Sztuczna inteligencja to temat, którym interesuje się coraz więcej elektroników. Dlatego tym razem pokażemy, jak wykorzystać płytkę Asus Tinker Edge T do rozpoznawania znaków drogowych.
Oczywiście przy okazji spora dawka informacji dla osób, które nie miały jeszcze styczności z sieciami neuronowymi, TPU i modułem Google Coral.
Mikrokontrolery mają tak dużą moc obliczeniową, że za ich pomocą możliwe jest realizowanie prostych algorytmów opartych na sztucznej inteligencji. Przykładem takiego projektu jest rozpoznawanie gestu potrząśnięcia płytką – omówiliśmy to w artykule: „Sztuczna inteligencja na STM32? Przykład użycia X-CUBE-AI”. Niestety, wraz ze wzrostem ilości danych oraz komplikacji sieci takie podejście może okazać się jednak niewystarczające.
Asus Tinker Edge T – główny bohater wpisu
Jeden z etapów prac – szczegóły w dalszej części
W ramach tego artykułu omówimy krótko, czym jest klasyfikowanie i detekcja obiektów za pomocą sztucznej inteligencji (AI). Wszystko w kontekście używania sztucznych sieci neuronowych na systemach embedded. Następnie przyjrzymy się modułowi Coral i świetnej dokumentacji, którą przygotowali do niego inżynierowie z Google. Zajmiemy się również przykładem praktycznym – wykorzystamy płytkę Asus Tinker Edge T do stworzenia systemu rozpoznającego znaki drogowe.
Spoiler: uda się osiągnąć rozpoznawanie wielu znaków, na żywo, i to przy ponad 150 fpsach!
Klasyfikowanie obiektów za pomocą AI
Przykładem typowego zadania, w którym dobrze sprawdza się AI, jest rozpoznawanie obrazów oraz identyfikacja obiektów. Zacznijmy więc od rozpoznawania czy też klasyfikacji obrazów. Na początek musimy określić zbiór etykiet dla klas, do których będziemy przypisywać obrazy.
Taki niemal książkowy przykład to podział na psy i koty. Albo rozpoznawanie ręcznie pisanych cyfr (wówczas etykietami są cyfry od 0 do 9). W sieci znajdziemy gotowe zbiory obrazów, np. MNIST, zawierający 60 tysięcy obrazów cyfr do trenowania sieci i 10 tysięcy do testowania.
Przykładowe materiały do trenowania sieci
Ten przykład może nie jest najlepszy, bo do rozpoznawania cyfr wystarczy mikrokontroler, ale zawsze można wykorzystać większą bazę, np. ImageNet. Jest to sieć wytrenowana do rozpoznawania obrazów. Na wejście podajemy dowolne zdjęcie, a na wyjściu otrzymamy informacje co do prawdopodobieństwa, z jakim obiekt na zdjęciu należy do konkretnej klasy.
Przykładowe zdjęcie kota
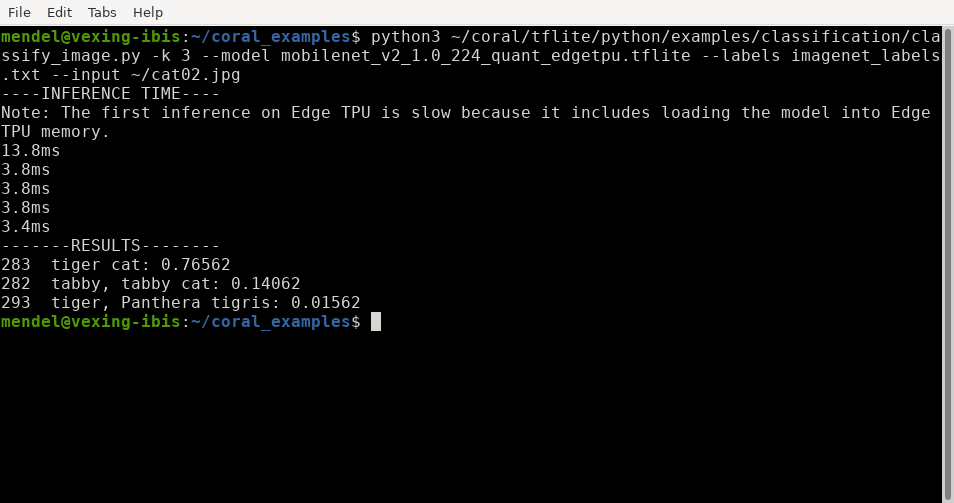
Po wgraniu zdjęcia, które zostało zaczerpnięte z Wikipedii (kot domowy), taka sieć poda poniższy wynik: prawdopodobieństwo wynosi ponad 76%, że jest to „tiger cat”, oraz 14%, że jest to „tabby cat”.
Do tej samej sieci możemy wgrać również inne zdjęcie, np. poniższego psa, które również pochodzi z Wikipedii (pies domowy). Rozpoznanie konkretnej rasy psa będzie dla naszej sieci jeszcze łatwiejsze.
Przykładowe zdjęcie psa
W wyniku działania sieci otrzymamy informację, że aż na 93% jest to pies rasy bokser. Jak widać, działa to wszystko zaskakująco sprawnie.
boxer: 0.92578
bull mastiff: 0.05859
Great Dane: 0.00391
Detekcja obiektów za pomocą AI
Detekcja obiektów wydaje się nieco trudniejsza. Podobnie jak w przypadku wcześniejszej klasyfikacji, na wejście sztucznej sieci neuronowej podajemy obraz, a jej zadaniem jest wykrycie widocznych obiektów i przypisanie każdego do odpowiedniej kategorii.
Przykładowe zdjęcia kotów
Gdy podamy na wejście sieci powyższy obraz, otrzymamy zbiór współrzędnych wykrytych obiektów wraz z prawdopodobieństwem ich przynależności do konkretnych klas. Mówiąc wprost, otrzymamy informację, że na obrazie jest sześć kotów i gdzie dokładnie znajdują się na zdjęciu – a przynajmniej tak powinno być w idealnej sytuacji. W praktyce taka sieć może oczywiście podać błędne wyniki.
Ciąg współrzędnych nie jest zbyt czytelny. Można więc wykorzystać te dane do tego, aby zaznaczyć obiekty na zdjęciu, które zostało podane na wejściu sieci. Tym sposobem uzyskamy poniższy obraz, który większości osób skojarzy się od razu właśnie ze sztuczną inteligencją.
Wynik działania sztucznej sieci neuronowej – odszukanie i klasyfikacja obiektów (na bazie innych danych niż te, które zostały pokazane wyżej w formie tekstowej)
Dlaczego potrzebujemy TPU (i co to jest)?
W artykule o STM32 używaliśmy jako danych wejściowych wektora o długości 128 B, a nasza sieć miała około 2000 węzłów, co pozwalało na jej realizację z użyciem mikrokontrolera. Jej strukturę sami zaprojektowaliśmy i wytrenowaliśmy od zera.
Do przetwarzania obrazów moglibyśmy również zaprojektować i wytrenować własną sieć, ale byłoby to zadanie o wiele trudniejsze. Zacznijmy od ilości danych wejściowych. Typowe kamery mają obecnie matryce liczone w megapikselach, jednak w przypadku sieci neuronowych używa się zmniejszonych obrazów – typowa wielkość to, powiedzmy, 224 × 224 piksele. W związku z tym, że obraz jest kolorowy, daje to nam: 224 · 224 · 3 = 150528 B.
Jest to prawie 150 kB danych wejściowych, czyli niemal 1200 razy więcej niż poprzednio.
Biorąc pod uwagę wielkość dostępnej pamięci RAM w mikrokontrolerach, wyraźnie widać, że tym razem musimy wykorzystać inne rozwiązanie. Oczywiście dane wejściowe to jedno, ale kolejny problem to wielkość i struktura samej sieci. Wszystkie narzędzia potrzebne do projektowania własnych sieci, jak chociażby pakiet Keras, są dostępne, jednak opracowanie własnej sieci to skomplikowane zadanie, którym zajmują się naukowcy na wiodących uczelniach oraz w firmach takich jak np. Google.
Na szczęście możemy skorzystać z osiągnięć innych. Opisywane wcześniej przykłady wykorzystywały sieć MobileNet, wytrenowaną na bazie ImageNet. Więcej informacji na temat MobileNet znaleźć można w tym artykule naukowym, który został napisany przez pracowników Google.
Nawet jeśli nie mamy czasu ani chęci, by przeczytać cały artykuł o MobileNet, to warto zwrócić uwagę na następujące parametry tej sieci:
Liczba warstw: 28
Liczba parametrów. 4,2 miliona
Liczba operacji mnożenia/dodawania: 569 milionów
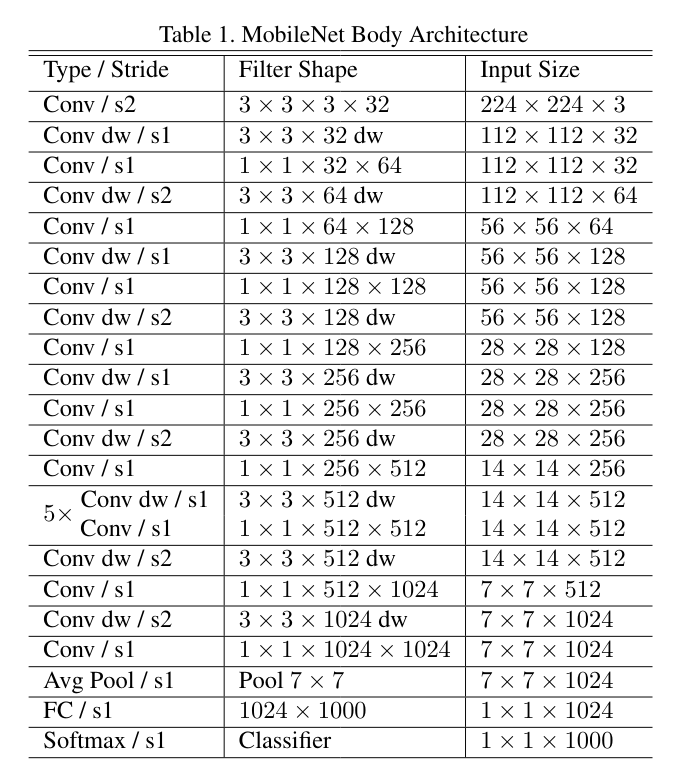
Struktura sieci została opisana we wspomnianym artykule, a jej schemat jest widoczny w poniżej. Na górze znajduje się warstwa wejściowa, której wejście ma rozmiar 224 × 224 × 3, co odpowiada przeskalowanemu obrazowi, który podajemy sieci. Natomiast na samym dole jest warstwa Softmax, która klasyfikuje wyniki, przypisując im prawdopodobieństwo przynależności do jednej z tysiąca klas.
Ten diagram jest narysowany odwrotnie niż w większości dokumentacji. Warstwa Softmax najczęściej jest określana jako najwyższa (top) i tak będziemy się do niej później odnosić.
Architektura sieci MobileNet
Liczba węzłów tej sieci jest znaczna, ale warto popatrzeć na liczbę operacji mnożenia/dodawania potrzebnych do przetworzenia jednego obrazu – 569 milionów to dużo nawet dla CPU pracującego z częstotliwością liczoną w gigahercach, szczególnie jeśli chcielibyśmy analizować obraz w czasie rzeczywistym, np. 30 klatek na sekundę. Dlatego w pracach nad sztuczną inteligencją zamiast CPU najczęściej wykorzystywane są procesory graficzne czy znane każdemu miłośnikowi gier 3D GPU.
Jednak użycie GPU w przypadku urządzenia przenośnego lub wbudowanego bywa problematyczne, o czym wie każdy użytkownik laptopa przeznaczonego do gier. Takie urządzenia mają ogromny pobór mocy, wymagają więc dobrego chłodzenia, co najczęściej jest głośne i może być awaryjne.
W związku z tym, że przetwarzanie danych w przypadku sztucznych sieci neuronowych sprowadza się do wykonywania ogromnej liczby bardzo prostych operacji matematycznych, producenci elektroniki opracowali układy przeznaczone właśnie do takiego zastosowania.
Są one bardziej energooszczędne niż GPU, dzięki czemu pozwalają na użycie zaawansowanych sieci nawet w urządzeniach mobilnych, chociażby w smartfonach.
Czym jest TPU?
Takie akceleratory dedykowane AI mają kilka nazw. Niektórzy, np. Google, swój produkt określają jako TPU, czyli tensor processing unit. Inni producenci używają czasem nazwy NPU, pochodzącej od neural processing unit, jednak w każdym przypadku chodzi o to samo, czyli o wydajną implementację obliczeń.
Takie TPU są charakteryzowane wieloma parametrami. Jednym z podstawowych jest liczba operacji wykonywanych na sekundę, opisywana jako TOPS (tera operations per second). Przypomnijmy, że tera oznacza 10 do potęgi 12, a typowe akceleratory mają moc obliczeniową od kilku do kilkudziesięciu TOPS-ów, więc opisywana sieć nie stanowi dla nich żadnego wyzwania.
Jak zacząć z TPU?
Nie da się ukryć, że początki przygody ze sztuczną inteligencją nie są zbyt łatwe. Większość dostępnych książek koncentruje się na aspektach matematycznych, skutecznie odstraszając wielu zainteresowanych zawiłymi wzorami z zakresu algebry liniowej. Znacznie trudniej jest znaleźć praktyczne porady odnośnie do użycia AI w rzeczywistych projektach, a już w przypadku systemów wbudowanych pozostaje właściwie tylko szukanie informacji w Internecie.
Google Coral w formie modułu SOM
Przeglądając oferty różnych producentów mikroprocesorów, znajdziemy wiele modeli wyposażonych w akceleratory TPU. Niestety często dostajemy raptem szczątkową dokumentację (przeważnie dostępną tylko w języku chińskim) oraz podstawowe narzędzia i biblioteki, raczej dość trudne do wykorzystania dla początkującego użytkownika. Na szczęście Google poświęcił dużo sił i środków na przygotowanie obszernej dokumentacji oraz przykładów dla własnego modułu TPU, nazwanego Google Coral.
Co ciekawe, sam układ TPU nie jest dostępny w sprzedaży detalicznej, jednak możemy bez problemu kupić gotowe moduły, które są w niego wyposażone, np. moduł SOM (system-on-module). Niemniej aby wykorzystać taki moduł do nauki, potrzebna nam będzie jeszcze płytka bazowa.
Asus Tinker Edge T w praktyce
Jednym z takich rozwiązań jest płytka wyprodukowana przez „tego samego” Asusa, którego kojarzymy np. z laptopami. Asus Tinker Edge T to płytka bazowa wyposażona w Coral SOM, produkowany przez Google, jest więc w 100% zgodna z dokumentacją i wspomnianymi wcześniej przykładami.
Na pokładzie modułu Coral SOM znajdziemy mikroprocesor NXP i.MX8M, wyposażony w cztery rdzenie Cortex-A53 i jeden Cortex-M4F, 1 GB pamięci LPDDR4, 8 GB eMMC oraz – co chyba najważniejsze – właśnie upragniony przez nas akcelerator TPU.
Asus Tinker Edge T wraz z dedykowaną podstawką
Płytka bazowa posiada natomiast złącze Ethernet, trzy interfejsy USB, wyjście HDMI oraz dwa złącza CSI do podłączenia kamery (przeznaczonej dla modułów Coral). Całość jest zasilana napięciem 12–19 V i pracuje pod kontrolą dedykowanego systemu o nazwie Mendel (bazuje on na Debianie).
Asus Tinker Edge T od spodu – widoczne są tu gniazda taśmowe na dwie kamery
Łatwo dostrzec podobieństwo tej płytki do Dev Board od Google. Jest to jednak ogromna zaleta – mamy dostęp do oprogramowania i świetnej dokumentacji przygotowanej przez Google.
Płytka od Asusa ma jednak możliwość podłączenia dwóch kamer, posiada o jedno gniazdo USB więcej, a całość wyposażona jest też w podstawkę, dzięki której nie zrobimy przypadkowego zwarcia. Co najciekawsze, Asus Tinker Edge T kosztuje obecnie 695 zł, a zatem jest tańszy i lepiej wyposażony od płytki Dev Board, za którą trzeba zapłacić 849 zł.
Asus Tinker Edge T z zamontowanym modułem Google Coral
Pełna specyfikacja płytki:
SoC NXP i.MX 8M
GPU GC7000 Lite
Google Edge TPU
1 × HDMI with CEC hardware ready
1 × 22-pin MIPI DSI
Dual-CH LPDDR4 1 GB
8 GB eMMC
Gniazdo na kartę microSD
Łączność:
RTL8211F-CG LAN
802.11 a/b/g/n/ac
Bluetooth 4.2
2 × USB 3.2
1 × USB 3.2 typu C (z OTG)
2 × 24-pin MIPI CSI-2
Złącze GPIO:
28 × GPIO
1 × SPI
2 × I2C
2 × UART
3 × PWM
1 × PCM/I2S
Złącze dla wentylatora
Zasilanie: 12–19 V (do 45 W)
Wymiary: 8,55 × 5,4 cm
Płytka Asus Tinker Edge T jest wyposażona w złącze GPIO, znane z Raspberry Pi
Pierwsze uruchomienie Asus Tinker Edge T
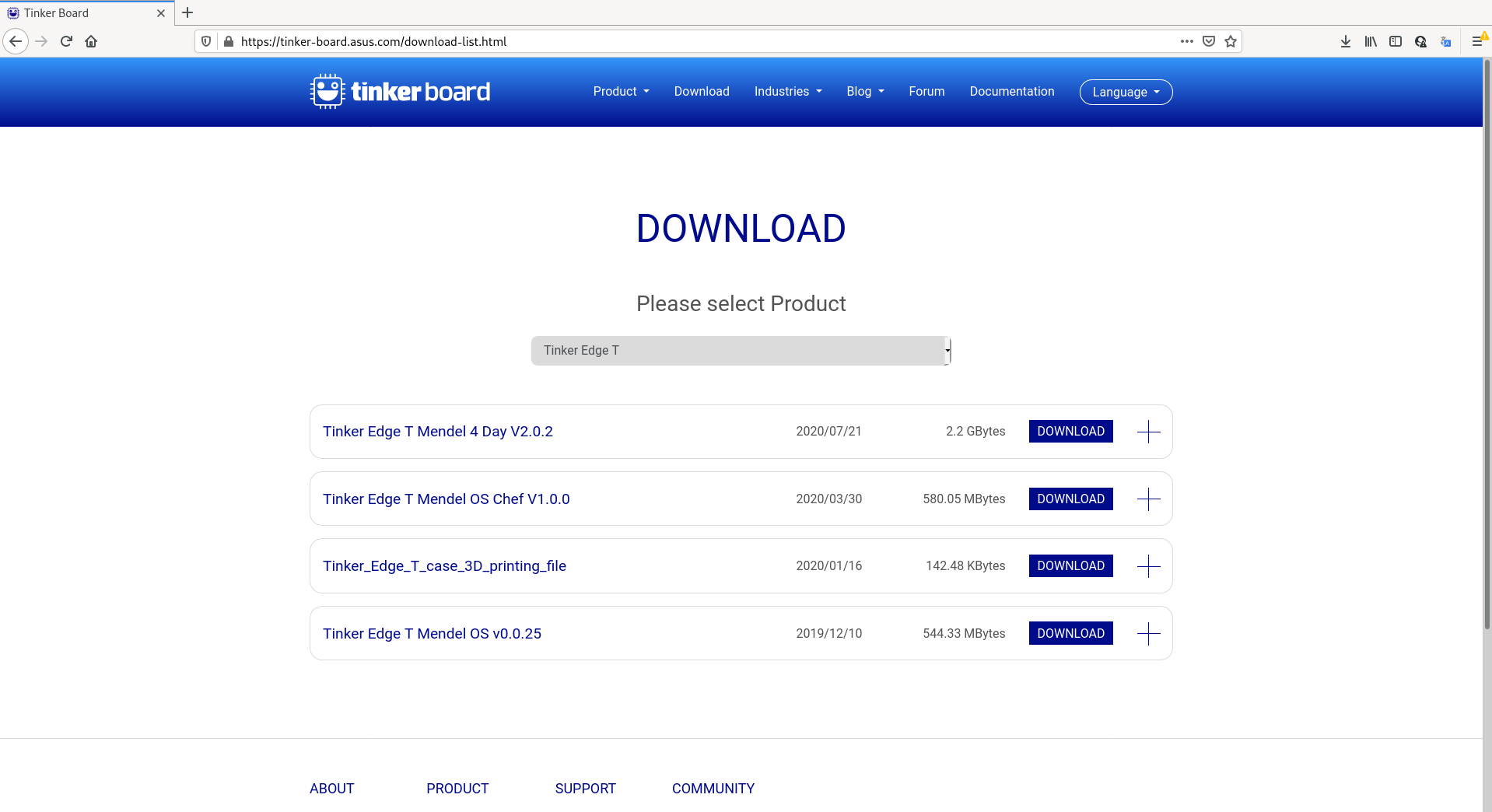
Dokumentację płytki znajdziemy na stronie producenta. Szczególnie warto zwrócić uwagę na pliki z instrukcją szybkiego startu oraz pełną instrukcją. Po zapoznaniu się z tymi dokumentami możemy przejść do najciekawszego, czyli praktyki. Pobieramy więc najnowszą wersję systemu operacyjnego (w chwili pisania tego artykułu jest to Mendel 4 Day).
Sam system, czyli Mendel, został również opracowany przez firmę Google, więc tutaj, podobnie jak w przypadku modułu Coral SOM, mamy pełną zgodność z oryginałem.
Instalacja systemu nie jest trudnym procesem. Wszystko znajdziemy we wspomnianych instrukcjach. Całość sprowadza się do instalacji sterowników, podłączenia płytki przewodem USB-C i uruchomienia specjalnego skryptu. Nagrywanie obrazu systemu zajmuje trochę czasu, ale na szczęście nie musimy wykonywać tego zbyt często. Po kilku minutach nasz nowy system powinien zostać uruchomiony.
Pobieranie systemu operacyjnego Mendel
Pierwsze, co rzuca się w oczy, poza oczywiście piękną tapetą, to dość nietypowy wygląd okienek oraz brak menu. Mendel jest bardzo nowoczesny – zamiast starego i znanego wszystkim użytkownikom Linuxa X-serwera domyślnie używany jest Weston. Na szczęście został on skonfigurowany z obsługą XWayland, więc aplikacje obsługujące tylko X będą również działały.
System Mendel zainstalowany na Asus Tinker Edge T
Nowo zainstalowany system trzeba najpierw oczywiście skonfigurować. W instrukcji znajdziemy opis podstawowych czynności do wykonania, takich jak wybór układu klawiatury i strefy czasowej oraz ustawianie daty czy rozdzielczości ekranu. Istotna jest także konfiguracja sieci, w tym sieci bezprzewodowej. Nie będziemy jednak skupiać się na tym w artykule – przejdźmy do najciekawszego.
Uruchomienie TPU na Asus Tinker Edge T
Gdy już przygotujemy system do pracy, możemy przejść do dokumentacji stworzonej przez Google. Na początek warto przeczytać instrukcję get-started dla płytki Coral-dev. Fragmenty dotyczące instalacji systemu musimy pominąć, ponieważ przebiega ona nieco inaczej, natomiast pozostałe informacje bardzo nam się przydadzą.
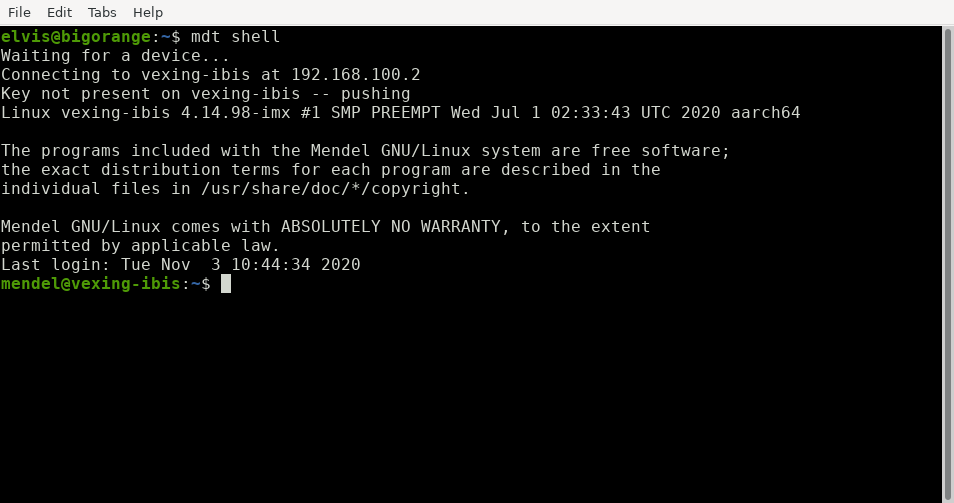
Pierwsza to możliwość pracy zdalnej za pomocą narzędzia mdt oraz zwykłego kabelka USB-C. Możemy oczywiście używać ssh, ale mdt czasem bywa wygodniejsze. Wystarczy uruchomić polecenie mdt shell i już jesteśmy zdalnie połączeni z naszą płytką (bez ustalania adresu IP, podawania loginu czy hasła).
Narzędzie mdt posiada kilka przydatnych opcji, jak np. push – do kopiowania plików na urządzenie, czy też install – do zdalnej instalacji pakietów dpkg.
Połączenie z Asus Tinker Edge T za pomocą mdt
Czytając kolejne kroki instrukcji, dochodzimy do najważniejszego, czyli do uruchomienia programów demonstrujących działanie TPU. Dzięki temu możemy nareszcie rozpocząć przygodę ze sztucznymi sieciami neuronowymi w praktyce.
Informacje na temat wykorzystania TPU z dokumentacji Google
Pierwszy skrypt, czyli edgetpu_demo, prezentuje możliwość wykrywania obiektów, w tym przypadku samochodów, w nagranym obrazie. Najlepiej samemu obejrzeć rezultat:
Jak widzimy, TPU działa bardzo sprawnie. Wiatraczek chłodzący układ pracuje teraz na pełnych obrotach, ale czasy detekcji wielu obiektów są na poziomie 20 ms – to zdecydowanie rekompensuje tę niedogodność. Możemy od razu przejść też do przykładu z klasyfikacją obiektów.
Przykład klasyfikowania obiektów w dokumentacji Google
Rezultat jest dokładnie taki jak w opisie na stronie Google i już w zaledwie kilka milisekund przepiękna papuga ze zdjęcia jest rozpoznawana jako „Ara macao”.
Rozpoznawanie gatunku papugi na podstawie zdjęcia
Na początku artykułu zaprezentowaliśmy możliwość klasyfikacji zdjęć psów i kotów. Wykorzystaliśmy do tego zdjęcia z Wikipedii oraz właśnie ten przykładowy skrypt. Wystarczyło jedynie zmodyfikować samo polecenie, podając inne zdjęcie jako parametr:
Obrazek cat02.jpg to zdjęcie kota, które było umieszczone na początku tego artykułu. Poniżej widoczny jest pełny wynik zwrócony przez naszą sztuczną sieć neuronową uruchomioną na Asus Tinker Edge T.
Zachowanie sieci po wgraniu zdjęcia z kotem
Takie uruchamianie gotowych przykładów może wydawać się mało interesujące, ma jednak ogromne zalety – pozwala bardzo szybko poznać możliwości, jakie dają nam sieci neuronowe, a do wszystkich skryptów otrzymujemy kody źródłowe. Możemy więc zacząć naukę od działającego rozwiązania, modyfikując je do naszych potrzeb albo tworząc własne na podstawie dostarczonych przykładów.
Wykorzystywanie gotowych modeli
Uruchamiając przykład, przekazywaliśmy do skryptu classify_image.py dwa ważne parametry:
nazwę pliku z parametrami sieci (mobilenet_v2_1.0_224_quant_edgetpu.tflite),
nazwę pliku z etykietami kategorii (imagenet_labels.txt).
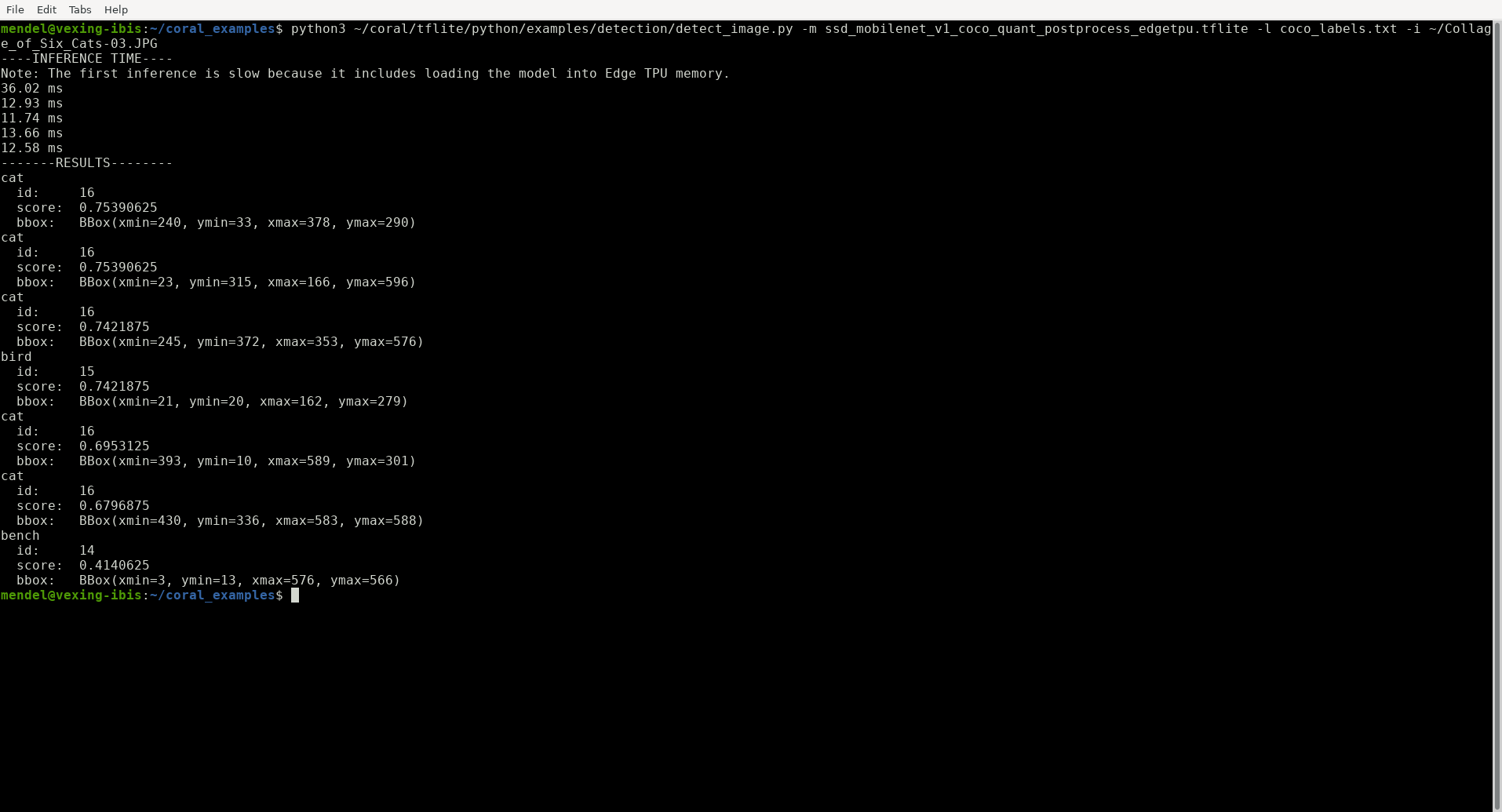
Mamy więc możliwość poeksperymentowania z różnymi sieciami, nie tylko z tą opisaną w poradniku. Pisząc o detekcji obiektów na początku tego artykułu, wykorzystaliśmy gotową sieć o bardzo długiej nazwie: ssd_mobilenet_v1_coco_quant_postprocess_edgetpu.tflite. Wystarczyło wywołać skrypt o nazwie detect_image.py z odpowiednimi parametrami:
I na naszej konsoli pojawiły się współrzędne wykrytych obiektów:
Efekt działania programu odszukującego koty na zdjęciu
Kolejny skrypt, tym razem o nazwie edgetpu_detect, pozwolił nie tylko wyświetlić współrzędne, ale również dał nam w wyniku obraz z nałożonymi miejscami, gdzie obiekty zostały wykryte.
Uruchamianie gotowych przykładów jest wciągające i pozwala szybko zapoznać się z możliwościami, jakie daje nam TPU oraz zastosowanie sztucznych sieci neuronowych. Jednak po pewnym czasie dochodzimy do wniosku, że warto byłoby wykorzystać sztuczną inteligencję do naszych własnych, niecnych celów.
Uczenie sieci od podstaw jest bardzo trudnym zajęciem, wymaga mnóstwa przykładów, dużo mocy obliczeniowej, czasu oraz umiejętności. Możemy jednak skorzystać z tzw. transfer learningu. W skrócie polega on na wykorzystaniu już wytrenowanej sieci do rozwiązywania innego zadania, niż sieć była uczona. Osiągamy to przez usunięcie najwyższej warstwy i zastąpienie jej inną, która będzie dostosowana do naszego zadania, oraz wykonanie trenowania z „zamrożonymi” niższymi warstwami.
Asus Tinker Edge T (elektronika, która normalnie schowana jest pod modułem Google Coral)
Pamiętacie diagram pokazujący sieć MobileNet, który zamieściliśmy na początku artykułu? Diagram jest narysowany do góry nogami, więc najwyższe warstwy są w nim na dole, ale idea jest następująca: warstwa Softmax oraz leżąca bezpośrednio pod nią FC ma wymiar 1000, ponieważ oryginalna sieć miała rozpoznawać 1000 klas obrazów.
A gdyby tak usunąć te warstwy i na ich miejsce wstawić własne, które będą rozpoznawały tyle klas, ile potrzebujemy? Na przykład dwie zamiast tysiąca wystarczą do rozpoznawania, czy na zdjęciu jest kot czy pies. Pozostałe warstwy możemy zostawić bez zmian, więc sama struktura sieci również pozostanie jak oryginał; zmienimy tylko to, co potrzebujemy.
Sieć MobileNet
Pomysł wydaje się dobry, ale jak się do tego zabrać? Tutaj znowu z pomocą przychodzą nam przykłady ze strony projektu Google Coral. Znajdziemy tam dokładny opis tego, jak wykorzystać transfer learning do trenowania własnej sieci dla problemu klasyfikacji.
Ponowne trenowanie wykrywania obiektów
Z kolei pod tym adresem znajdziemy inny przykład, tym razem zawierający dokładny opis, jak samemu wykonać trenowanie sieci wykrywającej rasy psów i kotów. Przykład dla detekcji obiektów przyda nam się za chwilę, więc omówmy nieco dokładniej to, co przygotował dla nas Google.
Na początku musimy przygotować obraz dockera, który wykorzystamy do trenowania sieci. To bardzo wygodna i nowoczesna metoda prezentowania przykładów, więc duży plus dla Google. W każdym razie wykonujemy krok po kroku polecenia z instrukcji, czyli:
CORAL_DIR=${HOME}/google-coral && mkdir -p ${CORAL_DIR}
cd ${CORAL_DIR}
git clone https://github.com/google-coral/tutorials.git
cd tutorials/docker/object_detection
docker build . -t detect-tutorial-tf1
Tym sposobem uzyskaliśmy obraz detect-tutorial-tf1, który jest gotowy do dalszej pracy. W kolejnym kroku uruchamiamy kontener z tym obrazem, a w nim skrypt prepare_checkpoint_and_dataset.sh.
Ten skrypt pobiera wszystkie dane niezbędne do wytrenowania naszej sieci. Najpierw pobierana jest sama sieć przygotowana do ponownego uczenia, a następnie zaciągane są też zdjęcia psów i kotów oraz etykiety informujące, gdzie na zdjęciach znajdziemy odpowiednie „obiekty”. Skrypt przygotowuje również pliki konfiguracyjne, w szczególności plik pipeline.config, do którego później jeszcze wrócimy.
Skrypt działa automatycznie, wystarczy go uruchomić i poczekać. Oczywiście warto przeanalizować jego działanie, ale nie jest to niezbędne, bo od razu mamy wersję gotową do dalszego działania.
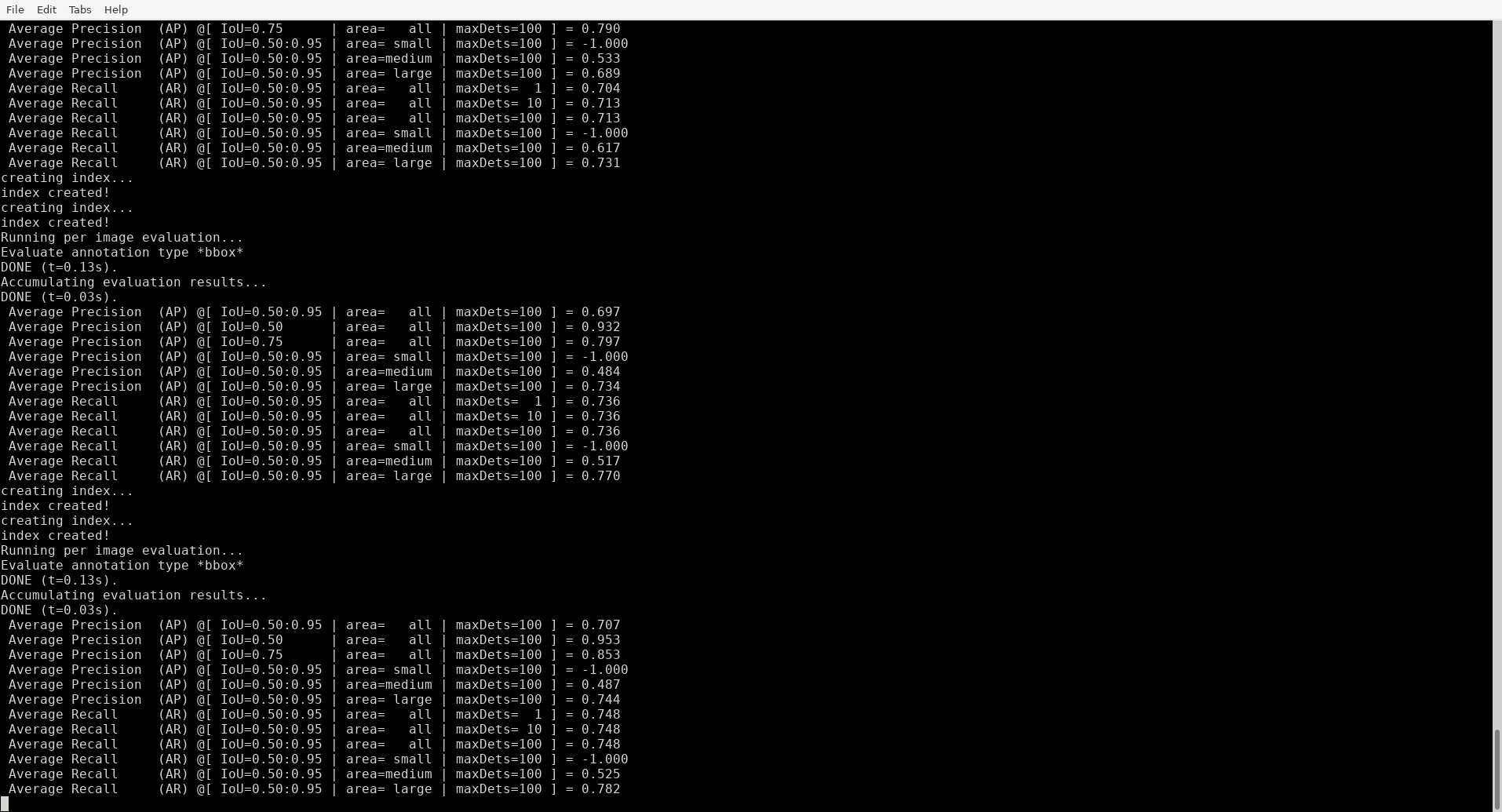
Teraz wystarczy uruchomić skrypt retrain_detection_model.sh, który rozpocznie uczenie sieci.
Nawet tak uproszczona wersja trenowania sieci zajmuje sporo czasu. Zgodnie z opisem na stronie Coral (oraz z tym, co wynika z naszych eksperymentów) potrzeba godziny, aby sieć została wytrenowana. W międzyczasie możemy oczywiście oglądać postępy uczenia.
Podgląd z postępów uczenia sztucznej sieci neuronowej
Nie jesteśmy jednak skazani na godzinę patrzenia w terminal. Możemy w ogóle nie śledzić tego postępu, ale możemy też zerknąć do interfejsu, który dostępny jest z poziomu przeglądarki – to wygląda już znacznie ciekawiej. Jest na co popatrzeć!
Podgląd procesu uczenia sieci z poziomu przeglądarki
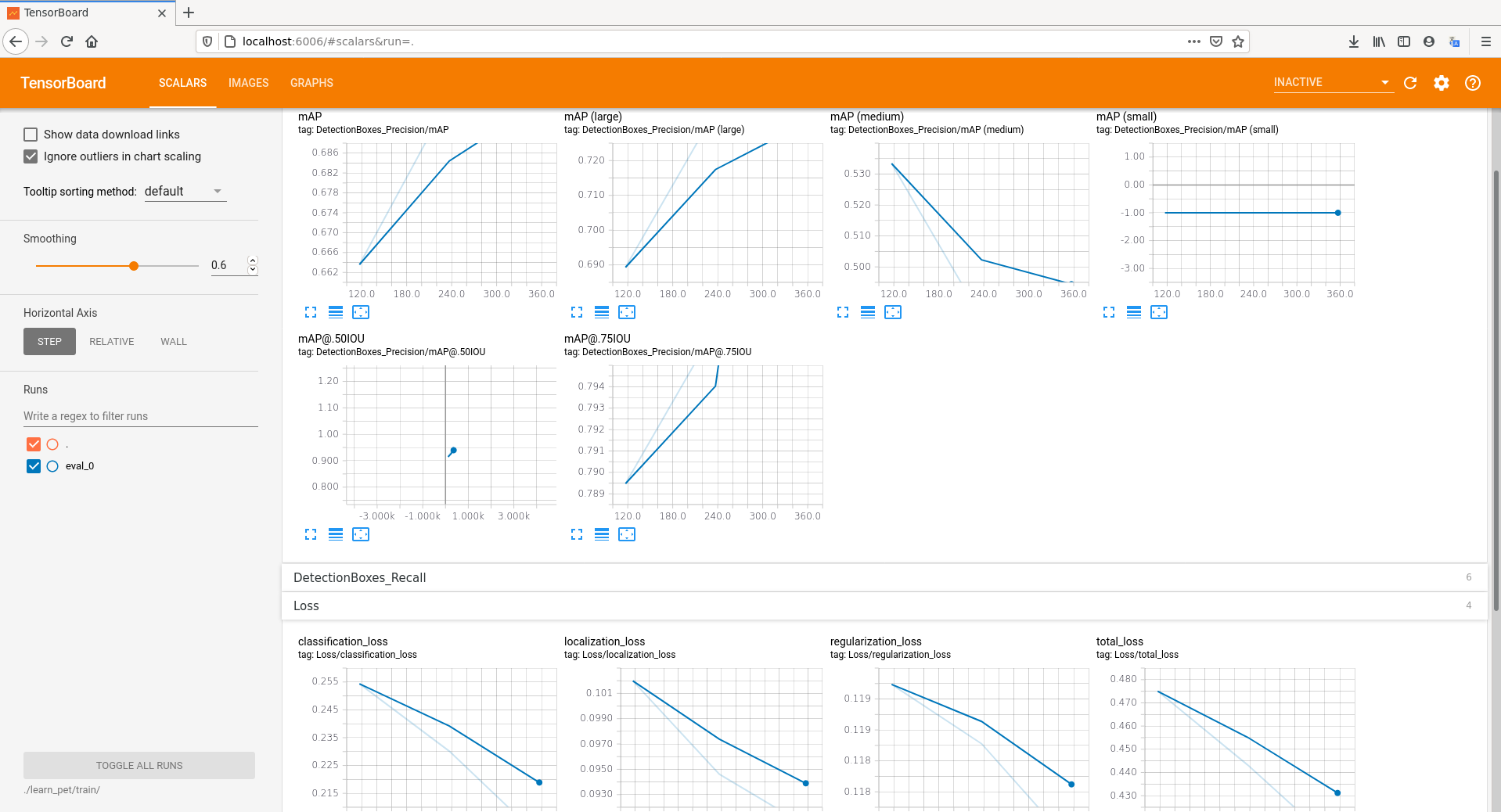
Najciekawsze dla wielu osób mogą być jednak statystyki. Tutaj warto śledzić np. tzw. stratę uczenia, czyli wskaźnik, który pozwala nam ocenić, jak wiele błędów popełnia sztuczna sieć neuronowa podczas rozpoznawania obrazów.
Podgląd na statystyki procesu uczenia
Gdy uczenie zostanie już zakończone, uruchamiamy skrypt convert_checkpoint_to_edgetpu_tflite.sh, który zapisze wyniki w formacie TensorFlow Lite.
./convert_checkpoint_to_edgetpu_tflite.sh --checkpoint_num 500
root@e2759a803523:/tensorflow/models/research# ls -hal learn_pet/models/output_tflite_graph.tflite
-rw-r--r-- 1 root root 5.4M Nov 4 17:34 learn_pet/models/output_tflite_graph.tflite
Otrzymany plik musimy jeszcze przekompilować do postaci używanej przez TPU. Wykonujemy to za pomocą programu edgetpu_compiler (to już poza dockerem):
edgetpu_compiler output_tflite_graph.tflite
W efekcie otrzymaliśmy plik o nazwie output_tflite_graph_edgetpu.tflite, który możemy uruchomić na naszej płytce Asus Tinker Edge T, tak samo jak wcześniej uruchamialiśmy przykładowe sieci. Jak widać, nawet gdy mamy wszystko idealnie przygotowane i udokumentowane, uczenie sieci nie jest trywialnym zajęciem. Na szczęście dzięki dobrej dokumentacji może to wykonać nawet początkujący adept machine learningu. Z czasem warto jednak zacząć analizować kolejne skrypty, aby wiedzieć, ile magii dzieje się „pod spodem”.
Rozpoznawanie znaków drogowych
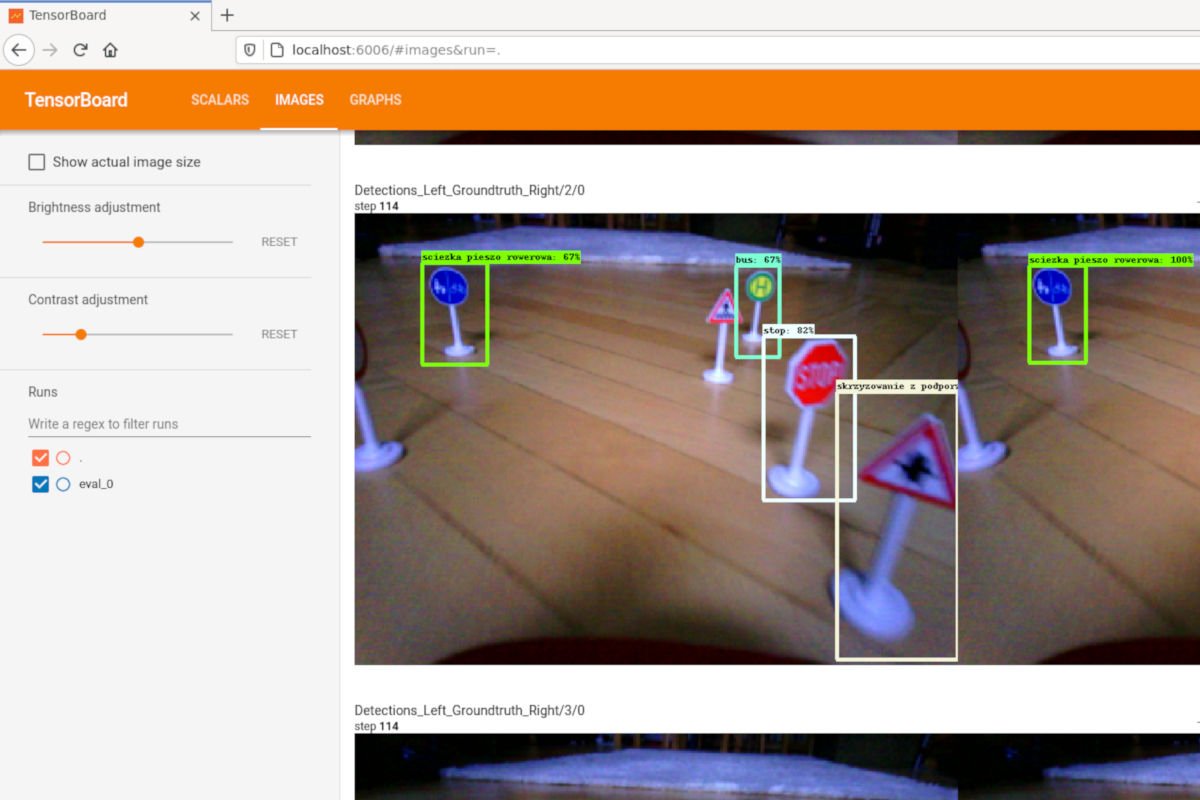
Wśród przykładów od Google znajdziemy też opis, jak samodzielnie zebrać dane oraz wytrenować sieć. Uznaliśmy, że warto spróbować i wykorzystać sieć do rozpoznawania czegoś innego niż psy i koty. Tym razem naszą inspiracją był autonomiczny samochód RC. Postanowiliśmy użyć płytki Asus Tinker Edge T do budowy systemu, który będzie automatycznie rozpoznawał znaki drogowe.
Platforma testowa – mały samochód RC z Asus Tinker Edge T i kamerą
Na początek (prowizoryczna) część mechaniczna, czyli przymocowanie płytki Asus Tinker Edge T wraz z kamerą do samochodu. To miał być tylko przykład, więc mechanika jest daleka od ideału. To gotowy samochód RC, do którego przykręciliśmy żółte mocowanie stworzone wcześniej na drukarce 3D, a następnie zamontowaliśmy na dachu płytkę Asus Tinker Edge T wraz z kamerą.
Znaki, które brały udział w naszym eksperymencie
Do tego konieczne było jeszcze zdobycie znaków drogowych – nie są to niestety znaki, które obowiązują w Polsce, ale nie można mieć wszystkiego… Mamy już nasz samochód wyposażony w kamerę oraz znaki drogowe, które będziemy chcieli później rozpoznawać. Przystępujemy więc do zbierania danych, czyli wykonywania zdjęć widzianych „oczami” naszego pojazdu.
Zbieranie danych do nauki sieci
Przygotowywanie danych do nauki to jeden z najważniejszych i – niestety – najbardziej czasochłonnych etapów pracy. Na potrzeby tego projektu wykonaliśmy 100 różnych zdjęć, co i tak jest zbyt małą liczbą, ale chcieliśmy tutaj przetestować, jak działa uczenie sieci i czy warto poświęcać na to więcej czasu.
Przykładowe zdjęcie do uczenia
Przykładowe zdjęcie do uczenia
Kolejnym etapem jest określenie położenia i typu znaków drogowych widocznych na zdjęciach. Trzeba więc ręcznie przejrzeć 100 zdjęć, zaznaczyć znaki i je opisać. Nasza sieć musi otrzymać informacje o wynikach, których oczekujemy. W tym przypadku konieczne było ręczne przygotowanie zbioru zdjęć z opisanymi znakami.
Jako narzędzie do tworzenia etykiet użyty został tutaj darmowy program labelImg.
Ręczne zaznaczanie znaków
Ręczne zaznaczanie znaków cd.
Po długiej i ciężkiej pracy otrzymujemy 100 zdjęć z zaznaczonymi na nich znakami drogowymi. Niestety narzędzia używane do nauki oczekują danych w innym formacie niż dotychczas stosowany. Jednak za pomocą Pythona bez problemu napiszemy prosty skrypt, który wczyta wszystkie zdjęcia oraz ich opisy (labelImg zapisuje je jako JSON), a następnie zapisze w formacie TFRecord, przy okazji dzieląc je na dwie grupy: treningową i testową.
Ostatnie, co zostało do przygotowania, to plik z etykietami znaków. Wygląda on następująco:
test1-train.tfrecord – dane treningowe dla sieci (zdjęcia + zaznaczone obiekty),
test1-eval.tfrecord – dane testowe,
test1.pbtxt – etykiety.
Możemy też wrócić do omówionego poprzednio przykładu z uczeniem sieci. Uruchamiamy kontener dockera, ale wykorzystujemy nowy katalog zamiast użytego poprzednio „out”. Dzięki temu będziemy mogli porównywać nasze rozwiązanie z przykładem.
Wewnątrz dockera nasz katalog jest widoczny pod tą samą nazwą co poprzednio, więc nie musimy zmieniać przykładowych skryptów.
Poprzednio w tym momencie uruchomiliśmy skrypt prepare_checkpoint_and_dataset.sh, ale nie chcemy znowu pobierać zdjęć psów i kotów, więc skopiujemy pliki ręcznie. Najpierw wchodzimy na stronę z wytrenowanymi modelami i pobieramy sieć, której użyjemy jako bazową – będzie to ta sama co w poprzednim przykładzie, czyli MobileNet SSD v1.
Model sieci potrzebnej do tego zadania
Zawartość archiwum rozpakowujemy do katalogu o nazwie ckpt. Z poziomu dockera powinniśmy teraz widzieć całą jego zawartość. Powinno to wyglądać jak na poniższym zrzucie ekranu.
Zawartość wypakowanego katalogu widoczna w dockerze
Teraz możemy utworzyć katalog na nasze dane treningowe i skopiować przygotowane wcześniej pliki. Nazwa nie ma większego znaczenia, ale skoro to miał być pierwszy test, to zostaniemy przy test1.
Katalog z danymi treningowymi
Wszystkie dane są już na miejscu, musimy jeszcze wprowadzić zmiany w pliku konfiguracyjnym, czyli ckpt/pipline.config. Zmieniamy odpowiednie wartości:
num_classes – mamy sześć znaków, więc zamiast domyślnych 90 ustawiamy 6 klas,
total_steps, warmup_steps – ustawiamy zgodnie z sugestią w tutorialu na 1000 i 100,
fine_tune_checkpoint – podajemy lokalizację pliku z siecią (model.ckpt),
from_detection_checkpoint, load_all_detection_checkpoint_vars – ustawiamy na true,
freeze_variables – ustawiamy, które warstwy mają zostać bez zmian; najłatwiej jest skopiować wartość z przykładu omawianego wcześniej (czyli rozpoznawania ras psów i kotów),
train_input_reader – podajemy, gdzie szukać naszych danych treningowych,
eval_input_reader – tutaj podajemy, gdzie są dane testowe.
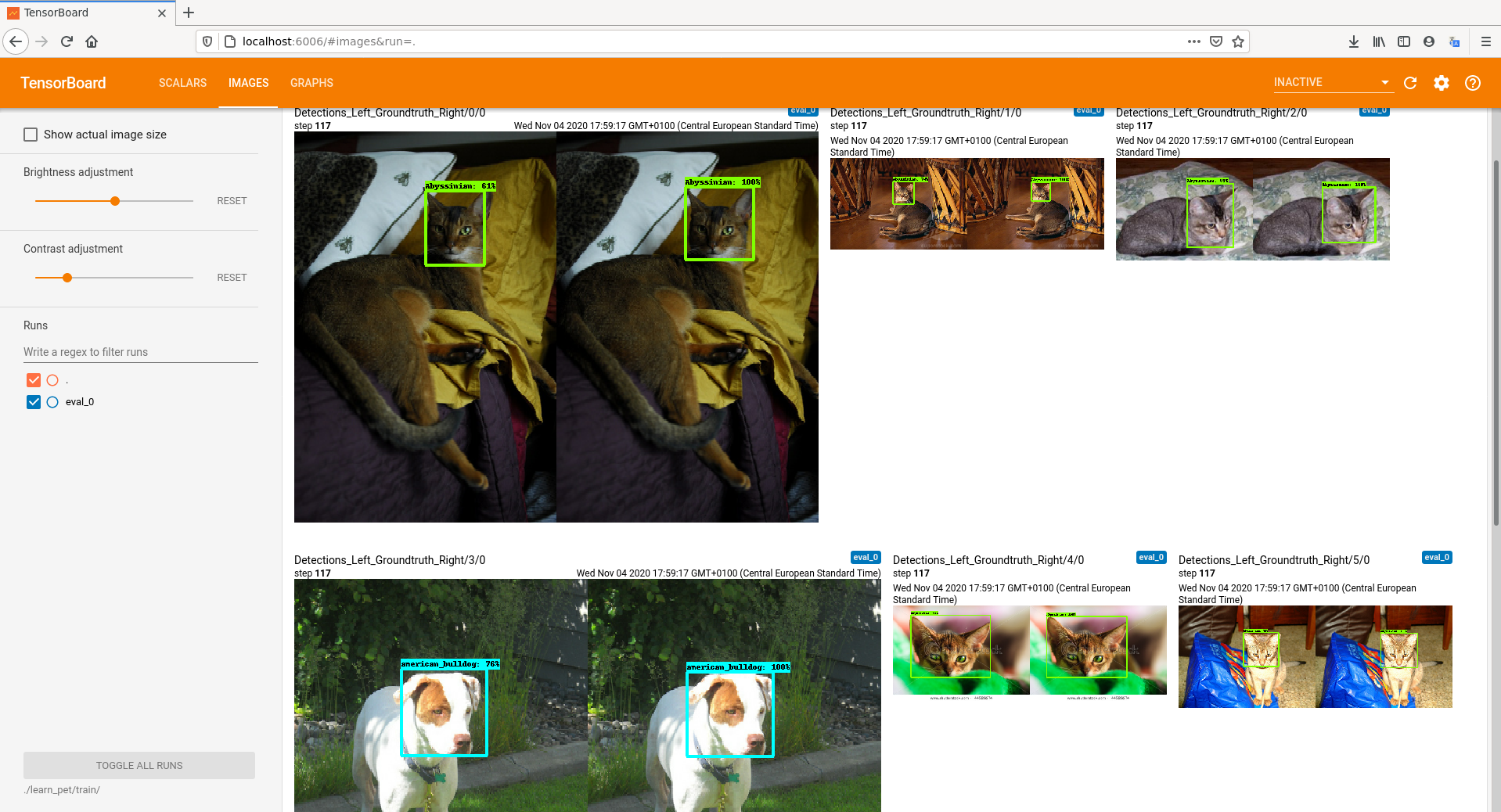
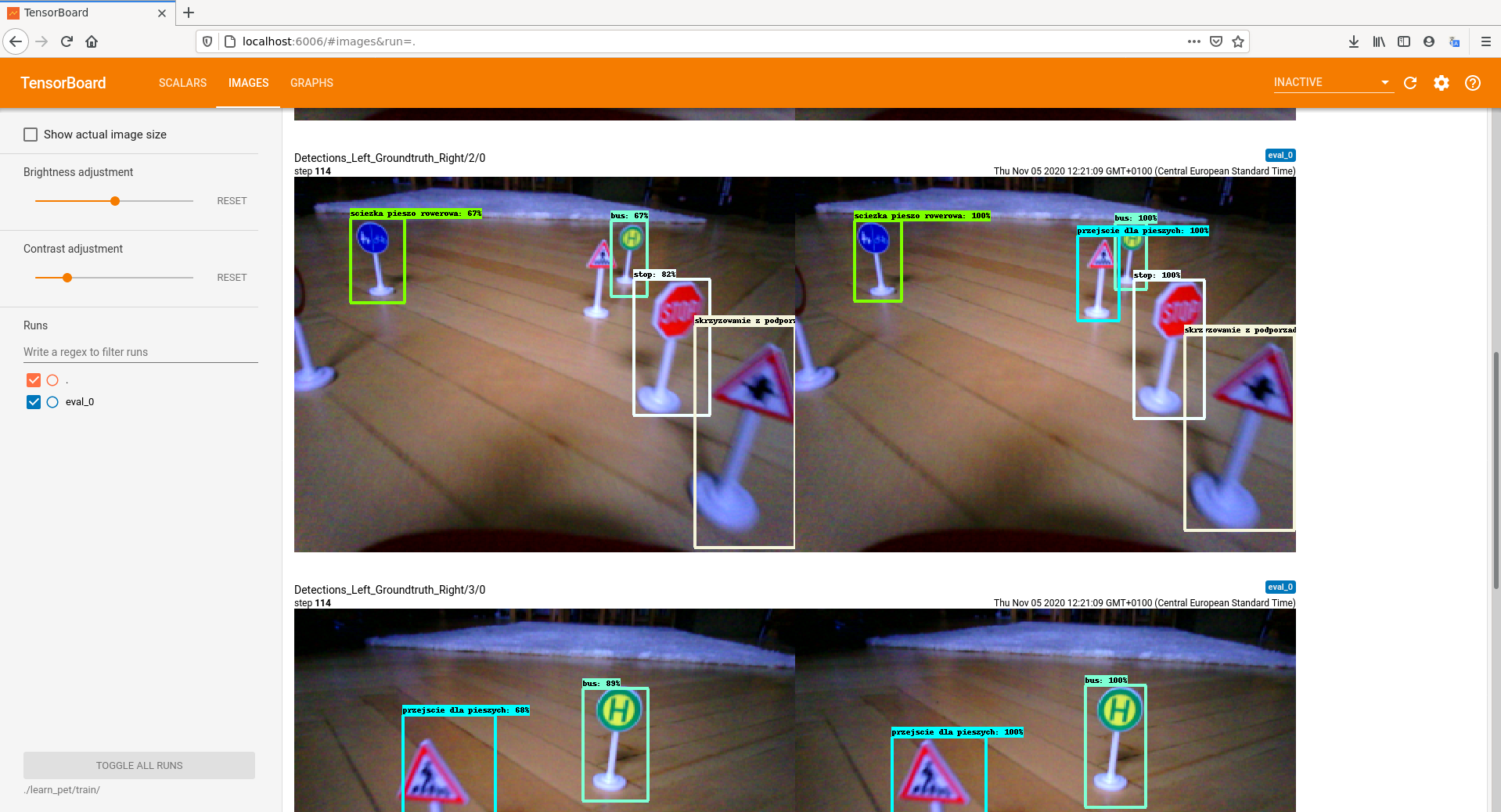
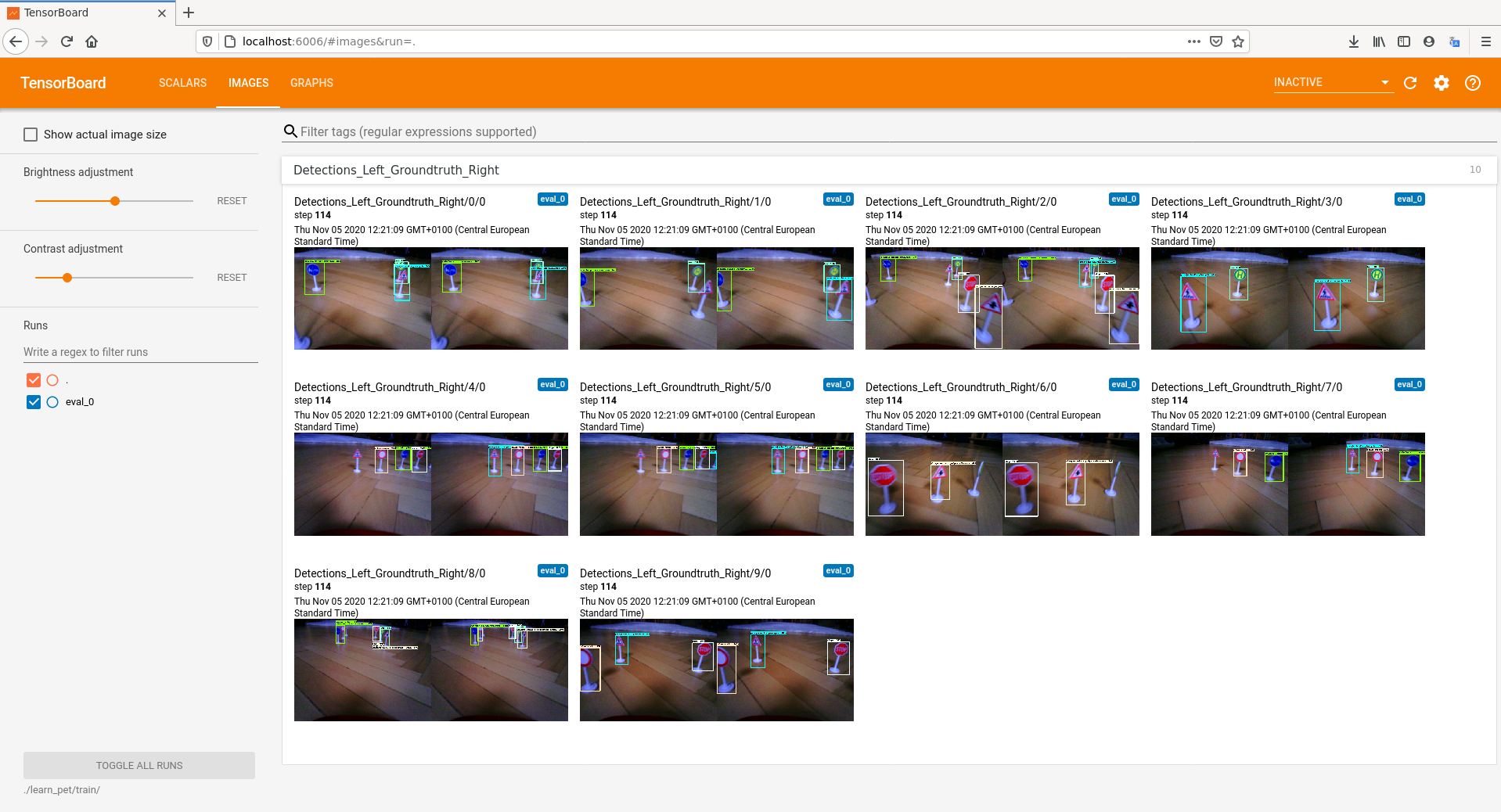
Teraz wszystko jest już faktycznie gotowe do nauki. Podobnie jak poprzednio uruchamiamy skrypt retrain_detection_model.sh i możemy sobie zrobić długą przerwę, czekając, aż sieć nauczy się nowych danych. W międzyczasie pozostaje nam obserwować postępy nauki naszej sieci.
Podgląd danych z uczenia sieci
Podgląd danych z uczenia sieci cd.
Gdy nauka sieci dobiegnie końca, konwertujemy wynik do formatu tflite, a następnie kompilujemy do postaci oczekiwanej przez TPU i gotowy plik wgrywamy na płytkę Asus Tinker Edge T. Teraz możemy uruchomić przykład podobnie jak wcześniej dostarczany przez Google.
Jak widzimy, akcelerator działa bardzo sprawnie, wykrywanie znaków trwa raptem milisekundy. Niestety nie udało nam się wyłączyć autofocusu w kamerze, więc obraz traci momentami na ostrości, ale nie ma to związku z siecią, więc uznajmy, że nie przeszkadza to podczas testów. Na zakończenie symulacja jazdy naszym „autonomicznym samochodem” w wersji DIY.
Podsumowanie
Uzyskany efekt wymagałby niewątpliwie dopracowania, ale już teraz widać, jakie możliwości daje TPU. Udało nam się upakować na dachu małego samochodu RC kamerę i miniaturowy komputer z TPU, dzięki któremu można wykrywać i rozpoznawać znaki drogowe, i to z częstotliwością >150 fpsów!
Co o tym sądzisz? Oceń ten wpis:
Średnia ocena 4.9 / 5. Głosów łącznie: 49
Nikt jeszcze nie głosował, bądź pierwszy!
Artykuł nie był pomocny? Jak możemy go poprawić? Wpisz swoje sugestie poniżej. Jeśli masz pytanie to zadaj je w komentarzu - ten formularz jest anonimowy, nie będziemy mogli Ci odpowiedzieć!
W niniejszym artykule chcieliśmy pokazać, jak ogromne możliwości daje zastosowanie sztucznych sieci neuronowych w urządzeniach wbudowanych. Zaprezentowane przykłady to mniej niż wstęp, ale tego typu materiałów jest w sieci tak mało, że ten poradnik i tak powinien być pomocny dla początkujących.
Autor: Piotr Bugalski Redakcja techniczna: Damian Szymański
Artykuł sponsorowany dla firmy Asus, która zaproponowała płytkę Asus Tinker Edge T jako platformę do przeprowadzenia testów AI. Firma ta nie miała jednak żadnego wpływu na treść publikacji.
Sztuczna inteligencja to temat kojarzony głównie z komputerami PC lub chmurami obliczeniowymi. Jednak z AI można korzystać nawet na... Czytaj dalej »
Odnośniki do niektórych produktów umieszczone w tym wpisie prowadzą do głównego partnera serwisu – sklepu Botland. Nie są to linki afiliacyjne. Na tej podstronie opisaliśmy na czym dokładnie polega nasza współpraca.
Dołącz do 30 tysięcy osób, które otrzymują powiadomienia o nowych artykułach! Zapisz się, a otrzymasz PDF-y ze ściągami (m.in. na temat mocy, tranzystorów, diod i schematów) oraz listę inspirujących DIY na bazie Arduino i Raspberry Pi.
To nie koniec, sprawdź również
Przeczytaj powiązane artykuły oraz aktualnie popularne wpisy lub losuj inny artykuł »
Dołącz do 30 tysięcy osób, które otrzymują powiadomienia o nowych artykułach! Zapisz się, a otrzymasz PDF-y ze ściągami (m.in. na temat mocy, tranzystorów, diod i schematów) oraz listę inspirujących DIY z Arduino i RPi.







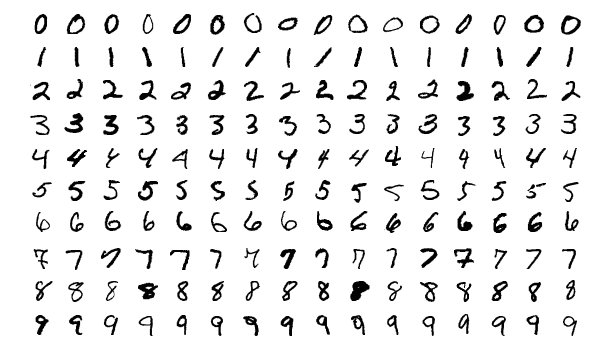








































Trwa ładowanie komentarzy...