudowany w STM32CubeIDE
Zgodnie z zapowiedzią sprawdzimy teraz, jak odebrać te same dane prosto w naszym IDE. W tym celu zamykamy Tera Term i wracamy do STM32CubeIDE. Restartujemy program, a następnie w dolnej części okna wybieramy opcję Open Console > Command Shell Console.
Dodawanie nowego okna konsoli
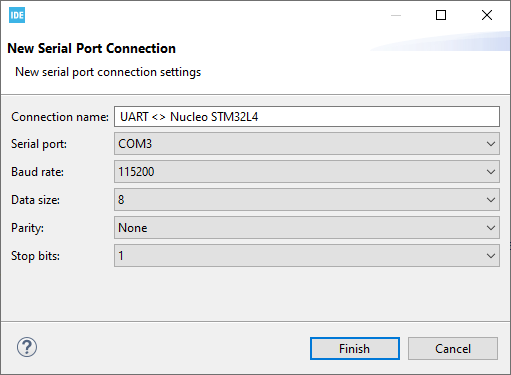
W nowym oknie wybieramy typ na Serial Port, a następnie klikamy przycisk New, aby podać parametry naszego połączenia. Wpisujemy tam dowolną nazwę, wybieramy numer portu COM oraz prędkość.
Ustawienia połączenia dla wbudowanego terminala
Po zatwierdzeniu wszystkich opcji i ponownym włączeniu programu zobaczymy tekst, który zostanie wyświetlony w dolnej części okna. Jednak dla nas to była tylko ciekawostka, bo nie będziemy używać tej opcji podczas dalszych ćwiczeń z tego kursu.
Podgląd danych za pomocą wbudowanego terminala
Po zakończeniu pracy z tym terminalem warto ręcznie zamknąć połączenie z portem COM (czerwona ikona Disconnect po prawej stronie okna). W przeciwnym wypadku mogą wystąpić różne problemy z komunikacją (między środowiskiem a Nucleo) i programowaniem.
Różnice między funkcjami sizeof oraz strlen
W programie wywołaliśmy funkcję strlen, dzięki której obliczyliśmy długość wysyłanego komunikatu. Funkcja ta zwraca liczbę znaków, które zawiera dany napis. W naszym przypadku jest to 14 – napis „Hello world!” ma 12 znaków, ale do tego dodajemy 2 znaki końca linii. Gdybyśmy zamiast strlen użyli sizeof, otrzymalibyśmy liczbę bajtów zajmowaną przez zmienną, czyli 15.
Oto jak naprawdę w programie zapisany jest napis „Hello world!”
Różnica wynika ze sposobu zapisywania napisów w języku C. Na końcu każdego napisu znajduje się znak o kodzie zero („\0”). Funkcja strlen zwraca nam długość napisu, nie uwzględnia więc końcowego znaku zerowego. Z kolei sizeof podaje, ile bajtów zajmuje całość (razem z końcowym znakiem), a nie potrzebujemy tej informacji, by wysyłać dane przez UART.
Wysyłanie danych z użyciem printf
W bibliotece standardowej języka C znajdziemy popularną funkcję printf, pozwalającą na wygodne formatowanie komunikatów tekstowych, które wyświetlane są w konsoli. Możemy z niej skorzystać również w przypadku portu szeregowego – nie jest to jednak takie oczywiste.
Na początek otwieramy plik o nazwie syscalls.c, który został utworzony przez CubeMX. Znajdziemy go w folderze Core > Src naszego projektu. Plik ten zawiera implementację używanych przez bibliotekę standardową funkcji, które w przypadku PC są implementowane w systemie operacyjnym.
Funkcja o nazwie _write jest wywoływana przez printf przy wypisywaniu przez nas komunikatów:
__attribute__((weak)) int _write(int file, char *ptr, int len)
{
int DataIdx;
for (DataIdx = 0; DataIdx < len; DataIdx++)
{
__io_putchar(*ptr++);
}
return len;
}
Jak widać, jest to funkcja z atrybutem weak, co oznacza, że możemy zastąpić ją własną wersją tej funkcji (np. deklarując ją w pliku main.c). Podczas kompilacji wykorzystana zostanie „nasza” wersja, a kompilator nie wyświetli błędu, że dana funkcja została wcześniej zadeklarowana już w innym miejscu.
Jej domyślna implementacja sprowadza się do przesłania kolejnych znaków do funkcji __io_putchar, która również została zadeklarowana z atrybutem weak:
extern int __io_putchar(int ch) __attribute__((weak));
Mamy więc dwie możliwości przekierowania komunikatów z printf na UART:
możemy napisać własną funkcję __io_putchar i wysyłać za jej pomocą po jednym znaku,
możemy też zastąpić _write własną wersją tej funkcji i przesyłać od razu cały napis.
Ta druga opcja mogłaby działać nieco szybciej, jednak nadpisanie __io_putchar jest łatwiejsze, a przy okazji pozwala na proste poprawienie kwestii znaków końca linii (o czym za chwilę). Wracamy więc do naszego kodu, czyli do pliku main.c, i dodajemy tam własną wersję tej funkcji.
/* USER CODE BEGIN 0 */
int __io_putchar(int ch)
{
HAL_UART_Transmit(&huart2, (uint8_t*)&ch, 1, HAL_MAX_DELAY);
return 1;
}
/* USER CODE END 0 */
Działanie tej funkcji jest bardzo proste. Dostajemy jako parametr znak do wysłania, przekazujemy go do znanej nam funkcji HAL_UART_Transmit, a na koniec zwracamy liczbę wysłanych znaków, która i tak nie jest nigdzie używana (zawsze i tak wynosi 1). Od teraz używanie printf nie różni się od tego, co spotyka się na PC.
Możemy więc przetestować nieśmiertelny przykład – wystarczy dodać tę funkcję nad pętlą while zamiast naszych dwóch wcześniejszych linijek:
printf("Hello world!\r\n");
Kompilator może zgłosić jeszcze ostrzeżenia wynikające z braku stdio.h, więc w odpowiednim miejscu dopisujemy kolejny plik nagłówkowy:
#include <stdio.h>
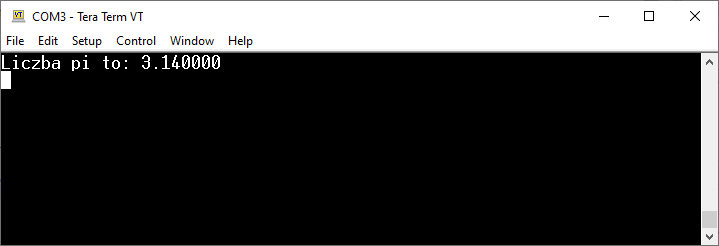
Po uruchomieniu programu zobaczymy w terminalu komunikat „Hello world!” – tym razem pojawi się on tam dzięki użyciu printf. To jednak nie koniec naszych zmagań z tą funkcją. Dla formalności możemy też sprawdzić, czy nasza funkcja na pewno działa poprawnie. Zamieniamy więc „Hello world!” na coś, co sprawdzi działanie printf (np. wstawmy wyraz do środka zdania):
printf("Hej %s! Co u Ciebie?\r\n", "FORBOT");
Spodziewamy się, że napis „FORBOT” zostanie podstawiony do tekstu w miejscu „%s” – i tak właśnie się dzieje. Wszystko działa poprawnie. Jeśli nie znasz tego zapisu, to koniecznie poczytaj o funkcji printf.
Efekt działania programu z funkcją printf
Pułapka nr 1: znaki końca linii
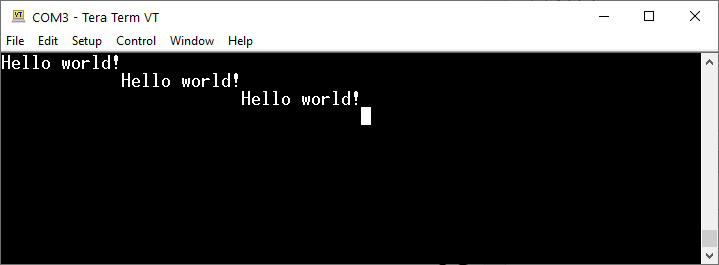
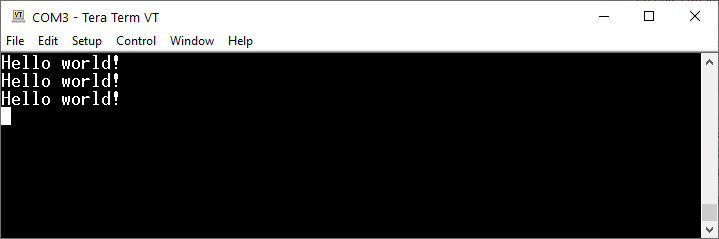
Pewną niedogodnością w naszych dotychczasowych programach jest konieczność używania aż dwóch znaków końca linii. Nie wynika to ze specyfiki biblioteki HAL czy samego STM32, ale używanego przez nas systemu operacyjnego, czyli Windowsa. Wróćmy do przykładu z „Hello world!” i zobaczmy, co się stanie, jeśli zamiast „\r\n” w programie użyjemy tylko „\n”.
W wyniku działania takiej wersji programu otrzymamy prawdopodobnie efekt jak poniżej. Wygląda to dość ciekawie, ale nie o to nam chodziło.
Wynik działania programu, jeśli korzystamy z jednego znaku końca linii
Możemy ten problem rozwiązać na kilka sposobów:
możemy pamiętać o używaniu „\r\n” na końcu linii,
możemy zmienić ustawienia Tera Term,
możemy też edytować funkcję __io_putchar.
Z pierwszego rozwiązania korzystaliśmy wcześniej, drugie jest proste i wygodne, ale nie każdy program odbierający dane będzie miał taką opcję. Co więcej, niezbyt wygodne będzie pamiętanie o konieczności zmiany ustawień, gdy np. instalujemy nowy program albo zmieniamy komputer.
Spróbujmy więc skorzystać z trzeciej opcji, czyli zmiany __io_putchar. Chcemy, żeby zamiast znaku „\n” funkcja wysyłała dwa znaki, tak jak tego oczekuje Windows. Możemy to zrealizować bardzo prosto, trzeba tylko sprawdzać, jaki znak ma być „za chwilę” wysłany. Jeśli wykryjemy, że zaraz będzie wysyłany znak „\n”, to możemy tuż przed nim automatycznie „wstrzelić” znak „\r”, co łącznie da „\r\n”.
Funkcja __io_putchar może zatem wyglądać np. w taki sposób:
Działanie programu, w którym drugi znak nowej linii dodawany jest automatycznie
O co chodzi ze znakami końca linii?
Bardzo dawno temu zamiast monitorów były używane drukarki. Efekt działania programu był wtedy drukowany na papierze. Drukarki te nie mogły drukować kolorowych grafik; co więcej, ich możliwości drukowania tekstów również były ograniczone. Ich działanie najlepiej porównać do jeszcze starszych maszyn do pisania, których pewnie większość czytelników tego kursu już nawet nie pamięta.
Maszyna do pisania, z której zaczerpnięto pewne określenia
W przypadku maszyny do pisania po napisaniu linii tekstu konieczne było wykonanie dwóch czynności:
powrót wózka (to ta ruchoma część z nawiniętym papierem) do początkowej pozycji,
przesunięcie papieru do następnej linii.
Pierwsza czynność po angielsku nazywana jest carriage return, w skrócie CR. Druga to line feed, czyli LF. Gdy tworzono komputery, maszyny do pisania były wszystkim bardzo dobrze znane. Podczas pisania pierwszych programów używano więc terminów, które znane były właśnie z maszyn do pisania. Nie inaczej było z programowymi znakami końca linii – otrzymały one nazwy LF oraz CR.
Niestety kolejność ich użycia nie została już w pełni ustandaryzowana.
A jak to się ma do naszego programu? Kod „\n” to nic innego jak LF, czyli przesunięcie do następnego wiesza. Natomiast znak „\r” oznacza CR, co odpowiada powrotowi karetki do początkowej pozycji. Żartobliwie można powiedzieć, że Windows zatrzymał się na etapie maszyn do pisania, więc na tym systemie cały czas wymagane jest najpierw przesłanie CR, a potem LF. Oba znaki występują zawsze razem, nie mogą być niczym oddzielone. Dlatego w programie pisaliśmy:
printf("Hello world!\r\n");
Użycie dwóch znaków jest mało efektywne i nie ma większego sensu w dobie komputerów. W związku z tym systemy Unix (i pochodne) używają tylko jednego znaku. W tym przypadku zdecydowano się na pozostanie tylko przy LF, czyli „\n”. Dlatego klasyczny przykład z „Hello world!” ma właśnie taką postać:
printf("Hello world!\n");
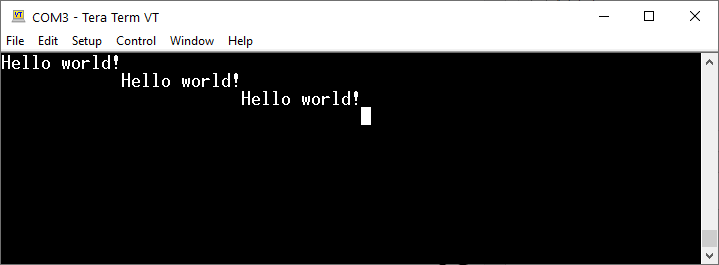
Jednak jeśli korzystamy z Windowsa, to system zrozumie to dosłownie – LF to przesunięcie kursora do następnego wiersza, ale bez powrotu karetki. Dlatego następny wiersz będzie zaczynał się od kolejnej kolumny. Wysłanie kilku takich napisów daje efekt jak ten, który był już widoczny wcześniej.
Efekt wysyłania nowych danych po przejściu do kolejnego wiersza, ale bez powrotu karetki
Na koniec warto wspomnieć, że możliwe są jeszcze dwie kombinacje końców linii, czyli kod CR albo LFCR. Takie opcje były używane w zapomnianych już systemach operacyjnych; obecnie też często się pojawiają, przede wszystkim jako drobne błędy w programach, których nie warto powielać.
Pułapka nr 2: buforowanie
Spróbujmy wysłać nieco inny komunikat – trzy napisy, ale bez znaków końca linii:
Można byłoby pomyśleć, że coś takiego sprawi, że na naszym ekranie wyświetlą się obok siebie trzy napisy. Jeśli jednak przetestujemy nasz program, to nie zobaczymy absolutnie nic.
Okazuje się, że funkcja printf nie wysyła naszych danych natychmiast, zamiast tego zachowuje je w wewnętrznym buforze, a przesyła dopiero po dojściu do końca linii (co jest wykrywane oczywiście za pomocą wspomnianych już wielokrotnie znaków końca linii).
Takie działanie jest bardzo wygodne i przyspiesza pracę tego mechanizmu, może jednak prowadzić do błędów (jak w tym przykładzie). Żeby program zadziałał, możemy wysłać znak końca linii, czyli dodać:
printf("\n");
Co jednak zrobić, gdybyśmy faktycznie chcieli wysłać tylko jeden wiersz? Wówczas musimy wymusić opróżnienie bufora. Pomoże nam w tym funkcja fflush, należąca do standardowej biblioteki języka C.
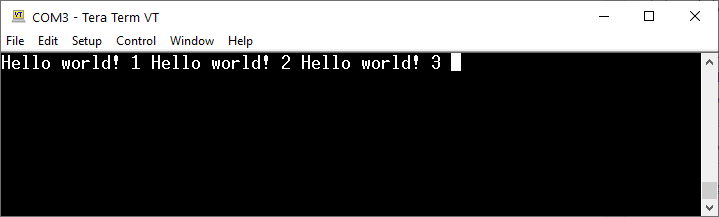
Tym razem zgodnie z planem zobaczymy trzy napisy, które będą wyświetlone obok siebie:
Efekt działania programu z ręcznym opróżnieniem bufora
Jeszcze tylko małe wyjaśnienie, czym jest stdout – jest to zmienna globalna zdefiniowana w bibliotece standardowej, która odpowiada strumieniowi wyjściowemu, czyli wyjściu naszego printf. Więcej na ten temat można przeczytać np. w tym miejscu.
Obsługa liczb float przez funkcję printf
Wiele osób zachęconych możliwością skorzystania z funkcji printf zechce użyć jej do wypisywania liczb zmiennopozycyjnych. Spróbujmy zmodyfikować nasz przykład, dodając następujący kod:
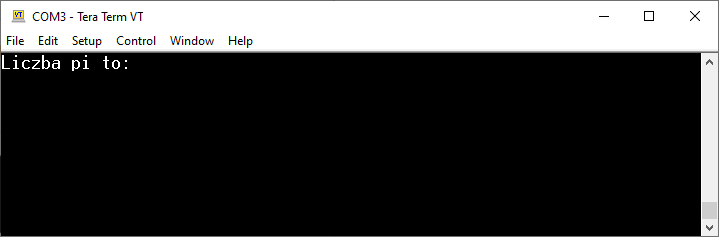
float pi = 3.14f;
printf("Liczba pi to: %f\n", pi);
Rezultat jest nieco rozczarowujący. Program co prawda kompiluje się poprawnie, ale nie działa zgodnie z oczekiwaniami. Wygląda na to, że funkcja printf nie działa całkiem dobrze, bo wartość zmiennej pi nie została podstawiona w odpowiednim miejscu.
Błędne działania funkcji printf w połączeniu ze zmienną float
Dlaczego tak się dzieje? Co ciekawe, kompilator nie ma zastrzeżeń do programu. Jednak środowisko STM32CubeIDE zgłasza nam pewne problemy (zakładka Problems).
Środowisko informuje nas, że nie włączyliśmy obsługi formatowania dla zmiennych float
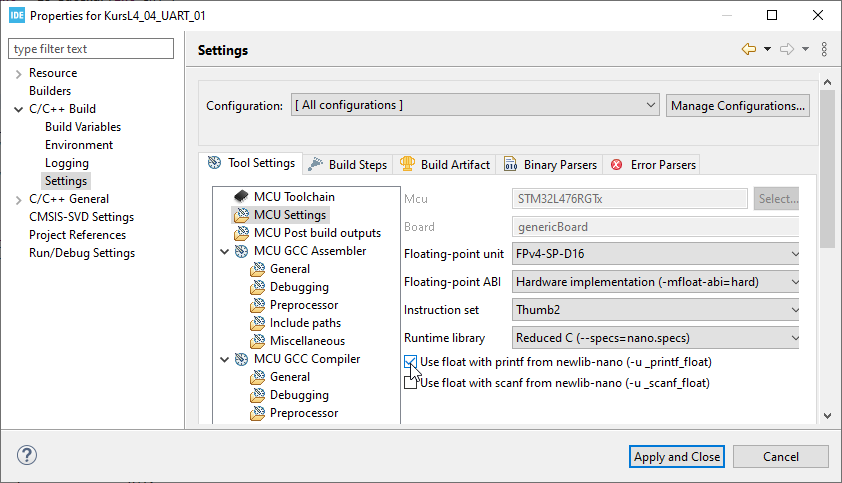
Aby zmienić to ustawienie, musimy przejść do ustawień STM32CubeIDE. Klikamy Project > Properties, a następnie w nowym oknie C/C++ Build > Settings, dalej w zakładce Tool Settings klikamy MCU settings i zaznaczamy opcję Use float with printf from newlib-nano. Na koniec zatwierdzamy nowe ustawienia.
Opcja, którą należy aktywować, aby program zadziałał poprawnie
Teraz musimy skompilować program całkowicie od zera. Wybieramy z menu opcję Project > Clean, a następnie kompilujemy program i uruchamiamy go na mikrokontrolerze. Tym razem całość zadziała zgodnie z naszymi oczekiwaniami – zawartość zmiennej zostanie podstawiona do tekstu.
Poprawne działanie funkcji printf ze zmienną typu float na STM32L4
Warto jeszcze zwrócić uwagę na wzrost wielkości programu. Pierwszy program zajmował nieco ponad 17 KiB pamięci flash, a po włączeniu obsługi printf oraz liczb zmiennopozycyjnych jego objętość wzrosła do ponad 26 KiB. To dużo dla wielu układów, ale w przypadku STM32L476RG mamy do dyspozycji aż 1 MiB flasha, więc możemy sobie pozwolić na luksus korzystania z takich udogodnień.
Statystyki wykorzystania pamięci przez nową wersję programu
Odbieranie danych przez UART
Umiemy już wysyłać dane, możemy więc przejść do czegoś trudniejszego, czyli do odbierania. Dlaczego jest to znacznie trudniejsze? Wysyłając dane, wiemy, ile mamy ich wysłać, decydujemy też, kiedy i w jakim tempie będziemy je nadawać. Natomiast odbierając, musimy dostosować się do „humoru” nadawcy, co – jak zobaczymy – nie zawsze jest proste.
Na początek bardzo prosty przykład, czyli odbieranie pojedynczych bajtów. Biblioteka HAL udostępnia funkcję HAL_UART_Receive, która – jak łatwo się domyślić – służy do odbierania danych przez UART. Jej prototyp (nagłówek) wygląda następująco:
Parametry tej funkcji oraz wartości zwracane są podobne do znanej nam już funkcji wysyłającej dane – HAL_UART_Transmit, możemy więc od razu przystąpić do napisania pierwszego programu, w którym zwyczajnie odbieramy bajt, zapisujemy go do zmiennej value, a następnie odsyłamy do PC.
Tym razem nasz kod musi znaleźć się wewnątrz pętli while, bo chcemy cały czas sprawdzać, czy układ odebrał jakieś dane (przypominamy, że w tej części kursu omawiamy najprostsze podejście do tematu, później wrócimy jeszcze np. do przerwań).
/* Infinite loop */
/* USER CODE BEGIN WHILE */
while (1)
{
uint8_t value;
HAL_UART_Receive(&huart2, &value, 1, HAL_MAX_DELAY);
printf("Odebrano: %c\n", value);
/* USER CODE END WHILE */
/* USER CODE BEGIN 3 */
}
/* USER CODE END 3 */
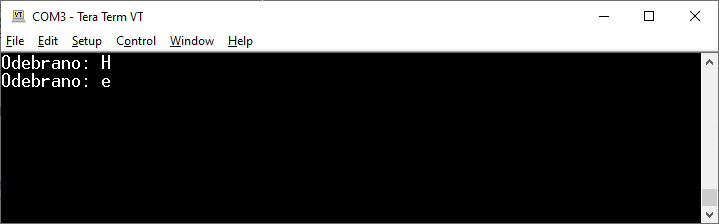
Wybraliśmy uproszczone podejście. Jako timeout podajemy HAL_MAX_DELAY, więc program będzie czekał tak długo, aż w końcu coś odbierze. W związku z tym, że nie wiemy, ile danych mamy odebrać, to odbieramy tylko jeden bajt. W ten sposób nieco „uciekliśmy” od problemów i możemy cieszyć się działającym programem. Pora, aby przetestować kod – wystarczy naciskać klawisze na klawiaturze w aktywnym oknie Tera Term. Każde naciśnięcie klawisza od razu wysyła przez port COM dany znak (bajt).
Tera Term w swojej domyślnej konfiguracji nie wyświetla samemu danych, które wpisywane są na klawiaturze (dlatego widzimy tylko to, co odesłał STM32).
Efekt działania pierwszego programu, który odsyła odebrane dane
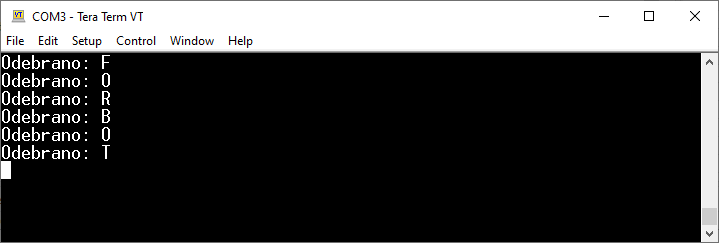
Wszystko pięknie działa, jeśli wysyłamy kolejne znaki powoli, np. przyciskając klawisze na klawiaturze. Jednak jeśli spróbujemy wysyłać dane bardzo szybko, to okaże się, że program nie działa prawidłowo. Spróbujmy, np. metodą kopiuj-wklej, wysłać komunikat „Hello Forbot” do Tera Term.
W tym celu przyda się nam opcja w menu Tera Term o nazwie Edit > Paste <CR>. Dzięki niej możemy wysłać ciąg danych ze schowka, do którego zostanie dodany znak końca linii. W efekcie działania tego programu zobaczymy, że pierwsze znaki zostaną poprawnie odebrane, a później komunikacja zupełnie przestanie działać.
Program, który zawiesił się po odebraniu pierwszych danych
Jak zostało wspomniane, odbieranie jest trudniejsze od wysyłania. Dzieje się tak, bo to nadajnik decyduje o tempie przesyłania danych. W tym przypadku po każdym odebranym bajcie wysyłamy odpowiedź za pomocą printf, program potrzebuje więc trochę czasu, zanim będzie mógł przyjąć następny bajt. Nasz program jest niedoskonały, bo nie korzystamy ze wsparcia sprzętu, np. przerwań, które omówimy później. Jednak nawet z przerwaniami taki problem może wystąpić.
Jeśli nadajnik wysyła dane dużo szybciej, niż odbiornik potrafi je przetwarzać, to po pewnym czasie zapełnią się bufory odbiorcze i część danych będzie gubiona.
Nie jest to więc niespotykany problem, natomiast większym problemem jest „zawieszanie” komunikacji po wystąpieniu przepełnienia. „Winnym” okazuje się tutaj mechanizm sprzętowej detekcji przepełnienia (ang. overrun). Możliwość wykrycia zgubienia danych jest bardzo cenna i dobrze, że STM32 wykrywa to zdarzenie, ale niestety domyślne działanie biblioteki HAL w sytuacji, gdy nie korzystamy z przerwań ani DMA, może prowadzić do pewnych problemów.
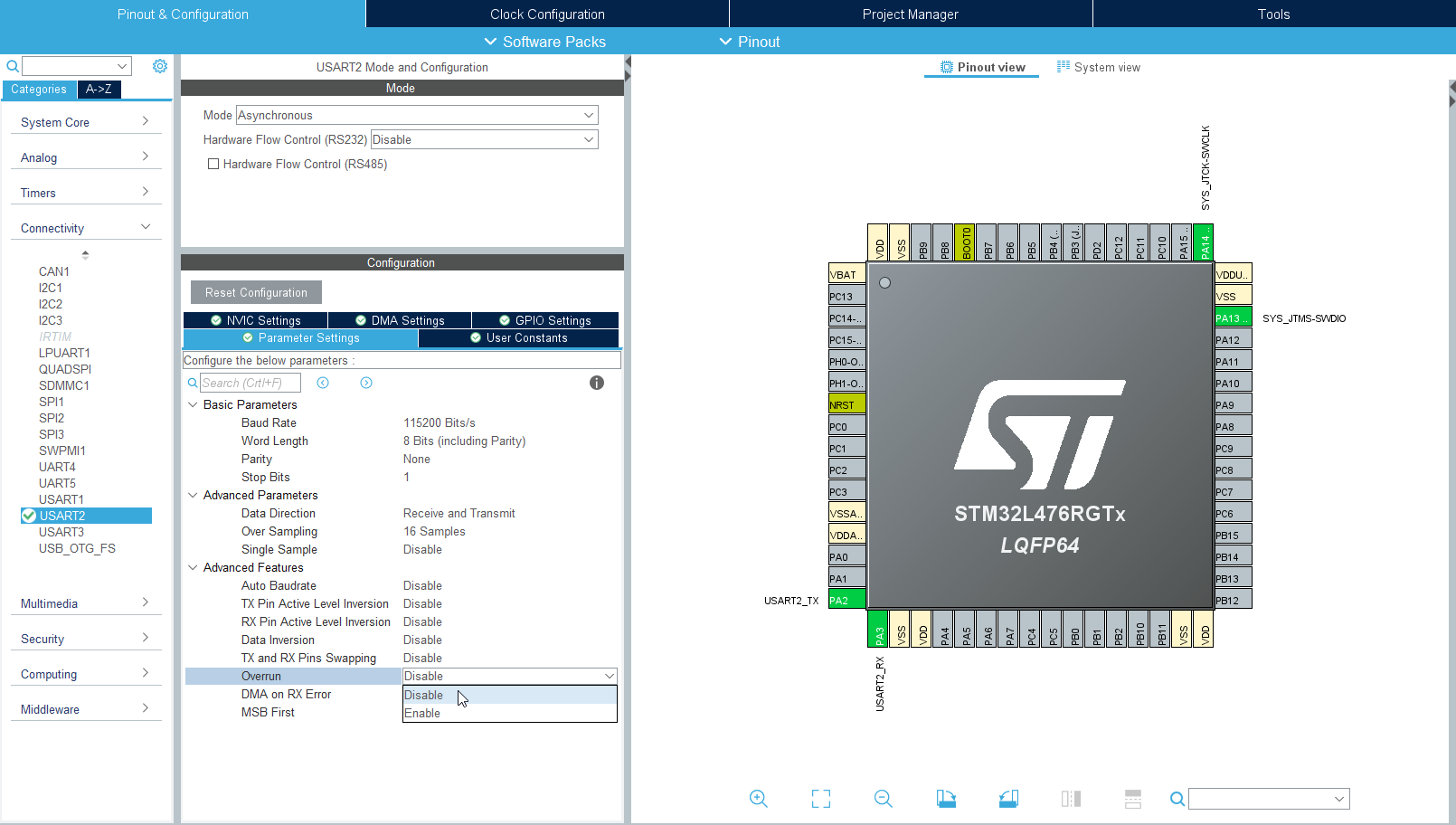
Najprostszym rozwiązaniem w tej sytuacji będzie wyłączenie wykrywania przepełnienia. Wracamy do perspektywy CubeMX, wybieramy używany moduł USART2, a następnie w grupie Advanced Features odnajdujemy parametr opisany jako Overrun. Domyślnie jest on włączony – wyłączamy go, zmieniając ustawienie na Disable.
Wyłączenie funkcji Overrun w ustawieniach STM32CubeMX
Teraz możemy skompilować kod i przetestować go ponownie. Jeśli będziemy szybko przesyłać dane, to część informacji zostanie zgubiona (najpewniej zobaczymy pierwszy i ostatni znak wklejanego ciągu), ale teraz całość nie przestaje działać. Gdy nadajnik spowolni tempo wysyłania danych, komunikacja wróci do normy. Oczywiście nie jest to idealne rozwiązanie, więc spróbujemy zrobić coś, aby nasz program działał poprawnie.
Zamiast wyłączenia detekcji przepełnienia lepszym rozwiązaniem jest wykrycie faktu zgubienia danych i odpowiednie zareagowanie na takie zdarzenie. W tej części kursu nie będziemy się tym zajmować – do wykrywania i obsługi błędów (w różnych kontekstach) jeszcze wrócimy.
Timeout i blokowanie programu
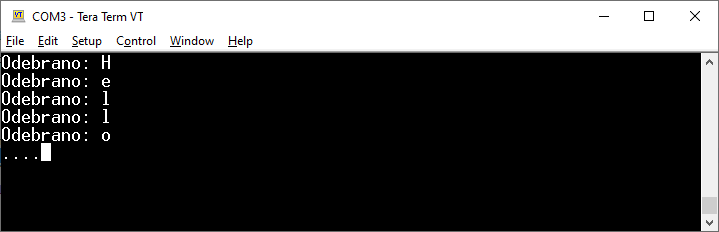
Poprzednio zastosowane rozwiązanie miało sporo wad. Pomijając problemy z gubieniem danych, wywołanie HAL_UART_Receive blokowało całkowicie wykonywanie programu. Spróbujmy wykorzystać parametr Timeout i za jego pomocą ograniczmy czekanie na otrzymanie danych. Nowy program może wyglądać tak jak poniżej (jest to zawartość pętli while). Sprawdzamy, czy odebraliśmy poprawne dane – jeśli tak, to odsyłamy odebrany bajt.
Tym razem czekamy na odebranie danych 2000 ms i jeśli nic nie otrzymamy, to wysyłamy kropkę jako ponaglenie dla nadawcy i informację, że program nadal działa i się nie zawiesił. Jak pamiętamy, printf buforuje wyjście, więc używamy funkcji fflush, aby program działał zgodnie z założeniami.
Efekt działania nowej wersji programu
Moglibyśmy pójść dalej i jako parametr timeout podać zero. Wówczas funkcja HAL_UART_Receive nie będzie czekać wcale – jeśli są jakieś dane gotowe do przetworzenia, to zwróci HAL_OK. Takie działanie jest podobne do funkcji Serial.available, którą znają użytkownicy np. Arduino UNO.
Odbieranie linii danych
W dotychczasowych programach odbieraliśmy pojedyncze znaki. Było to bardzo proste rozwiązanie, ale mocno nas ograniczało. Często wolelibyśmy zbierać dane do bufora i przetwarzać je po odebraniu całej linii. Zacznijmy więc od zadeklarowania bufora linii oraz napisania funkcji, która będzie dodawała dane do bufora. Oto cały nowy kod, który powinien trafić nad funkcję main, np. do bloku, który zaczyna się od komentarza USER CODE BEGIN 0 (mamy już tam naszą funkcję __io_putchar).
#define LINE_MAX_LENGTH 80
static char line_buffer[LINE_MAX_LENGTH + 1];
static uint32_t line_length;
void line_append(uint8_t value)
{
if (value == '\r' || value == '\n') {
// odebraliśmy znak końca linii
if (line_length > 0) {
// jeśli bufor nie jest pusty to dodajemy 0 na końcu linii
line_buffer[line_length] = '\0';
// przetwarzamy dane
printf("Otrzymano: %s\n", line_buffer);
// zaczynamy zbieranie danych od nowa
line_length = 0;
}
}
else {
if (line_length >= LINE_MAX_LENGTH) {
// za dużo danych, usuwamy wszystko co odebraliśmy dotychczas
line_length = 0;
}
// dopisujemy wartość do bufora
line_buffer[line_length++] = value;
}
}
Mamy tutaj nową definicję LINE_MAX_LENGTH, która określa maksymalną długość linii. Używamy jej do zadeklarowania tablicy, w której będziemy trzymać wszystkie znaki. Potrzebna jest też zmienna, dzięki której będziemy znać aktualną długość linii (liczbę znaków, które zostały wcześniej odebrane).
Podczas wywoływania funkcji będziemy do niej przekazywać najnowszy odebrany bajt. Zaczynamy więc od sprawdzenia, czy przypadkiem nie odebraliśmy znaku końca linii. Jeśli tak, to trzeba sprawdzić, czy w naszym buforze jest już jakiś komunikat (liczba bajtów jest większa od 0). Wcześniej w tym artykule wspominaliśmy już, że w języku C na końcu napisów znajduje się znak o kodzie „\0”, więc dodajemy go do naszej tablicy (i właśnie dlatego zadeklarowaliśmy, że ta tablica jest większa o 1 od maksymalnej spodziewanej długości linii). Następnie wysyłamy nasz komunikat za pomocą printf.
Z kolei jeśli odebraliśmy coś innego od znaku końca linii, to sprawdzamy, czy nasz bufor może jeszcze pomieścić kolejne dane, i zapisujemy odebrany bajt na najbliższej wolnej pozycji w buforze. Jak widać, dzięki temu, że wykorzystaliśmy printf, kod naszej funkcji line_append stał się zupełnie niezależny od biblioteki HAL, a nawet używanego mikrokontrolera. Jest to uniwersalny i bardzo uproszczony kod, który pozwala na przetwarzanie odbieranych znaków.
Teraz wystarczy w pętli while naszego programu dodać wywołanie tej nowej funkcji:
uint8_t value;
if (HAL_UART_Receive(&huart2, &value, 1, 0) == HAL_OK)
line_append(value);
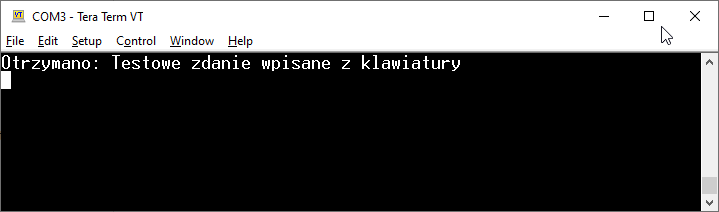
Jako timeout podajemy zero, więc funkcja nie będzie blokowała programu. Możemy uruchomić i przetestować nasz program. Wpisywane dane nie pojawiają się natychmiast na terminalu, zamiast tego są zbierane w buforze, a odpowiedź jest wysyłana po otrzymaniu znaku końca linii (klawisz Enter).
Efekt działania programu z nową funkcją buforującą
W związku z tym, że dopisywanie do bufora działa bardzo szybko, nasz program powinien zadziałać teraz poprawnie, nawet gdy wyślemy linijkę tekstu „Hello Forbot” za pomocą kopiuj-wklej. Oczywiście, jeśli danych będzie więcej, niż mieści się w buforze, to znów zgubimy część transmisji, ale i tak znacznie poprawiliśmy działanie tego mechanizmu.
Programy nie zawsze są bezbłędne
Wszyscy chcielibyśmy oczywiście pisać tylko bezbłędne programy, które działają od pierwszego do ostatniego uruchomienia. Niestety rzeczywistość nie zawsze bierze pod uwagę nasze życzenia i potrafi zrealizować zupełnie inne scenariusze, niż sobie wymarzymy. Zobaczmy, jak możemy sobie radzić z diagnozowaniem i naprawianiem błędów w napisanych przez nas programach.
Kilka akapitów wcześniej zobaczyliśmy, jak możemy odbierać linijkę danych. Spróbujmy napisać prosty program, który pozwoli na zdalne włączanie i wyłączanie diody. Użytkownik będzie wysyłał polecenie „włącz” lub „wyłącz”, a dioda będzie się zachowywała zgodnie z jego życzeniem.
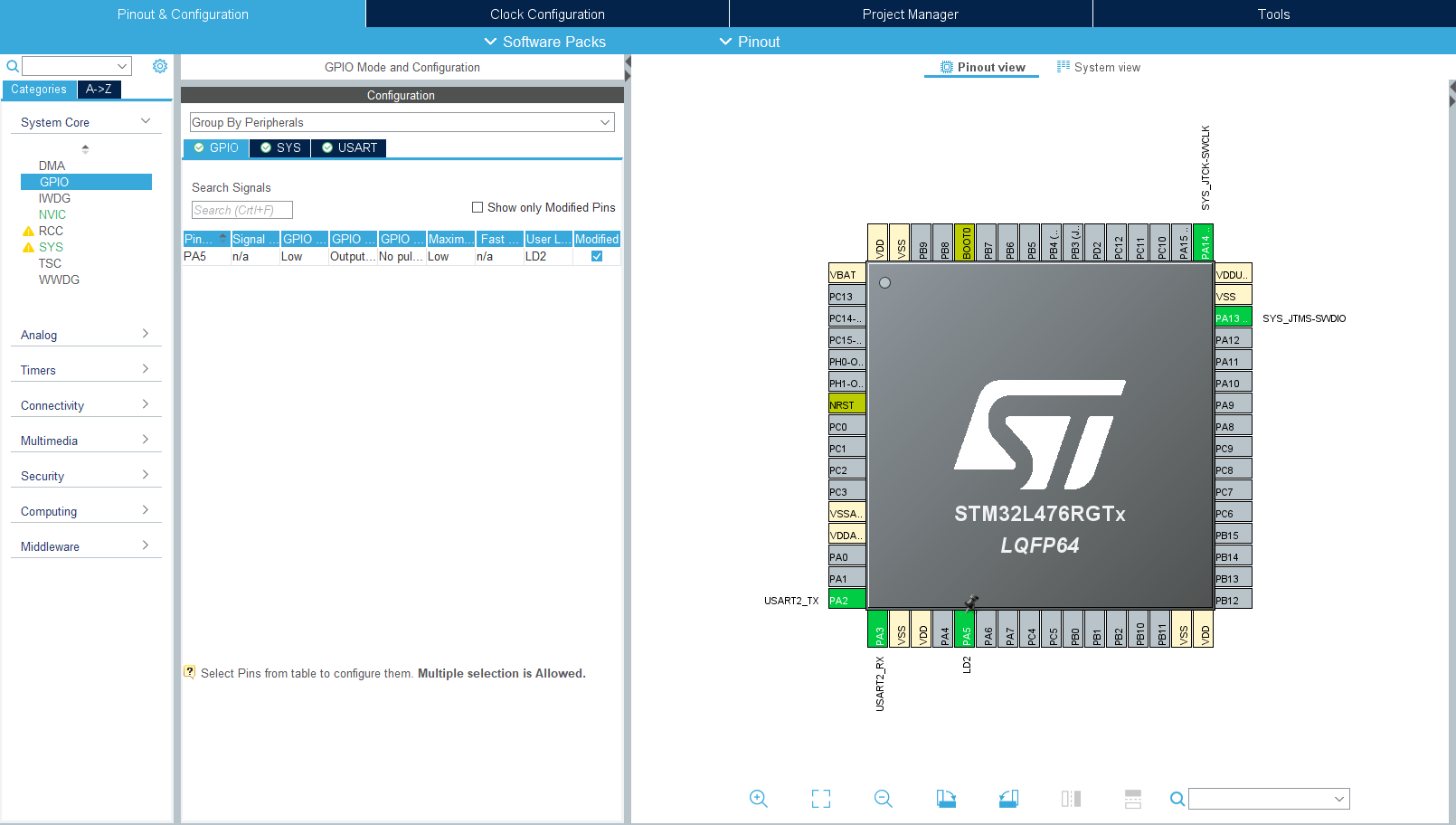
Program wydaje się banalnie prosty, nic nie może chyba pójść źle. Przystępujemy od razu do pracy i na początek przechodzimy do widoku CubeMX, gdzie dodajemy obsługę diody LD2 podłączonej do PA5.
Konfiguracja diody w CubeMX
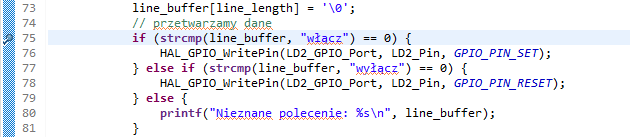
Generujemy szablon, a następnie wracamy do wcześniejszego przykładu, czyli do funkcji line_append. Poprzednio tylko odsyłaliśmy otrzymane dane, teraz chcemy sprawdzać, jakie otrzymaliśmy polecenie, i odpowiednio reagować. Kod takiego sprawdzenia jest bardzo prosty:
Porównujemy otrzymaną linijkę tekstu najpierw z napisem „włącz”. Jeśli tak jest, to funkcja strcmp zwraca zero, a program włącza diodę. Podobnie dla napisu „wyłącz”, z tym że tu dioda jest wyłączana.
Cały kod nowej funkcji będzie zatem następujący:
#define LINE_MAX_LENGTH 80
static char line_buffer[LINE_MAX_LENGTH + 1];
static uint32_t line_length;
void line_append(uint8_t value)
{
if (value == '\r' || value == '\n') {
// odebraliśmy znak końca linii
if (line_length > 0) {
// dodajemy 0 na końcu linii
line_buffer[line_length] = '\0';
// przetwarzamy dane
if (strcmp(line_buffer, "włącz") == 0) {
HAL_GPIO_WritePin(LD2_GPIO_Port, LD2_Pin, GPIO_PIN_SET);
} else if (strcmp(line_buffer, "wyłącz") == 0) {
HAL_GPIO_WritePin(LD2_GPIO_Port, LD2_Pin, GPIO_PIN_RESET);
} else {
printf("Nieznane polecenie: %s\n", line_buffer);
}
// zaczynamy zbieranie danych od nowa
line_length = 0;
}
}
else {
if (line_length >= LINE_MAX_LENGTH) {
// za dużo danych, usuwamy wszystko co odebraliśmy dotychczas
line_length = 0;
}
// dopisujemy wartość do bufora
line_buffer[line_length++] = value;
}
}
I jeszcze pętla główna, w której nie dzieje się zbyt wiele:
/* USER CODE BEGIN WHILE */
while (1)
{
uint8_t value;
if (HAL_UART_Receive(&huart2, &value, 1, 0) == HAL_OK)
line_append(value);
/* USER CODE END WHILE */
Kod mamy gotowy, czas go więc przetestować, ale zanim to zrobimy, przechodzimy do ustawień Tera Term: Setup > Font i ustawiamy czcionkę na pewno na Consolas (to ważne dla tego ćwiczenia). Teraz uruchamiamy kod i sprawdzamy, czy działa. Program niby działa, ale nie tak, jak chcieliśmy.
Poprawne teksty, które nie są rozpoznane jako poprawne polecenia
Pierwsze prawdziwe wykorzystanie debuggera
Z uruchamianiem debuggera nie powinniśmy mieć problemu, bo od początku kursu używaliśmy go do wgrywania programu do pamięci mikrokontrolera. Uruchamiamy więc program tak jak zwykle (wybierając z menu Run > Debug) albo klikając na ikonkę z robakiem.
Środowisko STM32CubeIDE dodaje automatycznie pułapkę (ang. breakpoint) na początku funkcji main. Dlatego nasz program zatrzymuje się w tym miejscu i widzimy podświetloną linię kodu, która ma być wykonana jako następna – w naszym przykładzie jest to HAL_Init. Zanim przejdziemy dalej, małe przypomnienie działania funkcji debuggera, którego skróty widoczne są na pasku narzędziowym:
Ikony sterujące debuggerem
Patrząc od lewej, są to:
Terminate and Relaunch – pozwala na przerwanie wykonywania programu, zresetowanie mikrokontrolera i rozpoczęcie debugowania od początku.
Resume (F8) – wznawia wykonywanie programu do następnej pułapki lub ręcznego zatrzymania.
Suspend – pozwala na ręczne zatrzymanie działania programu.
Terminate (Ctrl + F2) – przerwanie debugowania i powrót do edycji kodu.
Disconnect – rozłącza połączenie z debuggerem.
Step Into (F5) – wykonuje kolejny krok programu, wchodzi do wnętrza funkcji.
Step Over (F6) – wykonuje kolejną linijkę kodu, wykonuje całą funkcję na raz.
Step Return (F7) – kontynuuje wykonywanie programu aż do końca aktualnej funkcji.
Instruction Stepping Mode – pozwala na wykonywanie kodu po jednej instrukcji asemblera.
Instrukcję Suspend i Terminate już znamy, teraz sprawdzimy, jak działa Step Into i Step Over. Najpierw użyjemy drugiej z nich. Mając zaznaczoną pierwszą linijkę kodu funkcji main, czyli wywołanie HAL_Init, naciskamy F6 (lub odpowiednią ikonkę). Program wykonuje cały kod z funkcji HAL_Init i zatrzymuje się przy następnej linii, którą jest wywołanie SystemClock_Config.
Zatrzymanie działania programu na kolejnej funkcji
Teraz użyjemy Step Into – naciskamy F5 i nasz program przechodzi do pierwszej linijki kodu funkcji SystemClock_Config. Jak widzimy, obie funkcje debuggera są bardzo proste w użyciu, pozwalają na wykonywanie programu dosłownie krok po kroku. To cenna funkcja, ponieważ umożliwia zobaczenie, jak nasz program działa. Tutaj trzeba podkreślić, że to nie jest żadna symulacja – sprawdzamy, jak program działa na naszym mikrokontrolerze (podglądamy to dosłownie na żywo).
Program zatrzymał się po wejściu do funkcji
Podczas normalnej pracy mikrokontroler wykonuje te wszystkie operacje tak szybko, że człowiek nie jest w stanie tego zarejestrować. Wykorzystujemy więc debugger do tego, aby dosłownie zatrzymać układ – dzięki temu możemy podejrzeć, co się dzieje wewnątrz mikrokontrolera.
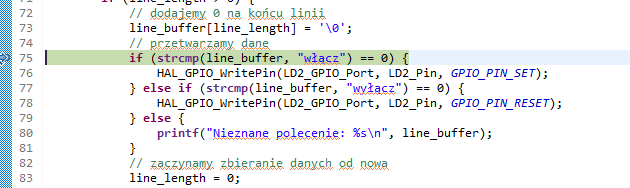
Moglibyśmy teraz tak linijka po linijce przechodzić przez program, ale to zajęłoby mnóstwo czasu, bo przecież musimy wysłać polecenie „włącz” przez port szeregowy. Ustawmy więc pułapkę w funkcji line_append, i to najlepiej w miejscu, gdzie nasz napis został już odebrany. Przewijamy kod źródłowy do funkcji line_append i odnajdujemy linijkę z pierwszym wywołaniem funkcji strcmp.
Następnie używamy kombinacji klawiszy Ctrl + Shift + B albo dwukrotnie klikamy pasek po lewej stronie od numeru linii – nowy breakpoint powinien zostać zaznaczony niebieską kropką.
Ręcznie dodany breakpoint
Teraz możemy kontynuować wykonywanie programu za pomocą przycisku Resume. Przechodzimy do Tera Term i wpisujemy polecenie „włącz”. Po naciśnięciu klawisza Enter program powinien zatrzymać się na zastawionej pułapce, co zostanie zasygnalizowane podświetleniem odpowiedniej linijki.
Zatrzymanie programu na wskazanej linii
Możemy teraz sprawdzić, jak zachowuje się nasz program, wykonując kod krok po kroku. Naciskamy F5 i widzimy, że kod przeskakuje od razu do drugiego porównania, a jak naciśniemy F5 kolejny raz, to do ostatniej instrukcji, czyli else. Okazuje się więc, że porównanie odebranego napisu za pomocą strcmp nie zwraca zera, tak jak oczekiwaliśmy. Musimy teraz ustalić dlaczego, zostawiamy więc program, który jest zatrzymany w tym miejscu, i przechodzimy do dalszej analizy.
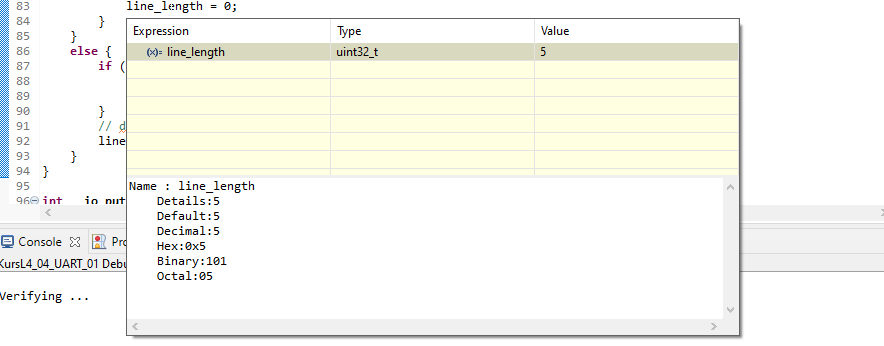
Debugger pozwala nie tylko na zatrzymywanie działania programu, ale również na podglądanie zawartości zmiennych. Najprościej jest po prostu zatrzymać kursor nad wybraną zmienną i chwilę zaczekać. Zobaczmy, jaką wartość ma zmienna line_length. Najeżdżamy na nią w dowolnym miejscu kodu, a w małym okienku zobaczymy, jaka jest jej wartość (w chwili, gdy program jest zatrzymany).
Podgląd aktualnej zawartości zmiennej
Jak widzimy, długość napisu to pięć znaków, czyli wygląda poprawnie. W takim razie możemy sprawdzić, jaka jest wartość samego bufora z danymi, czyli tablicy line_buffer.
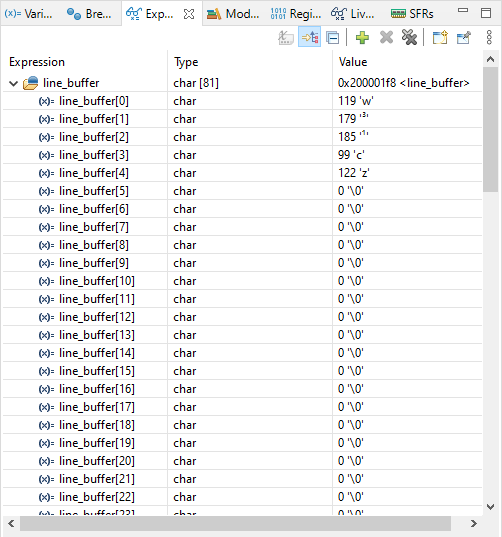
Tym razem użyjemy jednak nieco innej metody. Zaznaczamy tablicę line_buffer, a następnie klikamy prawym klawiszem myszy i z menu wybieramy opcję Add Watch Expression. Po jej wybraniu nasza zmienna zostanie dodana do listy obserwowanych wartości (w okienku o nazwie Expressions).
Podgląd zawartości tablicy w pamięci mikrokontrolera
Zmiany zawartości zmiennych wprowadzone w powyższym oknie debuggera zostaną automatycznie wprowadzone również do pamięci mikrokontrolera!
Wróćmy jednak do analizy naszego przykładu – to, co zwraca uwagę, to kodowanie polskich liter. Jak widzimy, pierwszy znak się zgadza, kod 119 odpowiada literze W. Natomiast kolejny znak ma kod 179 i STM32CubeIDE nie bardzo umie go wyświetlić. Wygląda to jak „typowy” błąd z kodowaniem znaków.
Okazuje się, że niestety standardów kodowania polskich znaków jest mnóstwo i nie są one ze sobą zgodne. Litera Ł została zakodowana jako 179, a następna po niej, czyli litera Ą, jako 185. Jeśli prześledzimy kodowania opisane na stronie, zobaczymy, że odpowiada to kodowaniu Windows-1250.
Czyli terminal Tera Term wysyła do nas napis „włącz” zakodowany w standardzie Windowsa. Okazuje się jednak, że STM32CuebIDE, a więc i nasz program, używa UTF-8 (można to sprawdzić w menu Project > Properties > Resource > Text file encoding).
Jak naprawić problem z kodowaniem znaków?
Z tym problemem możemy poradzić sobie na kilka sposobów. Najprościej i najlepiej po prostu unikać polskich znaków. Możemy zmienić polecenia na „wlacz” i „wylacz” albo – nawet lepiej – na „on” i „off”. Inna możliwość to zmiana terminala – np. popularny PuTTy koduje wysyłane dane właśnie w UTF-8. Można również zmienić konfigurację STM32CubeIDE, ale to jest najgorsza możliwa opcja, bo może to wygenerować różne konflikty z innymi programami.
Każdy może rozwiązać ten problem w wybrany przez siebie sposób (najlepiej zamiana treści poleceń na on/off). Celem tego przykładu było głównie szybkie pokazanie tego, jak cennym narzędziem jest debugger oraz jak wiele czasu może on zaoszczędzić, gdy szukamy błędów w programie.
W kolejnych częściach kursu jeszcze wielokrotnie wrócimy do tego narzędzia.
Na koniec pozostaje wyjaśnić, dlaczego podczas tego ćwiczenia zmienialiśmy czcionkę Tera Term. Otóż domyślnie program ten korzysta z czcionki, która nie obsługuje polskich znaków. W związku z tym w trakcie testów tego programu na ekranie byłyby widoczne dziwne znaczki (jak poniżej).
Błędne działanie Tera Term przy innej czcionce
Takie coś od razu podpowiadałoby większości czytelników, że pewnie chodzi tutaj o coś z kodowaniem znaków (chociaż sama czcionka nie ma wpływu na działanie tego kodu – to tylko przypadek).
Tym razem zależało nam, aby dojść do tego za pomocą debuggera, bo równie dobrze moglibyśmy testować ten program w takiej wersji, która nie wysyłałaby żadnych danych do PC. Wtedy, korzystając tylko z Tera Term, nie mielibyśmy pojęcia, czy dane są odbierane i czy są poprawne. Podgląd danych w debuggerze działałby jednak oczywiście nadal tak samo.
Zadanie domowe
Popraw program z ostatniego ćwiczenia w taki sposób, aby działał poprawnie. Zmień w tym celu komendy, które są rozpoznawane przez mikrokontroler, na takie, które nie mają polskich znaków.
Napisz program, który po naciśnięciu przycisku na płytce Nucleo zwiększa wartość zmiennej, a następnie odsyła ją do komputera przez UART.
Rozbuduj program z zadania nr 2 w taki sposób, aby po 10 naciśnięciach przycisku włączała się dioda świecąca. Spróbuj wykorzystać debugger do tego, aby podejrzeć i zmienić zawartość zmiennej, która jest licznikiem. Na przykład zatrzymaj program po 3 naciśnięciach przycisku, podejrzyj wartość zmiennej, spróbuj ją podmienić na 9 i wznów pracę programu. Sprawdź, czy dioda włączy się po kolejnym naciśnięciu przycisku.
Podsumowanie – co powinieneś zapamiętać?
Po pierwsze, powinieneś już wiedzieć, jak (w najprostszej możliwej wersji) korzystać z UART-a, aby odbierać i wysyłać dane. Ręczne dodawanie breakpointów i podglądanie zawartości zmiennych też nie powinno stanowić dla Ciebie problemu. Nie musisz z pamięci pisać funkcji, dzięki którym można korzystać z printf, ale przynajmniej powinieneś wiedzieć, gdzie ich szukać.
Co o tym sądzisz? Oceń ten wpis:
Średnia ocena 4.9 / 5. Głosów łącznie: 113
Nikt jeszcze nie głosował, bądź pierwszy!
Artykuł nie był pomocny? Jak możemy go poprawić? Wpisz swoje sugestie poniżej. Jeśli masz pytanie to zadaj je w komentarzu - ten formularz jest anonimowy, nie będziemy mogli Ci odpowiedzieć!
W kolejnej części kursu zajmiemy się taktowaniem układu. Niby prosta sprawa, bo takie Arduino UNO ma kwarc 16 MHz i koniec tematu. Jednak nie w tym przypadku. Mikrokontrolery z rodziny STM32L4 to rozbudowane układy, które mają potężne możliwości. Zapoznamy się w praktyce z dostępnymi opcjami taktowania, porównamy dokładność różnych sygnałów zegarowych i uruchomimy RTC.
Główny autor kursu: Piotr Bugalski Współautor: Damian Szymański, ilustracje: Piotr Adamczyk Oficjalnym partnerem tego kursu jest firma STMicroelectronics Zakaz kopiowania treści kursów oraz grafik bez zgody FORBOT.pl
Dołącz do 30 tysięcy osób, które otrzymują powiadomienia o nowych artykułach! Zapisz się, a otrzymasz PDF-y ze ściągami (m.in. na temat mocy, tranzystorów, diod i schematów) oraz listę inspirujących DIY na bazie Arduino i Raspberry Pi.
Dołącz do 30 tysięcy osób, które otrzymują powiadomienia o nowych artykułach! Zapisz się, a otrzymasz PDF-y ze ściągami (m.in. na temat mocy, tranzystorów, diod i schematów) oraz listę inspirujących DIY z Arduino i RPi.




































{kind=link}
{kind=link}
Trwa ładowanie komentarzy...