Problemy z komunikacją przez UART, zbyt późna reakcja mikrokontrolera na sygnał z czujnika lub na naciśnięcie przycisku – to błędy, które można naprawić za pomocą przerwań sprzętowych.
W niniejszej części kursu STM32L4 wykorzystamy przerwania do tego, aby usprawnić wcześniejsze programy, zajmiemy się też obsługą błędów.
Temat przerwań pojawił się w kursie STM32L4 już kilka razy – np. podczas omawiania watchdoga lub odczytywania wskazań licznika systemowego (za pomocą HAL_GetTick). Jednak nie zajmowaliśmy się tym zbyt dokładnie. W trakcie wykonywania ćwiczeń z tej części kursu dowiesz się, czym są przerwania sprzętowe i jak są obsługiwane przez mikrokontroler, czym są priorytety przerwań oraz jak można wykrywać błędy (np. wynikające z dzielenia przez 0 lub z błędów w komunikacji).
Czym są przerwania?
Za chwilę omówimy temat przerwań sprzętowych od strony technicznej. Zacznijmy jednak od prostego wytłumaczenia dla osób, które nigdy nie korzystały jeszcze z tego mechanizmu. Przerwania najprościej wytłumaczyć przez analogię z telefonem. Wyobraźmy sobie wykład, podczas którego bardzo czekamy na ważną dla nas wiadomość. Telefon musimy mieć wyciszony, więc nie pozostaje nam nic innego, jak co chwilę nerwowo spoglądać na ekran i sprawdzać, czy upragniona wiadomość wreszcie nadeszła.
Takie ciągłe „sprawdzanie w pętli”, czy przyszła do nas wiadomość, w programowaniu określamy jako polling – jest to prosty mechanizm, który znaleźć można w wielu programach.
Zabawa takim wyciszonym telefonem może być męcząca i bywa nieefektywna. Ciągle sprawdzamy, czy coś przyszło, zamiast słuchać wykładu, a jak w końcu przyjdzie wyczekiwana wiadomość, to i tak minie sporo czasu, zanim ją odczytamy, bo raczej nie trafimy idealnie w moment jej odebrania (chyba że skupimy swoją uwagę w 100% na patrzeniu na telefon).
Ciągłe wpatrywanie się w ekran telefonu w oczekiwaniu na wiadomość można porównać do tzw. pollingu
Z kolei przerwania odpowiadają włączeniu dźwięku w telefonie, który natychmiast nas powiadamia o odebraniu wiadomości. Nie musimy ciągle sprawdzać, czy coś przyszło, bo dostaniemy wtedy wyraźny sygnał. W przypadku mikrokontrolerów sygnalizacja dźwiękiem nie jest jednak najlepszym pomysłem, dlatego przerwania są obsługiwane jako procedury. Gdy wystąpi interesujące nas zdarzenie (np. odebranie wiadomości), program, który jest aktualnie wykonywany, zostanie na chwilę zawieszony, jego stan będzie zapisany, a procesor przejdzie do specjalnej funkcji zwanej procedurą obsługi przerwania.
Po wykonaniu instrukcji powiązanych z konkretnym przerwaniem mikrokontroler wznowi wykonywanie głównego programu (dokładnie w tym miejscu, gdzie nastąpiło zatrzymanie). Jeśli procedura obsługi przerwania będzie wykonywana szybko, to nawet nie zauważymy zatrzymania głównego programu.
Gotowe zestawy do kursów Forbota
Komplet elementów Gwarancja pomocy Wysyłka w 24h
Zamów zestaw elementów i wykonaj ćwiczenia z tego kursu! W komplecie płytka NUCLEO-L476RG oraz m.in. wyświetlacz graficzny, joystick, enkoder, czujniki (światła, temperatury, wysokości, odległości), pilot IR i wiele innych.
Masz już zestaw? Zarejestruj go wykorzystując dołączony do niego kod. Szczegóły »
Obsługa przerwań sprzętowych
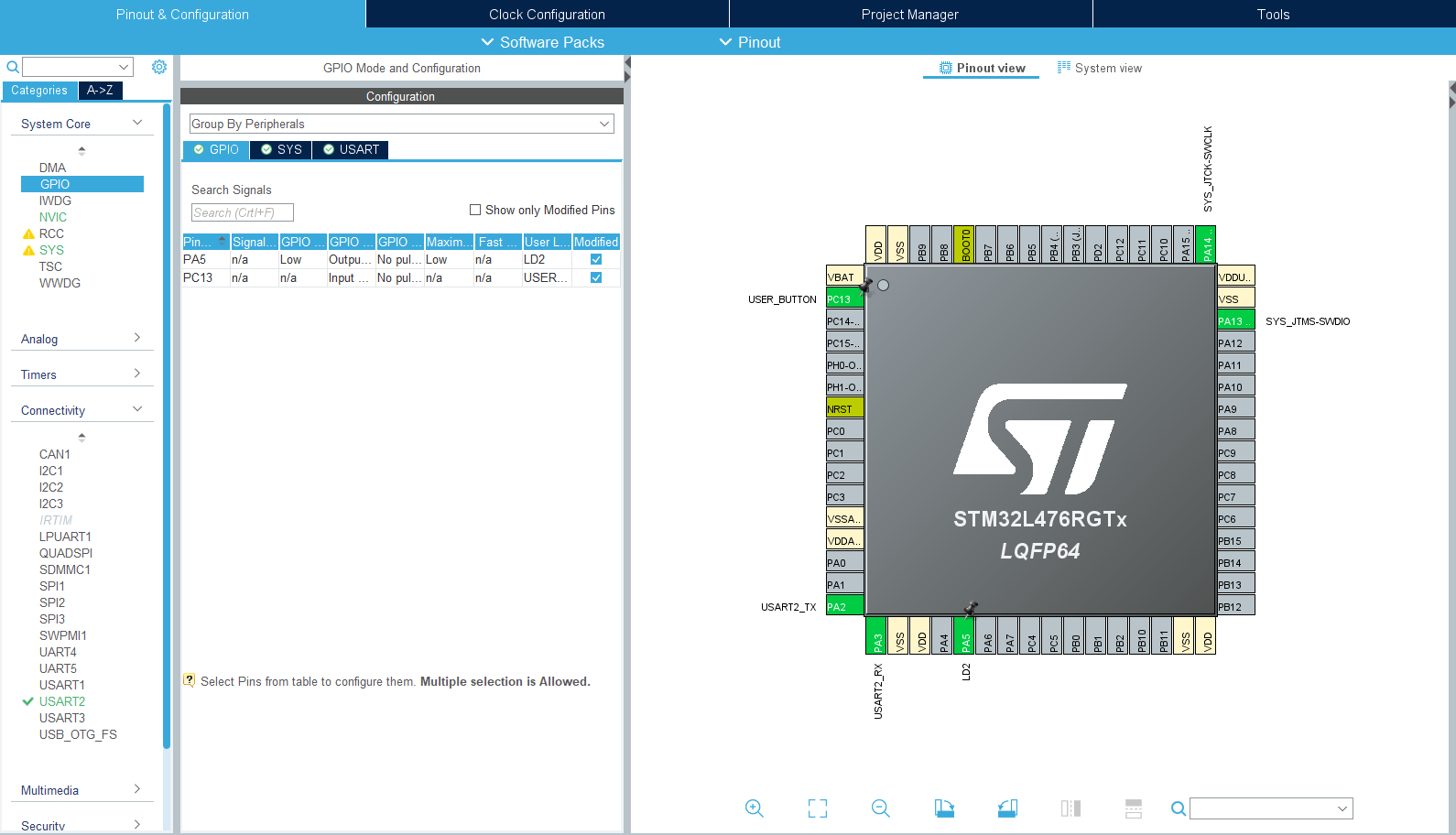
Temat przerwań najłatwiej zrozumieć w praktyce, więc od razu zaczynamy od standardowego projektu: STM32L476RG, który pracuje z częstotliwością 80 MHz. Uruchamiamy też debugger, USART2 w trybie asynchronicznym, pin PA5 konfigurujemy jako wyjście LD2, a PC13 jako wejście USER_BUTTON.
Wstępna, standardowa konfiguracja mikrokontrolera
Od razu dodajemy w programie przekierowanie komunikatów wysyłanych przez printf – tak samo, jak robiliśmy to w części o komunikacji STM32L4 przez UART. Wystarczy dodanie pliku nagłówkowego:
#include <stdio.h>
oraz kod zbliżony do poniższego:
int __io_putchar(int ch)
{
if (ch == '\n') {
__io_putchar('\r');
}
HAL_UART_Transmit(&huart2, (uint8_t*)&ch, 1, HAL_MAX_DELAY);
return 1;
}
Teraz możemy napisać prosty program, który będzie wysyłał do komputera aktualną wartość licznika systemowego (milisekundy od startu programu, informację tę zwraca funkcja HAL_GetTick).
Jeśli chcemy wykorzystać funkcję printf do wyświetlania „dużych liczb”, to zamiast popularnego „%d” należy wykorzystać zapis „%lu”, co będzie odpowiadało zmiennej typu long (bez znaku).
/* USER CODE BEGIN WHILE */
while (1)
{
printf("systick = %lu\n", HAL_GetTick());
/* USER CODE END WHILE */
/* USER CODE BEGIN 3 */
}
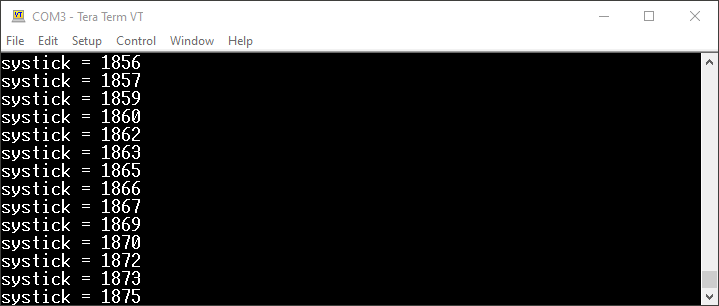
Uruchomienie takiego kodu sprawi, że w oknie terminala zobaczymy ciąg danych, które wysyłane są do nas co około 1 ms – czasami widoczne są jednak przeskoki o np. 2 ms. W programie nie ma żadnych opóźnień, które ograniczałyby częstotliwość wysyłania komunikatów. Wynika z tego, że wysyłanie tych informacji zajmuje (jak na mikrokontroler) bardzo dużo czasu.
Przykładowe dane odebrane przez UART
Dla nas milisekunda to moment, ale dla mikrokontrolera STM32, który pracuje z częstotliwością 80 MHz, to prawie wieczność. Warto więc zastanowić się chwilę nad przyczyną takiej sytuacji. Przyjrzyjmy się dokładniej działaniu licznika systemowego – zacznijmy od odnalezienia wnętrza funkcji HAL_GetTick (można ją znaleźć w pliku Drivers\STM32L4xx_HAL_Driver\Src\stm32l4xx_hal.c).
/**
* @brief Provide a tick value in millisecond.
* @note This function is declared as __weak to be overwritten in case of other
* implementations in user file.
* @retval tick value
*/
__weak uint32_t HAL_GetTick(void)
{
return uwTick;
}
Jak widać, program nie zwiększa wartości uwTick, a wywołanie HAL_GetTick tylko zwraca wartość tej zmiennej. Możemy się więc domyślać, że jej wartość musi być zmieniana w innym miejscu (i pewnie ma to związek z przerwaniami). Właściwy kod zwiększający wartość zmiennej uwTick znajdziemy w funkcji HAL_IncTick, którą można podejrzeć w tym samym pliku.
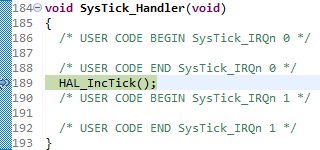
Z kolei ta funkcja wywoływana jest przez jeszcze kolejną, tym razem o nazwie SysTick_Handler. Ten fragment kodu znajdziemy z kolei w pliku Core\Src\stm32l4xx_it.c:
void SysTick_Handler(void)
{
/* USER CODE BEGIN SysTick_IRQn 0 */
/* USER CODE END SysTick_IRQn 0 */
HAL_IncTick();
/* USER CODE BEGIN SysTick_IRQn 1 */
/* USER CODE END SysTick_IRQn 1 */
}
Potrafimy już korzystać z debuggera, więc możemy bardzo łatwo sprawdzić, czy ta funkcja jest używana. W tym celu ustawiamy w jej wnętrzu pułapkę (ang. breakpoint), a następnie uruchamiamy program pod kontrolą debuggera. Po chwili program zatrzyma się w odpowiednim miejscu.
Zatrzymanie programu w funkcji
Mamy już konkretny dowód na to, że funkcja SysTick_Handler jest używana – szczegóły jej wywołania omówimy za chwilę. Na razie wystarczy nam informacja, że jest wywoływana co 1 ms niezależnie od działania programu, który w teorii tylko wysyła informacje przez UART.
Miganie diodą w przerwaniu
Aby upewnić się, że rozumiemy mechanizm działania przerwań, spróbujmy dodać nasz fragment kodu do procedury SysTick_Handler. Jak zwykle dobrym ćwiczeniem będzie tu miganie diodą świecącą.
To przerwanie jest wywoływane co 1 ms, więc gdybyśmy zmieniali stan diody za każdym razem, wówczas nawet nie byłoby widać migania (działoby się to zbyt szybko dla ludzkiego oka). Musimy zatem dodać programowy licznik i zmieniać stan diody nieco rzadziej. Na przykład będziemy liczyli do 100, czyli stan diody będzie zmieniany co 100 ms.
Nasz licznik programowo robi dokładnie to samo co znane nam, z części o zegarach, preskalery, czyli dzieli częstotliwość 1 kHz przez 100. Poniższy kod zadziała poprawnie, bo zmienna clk_div została zadeklarowana jako „static”, dzięki czemu jej wartość nie jest tracona po wykonaniu zawartości funkcji.
void SysTick_Handler(void)
{
/* USER CODE BEGIN SysTick_IRQn 0 */
static int clk_div;
clk_div++;
if (clk_div >= 100) {
HAL_GPIO_TogglePin(LD2_GPIO_Port, LD2_Pin);
clk_div = 0;
}
/* USER CODE END SysTick_IRQn 0 */
HAL_IncTick();
/* USER CODE BEGIN SysTick_IRQn 1 */
/* USER CODE END SysTick_IRQn 1 */
}
Usuwamy wcześniej dodany breakpoint i kompilujemy program. Po uruchomieniu najnowszej wersji kodu powinniśmy zobaczyć, że dioda miga, chociaż program główny jest zajęty zupełnie czymś innym. Przy okazji napisaliśmy kod testujący ogólne działanie przerwań i będziemy z niego korzystać na dalszym etapie tej części kursu.
Efekt działania najnowszego programu
Jak działają przerwania?
Nazewnictwo związane z przerwaniami jest czasem mylące, warto więc poświęcić chwilę na opanowanie podstawowych pojęć. Czytając dokumentację producenta, na pewno natrafimy na:
zdarzenie (ang. event),
przerwanie (ang. interrupt),
wyjątek (ang. exception).
Czym są zdarzenia?
Zdarzeniem nazywamy wystąpienie określonego stanu w module peryferyjnym, np. wykrycie zmiany sygnału wejściowego po naciśnięciu przycisku lub odebranie danych przez UART. Po wystąpieniu zdarzenia może zostać wygenerowane przerwanie, ale może ono być też obsługiwane przez sprzęt.
Przykładowo po wykryciu zmiany sygnału wejściowego może nastąpić odczyt z czujnika w pełni sprzętowo, bez konieczności wykonywania dedykowanego kodu.
Czym są przerwania i wyjątki?
Przerwanie powoduje zatrzymanie wykonywania programu i przejście do specjalnej procedury obsługi danego przerwania. Procedurę taką nazywa się ISR (ang. interrupt service routine). Po jej zakończeniu kontynuowane jest wykonywanie kodu programu głównego.
Przerwania są jednym z rodzajów wyjątków. Są generowane w odpowiedzi na sygnały z modułów peryferyjnych, mają więc charakter asynchroniczny. Pozostałe wyjątki mogą być również synchroniczne i pojawiać się w reakcji na zdarzenia występujące w samym mikrokontrolerze, jak np. obsługa pułapki debuggera, błąd adresowania pamięci lub dzielenie przez zero. Zarówno przerwania, jak i wyjątki są obsługiwane w ten sam sposób.
Wyjątki sprzętowe, o których mowa w tym przypadku, nie mają nic wspólnego z wyjątkami znanymi z niektórych języków programowania, np. C++.
Procedury obsługi przerwań
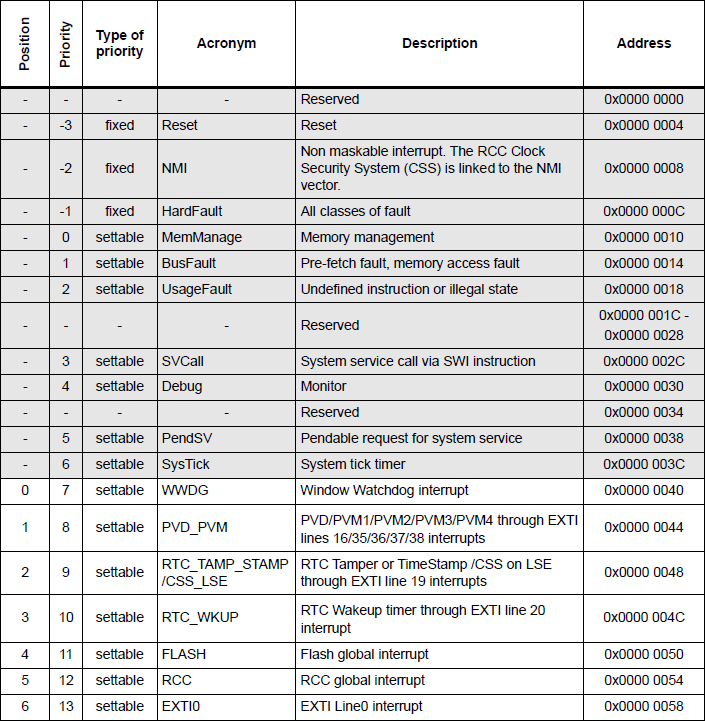
Lista wszystkich przerwań (a właściwie wyjątków) obsługiwanych przez STM32L476RG jest dostępna w jego dokumentacji (poniżej widoczny jest tylko fragment listy).
Tabela nr 57 z dokumentacji STM32L476RG
Wbrew pozorom nie ma w tym nic skomplikowanego, jest to po prostu lista 82 pozycji, które są niejako zaszyte w sprzętowej implementacji tego mikrokontrolera. Na przykład znajdziemy tam pozycję, która ma priorytet 6 i adres 0x0000 003C – jest to przerwanie SysTick, które właśnie testowaliśmy.
Od strony programistycznej wektor obsługi przerwań ma postać tablicy wskaźników do funkcji, a same funkcje są najzwyklejszymi funkcjami języka C. Tablica ta znajduje się w pliku startup_stm32l476rgtx.s, który znajdziemy w Core\Startup. Oto fragment tego kodu:
/******************************************************************************
*
* The minimal vector table for a Cortex-M4. Note that the proper constructs
* must be placed on this to ensure that it ends up at physical address
* 0x0000.0000.
*
******************************************************************************/
.section .isr_vector,"a",%progbits
.type g_pfnVectors, %object
.size g_pfnVectors, .-g_pfnVectors
g_pfnVectors:
.word _estack
.word Reset_Handler
.word NMI_Handler
.word HardFault_Handler
.word MemManage_Handler
.word BusFault_Handler
.word UsageFault_Handler
.word 0
.word 0
.word 0
.word 0
.word SVC_Handler
.word DebugMon_Handler
.word 0
.word PendSV_Handler
.word SysTick_Handler
.word WWDG_IRQHandler
.word PVD_PVM_IRQHandler
.word TAMP_STAMP_IRQHandler
.word RTC_WKUP_IRQHandler
.word FLASH_IRQHandler
.word RCC_IRQHandler
.word EXTI0_IRQHandler
.word EXTI1_IRQHandler
Kod został napisany w asemblerze, ale nie powinniśmy się tym zrażać. Widzimy w nim po prostu tablicę o nazwie g_pfnVectors, której kolejne pozycje (poza pierwszą) są nazwami funkcji wywoływanymi w momencie wystąpienia przerwania. To tutaj znajdziemy odwołanie do funkcji SysTick_Handler. Jej nazwa nie ma w sobie nic magicznego, ważna jest tylko pozycja w tablicy g_pfnVectors. Jeśli jej indeks odpowiada przerwaniu od SysTick, to zostanie ona wywołana co 1 ms.
Obsługa błędów
Przy okazji warto zapoznać się z zawartością pliku stm32l4xx_it.c, który znajdziemy w Core\Src. Jest to plik, w którym CubeMX umieszcza procedury obsługi przerwań. Znajdziemy tam znaną nam funkcję obsługi przerwania od SysTick, ale są tam również procedury obsługi błędów, np. HardFault_Handler, MemManage_Handler i innych.
Domyślnie ich kod to pusta pętla while(1), więc jeśli taki błąd pojawi się w naszym programie, to możemy nieoczekiwanie znaleźć się właśnie w tym miejscu i zostać w nim na zawsze.
Żeby przekonać się, jak taka obsługa błędów wygląda, wystarczy, że np. przed pętlą while dodamy:
int x, y;
x = 0;
y = 5 / x;
Jak łatwo się domyślić, nasz program wykona dzielenie przez zero, czego bardzo nie lubią matematycy (mikrokontrolery również). Jeśli uruchomimy ten kod za pomocą debuggera, to układ zatrzyma się po wejściu do funkcji odpowiedzialnej za obsługę takich błędów.
Zatrzymanie programu po wykryciu błędu
Gdybyśmy uruchamiali program bez debuggera, a pojawiłby się wyjątek HardFault, to program by się zawiesił, co nie jest dobrą metodą obsługi tego typu sytuacji. Uratować mógłby nas tylko watchdog, który zresetowałby układ (chociaż w tym konkretnym przypadku po resecie znów wykonałoby się błędne dzielenie). Trzeba więc pamiętać, że zanim udostępnimy komukolwiek nasze urządzenie, to warto zadbać o poprawną obsługę błędów.
Ciekawostka dla zaawansowanych: dzielnie przez zero generuje wyjątek HardFault tylko, jeśli uruchamiamy program za pomocą debuggera. Ten sam kod uruchomiony bez debuggera zwróci zero (wynika to z faktu, że debugger zmienia zawartość rejestru SCB->CCR).
Dzielenie przez zero było tylko małą odskocznią, więc przed przejściem dalej usuwamy z projektu ten fragment kodu – nie będzie już nam potrzebny.
Przerwania od przycisku
Wiemy już mniej więcej, jak od strony sprzętowej działa obsługa przerwań: gdy mikrokontroler wykryje odpowiednie zdarzenie, układ zatrzymuje wykonywanie aktualnego programu, odczytuje z tablicy g_pfnVectors adres funkcji obsługi przerwania i zaczyna wykonywać operacje, które są w jej wnętrzu. Po zakończeniu obsługi przerwania układ wraca do programu głównego i kontynuuje jego działanie.
Jeśli kod jest napisany poprawnie, to obsługa przerwania powinna być błyskawiczna, dzięki czemu nie zauważymy tego, że główny program został na chwilę przerwany.
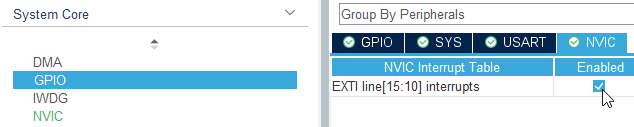
Widzieliśmy już, jak układ radzi sobie z przerwaniami pochodzącymi od zegara systemowego, wiemy też, jak wygląda obsługa wyjątku spowodowanego błędem w kodzie. Pora przetestować, jak działa obsługa przerwań pochodzących z innych modułów mikrokontrolera. Wracamy do CubeMX, wybieramy pin PC13 i zmieniamy funkcję z GPIO_Input na GPIO_EXTI13 (skrót od GPIO external interrupt 13).
CubeMX automatycznie zmieni nazwę przypisaną do pinu na domyślną, więc musimy do niego raz jeszcze przypisać ręcznie naszą etykietę „USER_BUTTON”.
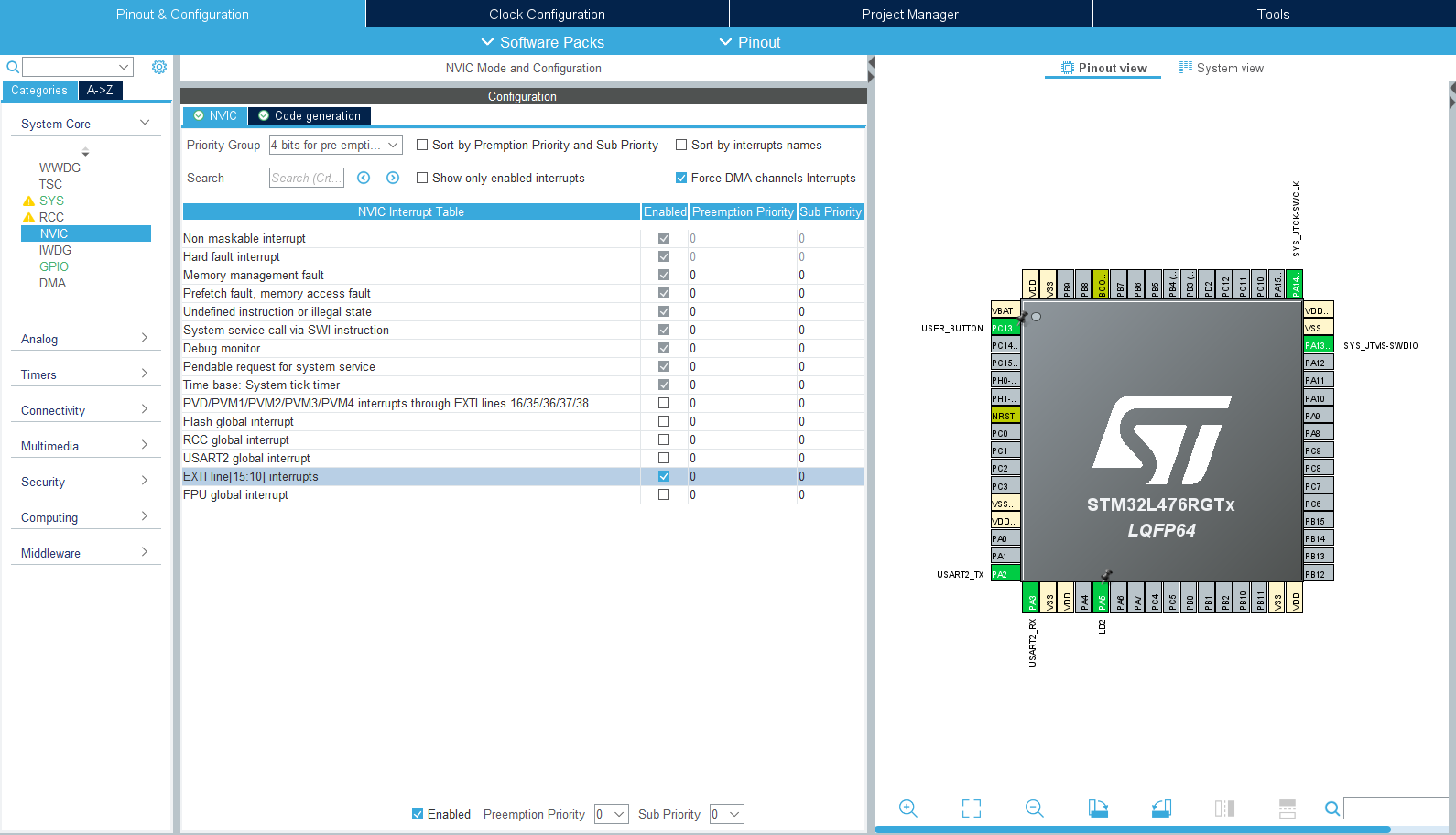
Następnie, będąc cały czas w System Core > GPIO, klikamy w zakładkę NVIC i zaznaczamy checkbox, aby włączyć przerwanie od EXTI line [15:10]. NVIC (ang. nested vectored interrupt controller) – nested oznacza zagnieżdżoną obsługę przerwań, czyli możliwość zawieszenia obsługi przerwania, gdy pojawi się nowe, o wyższym priorytecie, natomiast vectored odnosi się do tablicy funkcji obsługi przerwań, która jest również często nazywana wektorem przerwań. Na koniec mamy interrupt controller, czyli – jak łatwo się domyślić – kontroler przerwań.
NVIC to uniwersalny kontroler przerwań, który jest dostępny z rdzeniami ARM Cortex-M. To zaawansowane rozwiązanie, które charakteryzuje się wieloma zaletami względem wcześniejszych architektur (przekłada się to na szybszą i bardziej przewidywalną obsługę przerwań).
Z kolei aktywacja opcji „EXTI line [15:10]” to aktywacja przerwań zewnętrznych od pinów z numerami od 10 do 15 (a my używamy pinu nr 13). Po prostu piny te mają wspólną procedurę obsługi przerwania. Podobnie razem są połączone linie od 5 do 9, a piny o niższych numerach, czyli 0–4, mają dedykowane dla siebie przerwania. Może to teraz brzmieć zawile, ale za chwilę będzie jasne.
Włączenie przerwania w CubeMX
Zapisujemy zmiany w konfiguracji i generujemy nowy kod. Następnie w odpowiednim miejscu piszemy własną funkcję, której nazwa to HAL_GPIO_EXTI_Callback.
/* USER CODE BEGIN 0 */
void HAL_GPIO_EXTI_Callback(uint16_t GPIO_Pin)
{
if (GPIO_Pin == USER_BUTTON_Pin) {
}
}
Ta sama funkcja jest używana do obsługi przerwań pochodzących od różnych pinów, konkretny pin przekazywany jest do wnętrza funkcji jako (jedyny) parametr. Dlatego w kodzie sprawdzamy, czy na pewno jest to przerwanie od pinu, do którego podłączyliśmy nasz USER_BUTTON. W obecnej wersji programu moglibyśmy z tego sprawdzenia zrezygnować, bo obsługujemy tylko jeden pin, ale program piszemy od razu w sposób umożliwiający późniejsze dodanie obsługi kolejnych wejść.
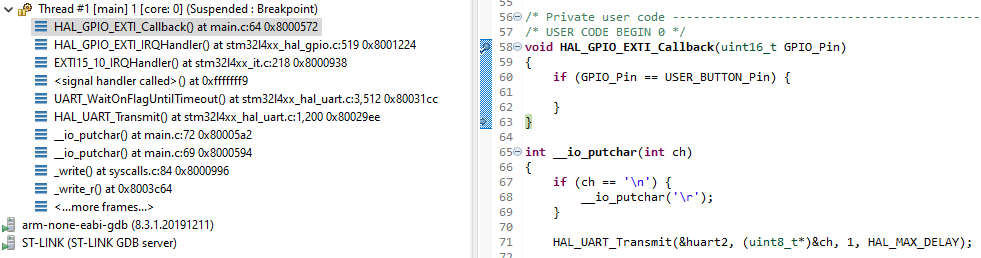
Dodajemy breakpoint do naszej nowej funkcji i uruchamiamy program za pomocą debuggera. Zaraz po naciśnięciu niebieskiego przycisku na Nucleo (USER_BUTTON) główny program zostanie tymczasowo przerwany i mikrokontroler przejdzie do obsługi funkcji przerwania.
Zatrzymanie programu w funkcji obsługującej przerwanie
Przy okazji warto zwrócić uwagę na widok zajmujący lewą część ekranu. Znajdziemy w nim informację o zagnieżdżeniu wywołań funkcji programu. Widzimy, że nasza funkcja HAL_GPIO_EXTI_Callback została wywołana przez HAL_GPIO_EXTI_IRQHandler, a ta z kolei przez EXTI15_10_IRQHandler.
Kliknięcie w nazwę konkretnej funkcji sprawi, że przejdziemy do odpowiedniego miejsca w kodzie. Pod informacją o powyższych funkcjach znajdziemy ważną linijkę: „<signal handler called>” – wyznacza ona rozpoczęcie procedury obsługi przerwania. Funkcje, które umieszczone są pod nią, należą już do programu głównego, którego działanie zostało wcześniej przerwane.
Numeracja przerwań zewnętrznych
Drobnego wyjaśnienia wymaga jeszcze numeracja przerwań zewnętrznych od GPIO. Wspomnieliśmy, że są one grupowane, i np. „EXTI line [15:10]” oznacza przerwanie od pinów z numerami od 10 do 15, więc podczas obsługi przerwania sprawdzamy, który pin wywołał przerwanie. Nigdzie nie ma jednak żadnej informacji na temat portu. Co w przypadku, gdy np. skonfigurujemy jednocześnie przerwanie od pinu PA0 i PB0? Otóż nie ustawimy takiej konfiguracji sprzętowej – CubeMX nie pozwoli na tego typu operację, bo nasz mikrokontroler nie obsłuży takich przerwań.
Przerwanie może być wygenerowane przez tylko jeden pin z danym numerem
Nie da się skonfigurować jednocześnie przerwań od pinów o tych samych numerach, które należą do różnych portów. Dlatego wystarczy sprawdzić sam numer pinu, aby było wiadomo, które przerwanie zostało wywołane.
Licznik naciśnięć przycisku
Wiemy już, że obsługa przerwania związanego z przyciskiem działa, możemy więc napisać przykładowy program wykorzystujący przerwanie. Na początek napiszmy kod zliczający, ile razy użytkownik nacisnął przycisk – w przerwaniu będziemy zliczać wciśnięcia, a wyniki będziemy wysyłać w programie głównym.
Procedury obsługi przerwań powinny być napisane w taki sposób, aby ich wykonywanie nie zajmowało dużo czasu. W ich wnętrzu nie powinno się umieszczać niczego, co opóźnia program.
Program po modyfikacji może wyglądać tak jak poniżej – dodaliśmy zmienną globalną push_counter, a wewnątrz funkcji obsługującej przerwanie zwiększamy jej wartość.
/* USER CODE BEGIN 0 */
volatile uint32_t push_counter;
void HAL_GPIO_EXTI_Callback(uint16_t GPIO_Pin)
{
if (GPIO_Pin == USER_BUTTON_Pin) {
push_counter++;
}
}
Warto zwrócić uwagę na użycie modyfikatora volatile podczas deklaracji zmiennej – taka opcja nie jest często znana początkującym programistom, ale w przypadku mikrokontrolerów i przerwań jest wręcz niezbędna. Główna pętla naszego programu nie modyfikuje tej zmiennej, dlatego optymalizator mógłby założyć, że jest to stała, której wartość wynosi zero. Taki program nie działałby poprawnie. Użycie volatile sprawia, że optymalizator nie próbuje swoich sztuczek w odniesieniu do tej zmiennej.
Z kolei w pętli głównej programu wysyłamy przez UART aktualną wartość licznika:
/* Infinite loop */
/* USER CODE BEGIN WHILE */
while (1)
{
printf("counter = %lu\n", push_counter);
/* USER CODE END WHILE */
/* USER CODE BEGIN 3 */
}
/* USER CODE END 3 */
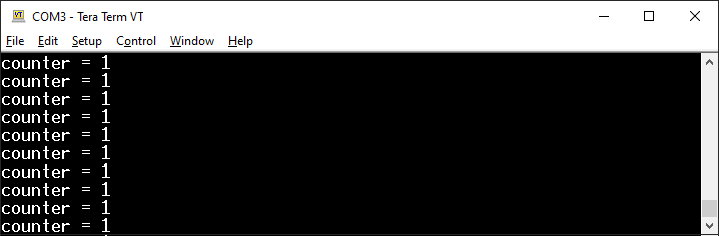
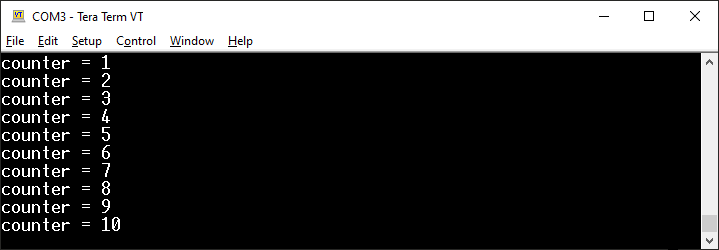
Po uruchomieniu zobaczymy, że program działa, ale wypisuje o wiele za dużo identycznych wyników.
Efekt działania pierwszej wersji licznika wciśnięć przycisku
Zapewne wolelibyśmy uzyskać informację tylko po zmianie wartości licznika, a nie za każdym razem, gdy wykonywana jest pętla główna. Możemy więc zastosować metodę, która jest bardzo użyteczna w wielu programach – zapiszemy poprzednio wysłaną wartość i dopóki licznik nie zmieni wartości, nie będziemy nic wysyłać. Wymaga to dodania jednej zmiennej oraz warunku:
/* Infinite loop */
/* USER CODE BEGIN WHILE */
uint32_t old_push_counter = push_counter;
while (1)
{
if (old_push_counter != push_counter) {
old_push_counter = push_counter;
printf("counter = %lu\n", old_push_counter);
}
/* USER CODE END WHILE */
/* USER CODE BEGIN 3 */
}
/* USER CODE END 3 */
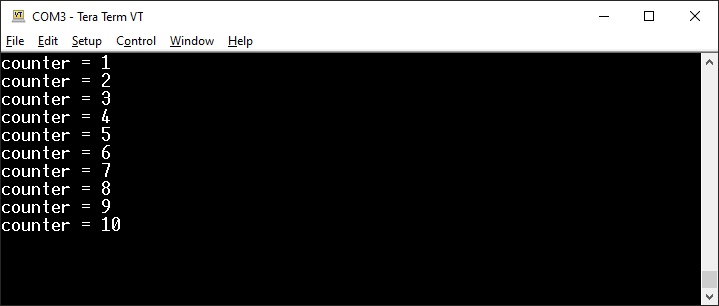
Program w tej wersji działa już poprawnie (sztuczkę z zachowywaniem w pamięci poprzedniego wyniku warto zapamiętać, bo tego typu metody przydają się w wielu różnych sytuacjach).
Efekt działania nowej wersji licznika wciśnięć przycisku
Więcej opcji związanych z przerwaniami
Dotychczas używaliśmy domyślnych ustawień, które dobrze sprawdzały się w naszym przypadku. Warto jednak zobaczyć, jakie możliwości mają przerwania zewnętrzne, czyli funkcja EXTI, którą wybraliśmy dla pinu PC13. W tym celu wracamy do perspektywy CubeMX i wybieramy System Core > GPIO. Na liście używanych wyprowadzeń zaznaczamy PC13 i rozwijamy listę GPIO mode.
Zawartość listy trybów pracy dla wejścia PC13
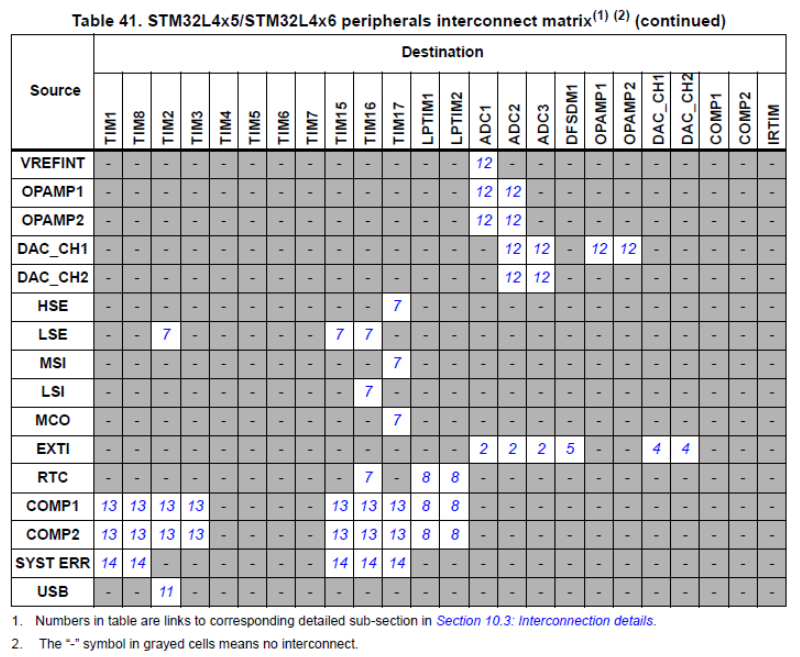
Mamy do wyboru aż sześć opcji, ale wyraźnie widać pewne powtórzenia. Po pierwsze mamy trzy opcje dla przerwań (External Interrupt Mode) i trzy dla zdarzeń (External Event Mode). Różnica polega na tym, że po zgłoszeniu przerwania wykonywana jest jego procedura obsługi. Natomiast zdarzenie można powiązać z kolejnym modułem sprzętowym i odpowiednie działanie zostanie podjęte bez przerywania programu. Możliwości układu w tym kontekście zostały opisane w dokumentacji za pomocą tabeli:
Możliwość powiązywania przerwań z modułem sprzętowym
Tabela ta pokazuje, które moduły mogą być źródłem (ang. source), a które celem (ang. destination). Przycisk jest podłączony do EXTI, a takie źródło może zostać powiązane z ADC, DFSDM oraz DAC. Czyli wciśnięcie przycisku może np. uruchamiać odczyt z ADC (po zakończeniu otrzymamy przerwanie). Bez zdarzeń mielibyśmy aż dwa przerwania – pierwsze od EXTI, które uruchamiałoby konwersję, a dopiero drugie odczytujące wynik. Użycie zdarzeń ma kilka zalet:
mniej przerwań, więc mikrokontroler ma więcej czasu na inne zadania,
jeśli procesor jest uśpiony, to zdarzenia mogą być obsługiwane bez jego budzenia,
zdarzenia działają sprzętowo, więc opóźnienia są minimalne i dokładnie określone. Dla przycisku to bez znaczenia, ale jeśli byłby to sygnał z czujnika mówiący o tym, że trzeba natychmiast pobrać dane z ADC, to w skrajnych sytuacjach użycie przerwań mogłoby być zbyt powolne (przerwania też mają opóźnienia).
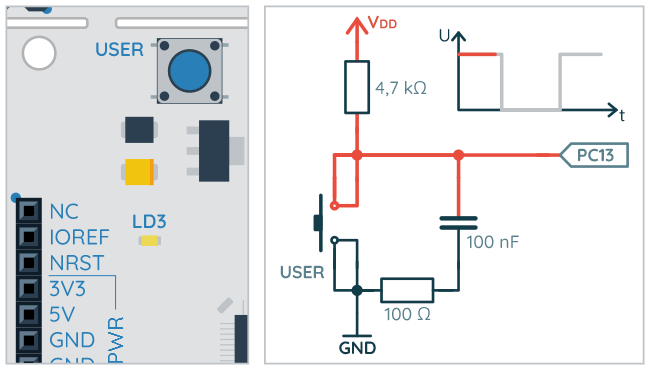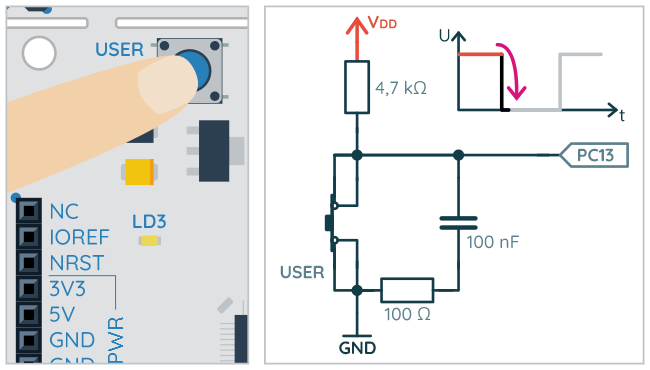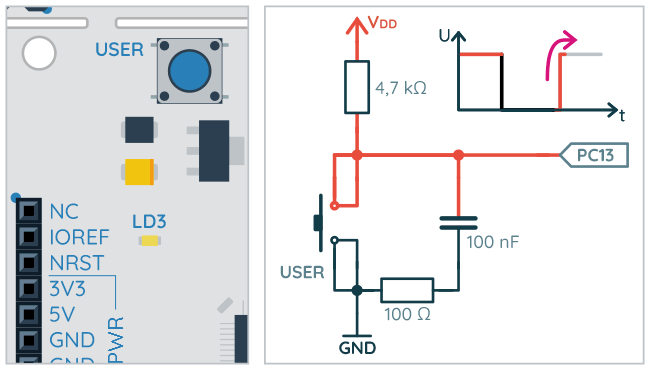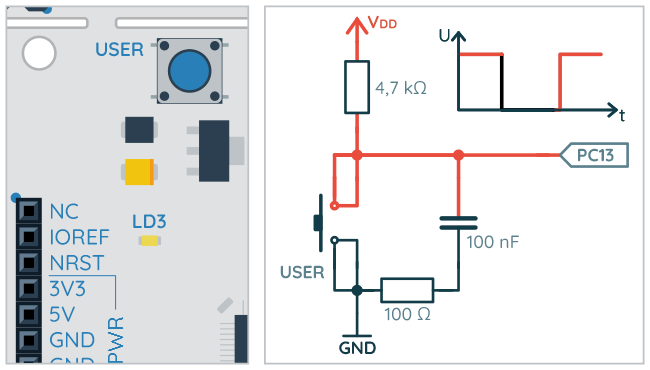
Kolejna opcja to wybór zbocza sygnału, które będzie generowało przerwanie/zdarzenie. Jak pamiętamy z części poświęconej GPIO, gdy przycisk USER_BUTTON jest zwolniony, wtedy na pinie PC13 pojawia się stan wysoki. Wciśnięcie tego przycisku zmienia stan na niski. Zmiana stanu wysokiego na niski to zbocze opadające. Łatwo się domyślić, że podczas zwalniania przycisku pojawia się zbocze narastające.
Zbocza podczas naciskania i puszczania przycisku
Do tej pory używaliśmy trybu domyślnego: External Interrupt Mode with Rising edge trigger detection. Dlatego przerwanie pojawiało się po wykryciu narastającego zbocza, czyli po zwolnieniu przycisku. Program będzie działać nieco bardziej intuicyjnie, gdy wybierzemy opcję generowania przerwania po wykryciu zbocza opadającego – użytkownik spodziewałby się zadziałania licznika raczej po wciśnięciu, a nie dopiero po zwolnieniu przycisku.
Niepoprawna wersja z printf w przerwaniu
Przerwania są specyficznym mechanizmem, który zaczyna się rozumieć i doceniać dopiero po pewnym czasie. Wielu początkujących popełnia błąd polegający na tym, że w funkcji obsługującej przerwanie umieszczają kod, którego wykonanie zajmuje dużo czasu. Pomijając fakt, że to naganna praktyka, takie sytuacje prowadzą często do błędów, które są bardzo ciężkie w zdiagnozowaniu.
Dlatego tutaj specjalnie stworzymy antyprzykład! Przedstawimy, jak nie należy pisać programów z przerwaniami. W poprzednim kodzie wysyłanie danych realizowaliśmy w pętli głównej. Było to poprawne podejście, bo procedura obsługi przerwania była wykonywana błyskawicznie (inkrementacja zmiennej), a samo wysyłanie odbywało się podczas normalnej pracy układu (gdy miał on na to czas).
Znacznie łatwiej byłoby jednak napisać program, który wysyła wiadomość bezpośrednio w przerwaniu, prawda? Przy takim podejściu program główny to pusta pętla:
/* USER CODE BEGIN WHILE */
while (1)
{
/* USER CODE END WHILE */
/* USER CODE BEGIN 3 */
}
/* USER CODE END 3 */
Natomiast całą resztę umieszczamy w procedurze obsługującej przerwanie:
/* USER CODE BEGIN 0 */
volatile uint32_t push_counter;
void HAL_GPIO_EXTI_Callback(uint16_t GPIO_Pin)
{
if (GPIO_Pin == USER_BUTTON_Pin) {
push_counter++;
printf("counter = %lu\n", push_counter);
}
}
Uruchamiamy program i testujemy:
Poprawny efekt działania błędnej wersji programu
Okazuje się, że wszystko działa, jak powinno, dlaczego więc nie uznać tego rozwiązania za poprawne? Teraz warto przypomnieć sobie eksperyment z wyświetlaniem licznika milisekund, który wykonywaliśmy na początku tej części kursu. Jak widzieliśmy, wysyłanie napisów zajmuje sporo czasu. Dla nas jedna milisekunda to moment, ale dla mikrokontrolera już niekoniecznie. Takie opóźnienie łatwo „przeoczyć”, ale może ono wpływać na działanie programu.
Żeby się o tym przekonać, spróbujmy nieco wydłużyć naszą procedurę obsługi przerwania. Najlepiej tak, żebyśmy mogli zobaczyć wpływ tego opóźnienia bez dodatkowego sprzętu (np. oscyloskopu). W tym celu specjalnie łamiemy główną zasadę korzystania z przerwań, czyli zakaz dodawania opóźnień wewnątrz funkcji obsługującej przerwanie.
/* USER CODE BEGIN 0 */
volatile uint32_t push_counter;
void HAL_GPIO_EXTI_Callback(uint16_t GPIO_Pin)
{
if (GPIO_Pin == USER_BUTTON_Pin) {
push_counter++;
printf("counter = %lu\n", push_counter);
HAL_Delay(100);
}
}
Intuicja może podpowiadać, że taki program też będzie działał poprawnie – najwyżej reakcja na naciśnięcie przycisku niekiedy zajmie więcej czasu. Uruchamiamy program, naciskamy niebieski przyciski i… cały układ się zawiesza. Nawet zielona dioda LD2 już nie miga, czyli nasz główny licznik systemowy przestał działać – tego się raczej nie spodziewaliśmy! Gdybyśmy skonfigurowali watchdoga, toby nas teraz uratował, ale jeśli go nie mamy, to jedynym wyjściem będzie ręczny reset płytki.
Przyczynę zawieszania wyjaśnimy za chwilę, zacznijmy jednak od „poprawienia” programu i zastąpienia wywołania HAL_Delay „zwykłą” pustą pętlą. Następna wersja procedury obsługi wygląda tak:
/* USER CODE BEGIN 0 */
volatile uint32_t push_counter;
void HAL_GPIO_EXTI_Callback(uint16_t GPIO_Pin)
{
if (GPIO_Pin == USER_BUTTON_Pin) {
push_counter++;
printf("counter = %lu\n", push_counter);
volatile uint32_t delay;
for (delay = 0; delay < 1000000; delay++);
}
}
Po uruchomieniu tego programu okaże się, że wszystko działa poprawnie… Czyżby? Niby układ działa i nic się nie zawiesza, ale podczas naciskania przycisku możemy jednak zauważyć, że dioda LD2 przestaje równo migać. Dzieje się tam coś złego, szczególnie że dioda jest sterowana za pomocą SysTick, czyli innego przerwania – jej działanie powinno być zatem niezależne od reszty układu.
Problem z działaniem SysTick podczas naciskania przycisku
Dzieje się tak, bo podczas obsługi przerwania od przycisku układ nie reaguje na inne przerwania. Nie działa nawet aktualizacja zmiennej uwTick, dzięki której odczytywaliśmy SysTick. Właśnie dlatego wcześniejsze wywołanie funkcji HAL_Delay prowadziło do zawieszenia programu (układ nie dał rady odczekać określonej liczby milisekund, jeśli wskazania głównego licznika nie były aktualizowane). Nasze opóźnienie było właściwie pętlą nieskończoną, w której utknęliśmy. Wersja z pętlą for nie zawieszała się, bo nie korzystaliśmy tam z przerwań, po prostu wykorzystywaliśmy „brutalnie” to, że wykonanie 999 999 obiegów pustej pętli zajmie na trochę nasz mikrokontroler.
Gdybyśmy używali w systemie innych przerwań, wówczas ich obsługa też byłaby zawieszana, co mogłoby powodować trudne do wykrycia błędy.
Bez dodatkowego opóźnienia nasz program blokował przerwania na niewiele ponad milisekundę. To czasem mogło powodować opóźnienia zliczania milisekund przez SysTick, ale były to tak krótkie czasy, że nie widzieliśmy tego efektu. Nie znaczy to, że takie działanie nie miało negatywnych następstw, ale wykrycie błędów było bardzo trudne i mogłoby przez długi czas pozostać niezauważone.
Priorytety przerwań
Procedury obsługi przerwań powinny działać szybko, aby nie powodować zakłóceń w obsłudze innych przerwań oraz nie spowalniać działania programu głównego. Może się jednak tak zdarzyć, że więcej niż jedno przerwanie zostanie zgłoszone w tej samej chwili albo przerwanie pojawi się podczas obsługi poprzedniego.
To, jak zachowa się układ w takiej sytuacji, zależy od tzw. priorytetów przerwań. Do tej pory używaliśmy domyślnych ustawień, zobaczmy jednak, jakie możliwości oferuje nam STM32L476RG. Przechodzimy do perspektywy CubeMX, a dalej do System Core > NVIC.
Ustawienia przerwań na STM32L4 w CubeMX
W oknie ustawień NVIC widzimy listę aktualnie używanych przerwań. Pozycje z zaznaczonym polem Enabled są włączone, czyli te przerwania są aktualnie obsługiwane. To, co nas na ten moment interesuje, to przerwanie „Time base: System tick timer” oraz to, które aktywowaliśmy już wcześniej, czyli „EXTI line[15:10] interrupts”. Oba są włączone i oba mają priorytety ustawione na zera.
Im mniejsza wartość, tym wyższy priorytet (0 oznacza najwyższy priorytet, a 15 najniższy).
Domyślnie wszystkie priorytety są ustawione jako najwyższe (wartość 0). Takie ustawienie sprawia, że gdy rozpocznie się obsługa jednego przerwania, np. od naszego przycisku, wtedy inne przerwania nie mogą być już obsługiwane. Domyślnie wszystkie przerwania mają najwyższy priorytet.
Priorytety są nieco skomplikowane, ponieważ zostały podzielone dodatkowo na dwie części. Pierwsza to priorytet wywłaszczania (ang. preemption priority), a druga – podpriorytet (ang. subpriority). Jeśli podczas obsługi przerwania pojawi się kolejne przerwanie, o niższej wartości preemption priority, to aktualna procedura zostanie zawieszona, a procesor zacznie obsługę nowego przerwania. Mamy więc przerwanie w przerwaniu, czyli przerwanie zagnieżdżone (ang. nested).
Natomiast drugie pole, subpriority, ma znaczenie, jeśli dwa przerwania o identycznym priorytecie będą gotowe do rozpoczęcia obsługi w tym samym momencie. Wówczas jako pierwsze zostanie obsłużone przerwanie o niższej wartości w polu subpriority.
Jeszcze drobna uwaga odnośnie do liczby priorytetów. Informacja ta jest zapisana jako wartość 4-bitowa, dlatego mamy do dyspozycji 16 poziomów. Możemy jednak sami ustalić, ile bitów przypadnie na pole preemption priority, a ile na subpriority.
Edycja ustawień priorytetów
W górnej części okna ustawień NVIC dostępna jest lista Priority Group, gdzie domyślnie wybrana jest wartość 4 bits for pre-emption priority 0 bits for subpriority, która oznacza, że mamy 16 poziomów preemption priority, a pole subpriority nie jest używane. Podczas nauki i tworzenia prostych projektów nie trzeba zmieniać tych ustawień – warto jednak pamiętać o tym na przyszłość.
Zmiana priorytetu przerwań
Pora sprawdzić, jak można wykorzystać w praktyce zmianę priorytetu przerwań. W przypadku biblioteki HAL warto zawsze ustawić wyższy priorytet dla przerwania SysTick niż dla innych peryferii. Inaczej może się okazać, że zegar systemowy się spóźnia lub procedury obsługi przerwań ulegają zawieszeniu.
Przerwanie SysTick powinno mieć wyższy priorytet niż inne moduły (dla przypomnienia: w przypadku układów STM32 0 to najwyższy priorytet, a 15 to najniższy możliwy priorytet).
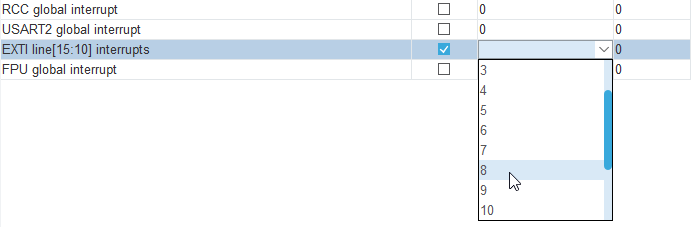
W ramach eksperymentu zmieńmy ustawienie priorytetu dla modułu EXTI z 0 na 8. Wystarczy kliknąć w odpowiednim polu i wybrać z listy rozwijanej właściwą opcję. Po zmianie zapisujemy projekt, aby został wygenerowany nowy kod, kompilujemy całość i wgrywamy na mikrokontroler.
Zmiana ustawień priorytetów dla przerwań zewnętrznych
Podczas testowania tej wersji programu zielona dioda nie powinna przestawać migać, nie powinna się też zawieszać. Można również teraz sprawdzić ponownie nasz antyprzykład z opóźnieniem HAL_Delay wewnątrz funkcji obsługującej przerwanie. Zmiana priorytetów przerwań sprawiała, że program się nie zawiesi – wszystko dlatego, że przerwanie od licznika systemowego ma wyższy priorytet.
Przypominamy jednak, że umieszczanie opóźnień wewnątrz funkcji obsługującej przerwanie to coś, czego raczej nie należy robić. W tym przypadku była to metoda na zasymulowanie tego, co może się dziać, gdy wykonanie zawartości tej funkcji będzie trwało zbyt długo.
Obsługa UART-a w przerwaniach
Wrócimy jeszcze do UART-a. Wcześniej do wysyłania danych używaliśmy funkcji HAL_UART_Transmit, która ma taką nieprzyjemną cechę, że blokuje wykonywanie programu na czas transmisji.
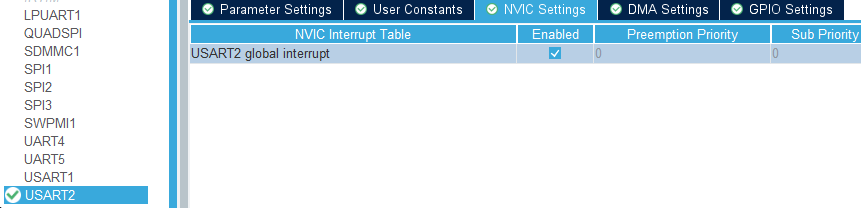
W związku z tym, że chcemy używać przerwań, w CubeMX przechodzimy do konfiguracji modułu USART2, a następnie klikamy zakładkę NVIC Settings. Znajdziemy w niej tylko jedną opcję, którą musimy zaznaczyć – mowa o „USART2 global interrupt”.
Aktywacja przerwań od modułu USART2
Kolejny krok to zmiana priorytetów przerwań. Przechodzimy więc do System Core > NVIC i na liście dostępnych przerwań odnajdujemy to, które powiązane jest z USART2. Powinno być już aktywne – to, co nas teraz interesuje, to zmiana priorytetu: z domyślnego 0 na 12, tak aby był on jeszcze niższy niż to przerwanie, które przypisaliśmy do obsługi przycisku.
Ustawienie priorytetu przerwania od modułu USART2
Wysyłanie danych z użyciem przerwań
Tym razem (celowo) nie skorzystamy z przekierowania printf, tylko wyślemy komunikat w najprostszy możliwy sposób – bezpośrednio z funkcji HAL_UART_Transmit_IT, która jest bliźniaczo podobna do znanej nam funkcji HAL_UART_Transmit (różnica to tylko dopisek „_IT”, który bierze się od tego, że funkcja ta korzysta właśnie z przerwań).
Jak pamiętamy, HAL_UART_Transmit wysyła kolejno wszystkie dane, które otrzymała jako parametry wywołania, i kończy działanie, gdy wszystkie dane zostaną wysłane (a mówiąc dokładniej: kiedy zostaną wstawione do rejestrów sprzętowych, wysyłanie może jeszcze wówczas trwać). HAL_UART_Transmit_IT robi niby to samo, ale działa zupełnie inaczej. Jej wywołanie jedynie rozpoczyna wysyłanie danych, po czym funkcja kończy swoje działanie, a dane są wysyłane „w tle” przy wykorzystaniu przerwań.
Napiszmy zatem pierwszy testowy program:
/* USER CODE BEGIN 2 */
char message[] = "Hello World!\r\n";
HAL_UART_Transmit_IT(&huart2, (uint8_t*)message, strlen(message));
/* USER CODE END 2 */
Dla przypomnienia: aby zadziałała funkcja strlen, musimy dodać jeszcze plik nagłówkowy:
#include <string.h>
Po uruchomieniu takiego programu widok będzie następujący:
Efekt działania programu wysyłającego dane dzięki przerwaniom
Nie powinno to być dla nikogo zaskoczeniem. Nie widać tutaj jednak żadnej różnicy ani tym bardziej zalety z takiego podejścia. Wiemy, że komunikacja z użyciem przerwań działa poprawnie, więc możemy już rozbudować trochę ten przykład.
Sprawdzanie komunikatu błędów
Tak jak już wspomnieliśmy, najprościej można powiedzieć, że nowa funkcja, która wysyła dane dzięki przerwaniom, „po prostu” nie zatrzymuje programu na czas transmisji. Takie działanie ma kilka bardzo ważnych konsekwencji. Pierwsza, która najczęściej jest zaletą, to możliwość kontynuowania programu. Niestety bywa ona również wadą, bo prowadzi czasem do nieco zaskakujących błędów.
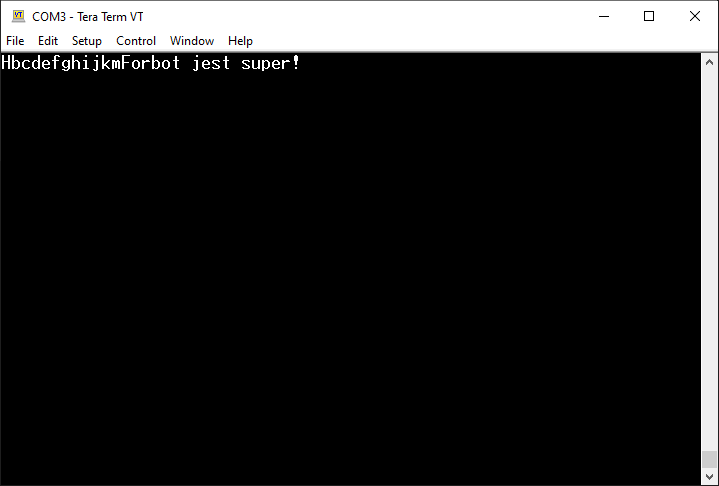
Zmieńmy nasz kod w taki sposób, aby wysyłał dwa napisy (jeden pod drugim):
/* USER CODE BEGIN 2 */
char message[] = "Hello World!\r\n";
HAL_UART_Transmit_IT(&huart2, (uint8_t*)message, strlen(message));
char message2[] = "Forbot jest super!\r\n";
HAL_UART_Transmit_IT(&huart2, (uint8_t*)message2, strlen(message2));
/* USER CODE END 2 */
Niestety po uruchomieniu programu rezultat może być nieco inny, niż oczekiwaliśmy, bo na ekranie zobaczymy to samo co poprzednio – czyli jeden napis „Hello World!”.
Zaskakujące działanie kodu, który miał wysłać dwa komunikaty
Problem wynika stąd, że kolejne wywołanie HAL_UART_Transmit_IT wykonaliśmy w czasie, gdy dane z pierwszego komunikatu były nadal nadawane. Biblioteka HAL w takiej sytuacji zwróciła kod błędu, ale my go nie sprawdziliśmy.
Pisząc programy, należy zawsze sprawdzać, czy wywołania funkcji zakończyły się sukcesem. Niestety taki kod jest często mniej czytelny, do tego podczas „szybkich testów” często zapomina się o tego typu mechanizmach. O ile podczas takich przykładów jak te, które opisywaliśmy do tej pory, można na to jeszcze „przymknąć oko”, o tyle w programach produkcyjnych obsługa błędów jest niezbędna!
Dodajmy teraz obsługę błędów do wcześniejszego programu. Funkcja HAL_UART_Transmit_IT zwraca wartość typu HAL_StatusTypeDef. Jest to typ wyliczeniowy, którego wartości są następujące:
Oczekujemy, że wartością zwracaną jest HAL_OK, powstaje jednak pytanie: co zrobić, jeśli otrzymamy inną wartość? Kod wygenerowany automatycznie przez CubeMX zawiera funkcję Error_Handler, która jest wywoływana w przypadku wystąpienia błędu (np. podczas inicjalizacji programu).
Jej kod znajdziemy w pliku main.c:
void Error_Handler(void)
{
/* USER CODE BEGIN Error_Handler_Debug */
/* User can add his own implementation to report the HAL error return state */
__disable_irq();
while (1)
{
}
/* USER CODE END Error_Handler_Debug */
}
Jak widać, domyślnie jest to po prostu nieskończona pętla, w której zawiesza się nasz układ. Oczywiście powraca uwaga dotycząca nieskończonych pętli w reakcji na błąd – to niezbyt dobre rozwiązanie w produkcyjnym kodzie, ale podczas nauki nam wystarczy. Spróbujmy więc wywoływać Error_Handler, jeśli HAL_UART_Transmit_IT nie zakończy się sukcesem.
Nowy kod powinien wyglądać teraz tak:
char message[] = "Hello World!\r\n";
if (HAL_UART_Transmit_IT(&huart2, (uint8_t*)message, strlen(message)) != HAL_OK) {
Error_Handler();
}
char message2[] = "Forbot jest super!\r\n";
if (HAL_UART_Transmit_IT(&huart2, (uint8_t*)message2, strlen(message2)) != HAL_OK) {
Error_Handler();
}
Teraz możemy uruchomić nasz program. Okaże się, że działa on jeszcze inaczej niż poprzednio. W tej chwili na ekranie zobaczymy prawdopodobnie tylko pierwszą literę pierwszego napisu, czyli H. Jeśli teraz przerwiemy działanie programu za pomocą debuggera, to zobaczymy, że została wywołana funkcja obsługi błędu. W jej wnętrzu oprócz nieskończonej pętli jest też wywołana funkcja __disable_irq, która blokuje wykonywanie przerwań – stąd nie udało nam się wysłać poprawnie nawet jednego napisu.
Program został zatrzymany w funkcji obsługującej błędy
Jak zwykle po lewej stronie okna widzimy tzw. stos wywołań, możemy więc zobaczyć, która instrukcja spowodowała konkretnie nasz błąd – w tym wypadku jest to funkcja main, bo w jej wnętrzu znalazł się nasz kod wysyłający dane przez UART.
Ukrywanie problemów
Zanim przejdziemy dalej, pokażemy rozwiązanie, które niestety często pojawia się w programach, (również produkcyjnych). Czasami programiści dochodzą za pomocą metody prób i błędów do tego, że urządzenie działa poprawnie, jeśli wstawi się „gdzieś jakieś” opóźnienie. Później w kodzie są takie „kwiatki” jak komentarz w poniższym przykładzie. Teraz możemy potraktować to humorystycznie, ale chyba nikt nie chciałby pracować z kodem, który był wcześniej „naprawiany w taki sposób”.
char message[] = "Hello World!\r\n";
if (HAL_UART_Transmit_IT(&huart2, (uint8_t*)message, strlen(message)) != HAL_OK) {
Error_Handler();
}
// Uwaga! nie kasować!
// nie wiem dlaczego to jest potrzebne, ale po usunięciu program nie działa
HAL_Delay(100);
char message2[] = "Forbot jest super!\r\n";
if (HAL_UART_Transmit_IT(&huart2, (uint8_t*)message2, strlen(message2)) != HAL_OK) {
Error_Handler();
}
Okazuje się, że teraz nasz program działa dokładnie tak, jak chcieliśmy. Jest to oczywiście niepoprawny przykład, gorszy niż wywołanie HAL_UART_Transmit bez przerwań, ale niestety dość popularny.
Zamiast naprawić przyczynę problemu, po prostu prowizorycznie ukryliśmy ten problem. Wywołanie HAL_UART_Transmit_IT uruchamia transmisję w tle. Kolejne użycia tej funkcji, przed zakończeniem wcześniejszej transmisji, kończą się błędem. Dodanie opóźnienia sprawia, że błędu już nie widać, bo drugie użycie funkcji pojawi się po 100 ms, a do tego czasu pierwszy komunikat zostanie wysłany. Warto dodać, że jeszcze inną wersją prowizorycznego rozwiązania tego problemu byłoby wywoływanie HAL_UART_Transmit_IT w pętli, aż w końcu zwróci HAL_OK. To też by działało, ale byłoby równie złe.
Informacja o zakończeniu transmisji
Wiemy już, że kod działa niepoprawnie, ponieważ wysyłamy kolejny komunikat przed zakończeniem transmisji poprzedniego. Na początek wróćmy do wysyłania tylko jednego komunikatu (bez warunków sprawdzających poprawność zakończenia transmisji):
/* USER CODE BEGIN 2 */
char message[] = "Hello World!\r\n";
HAL_UART_Transmit_IT(&huart2, (uint8_t*)message, strlen(message));
/* USER CODE END 2 */
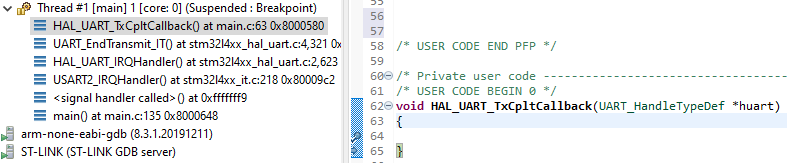
O zakończeniu transmisji przez UART możemy zostać poinformowani, jeśli napiszemy funkcję, która nazywa się HAL_UART_TxCpltCallback.
Biblioteka HAL wysyła kolejne bajty danych podczas obsługi przerwania od USART2, a gdy wyśle ostatni bajt, wywoła właśnie tę funkcję. Zacznijmy od sprawdzenia, czy działa to za pomocą debuggera. Dodajemy do kodu taką funkcję, ustawiamy w niej breakpoint i testujemy program. Po chwili od startu zostanie on zatrzymany właśnie w tej funkcji.
Zatrzymanie programu w funkcji informującej o końcu transmisji
Teraz moglibyśmy dodać flagę, która będzie zmieniała stan po zakończeniu transmisji, a w programie głównym czekalibyśmy na jej ustawienie, aby wysłać kolejne dane. Jest to równie zła metoda jak czekanie z HAL_Delay albo wywoływanie HAL_UART_Transmit_IT w pętli. Blokując wykonywanie kodu, niweczymy zalety używania przerwań i komplikujemy program, a jak wiadomo – im więcej linii ma kod, tym więcej jest w nim błędów…
Wysyłanie komunikatów w przerwaniu
Skoro funkcja HAL_UART_TxCpltCallback jest wywoływana po zakończeniu transmisji pierwszego komunikatu, to może wyślijmy w niej drugi komunikat? Warto spróbować! Piszemy więc program:
Użycie zmiennej statycznej wyjaśnimy za chwilę, na razie zobaczmy efekt działania programu. Dane są wyświetlane, ale… całość działa aż za dobrze. Jedno „super” całkowicie bym nam wystarczyło.
Błędne działanie nowej wersji programu
Oczywiście tym razem ponownie popełniliśmy błąd specjalnie, aby pokazać, co stałoby się, gdybyśmy chcieli rozwiązać ten problem w prosty, ale niepoprawny sposób. Wywołanie HAL_UART_Transmit_IT rozpoczyna transmisję, której zakończenie wywołuje HAL_UART_TxCpltCallback, która znów wywołuje HAL_UART_Transmit_IT – i tak w kółko.
Bardzo prosty automat skończony
Moglibyśmy jeszcze długo wymyślać poprawki naszego programu i pewnie w końcu udałoby nam się uzyskać zadowalający rezultat, spróbujmy jednak zastosować nieco inne podejście, które o wiele lepiej sprawdza się w przypadku procedur obsługi przerwania. Problem polega na tym, że jesteśmy przyzwyczajeni do pisania programów, które wykonują się jako ciąg instrukcji, czyli przykładowo:
Każda czynność wykonywana jest po zakończeniu poprzedniej, bo nie warto czekać na dostawę, jeśli nie zamówiliśmy pizzy, a odbieranie pizzy, zanim zostanie dostarczona, też nie ma sensu. Można byłoby dyskutować o ostatnim punkcie, ale załóżmy, że impreza na głodnego nas nie interesuje.
Korzystanie z przerwań wymaga odrobinę innego sposobu myślenia
W przypadku przerwań musimy zmienić podejście. Procedura obsługi przerwania jest wywoływana za każdym razem od początku i nie możemy w niej wykonywać długotrwałych czynności. Zamiast tego powinniśmy zlecić rozpoczęcie kolejnego etapu i natychmiast zakończyć procedurę. Gdy etap zostanie zakończony, procedura obsługi przerwania zostanie wywołana ponownie. Oznacza to, że musimy pamiętać, na jakim etapie jesteśmy.
Gdybyśmy chcieli nasz przykład zamienić na imprezę informatyków programujących w przerwaniach, mielibyśmy następujący pseudokod:
int następny_etap = 0;
void procedura_obsługi_przerwania()
{
switch (następny_etap) {
case 0:
zamów_pizzę();
następny_etap = 1;
break;
case 1:
poczekaj_na_dostawę();
następny_etap = 2;
break;
case 2:
zapłać_i_odbierz();
następny_etap = 3;
break;
case 3:
rozpocznij_imprezę();
// zostawiamy następny_etap na wartości 3, czyli impreza nigdy się nie kończy
break;
}
}
Wysyłanie komunikatów w przerwaniu, ulepszona wersja
Spróbujmy więc nasz poprzedni przykład odnieść do szarej rzeczywistości, czyli do wysyłania napisów. Chcemy wysłać dwa napisy, więc przypadków będzie nieco mniej:
Przy pierwszym wywołaniu send_next_message zmienna message_number będzie miała wartość 0, więc wywołamy w niej HAL_UART_Transmit_IT z pierwszym komunikatem jako parametrem, a wartość zmienimy na 1. Przy drugim wywołaniu wartość zmiennej będzie wynosiła 1, więc spowoduje to wysłanie kolejnego komunikatu oraz ustawienie wartości na 2. Podczas kolejnych wywołań wartość message_number będzie wynosiła 2, a funkcja nie będzie już nic robiła.
W procedurze obsługi przerwania wystarczy wywołać tę nową funkcję. Przy okazji możemy dodać sprawdzenie, czy na pewno obsługujemy przerwanie od USART2. W naszym projekcie obsługujemy tylko ten moduł UART, ale w przyszłości będziemy używać kilku modułów naraz. Wówczas ta sama funkcja HAL_UART_TxCpltCallback będzie wywoływana po zakończeniu komunikacji każdego modułu. Warto zatem przygotować się na taką możliwość:
Została jeszcze zmiana programu głównego. Jak wiemy, HAL_UART_TxCpltCallback będzie wywołany po zakończeniu transmisji, ale najpierw ktoś musi tę transmisję uruchomić. Okazuje się, że podejście z utworzeniem funkcji send_next_message bardzo ułatwia napisanie głównego kodu. Skoro zmienna message_number ma wartość 0, to wystarczy wywołać send_next_message i komunikacja odbędzie się w całości w przerwaniach:
/* USER CODE BEGIN 2 */
send_next_message();
/* USER CODE END 2 */
Po uruchomieniu tej wersji projektu zobaczymy wreszcie oczekiwany rezultat, i to bez blokowania programu w oczekiwaniu na zakończenie transmisji. Tym sposobem moglibyśmy wysyłać za pomocą przerwań wiele następujących po sobie komunikatów.
Ostateczny efekt działania programu
Ulepszanie kodu
Używanie w programie liczb o znaczeniach znanych tylko jego autorowi (dlatego nazywanych magicznymi liczbami) nie jest dobrym zwyczajem. Nawet nam będzie ciężko zrozumieć, co znaczyły wartości 0, 1, 2 przypisywane zmiennej message_number. Czytelność kodu można poprawić, używając typu wyliczeniowego zamiast zwykłych liczb. Moglibyśmy zdefiniować następujący typ:
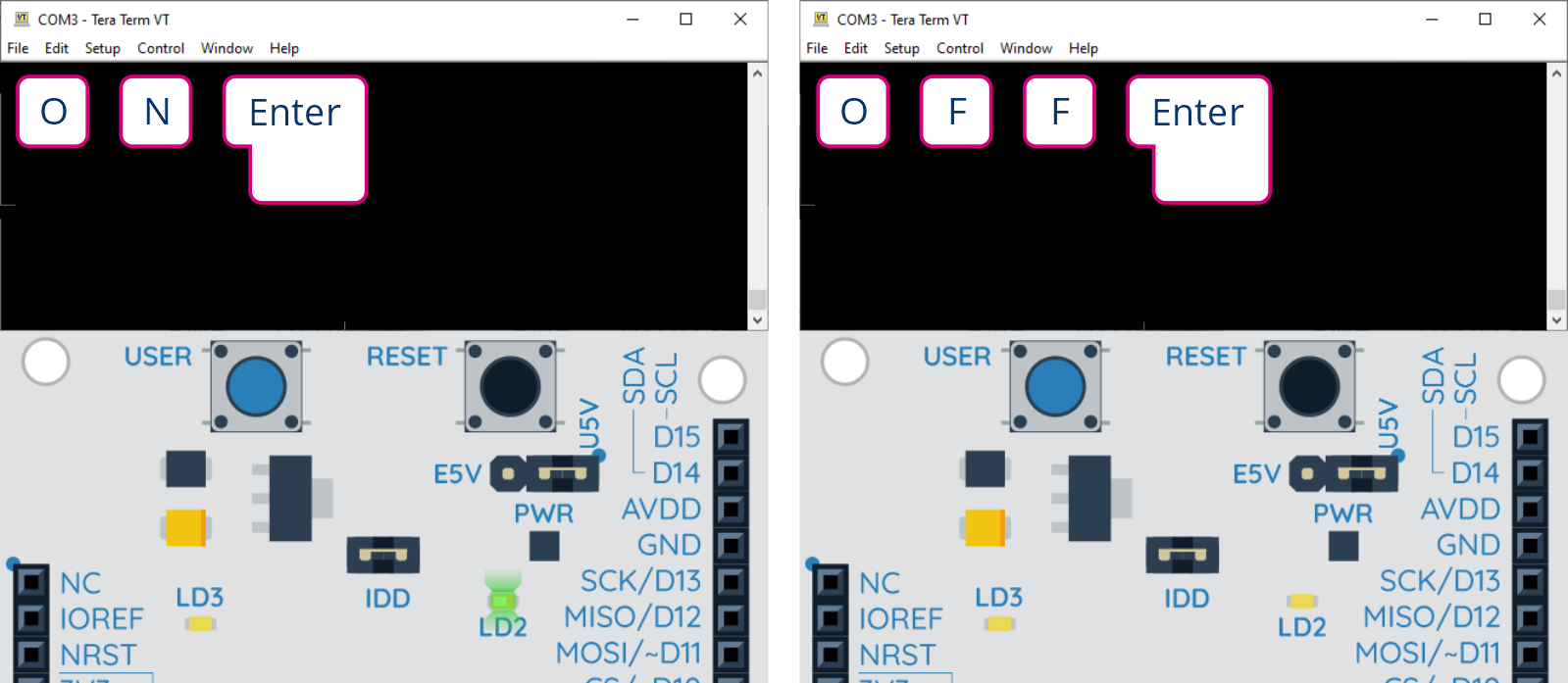
Teraz małe wyjaśnienie, dlaczego użyliśmy słowa kluczowego static przy deklaracji zmiennych message i message2. Zacznijmy od sprawdzenia, co będzie, jeśli usuniemy ten modyfikator – po uruchomieniu takiej wersji kodu program może działać częściowo poprawnie, tzn. będą się pojawiały komunikaty, ale o niepoprawnej (losowej?) treści. Jest znacznie gorzej, niż nam się wydaje, bo ta niepoprawna treść wcale nie jest losowa. Utwórzmy nową funkcję:
/* USER CODE BEGIN 0 */
void test() {
volatile char x[] = "abcdefghijkmnopq";
}
Nasza nowa funkcja nie robi właściwie nic oprócz zadeklarowania zmiennej lokalnej. W tym przypadku użyliśmy modyfikatora volatile, żeby optymalizator nie mógł tej zmiennej usunąć, pomimo że nie jest używana nigdzie w programie. Dodajmy wywołanie testu po rozpoczęciu transmisji, czyli:
/* USER CODE BEGIN 2 */
send_next_message();
test();
/* USER CODE END 2 */
Podczas kompilacji tego programu kompilator wyświetli ostrzeżenie o tym, że nie używamy nigdzie zmiennej x z funkcji test, ale tym się nie przejmujemy. Wgrywamy program i obserwujemy wyniki:
Zaskakujący wynik działania programu
Jak widzimy, zawartość zmiennej lokalnej funkcji test została wysłana przez port szeregowy. Nasza funkcja została dodana specjalnie, ale przy tego typu błędzie zmienne lokalne właściwie z dowolnej funkcji mogą zostać niechcący wysłane poza urządzenie.
Spróbujmy więc zrozumieć, co się stało. Zmienne lokalne tworzone są na tzw. stosie. Dopóki zmienne są w zasięgu, czyli aktualnie wykonywanym bloku kodu (np. funkcji), to są dostępne i działają zgodnie z oczekiwaniami. Jednak gdy program „wyjdzie” z miejsca, w którym były one widoczne, wtedy pamięć, którą zajmowały te zmienne, jest zwalniana i może zostać użyta przez kolejne zmienne.
Takie działanie jest jak najbardziej poprawne, zmienne lokalne istnieją tylko chwilowo. Niestety oznacza to, że nie możemy używać wskaźników do nich, gdy program opuści zasięg, bo w danej lokalizacji mogą czasami znajdować się „śmieci”.
Przekazaliśmy wskaźnik do zmiennej lokalnej messagew funkcji HAL_UART_TxCpltCallback, a po chwili działanie funkcji zostało zakończone, natomiast pamięć zwolniona. Jednak w przerwaniu moduł USART nadał wysyłał dane znajdujące się w miejscu, gdzie wcześniej była zmienna message. Jeśli teraz inny fragment programu zapisze dane w tym miejscu, to zostaną one wysłane przez port szeregowy.
Takie nadpisywanie zrealizowała właśnie nasza funkcja test.
Tego typu błąd nie tylko sprawia, że komunikat nie wygląda tak dobrze, jak oczekiwaliśmy, ale może zostać też wykorzystany do łamania zabezpieczeń. Gdyby w tym miejscu pamięci znalazły się ważne dane, np. hasło dostępu albo numer karty kredytowej, wówczas mogłyby „z rozpędu” zostać wysłane do użytkownika, który nie powinien mieć do nich wglądu.
Błędna deklaracja zmiennej może doprowadzić np. do wycieku numeru karty kredytowej użytkownika
Wniosek z tego przykładu jest taki, że używając przerwań, należy bardzo uważać, gdzie będziemy przechowywać dane przeznaczone do transmisji. Zmienne lokalne są w tym przypadku (na ogół) złym miejscem, można za to używać zmiennych globalnych albo zmiennych statycznych. W obu przypadkach ich lokalizacja jest stała i nie zostanie użyta przez inne zmienne.
Odbieranie danych w przerwaniach
Umiemy już wysyłać dane, wykorzystując przerwania, powinniśmy więc jeszcze zobaczyć, jak można w przerwaniach odbierać dane. Jest to nawet ważniejsze od wysyłania, bo wysyłając, wiemy, ile mamy danych i kiedy będziemy je przesyłać. Natomiast odbieranie wymagałoby ciągłej uwagi i sprawdzania, czy aby nie przyszły jakieś nowe dane. Zamiast tego znacznie lepiej używać przerwań.
Biblioteka HAL oczywiście ułatwia nam to zadanie, wywołując funkcję o nazwie HAL_UART_Receive_IT, która działa podobnie do HAL_UART_Receive.
Niestety nie ma w niej parametru określającego czas oczekiwania na dane (timeout), więc po wywołaniu biblioteka będzie czekała dowolnie długo. Nie jest to problemem, jeśli będziemy odbierać jeden bajt danych, zacznijmy więc od prostego przykładu.
Wywołajmy funkcję odbierania danych przed pętlą główną:
HAL_UART_Receive_IT(&huart2, &uart_rx_buffer, 1);
Musimy jeszcze zadeklarować nasz bufor na odebrane dane, czyli zmienną uart_rx_buffer, oraz napisać funkcję HAL_UART_RxCpltCallback, która zostanie wywołana po odebraniu danych.
/* USER CODE BEGIN 0 */
uint8_t uart_rx_buffer;
void HAL_UART_RxCpltCallback(UART_HandleTypeDef *huart)
{
}
Na początek jak zwykle przetestujmy działanie nowej funkcji, używając debuggera. Ustawiamy w niej pułapkę i uruchamiamy program. Aby pułapka zadziałała, musimy do programu przesłać coś z naszego terminala (np. TeraTerm). Wysyłamy dowolny znak i widzimy wywołanie naszej funkcji:
Sprawdzenie działania funkcji za pomocą debuggera
Odebraną wartość znajdziemy w zmiennej uart_rx_buffer. Będzie to jeden bajt (znak), więc z punktu widzenia naszego programu jest to mało użyteczne. Przydałoby się zapisać ten bajt do jakiegoś bufora, aby móc przetworzyć wszystkie dane, np. po odebraniu całej linii danych. Brzmi znajomo? Dokładnie taką funkcję napisaliśmy podczas omawiania komunikacji przez UART na STM32L4.
Dla przypomnienia: mowa o funkcji line_append. Możemy tu wykorzystać jej rozbudowaną wersję, we wnętrzu której znalazł się od razu mechanizm sterujący pracą diody świecącej (zmieniamy tylko hasła sterujące diodą z „włącz/wyłącz” na „on/off”).
#define LINE_MAX_LENGTH 80
static char line_buffer[LINE_MAX_LENGTH + 1];
static uint32_t line_length;
void line_append(uint8_t value)
{
if (value == '\r' || value == '\n') {
// odebraliśmy znak końca linii
if (line_length > 0) {
// dodajemy 0 na końcu linii
line_buffer[line_length] = '\0';
// przetwarzamy dane
if (strcmp(line_buffer, "on") == 0) {
HAL_GPIO_WritePin(LD2_GPIO_Port, LD2_Pin, GPIO_PIN_SET);
} else if (strcmp(line_buffer, "off") == 0) {
HAL_GPIO_WritePin(LD2_GPIO_Port, LD2_Pin, GPIO_PIN_RESET);
}
// zaczynamy zbieranie danych od nowa
line_length = 0;
}
}
else {
if (line_length >= LINE_MAX_LENGTH) {
// za dużo danych, usuwamy wszystko co odebraliśmy dotychczas
line_length = 0;
}
// dopisujemy wartość do bufora
line_buffer[line_length++] = value;
}
}
Dodajemy powyższą funkcję do kodu, a następnie wykorzystujemy ją w HAL_UART_RxCpltCallback:
Wywołanie HAL_UART_Receive_IT przed pętlą główną sprawia, że układ zaczyna czekać na jeden bajt danych, co doprowadzi do jednego wywołania HAL_UART_RxCpltCallback. Zależy nam, aby dane były odbierane cały czas, więc po odebraniu każdego znaku znów wywołujemy HAL_UART_Receive_IT.
Na koniec wracamy koniecznie do pliku Core\Src\stm32l4xx_it.c i usuwamy z funkcji SysTick_Handler instrukcje, które migały diodą (zakłócałoby to działanie tego programu).
Teraz możemy włączać i wyłączać diodę LD2, przesyłając polecenia „on” lub „off”. Co więcej, cały kod obsługujący wykonywanie tych poleceń działa niezależnie od programu głównego, a odpowiednie ustawienie priorytetów przerwań sprawia, że pozostała część programu działa bez zakłóceń.
Sterowanie diodą za pomocą komend tekstowych realizowane jest przez przerwania
Trzeba jednak pamiętać, że są różne „szkoły”. Nie wszyscy programiści akceptują tak długie procedury obsługi przerwań (pomimo że ich wykonanie jest bardzo szybkie). Są jednak osoby, które uważają, że w przypadku mikrokontrolerów z wbudowanym mechanizmem zagnieżdżania przerwań (tak jak STM32L4) programy należy pisać wyłącznie w oparciu o przerwania, pozostawiając pustą pętlę główną (co można wykorzystać np. do usypiania układu). Nie namawiamy do stosowania żadnego konkretnego stylu, ale sygnalizujemy, że można spotkać się z różnymi podejściami do tego tematu.
Zadanie domowe
Wróć do programu, w którym zliczaliśmy w przerwaniu naciśnięcia przycisku. Sprawdź, jak zachowa się układ przy różnych ustawieniach przerwań (np. wyzwalanie przy obu zboczach).
Dodaj do układu drugi przycisk i drugi licznik naciśnięć. Sprawdź, czy działanie układu jest zakłócane przez drgania styków. Jeśli tak, to rozwiąż ten problem (cyfrowo lub filtrem RC).
Napisz program, który w procedurze obsługi przerwania SysTick będzie wysyłał przez UART aktualną wartość licznika SysTick podzieloną przez 1000. Sprawdź telefonem, czy taki sekundnik działa poprawnie i jak na jego dokładność wpływa sposób formatowania danych – porównaj wersję „%d\n” oraz „Aktualny czas: %d\n”.
Podsumowanie – co powinieneś zapamiętać?
Przerwania sprzętowe to mechanizm, który znacznie ułatwia tworzenie rozbudowanych programów. Trzeba jednak pamiętać, że niepoprawne korzystanie z przerwań może prowadzić do dziwnych błędów, które będzie ciężko naprawić. Czasami wystarczy zmiana priorytetów, ale niekiedy problem będzie leżał w zupełnie innym miejscu. Najważniejsze, abyś po lekturze tej części kursu potrafił stworzyć program wykorzystujący przerwania do reakcji na przycisk (pamiętając o ustawieniu odpowiednich priorytetów).
Co o tym sądzisz? Oceń ten wpis:
Średnia ocena 4.9 / 5. Głosów łącznie: 93
Nikt jeszcze nie głosował, bądź pierwszy!
Artykuł nie był pomocny? Jak możemy go poprawić? Wpisz swoje sugestie poniżej. Jeśli masz pytanie to zadaj je w komentarzu - ten formularz jest anonimowy, nie będziemy mogli Ci odpowiedzieć!
W kolejnej części kursu zajmiemy się licznikami (ang. timers), czyli peryferiami, dzięki którym możliwe jest wykonanie wielu przydatnych rzeczy – od generowania opóźnień, przez precyzyjne odmierzanie czasu, aż do generowania sygnału PWM, a to i tak tylko wycinek ich możliwości.
Główny autor kursu: Piotr Bugalski Współautor: Damian Szymański, ilustracje: Piotr Adamczyk Oficjalnym partnerem tego kursu jest firma STMicroelectronics Zakaz kopiowania treści kursów oraz grafik bez zgody FORBOT.pl
Dołącz do 30 tysięcy osób, które otrzymują powiadomienia o nowych artykułach! Zapisz się, a otrzymasz PDF-y ze ściągami (m.in. na temat mocy, tranzystorów, diod i schematów) oraz listę inspirujących DIY na bazie Arduino i Raspberry Pi.
Dołącz do 30 tysięcy osób, które otrzymują powiadomienia o nowych artykułach! Zapisz się, a otrzymasz PDF-y ze ściągami (m.in. na temat mocy, tranzystorów, diod i schematów) oraz listę inspirujących DIY z Arduino i RPi.





































{kind=link}
Trwa ładowanie komentarzy...